Linux的基本学习(十一)——磁盘配额 与 磁盘阵列
前言:
承接前面的内容来继续学习Linux
磁盘配额(Quota)的应用于实践
磁盘配额
由于Linux系统是多人多任务的环境,所以会有多人共同使用一个磁盘空间的情况发生。如果其中有少数几个用户大量地占用了硬盘空间的话,那势必压缩其他用户的使用权力。因此管理员应该限制用户的硬盘容量,以妥善分配系统资源,避免有人抗议。
举例来说,用户的默认家目录都是在/home下面,如果/home是一个独立的分区,假设这个分区有10GB,而/home下面共有30个账号,也就是说,每个用户平均应该会有333MB的空间才对。偏偏有个用户在它的家目录放了很多影片,一个人占用了8G,这就很不合理了。
如果想要让磁盘的容量公平分配,这个时候就要靠磁盘配额帮忙。
磁盘配额的一般用途
比较常用磁盘配额的几种情况是:
- 针对网站服务器,例如:每个人的网页空间容量限制
- 针对邮件服务器,例如:每个人的邮件空间限制
- 针对文件服务器,例如:每个人最大的可用网络硬盘空间
这些是针对网络服务的设计,如果是针对Linux系统主机上面的设置,那么使用的地方有下面这些:
- 限制某一用户组所能使用的最大磁盘配额(使用用户组限制)
- 限制某一用户的最大磁盘配额(使用用户限制)
- 限制某一目录的最大磁盘配额
基本上,磁盘配额就是为管理员提供磁盘使用率以及让管理员管理磁盘使用情况的一个工具。比较特别的是,xfs的磁盘配额是整合到文件系统内的,并不是其他外置的程序来管理的,因此通过磁盘配额来直接报告磁盘使用率,要比UNIX工具快很多,比如命令du可以重新计算目录下的磁盘使用率,但xfs可以通过xfs_quota来直接报告各目录的使用率,速度会快很多。
磁盘配额的使用限制
- ext文件系统仅能针对整个文件系统,不能针对某个单一的目录来设置磁盘配额。
- 内核必须支持磁盘配额
- 磁盘配额仅对一般用户有效
- 若启用SELinux,非所有目录均可设置磁盘配额
新版的CentOS都支持SELinux这个内核功能,该功能会加强某些特殊的权限控制。所以即使你是xfs文件系统,可能很多文件目录你也不能设置磁盘配额。
磁盘配额的规范设置选项
磁盘配额这玩意儿针对xfs文件系统的限制选项主要分为下面几个部分:
- 分别针对用户、用户组或个别目录(user、group、project):xfs文件系统的磁盘配额中,主要是针对用户、用户组、个别目录进行磁盘使用率的限制。
- 容量限制或文件数量限制(block或inode):文件系统主要规划为存放属性的inode与实际文件数据的block区块,磁盘配额既然是管理文件系统,所以当然也可以管理inode或block,这两个管理的功能为
- 限制inode使用量:管理用户可以建立的【文件数量】
- 限制block使用量:管理用户磁盘容量的限制,这种方式较为常见
- 软限制与硬限制(soft/hard):既然是规范,当然就有限制值。不管inode还是block,限制值都有两个,分别是soft与hard。通常hard限制值要比soft还要高。这两个限制值的意义为:
- hard:表示用户的使用量绝对不会超过这个限制值,以上面的设置为例,用户所能使用的磁盘容量绝对不会超过500MB,若超过这个值则系统会锁定该用户的磁盘使用权。
- soft:表示用户在低于soft限值时(此例中为400MB),可以正常使用磁盘,但超过soft但低于hard的限值,每次用户登录时,系统会主动发出磁盘容量即将耗尽的警告,并给与一个宽限时间(grace time)。不过,若用户在宽限时间倒数期限就将容量再次降低与soft之下,则宽限时间会停止。
- 回倒数计时的宽限时间:一般默认的宽限时间是七天,如果七天内你都不进行任何磁盘管理,那么soft限制值会即将替换hard限制值来作为磁盘配额的配置。
一个xfs文件系统的磁盘配额实践范例
- 目的与账号:现在我想要让我的实习生五个为一组,这五个用户的账号都是 myquota1、myquota2、myquota3、myquota4、myquota5,这五个用户的密码都是 passwd ,且这五个用户所属的初始用户组都是 myquotagrp,其他账号的属性使用默认值。
- 账号的磁盘容量限制值:我想让五个用户都能够获得300MB的磁盘使用量(hard),文件数量不做限制。此外,只要容量使用超过250MB,就予以警告(soft)。
- 用户组的配额(option1):由于我的系统里面还有其他用户存在,因此我仅承认 myquotagrp 这个用户组最多使用 1GB 的容量。
- 共享目录配额(option2):另一种设置方式,每个用户还是具有自己独特的容量限制,但是五个人的实习共享目录在 /home/myquota 里面这里,该目录设置为其他人没有任何权限的共享目录空间,仅有 myquotagrp 用户组拥有全部的权限。且无论如何该目录最多仅能够接受 500MB的容量。请注意,用户组(group)与目录(directory/project)的限制无法同时并存。
- 宽限时间的限制:最后,我希望每个用户在超过soft限制值后,都还能够有14天的宽限时间。
在这一小节咱们先来创建这五个实习生的账号

2770不知道是什么?复习一下这篇文章吧!

