条件变分自编码器(CVAE)及相关论文ELBO推导
推导用到的概率公式:
P ( A , B ∣ C ) = P ( A ∣ B , C ) P ( B ∣ C ) P(A,B|C) = P(A|B,C)P(B|C) P(A,B∣C)=P(A∣B,C)P(B∣C)
证明:
由于 P ( A ∣ B ) = P ( A , B ) P ( B ) P(A|B) = {P(A,B) \over P(B)} P(A∣B)=P(B)P(A,B),所以 P ( A , B ∣ C ) = P ( A , B , C ) P ( C ) P(A,B|C)={P(A,B,C) \over P(C)} P(A,B∣C)=P(C)P(A,B,C)。
P ( A , B , C ) = P ( A ∣ B , C ) P ( B ∣ C ) P ( C ) P(A,B,C)=P(A|B,C)P(B|C)P(C) P(A,B,C)=P(A∣B,C)P(B∣C)P(C),所以 P ( A , B ∣ C ) = P ( A ∣ B , C ) P ( B ∣ C ) P(A,B|C) = P(A|B,C)P(B|C) P(A,B∣C)=P(A∣B,C)P(B∣C)
VAE的缺点
VAE是一种无监督模型,只能生成与输入类似的数据,有研究者提出能够生成不同的数据,比如,输入一张黄皮肤人脸,可以生成类似的白皮肤人脸或者黑皮肤人脸,这种情况下VAE就做不到了,故有研究人员提出了CVAE,这个C就是附加的条件,可以利用附加的条件生成更有多样性的数据。
CVAE
CVAE是一个系列,CVAE的模型不止一个,其他模型以后再慢慢补充。CVAE的推导方法与VAE的类似,不了解VAE的可以看我之前的博客变分自编码器(VAE)
CVAE的模型图如下图所示:
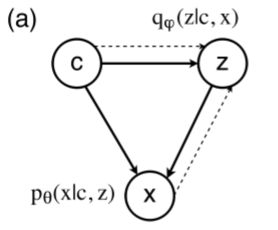
在下面的推导中, c c c是附加信息, x x x是输入数据, z z z是隐变量,
l o g p θ ( x ∣ c ) = l o g ∫ z p θ ( x , z ∣ c ) d z = l o g ∫ z q φ ( z ∣ x , c ) p θ ( x , z ∣ c ) q φ ( z ∣ x , c ) d z = l o g E q φ ( z ∣ x , c ) [ p θ ( x , z ∣ c ) q φ ( z ∣ x , c ) ] ≥ E q φ ( z ∣ x , c ) [ l o g p θ ( x , z ∣ c ) q φ ( z ∣ x , c ) ] (1) \begin{aligned} \tag{1}logp_{\theta}(x|c) = & log\int_{z}p_{\theta}(x, z|c)dz \\ = & log\int_{z}{q_{\varphi}(z|x,c)p_{\theta}(x,z|c) \over q_{\varphi}(z|x,c)}dz \\ = & log E_{q_{\varphi}(z|x,c)}[{p_{\theta}(x,z|c) \over q_{\varphi}(z|x,c)}] \\ \ge & E_{q_{\varphi}(z|x,c)}[log{p_{\theta}(x,z|c) \over q_{\varphi}(z|x,c)}] \\ \end{aligned} logpθ(x∣c)===≥log∫zpθ(x,z∣c)dzlog∫zqφ(z∣x,c)qφ(z∣x,c)pθ(x,z∣c)dzlogEqφ(z∣x,c)[qφ(z∣x,c)pθ(x,z∣c)]Eqφ(z∣x,c)[logqφ(z∣x,c)pθ(x,z∣c)](1)
E L B O = E q φ ( z ∣ x , c ) [ l o g p θ ( x , z ∣ c ) q φ ( z ∣ x , c ) ] = E q φ ( z ∣ x , c ) [ l o g p θ ( x ∣ z , c ) p θ ( z ∣ c ) q φ ( z ∣ x , c ) ] = E q φ ( z ∣ x , c ) [ l o g p θ ( x ∣ z , c ) ] − K L [ q φ ( z ∣ x , c ) ∣ ∣ p θ ( z ∣ c ) ] (2) \begin{aligned} \tag{2}ELBO = & E_{q_{\varphi}(z|x,c)}[log{p_{\theta}(x,z|c) \over q_{\varphi}(z|x,c)}] \\ = & E_{q_{\varphi}(z|x,c)}[log{p_{\theta}(x|z,c)p_{\theta}(z|c) \over q_{\varphi}(z|x,c)}] \\ = & E_{q_{\varphi}(z|x,c)}[logp_{\theta}(x|z,c)] - KL[q_{\varphi}(z|x,c)||p_{\theta}(z|c)] \end{aligned} ELBO===Eqφ(z∣x,c)[logqφ(z∣x,c)pθ(x,z∣c)]Eqφ(z∣x,c)[logqφ(z∣x,c)pθ(x∣z,c)pθ(z∣c)]Eqφ(z∣x,c)[logpθ(x∣z,c)]−KL[qφ(z∣x,c)∣∣pθ(z∣c)](2)
在(2)式中, p θ ( z ∣ c ) 是 z 的 先 验 , q φ ( z ∣ x , c ) 是 z 的 后 验 p_{\theta}(z|c)是z的先验,q_{\varphi}(z|x,c)是z的后验 pθ(z∣c)是z的先验,qφ(z∣x,c)是z的后验。
相应的网络结构如下图所示:

与CVAE相关的论文:
[1]Modeling Event Background for If-Then Commonsense Reasoning Using Context-awareVariational Autoencoder.
