python 机器学习之有监督学习(二)
对于那些特征和结果存在线性关系的分类问题可以使用线性分类器进行解决,对于那些不存在线性关系的就要采用这种非线性分类器进行解决了。非线性问题的解决方法也很多,总体上可以分为基于判别函数的和非基于判别函数的。
1、朴素贝叶斯分类器
1.1、模型解释:构造基础为贝叶斯理论

总体的说,朴素贝叶斯会单独考量每一维度特征被分类的条件概率,进而整合这些概率并对其所在的特征向量做出分类预测。这个模型的假设为各个维度上的特征被分类的概率之间是互相独立的。一句话讲就是找到使其找到一个类别,使其后验概率取到最大。
1.2、python 应用实例
- 数据说明:朴素贝叶斯在文本的分类问题、垃圾邮箱的筛选问题等有着很大的用途。下面这个例子,就是用本模型对新闻文本分类
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 27 19:08:29 2017
@author: mynumber
"""
#sklearn.datasets导入新闻数据抓取器fetch_20newsgroups
from sklearn.datasets import fetch_20newsgroups
#用于对数据进行切割
from sklearn.cross_validation import train_test_split
#导入文本特征向量转化模块
from sklearn.feature_extraction.text import CountVectorizer
#导入朴素贝叶斯模型
from sklearn.naive_bayes import MultinomialNB
#对分类结果做性能报告
from sklearn.metrics import classification_report
#需要从网上实时下载数据
news=fetch_20newsgroups(subset='all')
print(len(news.data))
print(news.data[0])
#数据切割,25%的样本数据做为测试集
x_train,x_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25,random_state=33)
#初始化特征提取转化器
vec=CountVectorizer()
x_train=vec.fit_transform(x_train)
x_test=vec.transform(x_test)
#贝叶斯决策进行训练、测试
mnb=MultinomialNB()
mnb.fit(x_train,y_train)
y_predict=mnb.predict(x_test)
#输出精确率、召回率、和支持率、及F-1评分
print('The accuracy of Native Bayes Classification is',mnb.score(x_test,y_test))
print(classification_report(y_test,y_predict,target_names=news.target_names))
#结果如下:
The accuracy of Native Bayes Classification is 0.839770797963
precision recall f1-score support
alt.atheism 0.86 0.86 0.86 201
comp.graphics 0.59 0.86 0.70 250
comp.os.ms-windows.misc 0.89 0.10 0.17 248
comp.sys.ibm.pc.hardware 0.60 0.88 0.72 240
comp.sys.mac.hardware 0.93 0.78 0.85 242
comp.windows.x 0.82 0.84 0.83 263
misc.forsale 0.91 0.70 0.79 257
rec.autos 0.89 0.89 0.89 238
rec.motorcycles 0.98 0.92 0.95 276
rec.sport.baseball 0.98 0.91 0.95 251
rec.sport.hockey 0.93 0.99 0.96 233
sci.crypt 0.86 0.98 0.91 238
sci.electronics 0.85 0.88 0.86 249
sci.med 0.92 0.94 0.93 245
sci.space 0.89 0.96 0.92 221
soc.religion.christian 0.78 0.96 0.86 232
talk.politics.guns 0.88 0.96 0.92 251
talk.politics.mideast 0.90 0.98 0.94 231
talk.politics.misc 0.79 0.89 0.84 188
talk.religion.misc 0.93 0.44 0.60 158
avg / total 0.86 0.84 0.82 4712总结:朴素贝叶斯模型广泛的用到互联网的文本分类问题,由于较强的特征条件独立假设,使得模型效率极高,极大的节省了内存消耗。但是,正因为存在着这种假设,使得在解决那些关联性较强的问题时效果不佳。
2、决策树
2.1、模型解释: 决策树通常用来解决非线性分类问题
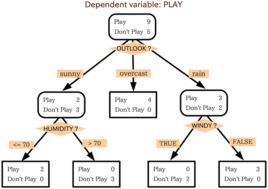
如图,通过一定的策略构建数的节点,每个叶节点代表一个决策结果,节点与节点之间的路径为决策的条件。节点的策略主要有信息熵(Entropy),基尼不纯性(Gini)。决策树的质量与生成节点的策略有很大的关联。
2.2、python 应用实例
- 数据说明:决策树通常用来解决评判用户信用问题,和多分类的问题。下面的例子就展示了使用决策树来预测泰坦尼克号的生还概率。
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 28 11:18:23 2017
@author: mynumber
"""
import pandas as pd
#用于数据切割
from sklearn.cross_validation import train_test_split
#用于将数据剥离
from sklearn.feature_extraction import DictVectorizer
#导入决策树
from sklearn.tree import DecisionTreeClassifier
#用于对决策结果进行评价
from sklearn.metrics import classification_report
#使用pandas的read_csv 从网上获取资源
titanic=pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#输出部分数据进行查看
print(titanic.head())
print(titanic.info())
#将各类数据(不同标签)剥离出来
x=titanic[['pclass','age','sex']]
y=titanic['survived']
print(x.info())
x['age'].fillna(x['age'].mean(),inplace=True)
print(x.info())
#将数据进行切割
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25,random_state=33)
vec=DictVectorizer(sparse=False)
x_train=vec.fit_transform(x_train.to_dict(orient='record'))
print(vec.feature_names_)
#对测试数据进行特征剥离
x_test=vec.transform(x_test.to_dict(orient='record'))
dtc=DecisionTreeClassifier()
dtc.fit(x_train,y_train)
y_predict=dtc.predict(x_test)
#输出对决策的评价
print('the accuracy of DTC is',dtc.score(x_test,y_test))
print(classification_report(y_test,y_predict,target_names=['died','survived']))
总结而言,决策树在模型描述上有着巨大的优势。决策树的推断逻辑非常直观,解释性很强,而且在使用模型时,无须考虑对数据的标准化,这些都使得决策树应用很广。
单一的决策树有时无法达到很好的效果,这时可以考虑使用随机森林,这是在同一数据集上搭建多颗决策树;也可以使用梯度提升决策树。
因此对于有监督的分类问题,我们学习了这些模型,我们可以使用的模型也有很多,但是每个模型都有着不同的优势和应用范围,到底应该使用哪一种模型,这就需要读者自己多多分析、多多领悟。