下面我们正式开始磁盘配额的练习
实践磁盘配额流程-1:文件系统的支持与查看
对于单个文件或目录,如果要设置磁盘配额,请注意文件系统要是xfs。
此外,不要在根目录下面进行磁盘配额设置,因为文件系统会变的太复杂。
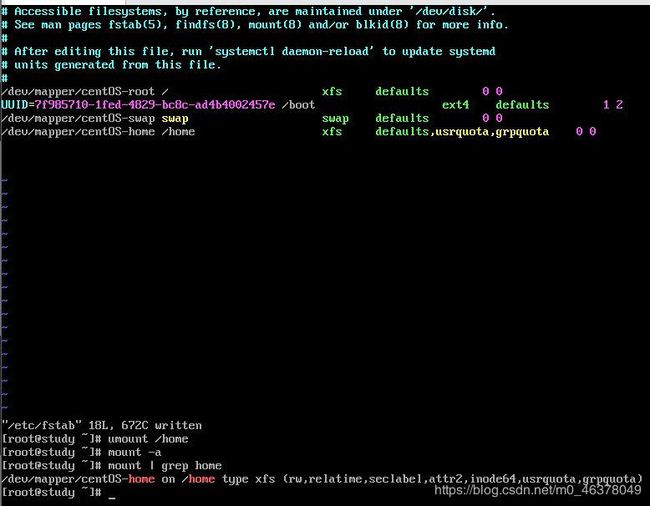
因此,我们是以/home 这个xfs文件系统为例。使用df来检查看看。

-h :以人们较易阅读的 GBytes, MBytes, KBytes 等格式自行显示;
-T :连同该硬盘分区的文件系统名称 (例如 xfs) 也列出;在过去的版本中,管理员似乎可以通过 mount -o remount 的机制来重新挂载启动磁盘配额功能,不过xfs文件文件系统的磁盘配额似乎是在挂载之初就声明了,因此无法使用remount来重新启动磁盘配额功能,一定得要写入/etc/fstab (设置启动挂载的系统配置文件)当中,或是在初始挂载过程中加入这个选项,否则不会生效。

基本上,针对磁盘配额限制的主要选项主要有三项:
- uquota/usrquota/quota:针对用户账号的设置
- gquota/grpquota:针对用户组的设置
- pquota/prjquota:针对单一目录的设置,但是不可与 grpquota 同时存在
再次强调,修改/etc/fstab后,务必要测试一下。若发生错误就要赶紧处理。因为这个文件如果修改错误,是会造成无法启动的情况。此外,由于一般用户的家目录是在/home目录下,因此删除这个选项时,一定要将一般账号的身份注销,否则肯定无法删除。
实践磁盘配额流程-2:查看磁盘配额报告数据
设置文件系统支持之后,当然得要来看一看到底有没有正确地将磁盘配额的管理数据列出来才好,这时我们得要使用 xfs_quota 这个命令。里面参数很多,不过稍微查看一下即可。先让我们来查看目前磁盘配额的设置信息。
xfs_quota -x -c “命令” [挂载点]
-x:专家模式,后续才能够加入-c的命令参数
-c:后面就是命令,这个小节我们先来谈谈数据报告的命令
命令:
print:单纯地列出目前主机内的文件系统参数等数据
df:与原本的df,可以加上-b(block)、-i(inode)、-h(加上单位)等
report:列出目前的磁盘配额选项、有-ugr(user、group、project )及 -bi 等
state:说明目前支持磁盘配额的文件系统的信息,有没有使用相关选项等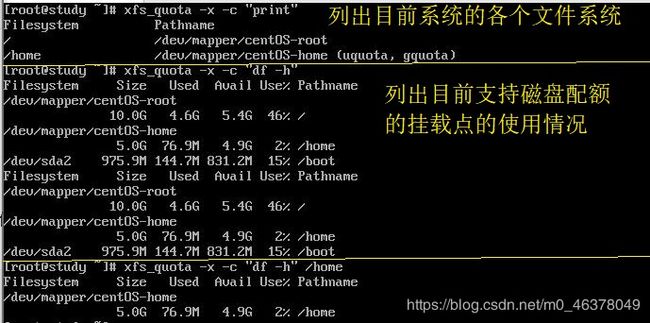

上面的report加上了u,就是让它只列出用户的限制信息,如果不加,它会将支持的user、group、directory相关信息显示出来。
实践磁盘配额流程-3:限制值设置方式
确认文件系统的磁盘配额支持顺利启用后,也能够查看到相关的磁盘配额限制,接下来就是要实际设置用户或用户组限制。回去看看,我们需要每个用户 250MB/300MB 的容量限制,用户组共 950MB/1GB 的容量限制,同时 grace time设置为14天。
xfs_quota -x -c "limit [-ug] b[soft|hard]=N i[soft|hard]=N name"
xfs_quota -x -c "timer [-ug] [-bir] Ndags"
limit:实际限制的选项,可以针对 user/group 来限制,限制的选项有以下内容:
bsoft/bhard:block的soft/hard 限制值,可以加单位
isoft/ihard:inode的soft/hard 限制值。
name:就是用户/用户组的名称
timer:用来设置grace time的选项,也是可以针对 user/group 以及 block/inode 设置。设置用户限制(示例中那里是ubih,写成n了,对不住)

设置用户组限制
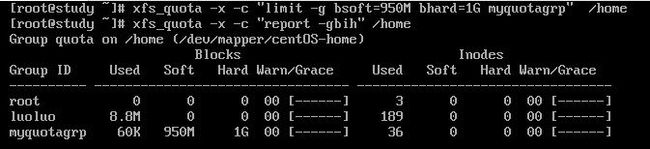
设置grace time(限制时间)
xfs_quota -x -c "timer -u -b 14days" /home
xfs_quota -x -c "timer -g -b 14days" /home测试一下:

实践磁盘配额流程-4:project的限制(针对目录限制)
如果限制的是目录而不是用户组时,那该如何处理呢?