[2]Learning Discourse-level Diversity for Neural Dialog Models using Conditional Variational Autoencoders.
[3]Learning Structured Output Representation using Deep Conditional Generative Models.
论文中的 E L B O ELBO ELBO推导:
[1]中的 E L B O ELBO ELBO推导:
用到的概率公式:
P ( A , B , C ∣ D ) = P ( A ∣ B , C , D ) P ( B , C ∣ D ) = P ( A ∣ B , C , D ) P ( B ∣ C , D ) P ( C ∣ D ) P(A,B,C|D) = P(A|B,C,D)P(B,C|D)= P(A|B,C,D)P(B|C,D)P(C|D) P(A,B,C∣D)=P(A∣B,C,D)P(B,C∣D)=P(A∣B,C,D)P(B∣C,D)P(C∣D)

概率图模型如上图所示,虚线是推理网络,实线是生成网络, x 是 x是 x是base event(输入数据), y 是 y是 y是target(输出数据), z c ′ 和 z c z_{c^{'}}和z_c zc′和zc是隐变量,分别表示event的背景信息和inference dimensions.
l o g p θ ( y ∣ x ) = l o g ∬ p θ ( y , z , z c ′ ∣ x ) d z d z c ′ = l o g ∬ p θ ( y , z , z c ′ ∣ x ) q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) d z d z c ′ = l o g E q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) [ p θ ( y , z , z c ′ ∣ x ) q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) ] ≥ E q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) [ l o g p θ ( y , z , z c ′ ∣ x ) q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) ] E L B O = E q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) [ l o g p θ ( y , z , z c ′ ∣ x ) q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) ] = E q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) [ l o g p θ ( y ∣ z , z c ′ x ) p θ ( z ∣ z c ′ , x ) p θ ( z c ′ ∣ x ) q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) ] = E q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) [ l o g p θ ( y ∣ z , z c ′ x ) ] + E q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) [ l o g p θ ( z ∣ z c ′ , x ) p θ ( z c ′ ∣ x ) q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) ] = E q φ ( z ∣ x , z c ′ , y ) q φ ( z c ′ ∣ x , y ) [ l o g p θ ( y ∣ z , z c ′ x ) ] − ∫ z q φ ( z ∣ x , z c ′ , y ) K L [ q φ ( z c ′ ∣ x , y ) ∣ ∣ p θ ( z c ′ ∣ x ) ] d z − ∫ z c ′ q φ ( z c ′ ∣ x , y ) K L [ q φ ( z ∣ x , z c ′ , y ) ∣ ∣ p θ ( z ∣ z c ′ , x ) ] d z c ′ \begin{aligned} logp_{\theta}(y|x) = & log \iint p_{\theta}(y, z, z_{c^{'}}|x)dzdz_{c^{'}} \\ = & log \iint { p_{\theta}(y, z, z_{c^{'}}|x)q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y) \over q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}dzdz_{c^{'}} \\ = & logE_{q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}[{p_{\theta}(y, z, z_{c^{'}}|x) \over q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}] \\ \ge & E_{q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}[log{p_{\theta}(y, z, z_{c^{'}}|x) \over q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}] \\ ELBO = & E_{q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}[log{p_{\theta}(y, z, z_{c^{'}}|x) \over q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}] \\ = & E_{q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}[log{p_{\theta}(y |z, z_{c^{'}}x)p_{\theta}(z|z_{c^{'}},x)p_{\theta}(z_{c^{'}}|x) \over q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}] \\ = & E_{q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}[log{p_{\theta}(y |z, z_{c^{'}}x)]} +E_{q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}[log{p_{\theta}(z|z_{c^{'}},x)p_{\theta}(z_{c^{'}}|x) \over q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}] \\ =&E_{q_{\varphi}(z|x,z_{c^{'}}, y)q_{\varphi}(z_{c^{'}}|x,y)}[log{p_{\theta}(y |z, z_{c^{'}}x)]} \\ & - \int_z q_{\varphi}(z|x,z_{c^{'}},y)KL[q_{\varphi}(z_{c^{'}}|x,y)||p_{\theta}(z_{c^{'}}|x)]dz \\ & - \int_{z_{c^{'}}}q_{\varphi}(z_{c^{'}}|x,y)KL[q_{\varphi}(z|x, z_{c^{'}},y)||p_{\theta}(z|z_{c^{'}},x)]dz_{c^{'}} \end{aligned} logpθ(y∣x)===≥ELBO====log∬pθ(y,z,zc′∣x)dzdzc′log∬qφ(z∣x,zc′,y)qφ(zc′∣x,y)pθ(y,z,zc′∣x)qφ(z∣x,zc′,y)qφ(zc′∣x,y)dzdzc′logEqφ(z∣x,zc′,y)qφ(zc′∣x,y)[qφ(z∣x,zc′,y)qφ(zc′∣x,y)pθ(y,z,zc′∣x)]Eqφ(z∣x,zc′,y)qφ(zc′∣x,y)[logqφ(z∣x,zc′,y)qφ(zc′∣x,y)pθ(y,z,zc′∣x)]Eqφ(z∣x,zc′,y)qφ(zc′∣x,y)[logqφ(z∣x,zc′,y)qφ(zc′∣x,y)pθ(y,z,zc′∣x)]Eqφ(z∣x,zc′,y)qφ(zc′∣x,y)[logqφ(z∣x,zc′,y)qφ(zc′∣x,y)pθ(y∣z,zc′x)pθ(z∣zc′,x)pθ(zc′∣x)]Eqφ(z∣x,zc′,y)qφ(zc′∣x,y)[logpθ(y∣z,zc′x)]+Eqφ(z∣x,zc′,y)qφ(zc′∣x,y)[logqφ(z∣x,zc′,y)qφ(zc′∣x,y)pθ(z∣zc′,x)pθ(zc′∣x)]Eqφ(z∣x,zc′,y)qφ(zc′∣x,y)[logpθ(y∣z,zc′x)]−∫zqφ(z∣x,zc′,y)KL[qφ(zc′∣x,y)∣∣pθ(zc′∣x)]dz−∫zc′qφ(zc′∣x,y)KL[qφ(z∣x,zc′,y)∣∣pθ(z∣zc′,x)]dzc′
第一项是重构误差,也就是生成网络,包括 p θ ( y ∣ z , z c ′ , x ) , 用 神 经 网 络 来 拟 合 p_{\theta}(y|z,z_{c^{'}},x),用神经网络来拟合 pθ(y∣z,zc′,x),用神经网络来拟合,
后面两项是KL项,也就是编码网络,包括 两 个 先 验 网 络 p θ ( z c ′ ∣ x ) 和 p θ ( z ∣ z c ′ , x ) , 两 个 识 别 网 络 q φ ( z ∣ x , z c ′ , y ) 和 q φ ( z c ′ ∣ x , y ) 两个先验网络p_{\theta}(z_{c^{'}}|x)和p_{\theta}(z|z_{c^{'}},x),两个识别网络q_{\varphi}(z|x,z_{c^{'}},y)和q_{\varphi}(z_{c^{'}}|x,y) 两个先验网络pθ(zc′∣x)和pθ(z∣zc′,x),两个识别网络qφ(z∣x,zc′,y)和qφ(zc′∣x,y),因此总共有5个神经网络来拟合上面提到的概率分布。两个识别网络是用来近似真实的后验分布 p θ ( z ∣ x , z c ′ , y ) 和 p θ ( z c ′ ∣ x , y ) p_{\theta}(z|x,z_{c^{'}},y)和p_{\theta}(z_{c^{'}}|x,y) pθ(z∣x,zc′,y)和pθ(zc′∣x,y)的,所以VAE和CVAE都是近似推断而不是精确推断,。
注:上面的推导结果和分析与论文中有差异。
