YOLO初体验
用tensorflow玩了玩Faster-RCNN,都说YOLO用起来更爽,也玩了玩YOLO,确实爽,这边做个入门的Demo~
目录:
1、环境搭建
2、数据准备
3、训练
4、测试
一、环境搭建
操作系统:Ubuntu16.04
GPU:GTX1080ti x 4
CUDA:V8.0.61
cudnn:V5.1.10
自行安装~
下载yolo3项目(自己找个位置放):
git clone https://github.com/pjreddie/darknet
cd darknet
修改makefile配置(在darknet文件夹下):
GPU=1 #如果使用GPU设置为1,CPU设置为0
CUDNN=0 #如果使用CUDNN设置为1,否则为0
OPENCV=0 #如果调用摄像头,还需要设置OPENCV为1,否则为0
OPENMP=0 #如果使用OPENMP设置为1,否则为0
DEBUG=0 #如果使用DEBUG设置为1,否则为0
CC=gcc
NVCC=nvcc #修改为自己的路径
AR=ar
ARFLAGS=rcs
OPTS=-Ofast
LDFLAGS= -lm -pthread
COMMON= -Iinclude/ -Isrc/
CFLAGS=-Wall -Wno-unused-result -Wno-unknown-pragmas -Wfatal-errors -fPIC
...
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/usr/local/cuda/include/
CFLAGS+= -DGPU
LDFLAGS+= -L/usr/local/cuda/lib64 -lcuda -lcudart -lcublas -lcurand
endif
然后保存,make一下~
接下来安装一下opencv包吧~
参考:
https://blog.csdn.net/zzyczzyc/article/details/84193696
二、数据准备
首先要有标注过的图片吧,网上大多教程都用VOC数据集,我这里用的不是VOC,也是网上找的小数据集,下载链接:
链接: https://pan.baidu.com/s/1T2v88vaQ34nII6ikmf5gww 提取码: jazm
数据长这样子:

那先来讲讲yolo的标注软件吧,这里用的是yolo_mark~
教程一大堆:
可参考:https://blog.csdn.net/heiheiya/article/details/83506913
其中说到的“配置正确的opencv包含目录和库目录”,如果没配置编译的时候会报如下错误:
无法打开源文件: “opencv2/opencv.hpp”
这时参考这个博客可解决:
https://www.cnblogs.com/aiguona/p/9370433.html
注意,博客里面是debug的,我们要用x64 release的~
vs2015破解:https://blog.csdn.net/qq_19678579/article/details/76692822
按照教程即可打开已标注的图片啦~
如下图:
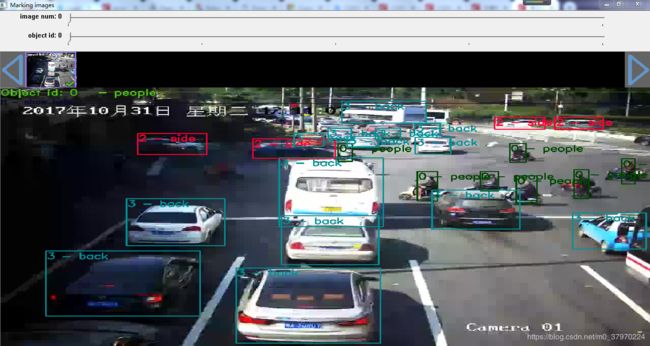
分4类
people:行人
front:车的前边
side:车的侧边
back:车的后边
对,还有一个它的标注文件长这样:
一张图片对应一个txt文件,一个txt文件包含多个object
以相对坐标给出~
举个例子吧
下图是用labelImg软件标注出来行人的坐标,xml的那种形式
对应的xml文件如下:

这边得到几个有用的信息:
目标物四至坐标:

图片长、宽:
![]()
好嘞~,根据公式开始换算成yolo3的那种txt形式:
先看txt想要什么,如下:

那来换算一下呗~
中心点 = (Xmin + 1/2(Xmax - Xmin),Ymin + 1/2(Ymax - Ymin)) = (671,582)

可以计算一下。
可参考这个示意图
https://blog.csdn.net/qq_34806812/article/details/82355614
yolo_mark的一些快捷键:

三、训练
有了数据,那就开始来训练吧~
上面已经下载了darknet,然后也修改了makefile
我们再下载下预训练权重吧
wget https://pjreddie.com/media/files/yolov3.weights
wget https://pjreddie.com/media/files/yolov3-tiny.weights
wget https://pjreddie.com/media/files/darknet53.conv.74
看要用哪一个,这里是用最后一个darknet53.conv.74
接下来,有了数据,有了预训练权重,那就来设计下怎么训练呗,也就是你想设置模型的参数
有个很重要的文件就是.cfg文件
.cfg文件:
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 50200
policy=steps
steps=40000,45000
scales=.1,.1
.................................
根据需要来设置吧
包括初始学习率、学习率衰减率,batch、step及各层参数…
详细参见:https://blog.csdn.net/ll_master/article/details/81487844
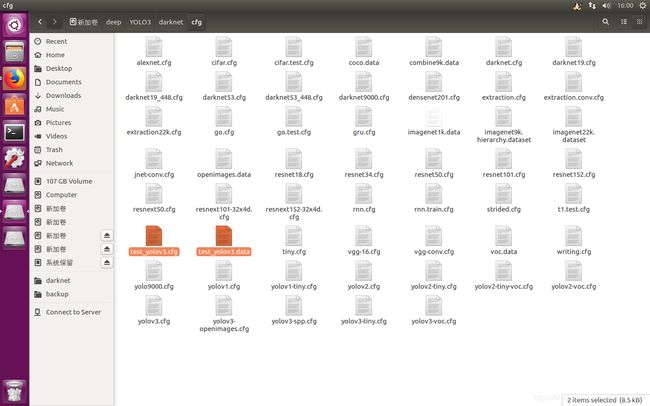
设置完后还要有个.data结尾的配置文件

好,最后把这两个文件放在darknet下面的cfg文件夹里面(名字自个取,如test_yolo3.cfg和test_yolo3.data)
 然后开始训练吧~
然后开始训练吧~
命令如下:
sudo ./darknet detector train cfg/test_yolov3.data cfg/test_yolov3.cfg darknet53.conv.74
//mutil gpu
sudo ./darknet detector train cfg/test_yolov3.data cfg/test_yolov3.cfg /home/adminroot/test/backup/test_yolov3_700.weights -gpus 0,1,2,3
//恢复训练
sudo ./darknet detector train cfg/test_yolov3.data cfg/test_yolov3.cfg /home/adminroot/test/backup/test_yolov3.backup -gpus 0,1
训练日志说明:
https://blog.csdn.net/qq_33444963/article/details/80842179
四、测试
最后测试一张图片:
//test pic
sudo ./darknet detector test cfg/test_yolov3.data cfg/test_yolov3.cfg backup/my_yolov3_900.weights /home/adminroot/Desktop/jam1_0001.jpg

最后视频:
//test mp4
sudo ./darknet detector demo cfg/test_yolov3.data cfg/test_yolov3.cfg backup/my_yolov3_900.weights /home/adminroot/test/data/test.mp4
附:可能出现的问题

参考:https://blog.csdn.net/qq_34806812/article/details/81537842
参考:
https://blog.csdn.net/lixiaoyu101/article/details/86537128
https://blog.csdn.net/lilai619/article/details/79695109