要注意限制的是/home/myquota这个目录本身,而不是针对myquotagrp 这个组。这两种设置方法的意义不同。
例如,以前一个小节谈到的测试范例来说,myquota1已经使用了300MB的容量,而/home/myquota其实还没有任何的使用量(因为是在myquota1的家目录做的dd命令)。不过如果你使用了xfs_quota -x -c “report -h” /home 这个命令来查看,就会发现其实 myquotagrp 已经用掉了300MB,如此一来,对于目录的限制来说,就不会有效果。
为了解决这个问题,我们这个小节来设置project选项,注意这个选项不可以与 group 同时设置,因此我们需要先取消掉group设置然后再加入project设置,下面我们实验看看:
首先,要将grpquota的参数取消,然后加入prjquota,并且卸载/home再重新挂载。
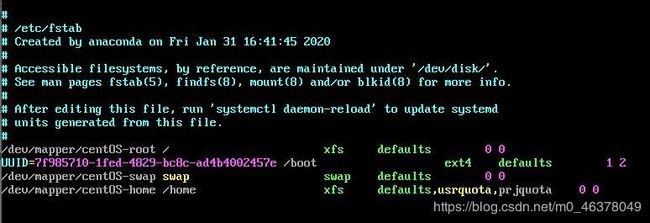

mount -a
依照配置文件 [/etc/fstab]的数据将所有未挂载的磁盘都挂载上来然后,规范目录、选项名称(Project)与选项ID
目录的配置比较奇怪,它必须要指定一个所谓的【选项名称、选项标识符】来规范才行,而且还需要用到两个配置文件。
现在,我们要规范的目录是/home/myquota,其选项名称为muquotaproject的选项名称,其标识符为11,这些都是自己指定的,若不喜欢可以指定另外一个。

接下来我们来进行设置,/home/myquota 指定为450/500MB的容量限制

我就不测试了,总之后面连root在该目录下建立文件都会受到限制。
这样就设置好了,未来你还要针对某些目录进行限制,那么就修改/etc/projects、/etc/projid的配置,然后直接处理目录的初始化与设置,就完成了设置。
xfs磁盘配额的管理与额外命令对照表
不管多么完美的系统,都要为可能的突发情况准备应对方案。所以,接下来我们就来谈一谈,万一需要暂停磁盘配额的限制,或是需要重新启动磁盘配额的限制时,该如何处理?还是使用xfs_quota,使用下面几个内部命令即可:
- disable:暂时取消磁盘配额的限制,但其实系统还是在计算磁盘配额中,只是没有管制而已,应该算是最有用的功能。
- enable:就是恢复到正常管制的状态中,与disable可以互相取消、启用
- off:完全关闭磁盘配额的限制,使用了这个状态后,你只有卸载再重新挂载才能够再次启动磁盘配额。也就是说,用了off状态后,你无法使用enable再次恢复磁盘配额的管制。注意不要乱用这个状态,一般建议用disable即可,除非你需要执行remove操作。
- remove:必须要在off的状态下才能够执行的命令。这个remove命令可以【删除】磁盘配额的限制设置,例如要取消project的设置,无需重新设置为0,只需要remove -p即可。
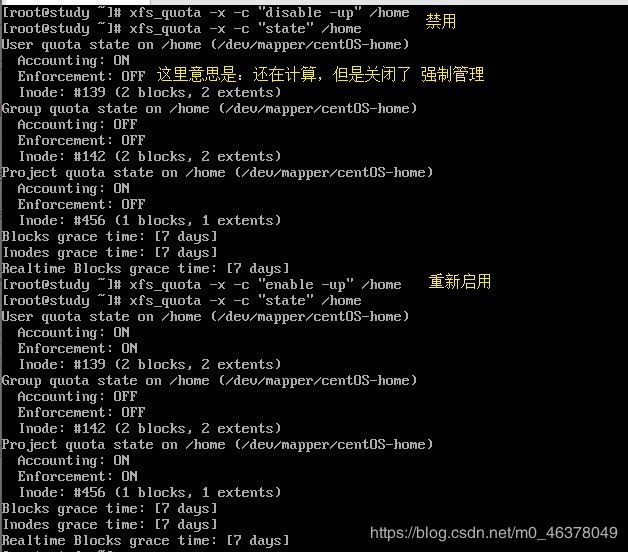


最后一个“remove -p” 会删除掉/home下面的所有project配额限制,无法恢复。
| 设定流程项目 | XFS 文件系统 | EXT 家族 |
|---|---|---|
| /etc/fstab 参数设定 | usrquota/grpquota/prjquota | usrquota/grpquota |
| quota 配置文件 | 不需要 | quotacheck |
| 设定用户/群组限制值 | xfs_quota -x -c “limit…” | edquota 或 setquota |
| 设定 grace time | xfs_quota -x -c “timer…” | edquota |
| 设定目录限制值 | xfs_quota -x -c “limit…” | 无 |
| 观察报告 | xfs_quota -x -c “report…” | repquota 或 quota |
| 启动与关闭 quota 限制 | xfs_quota -x -c “[disable|enable]…” | quotaoff, quotaon |
| 发送警告信给用户 | 目前版本尚未支持 | warnquota |
不修改既有系统的磁盘配额实例
想一想,如果你的主机原先没有想到要设定成为邮件主机,所以并没有规划将邮件信箱所在的 /var/spool/mail/ 目录独立成为一个 分区,而目前你的主机已经没有办法新增或分区出任何新 的分区了。我们知道 quota 的支持与文件系统有关, 所以并无法跨文件系统来设计 quota 的 project 功能啊!因此,你是否就无法针对 mail 的使用量给予 quota 的限制呢?
如果你想要让使用者的邮件信箱与家目录的总体磁盘使用量为固定,那又该如何是好? 由于 /home 及 /var/spool/mail 根本不可能是同一个 filesystem (除非是都不分区,使用根目录,才有可能 整合在一起), 所以,该如何进行这样的 quota 限制呢?
既然 quota 是针对 filesystem 来进行限制,假设你又已经有 /home 这个独立的分区槽了,那么你只要:
- 将 /var/spool/mail 这个目录完整的移动到 /home 底下;
- 利用 ln -s /home/mail /var/spool/mail 来建立链接数据;
- 将 /home 进行 quota 限额设定
您也可以依据不同的使 用者与群组来设定 quota 然后同样的以上面的方式来进行 link 的动作!嘿嘿嘿!就有不同的限额针 对不同的使用者提出啰!
软件磁盘阵列(Software RAID)
什么是RAID
磁盘阵列全名是【Redundant Arrays of Inexpensive Disks ,RAID】,中文意思是 独立冗余磁盘阵列。RAID 可以通过技术(软件或硬件)将多个较小的磁盘整合成为一个较大的磁盘设备,而这个较大的磁盘功能可不止存储而已,他还具有保护数据的功能。整个RAID由于选择的级别(level)不同,而使得整合后的磁盘具有不同的功能,基本常见的level有这几种:
RAID 0(等量模式,stripe):性能最佳
这种模式如果使用相同型号与容量的磁盘来组成时,效果较佳。这种模式的RAID会将磁盘先切出等量的数据块(名为chunk,一般可设置为4KB~1MB),然后当一个文件要写入RAID时,该文件会根据chunk的大小切割好,之后再依序放到各个磁盘里去。由于每个磁盘会交错地存放数据,因此当你的数据要写入RAID时,数据会被等量地放置在各个磁盘上面。举例来说,你有两颗磁盘组成 RAID-0 , 当你有 100MB 的数据要写入时,每个磁盘会各被分配到 50MB 的储存量。RAID-0 的示意图如下所示:

上图的意思是,在组成 RAID-0 时,每颗磁盘 (Disk A 与 Disk B) 都会先被区隔成为小区块 (chunk)。 当有数据要写入 RAID 时,数据会先被切割成符合小区块的大小,然后再依序一个一个的放置到不同的磁盘去。 由于数据已经先被切割并且依序放置到不同的磁盘上面,因此每颗磁盘所负责的数据量都降低了!照这样的情况来看, 越多颗磁盘组成的 RAID-0 性能会越好,因为每颗负责的数据量就更低了! 这表示我的数据可以分散让多颗磁盘来储存,当然性能会变的更好啊!此外,磁盘总容量也变大了! 因为每颗磁盘的容量最终会加总成为 RAID-0 的总容量喔!