[2]中的 E L B O ELBO ELBO推导:
用到的概率公式:
P ( A , B , C ∣ D ) = P ( A ∣ B , C , D ) P ( B , C ∣ D ) = P ( A ∣ B , C , D ) P ( B ∣ C , D ) P ( C ∣ D ) P(A,B,C|D) = P(A|B,C,D)P(B,C|D)= P(A|B,C,D)P(B|C,D)P(C|D) P(A,B,C∣D)=P(A∣B,C,D)P(B,C∣D)=P(A∣B,C,D)P(B∣C,D)P(C∣D)
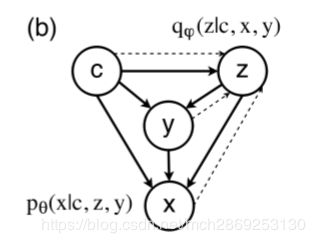
概率图模型如上图所示,虚线是推理网络,实线是生成网络, x x x是对话中的第 k k k条语句, c c c是前 k − 1 k-1 k−1条语句,也就是上下文, y y y是语言的一些特征,比如整个对话表达的动作行为, z z z是隐变量。
l o g p θ ( x ∣ c ) = l o g ∬ p θ ( x , z , y ∣ c ) d z d y = l o g ∬ p θ ( x , z , y ∣ c ) q φ ( z ∣ c , x , y ) q φ ( z ∣ c , x , y ) d z d y = l o g E q φ ( z ∣ c , x , y ) [ p θ ( x , z , y ∣ c ) q φ ( z ∣ c , x , y ) ] ≥ E q φ ( z ∣ c , x , y ) [ l o g p θ ( x , z , y ∣ c ) q φ ( z ∣ c , x , y ) ] E L B O = E q φ ( z ∣ c , x , y ) [ l o g p θ ( x , z , y ∣ c ) q φ ( z ∣ c , x , y ) ] = E q φ ( z ∣ c , x , y ) [ l o g p θ ( x ∣ c , z , y ) p θ ( y ∣ c , z ) p θ ( z ∣ c ) q φ ( z ∣ c , x , y ) ] = E q φ ( z ∣ c , x , y ) [ l o g p θ ( x ∣ c , z , y ) ] + E q φ ( z ∣ c , x , y ) [ l o g p θ ( y ∣ c , z ) ] − K L [ q φ ( z ∣ c , x , y ) ∣ ∣ p θ ( z ∣ c ) ] \begin{aligned} logp_{\theta}(x|c) = & log\iint p_{\theta}(x,z,y|c)dzdy \\ = & log \iint{p_{\theta}(x,z,y|c)q_{\varphi}(z|c,x,y) \over q_{\varphi}(z|c,x,y)}dzdy \\ = & logE_{q_{\varphi}(z|c,x,y)}[{p_{\theta}(x,z,y|c)\over q_{\varphi}(z|c,x,y)}] \\ \ge & E_{q_{\varphi}(z|c,x,y)}[log{p_{\theta}(x,z,y|c)\over q_{\varphi}(z|c,x,y)}] \\ ELBO = & E_{q_{\varphi}(z|c,x,y)}[log{p_{\theta}(x,z,y|c)\over q_{\varphi}(z|c,x,y)}] \\ = & E_{q_{\varphi}(z|c,x,y)}[log{p_{\theta}(x|c,z,y)p_{\theta}(y|c,z)p_{\theta}(z|c)\over q_{\varphi}(z|c,x,y)}] \\ = & E_{q_{\varphi}(z|c,x,y)}[logp_{\theta}(x|c,z,y)] \\ &+ E_{q_{\varphi}(z|c,x,y)}[logp_{\theta}(y|c,z)] \\ & - KL[q_{\varphi}(z|c,x,y)||p_{\theta}(z|c)] \end{aligned} logpθ(x∣c)===≥ELBO===log∬pθ(x,z,y∣c)dzdylog∬qφ(z∣c,x,y)pθ(x,z,y∣c)qφ(z∣c,x,y)dzdylogEqφ(z∣c,x,y)[qφ(z∣c,x,y)pθ(x,z,y∣c)]Eqφ(z∣c,x,y)[logqφ(z∣c,x,y)pθ(x,z,y∣c)]Eqφ(z∣c,x,y)[logqφ(z∣c,x,y)pθ(x,z,y∣c)]Eqφ(z∣c,x,y)[logqφ(z∣c,x,y)pθ(x∣c,z,y)pθ(y∣c,z)pθ(z∣c)]Eqφ(z∣c,x,y)[logpθ(x∣c,z,y)]+Eqφ(z∣c,x,y)[logpθ(y∣c,z)]−KL[qφ(z∣c,x,y)∣∣pθ(z∣c)]
前两项是重构误差,也就是生成网络,包括 l o g p θ ( x ∣ c , z , y ) logp_{\theta}(x|c,z,y) logpθ(x∣c,z,y)和 l o g p θ ( y ∣ c , z ) logp_{\theta}(y|c,z) logpθ(y∣c,z),分别用来生成 x 和 y x和y x和y,第三项是KL项,也就是编码网络,包括先验网络 p θ ( z ∣ c ) p_{\theta}(z|c) pθ(z∣c)和后验网络 q φ ( z ∣ c , x , y ) q_{\varphi}(z|c,x,y) qφ(z∣c,x,y),总共有4个网络来拟合上面的概率分布。