《统计学》学习笔记之数据的概括性度量
鄙人学习笔记
文章目录
- 数据的概括性度量
- 集中趋势的度量
- 离散程度的度量
- 偏态与峰态的度量
数据的概括性度量
数据分布的特征可以从三个方面进行测度和描述:
①分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度
②分布的离散程度,反映各数据远离其中心值的趋势
③分布的形状,反映数据分布的偏态和峰态。
集中趋势的度量
- 集中趋势
集中趋势是指一组数据向某一中心值靠拢的程度。它反映了一组数据中心点的位置所在。
- 众数
众数是一组数据中出现次数最多的变量值,用Mo表示。众数主要用于测度分类数据的集中趋势,当然也适用于作为顺序数据以及数值型数据集中趋势的测度值。一般情况下,只有在数据量较大的情况下,众数才有意义。
- 中位数
中位数是一组数据排序后处于中间位置上的变量值,用Me表示。显然,中位数将全部数据等分成两部分,每部分包含50%的数据,一部分数据比中位数大,另一部分比中位数小。中位数主要用于测度顺序数据的集中趋势,当然也适用于测度数值型数据的集中趋势,但不适用于分类数据。
备注:各变量值与其中位数的离差绝对值之和最小。
设一组数据为x1,x2,…,xn,按从小到大的顺序排序后为x(1),x(2),…,x(n).则中位数为:
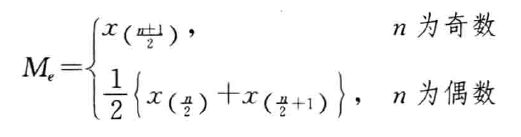
- 四分位数
四分位数也称四分位点,它是一组数据排序后处于25%和75%位置上的值。
设下四分位数为QL, 上四分位数为QU, 根据四分位数的定义有:
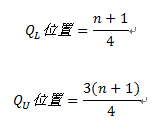
如果位置是整数,四分位数就是该位置对应的值;如果是在0.5的位置上,则取该位置两侧值的平均数;如果是在0.25或0.75的位置上,则四分位数等于该位置的下侧值加上按比例分摊位置两侧数值的差值。
- 平均数
平均数也称为均值,它是一组数据相加后除以数据的个数得到的结果。
平均数在统计学中具有重要的地位.是集中趋势的最主要测度值,它主要适用于数值型数据,而不适用于分类数据和顺序数据。根据所掌握数据的不同,平均数有不同的计算形式和计算公式。
- 简单平均数
根据未经分组数据计算的平均数称为简单平均数。
设一组样本数据为为x1,x2,…,xn,样本量为n,则简单样本平均数的计算公式为:
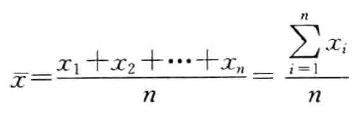
- 加权平均数
根据分组数据计算的平均数称为加权平均数。
设原始数据被分成k组,各组的组中值分别用M1,M2,…,Mk表示,各组变量值出现的频数分别f1,f2,…,fk表示,则样本加权平均数的计算公式为:
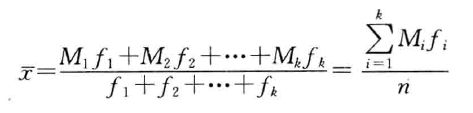
- 几何平均数
几何平均数,是n个变量值乘积的n次方根,用G表示。计算公式为:
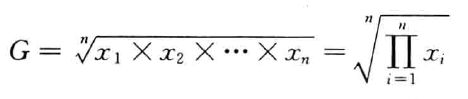
几何平均数是适用于特殊数据的一种平均数,它主要用于计算平均比率。
- 众数、中位数和平均数的比较
众数、中位数和平均数是集中趋势的三个主要测度值。
从分布的角度看,众数始终是一组数据分布的最高峰值,中位数是处于一组数据中间位置上的值,而平均数则是全部数据的算术平均。
不同分布下众数、中位数和平均数的情况:
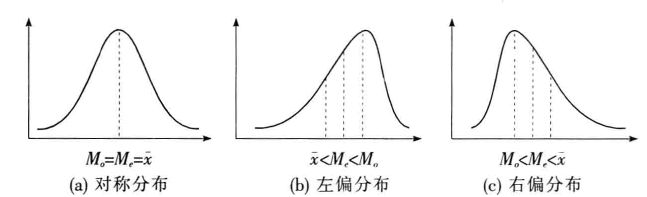
众数、中位数和平均数的特点与应用场合:
众数是一组数据分布的峰值,不受极端值的影响。其缺点是具有不唯一性,一组数据可能有一个众数,也可能有两个或多个众数,也可能没有众数。众数只有在数据量较多时才有意义,当数据量较少时,不宜使用众数。众数主要适合作为分类数据的集中趋势测度值。
中位数是一组数据中间位置上的代表值,不受数据极端值的影响。当一组数据的分布偏斜程度较大时,使用中位数也许是一个好的选择。中位数主要适合作为顺序数据的集中趋势测度值。
均数是针对数值型数据计算的,而且利用了全部数据信息,它是实际中应用最广泛的集中趋势测度值。当数据呈对称分布或接近对称分布时,3个代表值相等或接近相等,这时则应选择平均数作为集中趋势的代表值。但平均数的主要缺点是易受数据极端值的影响,对于偏态分布的数据,平均数的代表性较差。因此,当数据为偏态分布.特别是偏斜程度较大时,可以考虑选择中位数或众数,这时它们的于忆表性要比平均数好。
离散程度的度量
数据的离散程度是数据分布的另一个重要特征,它反映的是各变量值远离其中心值的程度。数据的离散程度越大,集中趋势的测度值对该组数据的代表性就越差;离散程度越小,其代表性就越好。
- 异众比率
异众比率是指非众数组的频数占总频数的比例,用Vr表示。
其计算公式为:

异众比率主要用于衡量众数对一组数据的代表程度。异众比率越大,说明非众数组的频数占总频数的比重越大,众数的代表性越差;异众比率越小,说明非众数组的频数占总频数的比重越小,众数的代表性越好。
- 四分位差
四分位差,也称为内距或四分间距,它是上四分位数与下四分位数之差,用 Q d Q_d Qd表示,其计算公式为:
Q d = Q U − Q L Q_d=Q_U-Q_L Qd=QU−QL
四分位差反映了中间50%数据的离散程度,其数值越小,说明中间的数据越集中;其数值越大,说明中间的数据越分散。四分位差不受极值的影响。
- 极差
一组数据的最大值与最小值之差称为极差,也称全距,用R表示。其计算公式为:
R = m a x ( x i ) − m i n ( x i ) R=max(x_i)-min(x_i) R=max(xi)−min(xi)
- 平均差
平均差也称平均绝对离差,它是各变量值与其平均数离差绝对值的平均数,用Md表示。
根据未分组数据计算平均差的公式为:
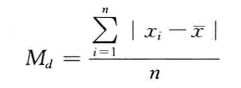
根据分组数据计算平均差的公式为:
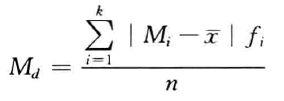
平均差以平均数为中心,反映了每个数据与平均数的平均差异程度,它能全面准确地反映一组数据的离散状况。平均差越大,说明数据的离散程度越大;反之,则说明数据的离散程度越小。
- 方差和标准差
方差是各变量值与其平均数离差平方的平均数。它在数学处理上是通过平方的办法消去离差的正负号,然后再进行平均。方差的平方根称为标准差。方差(或标准差)能较好地反映出数据的离散程度,是实际中应用最广的离散程度测度值。
设样本方差为s2,根据未分组数据和分组数据
计算样本方差的公式为:
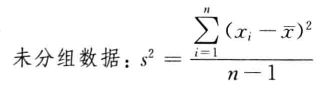
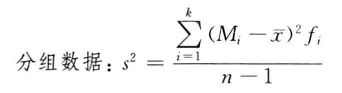
样本方差是用样本数据个数减1后去除离差平方和。其中样本数据个数减1即n-1称为自由度。
标准差的计算公式分别为:

- 离散系数
为消除变量值水平高低和计量单位不同对离散程度测度值的影响,需要计算离散系数。
离散系数也称为变异系数,它是一组数据的标准差与其相应的平均数之比。其计算公式为:

离散系数是测度数据离散程度的相对统计量,主要是用于比较不同样本数据的离散程度。离散系数大,说明数据的离散程度也大;离散系数小,说明数据的离散程度也小。
偏态与峰态的度量
集中趋势和离散程度是数据分布的两个重要特征,但要全面了解数据分布的特点,还需要知道数据分布的形状是否对称、偏斜的程度以及分布的扁平程度等。偏态和峰态就是对分布形状的测度。
- 偏态
偏态是对数据分布对称性的测度。测度偏态的统计量是偏态系数,记作SK。
未分组数据计算公式:

式中,s3是样本标准差的三次方。
分组数据计算公式:
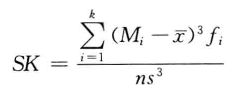
当SK为正值时,可以判断为正偏或右偏;反之,当SK为负值时,可判断为负偏或左偏。当分布对称时,SK=0。
- 峰态
峰态是对数据分布平峰或尖峰程度的测度。测度峰态的统计量是峰态系数,记作K。
峰态通常是与标准正态分布相比较而言的。如果一组数据服从标准正态分布,则峰态系数的值等于0;若峰态系数的值明显不等于0,则表明分布比正态分布更平或更尖,通常称为平峰分布或尖峰分布。
未分组数据计算公式:

分组数据计算公式:
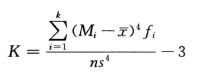
示中,S4是样本标准差的四次方。