只是使用此等级,你必须要自行负担数据损毁的风险,由上图我们知道文件是被切割成为适合每颗磁盘分区区块的大小, 然后再依序放置到各个磁盘中。想一想,如果某一颗磁盘损毁了,那么文件数据将缺一块,此时这个文件就损毁了。 由于每个文件都是这样存放的,因此 RAID-0 只要有任何一颗磁盘损毁,在 RAID 上面的所有数据都会遗失而无法读取。
另外,如果使用不同容量的磁盘来组成 RAID-0 时,由于数据是一直等量的依序放置到不同磁盘中,当小容量磁盘的区块被用完了, 那么所有的数据都将被写入到最大的那颗磁盘去。举例来说,我用 200G 与 500G 组成 RAID-0 , 那么最初的 400GB 数据可同时写入两颗磁盘 (各消耗 200G 的容量),后来再加入的数据就只能写入 500G 的那颗磁盘中了。 此时的性能就变差了,因为只剩下一颗可以存放数据嘛!
RAID 1(镜像模式,mirror):完整备份
这种模式也是需要相同的磁盘容量的,最好是一模一样的磁盘啦!如果是不同容量的磁盘组成 RAID-1 时,那么总容量将以最小的那一颗磁盘为主!这种模式主要是“让同一份数据,完整的保存在两颗磁盘上头”。举例来说,如果我有一个 100MB 的文件,且我仅有两颗磁盘组成 RAID-1 时, 那么这两颗磁盘将会同步写入 100MB 到他们的储存空间去。 因此,整体 RAID 的容量几乎少了 50%。由于两颗硬盘内容一模一样,好像镜子映照出来一样, 所以我们也称他为 mirror 模式啰~

如上图所示,一份数据传送到 RAID-1 之后会被分为两股,并分别写入到各个磁盘里头去。 由于同一份数据会被分别写入到其他不同磁盘,因此如果要写入 100MB 时,数据传送到 I/O 总线后会被复制多份到各个磁盘, 结果就是数据量感觉变大了!因此在大量写入 RAID-1 的情况下,写入的性能可能会变的非常差 (因为我们只有一个南桥啊!)。 好在如果你使用的是硬件 RAID (磁盘阵列卡) 时,磁盘阵列卡会主动的复制一份而不使用系统的 I/O 总线,性能方面则还可以。 如果使用软件磁盘阵列,可能性能就不好了。
由于两颗磁盘内的数据一模一样,所以任何一颗硬盘损毁时,你的数据还是可以完整的保留下来的! 所以我们可以说, RAID-1 最大的优点大概就在于数据的备份吧!不过由于磁盘容量有一半用在备份, 因此总容量会是全部磁盘容量的一半而已。虽然 RAID-1 的写入性能不佳,不过读取的性能则还可以啦!这是因为数据有两份在不同的磁盘上面,如果多个 processes(进程) 在读取同一笔数据时, RAID 会自行取得最佳的读取平衡。
RAID 1+0,RAID 0+1
RAID-0 的性能佳但是数据不安全,RAID-1 的数据安全但是性能不佳,那么能不能将这两者整合起来设置 RAID 呢? 可以啊!那就是 RAID 1+0 或 RAID 0+1。所谓的 RAID 1+0 就是: (1)先让两颗磁盘组成 RAID 1,并且这样的设置共有两组; (2)将这两组 RAID 1 再组成一组 RAID 0。这就是 RAID 1+0 啰!反过来说,RAID 0+1 就是先组成 RAID-0 再组成 RAID-1 的意思。
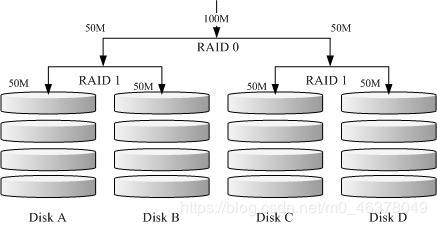
如上图所示,Disk A + Disk B 组成第一组 RAID 1,Disk C + Disk D 组成第二组 RAID 1, 然后这两组再整合成为一组 RAID 0。如果我有 100MB 的数据要写入,则由于 RAID 0 的关系, 两组 RAID 1 都会写入 50MB,又由于 RAID 1 的关系,因此每颗磁盘就会写入 50MB 而已。 如此一来不论哪一组 RAID 1 的磁盘损毁,由于是 RAID 1 的图像数据,因此就不会有任何问题发生了!这也是目前储存设备厂商最推荐的方法!
Tips 为何会推荐 RAID 1+0 呢?想像你有 20 颗磁盘组成的系统,每两颗组成一个 RAID1,因此你就有总共 10组可以自己复原的系统了! 然后这 10组再组成一个新的 RAID0,速度立刻拉升 10倍了!同时要注意,因为每组 RAID1 是个别独立存在的,因此任何一颗磁盘损毁, 数据都是从另一颗磁盘直接复制过来重建,并不像 RAID5/RAID6 必须要整组 RAID 的磁盘共同重建一颗独立的磁盘系统!性能上差非常多! 而且 RAID 1 与 RAID 0 是不需要经过计算的 (striping) !读写性能也比其他的 RAID 等级好太多了!
RAID 5:性能与数据备份的均衡考虑
RAID-5 至少需要三颗以上的磁盘才能够组成这种类型的磁盘阵列。这种磁盘阵列的数据写入有点类似 RAID-0 , 不过每个循环的写入过程中 (striping),在每颗磁盘还加入一个奇偶校验数据 (Parity) ,这个数据会记录其他磁盘的备份数据, 用于当有磁盘损毁时的救援。RAID-5 读写的情况有点像下面这样:
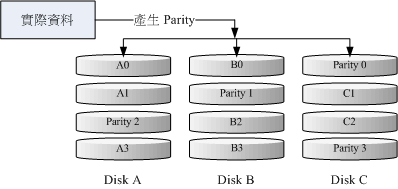
如上图所示,每个循环写入时,都会有部分的奇偶校验值(parity) 被记录起来,并且每次都记录在不同的磁盘, 因此,任何一个磁盘损毁时都能够借由其他磁盘的检查码来重建原本磁盘内的数据!不过需要注意的是, 由于有奇偶校验值,因此 RAID 5 的总容量会是整体磁盘数量减一块。以上图为例, 原本的 3 块磁盘只会剩下 (3-1)=2 颗磁盘的容量。而且当损毁的磁盘数量大于等于两颗时,这整组 RAID 5 的数据就损毁了。 因为 RAID 5 默认仅能支持一颗磁盘的损毁情况。
在读写性能的比较上,读取的性能还不赖!与 RAID-0 有的比!不过写的性能就不见得能够增加很多! 这是因为要写入 RAID 5 的数据还得要经过计算奇偶校验值(parity) 的关系。由于加上这个计算的动作, 所以写入的性能与系统的硬件关系较大!尤其当使用软件磁盘阵列时,奇偶校验是通过 CPU 去计算而非专职的磁盘阵列卡, 因此性能方面还需要评估。
另外,由于 RAID 5 仅能支持一颗磁盘的损毁,因此近来还有发展出另外一种等级,就是 RAID 6 ,这个 RAID 6 则使用两颗磁盘的容量作为 parity 的储存,因此整体的磁盘容量就会少两颗,但是允许出错的磁盘数量就可以达到两颗了! 也就是在 RAID 6 的情况下,同时两颗磁盘损毁时,数据还是可以救回来!
Spare Disk:热备份磁盘
当磁盘阵列的磁盘损毁时,就得要将坏掉的磁盘拔除,然后换一颗新的磁盘。换成新磁盘并且顺利启动磁盘阵列后, 磁盘阵列就会开始主动的重建 (rebuild) 原本坏掉的那颗磁盘数据到新的磁盘上!然后你磁盘阵列上面的数据就复原了! 这就是磁盘阵列的优点。不过,我们还是得要动手拔插硬盘,除非你的系统有支持热插拔,否则通常得要关机才能这么做。
为了让系统可以实时的在坏掉硬盘时主动的重建,因此就需要预备磁盘 (spare disk) 的辅助。 所谓的 spare disk 就是一颗或多颗没有包含在原本磁盘阵列等级中的磁盘,这颗磁盘平时并不会被磁盘阵列所使用, 当磁盘阵列有任何磁盘损毁时,则这颗 spare disk 会被主动的拉进磁盘阵列中,并将坏掉的那颗硬盘移出磁盘阵列! 然后立即重建数据系统。如此你的系统则可以永保安康啊!若你的磁盘阵列有支持热插拔那就更完美了! 直接将坏掉的那颗磁盘拔除换一颗新的,再将那颗新的设置成为 spare disk ,就完成了!
举例来说,鸟哥之前所待的研究室有一个磁盘阵列可允许 16 颗磁盘的数量,不过我们只安装了 10 颗磁盘作为 RAID 5。 每颗磁盘的容量为 250GB,我们用了一颗磁盘作为 spare disk ,并将其他的 9 颗设置为一个 RAID 5, 因此这个磁盘阵列的总容量为: (9-1)*250G=2000G。运行了一两年后真的有一颗磁盘坏掉了,我们后来看灯号才发现! 不过对系统没有影响呢!因为 spare disk 主动的加入支持,坏掉的那颗拔掉换颗新的,并重新设置成为 spare 后, 系统内的数据还是完整无缺的!嘿嘿!真不错!
磁盘阵列的优点
说的口沫横飞,重点在哪里呢?其实你的系统如果需要磁盘阵列的话,其实重点在于:
- 数据安全与可靠性:指的并非网络信息安全,而是当硬件 (指磁盘) 损毁时,数据是否还能够安全的救援或使用之意;
- 读写性能:例如 RAID 0 可以加强读写性能,让你的系统 I/O 部分得以改善;
- 容量:可以让多颗磁盘组合起来,故单一文件系统可以有相当大的容量。
尤其数据的可靠性与完整性更是使用 RAID 的考虑重点!毕竟硬件坏掉换掉就好了,软件数据损毁那可不是闹着玩的! 所以企业界为何需要大量的 RAID 来做为文件系统的硬件基准,现在您有点了解了吧?那依据这三个重点,我们来列表看看上面几个重要的 RAID 等级各有哪些优点吧!假设有 n 颗磁盘组成的 RAID 设置喔!
| 项目 | RAID0 | RAID1 | RAID10 | RAID5 | RAID6 |
|---|---|---|---|---|---|
| 最少磁盘数 | 2 | 2 | 4 | 3 | 4 |
| 最大容错磁盘数(1) | 无 | n-1 | n/2 | 1 | 2 |
| 数据安全性(1) | 完全没有 | 最佳 | 最佳 | 好 | 比 RAID5 好 |
| 理论写入性能(2) | n | 1 | n/2 | ||
| 理论读出性能(2) | n | n | n | ||
| 可用容量(3) | n | 1 | n/2 | n-1 | n-2 |
| 一般应用 | 强调性能但数据不重要的环境 | 数据与备份 | 服务器、云系统常用 | 数据与备份 | 数据与备份 |
因为 RAID5, RAID6 读写都需要经过 parity 的计算机制,因此读/写性能都不会刚好满足于使用的磁盘数量喔!
另外,根据使用的情况不同,一般推荐的磁盘阵列等级也不太一样。以鸟哥为例,在鸟哥的跑空气品质模式之后的输出数据,动辄几百 GB 的单一大文件数据, 这些情况鸟哥会选择放在 RAID6 的阵列环境下,这是考虑到数据保全与总容量的应用,因为 RAID 6 的性能已经足以应付模式读入所需的环境。
近年来鸟哥也比较积极在作一些云程序环境的设计,在云环境下,确保每个虚拟机能够快速的反应以及提供数据保全是最重要的部份! 因此性能方面比较弱的 RAID5/RAID6 是不考虑的,总结来说,大概就剩下 RAID10 能够满足云环境的性能需求了。在某些更特别的环境下, 如果搭配 SSD 那才更具有性能上的优势哩!
硬件RAID、软件RAID
为何磁盘阵列又分为硬件和软件呢?所谓的硬件磁盘阵列(hardware RAID)是通过磁盘阵列卡来完成磁盘阵列的功能。磁盘阵列卡上面有一块专门的芯片用于处理RAID的任务,因此在性能方面会比较好。在很多任务(例如RAID 5 的奇偶校验值计算上),磁盘阵列并不会重复消耗原本系统的I/O总线,理论上性能会比较佳。此外目前一般的中高级磁盘阵列卡都支持热插拔,即在不关机的情况下抽换损坏的磁盘,在系统的恢复与数据的可靠性方面非常的好用。
不过一块好的磁盘阵列卡动不动就上千块,便宜的在主板上面附赠的磁盘阵列功能可能又不支持某些高级功能。例如底端主板若有磁盘阵列芯片,通常仅支持到RAID 0,RAID 1。此外,操作系统也必须拥有磁盘阵列卡的驱动程序,才能够正确地识别到磁盘阵列所产生的磁盘驱动器。
因此就发展出软件来模拟磁盘阵列的功能,这就是所谓的软件磁盘阵列(Software RAID)。软件磁盘阵列主要是通过软件来模拟磁盘阵列的任务,因此会损耗很多的系统资源,比如说CPU运算与I/O总线的资源等。不过目前我们的个人计算机已经非常快了,以前的速度限制现在已经不存在,所以我们可以来玩一玩软件磁盘阵列。
我们的CentOS提供的软件磁盘阵列为mdadm这个软件,这个软件会以分区或disk为单位,也就是说你不需要两块以上的磁盘,只要有两个以上的磁盘分区(partition)就能够设计的你得磁盘阵列了。此外,mdadm支持刚刚我们前面提到的RAID 0、RAID 1、RAID 5、热备份磁盘等。而且提供的管理机制可以达到类似热插拔的功能,可以在线(文件系统正常使用)进行分区的抽换,使用上也非常的方便。
另外,硬件磁盘阵列在Linux下面看起来就是一块实际的大磁盘,因此硬件磁盘阵列的设备文件名为 /dev/sd[a-p],因为使用到SCSI的模块之故。至于软件磁盘阵列则是系统模拟的,因此使用的设备文件名就是系统的设备文件,文件名为/dev/md0、/dev/md1等,两者的设备文件名并不相同,不要搞混了。
软件磁盘阵列的设置
使用 mdadm这个命令,语法:
mdadm --detail /dev/md0
mdadm --create /dev/md[0-9] --auto=yes --level=[015] --chunk=NK \
> --raid-devices=N --spare-devices=N /dev/sdx /dev/hdx...
--create:为建立RAID的选项
--auto=yes:决定建立后面接的软件磁盘阵列设备,亦即/dev/md0、/dev/md1等
--chunk=NK:决定这个设备的chunk大小,也就是当成stripe大小,一般是64K或512K
--raid-devices=N:使用几个磁盘分区(partition)作为磁盘阵列的设备
--spare-devices=N:使用几个磁盘作为备用(spare)设备
--level=[015]:设置这组磁盘阵列的级别,支持很多,不过建议只用0、1、5
--detail:后面所接的那个磁盘阵列设备的详细信息上面的语法中, 最后面会接许多的设备文件名,这些设备文件名可以是整块磁盘,例如/dev/sdb,也可以是分区,例如 /dev/sdb1 之类的。不过,这些设备文件名的总数必须要等于 –raid-devices 与 –spare-devices 的个数总和才行。下面我照着鸟哥的步骤来利用测试机来创建一个RAID 5的软件磁盘阵列给您看看。
- 利用4个分区组成 RAID 5
- 每个分区约1GB,需确定每个分区一样大较佳
- 将1个分区设置为热备份磁盘
- chunk设置为256kb这么大即可
- 这个热备份磁盘的大小与其他RAID所需分区一样大
- 将此RAID 5 设备挂载到 /srv/raid 目录下
最终我需要 5 个 1GB 的 partition。在鸟哥的测试机中,根据前面的章节实做下来,包括课后的情境仿真题目,目前应该还有 8GB 可供利用! 因此就利用这部测试机的 /dev/vda 切出 5 个 1G 的分区。实际的流程鸟哥就不一一展示了,自己通过 gdisk /dev/vda 实作一下! 最终这部测试机的结果应该如下所示:
[root@study ~]# gdisk -l /dev/vda Number Start (sector) End (sector) Size Code Name 1 2048 6143 2.0 MiB EF02 2 6144 2103295 1024.0 MiB 0700 3 2103296 65026047 30.0 GiB 8E00 4 65026048 67123199 1024.0 MiB 8300 Linux filesystem 5 67123200 69220351 1024.0 MiB FD00 Linux RAID 6 69220352 71317503 1024.0 MiB FD00 Linux RAID 7 71317504 73414655 1024.0 MiB FD00 Linux RAID 8 73414656 75511807 1024.0 MiB FD00 Linux RAID 9 75511808 77608959 1024.0 MiB FD00 Linux RAID # 上面特殊字体的部份就是我们需要的那 5 个 partition 啰!注意注意! [root@study ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 252:0 0 40G 0 disk |-vda1 252:1 0 2M 0 part |-vda2 252:2 0 1G 0 part /boot |-vda3 252:3 0 30G 0 part | |-centos-root 253:0 0 10G 0 lvm / | |-centos-swap 253:1 0 1G 0 lvm [SWAP] | `-centos-home 253:2 0 5G 0 lvm /home |-vda4 252:4 0 1G 0 part /srv/myproject |-vda5 252:5 0 1G 0 part |-vda6 252:6 0 1G 0 part |-vda7 252:7 0 1G 0 part |-vda8 252:8 0 1G 0 part `-vda9 252:9 0 1G 0 part
- 以 mdadm 创建 RAID
接下来就简单啦!通过 mdadm 来创建磁盘阵列先!
[root@study ~]# mdadm --create /dev/md0 --auto=yes --level=5 --chunk=256K \
> --raid-devices=4 --spare-devices=1 /dev/vda{5,6,7,8,9}
mdadm: /dev/vda5 appears to contain an ext2fs file system
size=1048576K mtime=Thu Jun 25 00:35:01 2015 # 某些时刻会出现这个东西!没关系的!
Continue creating array? y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
# 详细的参数说明请回去前面看看啰!这里我通过 {} 将重复的项目简化!
# 此外,因为鸟哥这个系统经常在创建测试的环境,因此系统可能会抓到之前的 filesystem
# 所以就会出现如上前两行的讯息!那没关系的!直接按下 y 即可删除旧系统
[root@study ~]# mdadm --detail /dev/md0
/dev/md0: # RAID 的设备文件名
Version : 1.2
Creation Time : Mon Jul 27 15:17:20 2015 # 创建 RAID 的时间
Raid Level : raid5 # 这就是 RAID5 等级!
Array Size : 3142656 (3.00 GiB 3.22 GB) # 整组 RAID 的可用容量
Used Dev Size : 1047552 (1023.17 MiB 1072.69 MB) # 每颗磁盘(设备)的容量
Raid Devices : 4 # 组成 RAID 的磁盘数量
Total Devices : 5 # 包括 spare 的总磁盘数
Persistence : Superblock is persistent
Update Time : Mon Jul 27 15:17:31 2015
State : clean # 目前这个磁盘阵列的使用状态
Active Devices : 4 # 启动(active)的设备数量
Working Devices : 5 # 目前使用于此阵列的设备数
Failed Devices : 0 # 损坏的设备数
Spare Devices : 1 # 预备磁盘的数量
Layout : left-symmetric
Chunk Size : 256K # 就是 chunk 的小区块容量
Name : study.centos.vbird:0 (local to host study.centos.vbird)
UUID : 2256da5f:4870775e:cf2fe320:4dfabbc6
Events : 18
Number Major Minor RaidDevice State
0 252 5 0 active sync /dev/vda5
1 252 6 1 active sync /dev/vda6
2 252 7 2 active sync /dev/vda7
5 252 8 3 active sync /dev/vda8
4 252 9 - spare /dev/vda9
# 最后五行就是这五个设备目前的情况,包括四个 active sync 一个 spare !
# 至于 RaidDevice 指的则是此 RAID 内的磁盘顺序
由于磁盘阵列的创建需要一些时间,所以你最好等待数分钟后再使用“ mdadm –detail /dev/md0 ”去查阅你的磁盘阵列详细信息! 否则有可能看到某些磁盘正在“spare rebuilding”之类的创建字样!通过上面的指令, 你就能够创建一个 RAID5 且含有一颗 spare disk 的磁盘阵列啰!非常简单吧! 除了指令之外,你也可以查阅如下的文件来看看系统软件磁盘阵列的情况:
[root@study ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 vda8[5] vda9[4](S) vda7[2] vda6[1] vda5[0] 《==第一行
3142656 blocks super 1.2 level 5, 256k chunk, algorithm 2 [4/4] [UUUU] 《==第二行
unused devices: <none>
上述的数据比较重要的在特别指出的第一行与第二行部分[3]:
- 第一行部分:指出 md0 为 raid5 ,且使用了 vda8, vda7, vda6, vda5 等四颗磁盘设备。每个设备后面的中括号 [] 内的数字为此磁盘在 RAID 中的顺序 (RaidDevice);至于 vda9 后面的 [S] 则代表 vda9 为 spare 之意。
- 第二行:此磁盘阵列拥有 3142656 个block(每个 block 单位为 1K),所以总容量约为 3GB, 使用 RAID 5 等级,写入磁盘的小区块 (chunk) 大小为 256K,使用 algorithm 2 磁盘阵列演算法。 [m/n] 代表此阵列需要 m 个设备,且 n 个设备正常运行。因此本 md0 需要 4 个设备且这 4 个设备均正常运行。 后面的 [UUUU] 代表的是四个所需的设备 (就是 [m/n] 里面的 m) 的启动情况,U 代表正常运行,若为 _ 则代表不正常。
这两种方法都可以知道目前的磁盘阵列状态啦!
- 格式化与挂载使用 RAID
接下来就是开始使用格式化工具啦!这部分就需要注意喔!因为涉及到 xfs 文件系统的优化!还记得第七章的内容吧?我们这里的参数为:
- srtipe (chunk) 容量为 256K,所以 su=256k
- 共有 4 颗组成 RAID5 ,因此容量少一颗,所以 sw=3 喔!
- 由上面两项计算出数据宽度为: 256K*3=768k
所以整体来说,要优化这个 XFS 文件系统就变成这样:
[root@study ~]# mkfs.xfs -f -d su=256k,sw=3 -r extsize=768k /dev/md0 # 有趣吧!是 /dev/md0 做为设备被格式化呢! [root@study ~]# mkdir /srv/raid [root@study ~]# mount /dev/md0 /srv/raid [root@study ~]# df -Th /srv/raid Filesystem Type Size Used Avail Use% Mounted on /dev/md0 xfs 3.0G 33M 3.0G 2% /srv/raid # 看吧!多了一个 /dev/md0 的设备,而且真的可以让你使用呢!还不赖!
模拟RAID错误的恢复模式
俗话说“天有不测风云、人有旦夕祸福”,谁也不知道你的磁盘阵列内的设备啥时会出差错,因此, 了解一下软件磁盘阵列的救援还是必须的!下面我们就来玩一玩救援的机制吧!首先来了解一下 mdadm 这方面的语法:
[root@study ~]# mdadm --manage /dev/md[0-9] [--add 设备] [--remove 设备] [--fail 设备] 选项与参数: --add :会将后面的设备加入到这个 md 中! --remove :会将后面的设备由这个 md 中移除 --fail :会将后面的设备设置成为出错的状态
- 设置磁盘为错误 (fault)
首先,我们来处理一下,该如何让一个磁盘变成错误,然后让 spare disk 自动的开始重建系统呢?
# 0\. 先复制一些东西到 /srv/raid 去,假设这个 RAID 已经在使用了
[root@study ~]# cp -a /etc /var/log /srv/raid
[root@study ~]# df -Th /srv/raid ; du -sm /srv/raid/*
Filesystem Type Size Used Avail Use% Mounted on
/dev/md0 xfs 3.0G 144M 2.9G 5% /srv/raid
28 /srv/raid/etc <==看吧!确实有数据在里面喔!
51 /srv/raid/log
# 1\. 假设 /dev/vda7 这个设备出错了!实际仿真的方式:
[root@study ~]# mdadm --manage /dev/md0 --fail /dev/vda7
mdadm: set /dev/vda7 faulty in /dev/md0 # 设置成为错误的设备啰!
/dev/md0:
.....(中间省略).....
Update Time : Mon Jul 27 15:32:50 2015
State : clean, degraded, recovering
Active Devices : 3
Working Devices : 4
Failed Devices : 1 <==出错的磁盘有一个!
Spare Devices : 1
.....(中间省略).....
Number Major Minor RaidDevice State
0 252 5 0 active sync /dev/vda5
1 252 6 1 active sync /dev/vda6
4 252 9 2 spare rebuilding /dev/vda9
5 252 8 3 active sync /dev/vda8
2 252 7 - faulty /dev/vda7
# 看到没!这的动作要快做才会看到! /dev/vda9 启动了而 /dev/vda7 死掉了
上面的画面你得要快速的连续输入那些 mdadm 的指令才看的到!因为你的 RAID 5 正在重建系统! 若你等待一段时间再输入后面的观察指令,则会看到如下的画面了:
2\. 已经借由 spare disk 重建完毕的 RAID 5 情况
[root@study ~]# mdadm --detail /dev/md0
....(前面省略)....
Number Major Minor RaidDevice State
0 252 5 0 active sync /dev/vda5
1 252 6 1 active sync /dev/vda6
4 252 9 2 active sync /dev/vda9
5 252 8 3 active sync /dev/vda8
2 252 7 - faulty /dev/vda7
看吧!又恢复正常了!真好!我们的 /srv/raid 文件系统是完整的!并不需要卸载!很棒吧!
- 将出错的磁盘移除并加入新磁盘
因为我们的系统那个 /dev/vda7 实际上没有坏掉啊!只是用来仿真而已啊!因此,如果有新的磁盘要替换,其实替换的名称会一样啊! 也就是我们需要:
- 先从 /dev/md0 阵列中移除 /dev/vda7 这颗“磁盘”
- 整个 Linux 系统关机,拔出 /dev/vda7 这颗“磁盘”,并安装上新的 /dev/vda7 “磁盘”,之后开机
- 将新的 /dev/vda7 放入 /dev/md0 阵列当中!
# 3\. 拔除“旧的”/dev/vda7 磁盘
[root@study ~]# mdadm --manage /dev/md0 --remove /dev/vda7
# 假设接下来你就进行了上面谈到的第 2, 3 个步骤,然后重新开机成功了!
# 4\. 安装“新的”/dev/vda7 磁盘
[root@study ~]# mdadm --manage /dev/md0 --add /dev/vda7
[root@study ~]# mdadm --detail /dev/md0
....(前面省略)....
Number Major Minor RaidDevice State
0 252 5 0 active sync /dev/vda5
1 252 6 1 active sync /dev/vda6
4 252 9 2 active sync /dev/vda9
5 252 8 3 active sync /dev/vda8
6 252 7 - spare /dev/vda7
嘿嘿!你的磁盘阵列内的数据不但一直存在,而且你可以一直顺利的运行 /srv/raid 内的数据,即使 /dev/vda7 损毁了!然后通过管理的功能就能够加入新磁盘且拔除坏掉的磁盘!注意,这一切都是在上线 (on-line) 的情况下进行! 所以,您说这样的咚咚好不好用啊! ^_^
开机自动启动 RAID 并自动挂载
新的 distribution 大多会自己搜寻 /dev/md[0-9] 然后在开机的时候给予设置好所需要的功能。不过鸟哥还是建议你, 修改一下配置文件吧! ^_^。software RAID 也是有配置文件的,这个配置文件在 /etc/mdadm.conf !这个配置文件内容很简单, 你只要知道 /dev/md0 的 UUID 就能够设置这个文件啦!这里鸟哥仅介绍他最简单的语法:
[root@study ~]# mdadm --detail /dev/md0 | grep -i uuid
UUID : 2256da5f:4870775e:cf2fe320:4dfabbc6
# 后面那一串数据,就是这个设备向系统注册的 UUID 识别码!
# 开始设置 mdadm.conf
[root@study ~]# vim /etc/mdadm.conf
ARRAY /dev/md0 UUID=2256da5f:4870775e:cf2fe320:4dfabbc6
# RAID设备 识别码内容
# 开始设置开机自动挂载并测试
[root@study ~]# blkid /dev/md0
/dev/md0: UUID="494cb3e1-5659-4efc-873d-d0758baec523" TYPE="xfs"
[root@study ~]# vim /etc/fstab
UUID=494cb3e1-5659-4efc-873d-d0758baec523 /srv/raid xfs defaults 0 0
[root@study ~]# umount /dev/md0; mount -a
[root@study ~]# df -Th /srv/raid
Filesystem Type Size Used Avail Use% Mounted on
/dev/md0 xfs 3.0G 111M 2.9G 4% /srv/raid
# 你得确定可以顺利挂载,并且没有发生任何错误!
如果到这里都没有出现任何问题!接下来就请 reboot 你的系统并等待看看能否顺利的启动吧! ^_^
关闭软件 RAID(重要!)
除非你未来就是要使用这颗 software RAID (/dev/md0),否则你势必要跟鸟哥一样,将这个 /dev/md0 关闭! 因为他毕竟是我们在这个测试机上面的练习设备啊!为什么要关掉他呢?因为这个 /dev/md0 其实还是使用到我们系统的磁盘分区, 在鸟哥的例子里面就是 /dev/vda{5,6,7,8,9},如果你只是将 /dev/md0 卸载,然后忘记将 RAID 关闭, 结果就是….未来你在重新分区 /dev/vdaX 时可能会出现一些莫名的错误状况啦!所以才需要关闭 software RAID 的步骤! 那如何关闭呢?也是简单到爆炸!(请注意,确认你的 /dev/md0 确实不要用且要关闭了才进行下面的玩意儿)
# 1\. 先卸载且删除配置文件内与这个 /dev/md0 有关的设置: [root@study ~]# umount /srv/raid [root@study ~]# vim /etc/fstab UUID=494cb3e1-5659-4efc-873d-d0758baec523 /srv/raid xfs defaults 0 0 # 将这一行删除掉!或者是注解掉也可以! # 2\. 先覆盖掉 RAID 的 metadata 以及 XFS 的 superblock,才关闭 /dev/md0 的方法 [root@study ~]# dd if=/dev/zero of=/dev/md0 bs=1M count=50 [root@study ~]# mdadm --stop /dev/md0 mdadm: stopped /dev/md0 《==不啰唆!这样就关闭了! [root@study ~]# dd if=/dev/zero of=/dev/vda5 bs=1M count=10 [root@study ~]# dd if=/dev/zero of=/dev/vda6 bs=1M count=10 [root@study ~]# dd if=/dev/zero of=/dev/vda7 bs=1M count=10 [root@study ~]# dd if=/dev/zero of=/dev/vda8 bs=1M count=10 [root@study ~]# dd if=/dev/zero of=/dev/vda9 bs=1M count=10 [root@study ~]# cat /proc/mdstat Personalities : [raid6] [raid5] [raid4] unused devices:《==看吧!确实不存在任何阵列设备! [root@study ~]# vim /etc/mdadm.conf #ARRAY /dev/md0 UUID=2256da5f:4870775e:cf2fe320:4dfabbc6 # 一样啦!删除他或是注解他!
你可能会问,鸟哥啊,为啥上面会有数个 dd 的指令啊?干麻?这是因为 RAID 的相关数据其实也会存一份在磁盘当中,因此,如果你只是将配置文件移除, 同时关闭了 RAID,但是分区并没有重新规划过,那么重新开机过后,系统还是会将这颗磁盘阵列创建起来,只是名称可能会变成 /dev/md127 就是了! 因此,移除掉 Software RAID 时,上述的 dd 指令不要忘记!但是…千千万万不要 dd 到错误的磁盘~那可是会欲哭无泪耶~
Tips 在这个练习中,鸟哥使用同一颗磁盘进行软件 RAID 的实验。不过朋友们要注意的是,如果真的要实作软件磁盘阵列, 最好是由多颗不同的磁盘来组成较佳!因为这样才能够使用到不同磁盘的读写,性能才会好! 而数据分配在不同的磁盘,当某颗磁盘损毁时数据才能够借由其他磁盘挽救回来!这点得特别留意呢!
商业转载 请联系作者获得授权,非商业转载 请标明出处,谢谢