00.python基础学习——环境搭建与数据类型
python火遍整个数据圈,数据分析的人员基本要求会python,在互联网公司应用最多,在银行或者大型国企应用SAS或者SPSS,有些也用R语言。不扯淡了,直接进入主题;
1.Anaconda环境搭建:
Anaconda基本上包含了python所有常用的安装包,甚是好用。
a)环境配置:
Anaconda可安装与Windows,Linux以及OS。
(1)下载地址 Index of /anaconda/archive/
(2)选择相应的版本进行下载就好
(3)下载过程中除了安装位置外,还有两个需要确认的地方
(3.1)是否把Anaconda加入环境变量,这涉及到能否直接在cmd中使用conda、jupyter、ipython等命令,推荐打勾
(3.2)是否设置Anaconda所带的Python 3.6为系统默认的Python版本
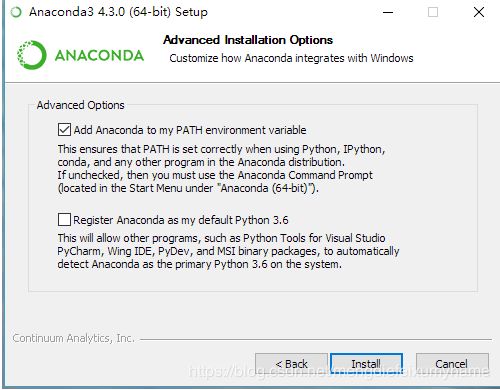
注意:倘若在CMD中输入conda命令无效,可以参考下面参考文章进行设置环境变量:https://blog.csdn.net/larry233/article/details/81088765
b)解释器:
pycharm将anaconda设置为默认解释器,但是我个人比较推荐数据分析人员使用anaconda自带的IDE–spyder;
(1)运行pycharm,file->settings
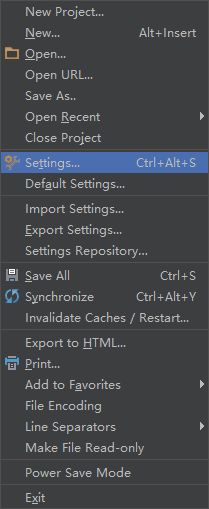
(2)Project->Project Intepreter

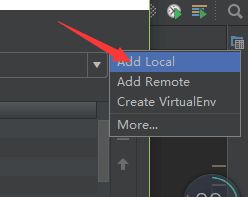
(3)选择解释器,Add Local,找到Anaconda安装目录下的python.exe路径即可

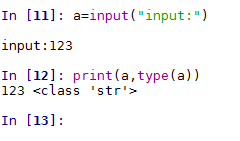
2.python初体验(IDE为spyder)
3.python基础讲解
3.1 标识符
标识符区分大小写,包含字符,数字以及下划线,但是不可以数字开头,下划线开头的字符具有特殊意义,Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠()来实现多行语句;
3.2关键字:
通过下面代码显示python里面的所有关键字
import keyword
keyword.kwlist
3.4注释:
a) #
b) ‘’’ ‘’’
c) “”" “”"
3.5 行缩进:
python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。实例如下:
a = input("input:")
b=int(a)
if b>1:
print('True')
else:
print('Flase')
3.6 dir()函数以及help函数
(1)dir()函数:
在 Python 中,有大量的内置模块,模块中的定义(例如:变量、函数、类)众多,不可能全部都记住,这时 dir() 函数就非常有用了。
dir() 是一个内置函数,用于列出对象的所有属性及方法。在 Python 中,一切皆对象,模块也不例外,所以模块也可以使用 dir()。除了常用定义外,其它的不需要全部记住它,交给 dir() 就好了。
import pandas as pd
dir(pd)
(2)help使用:包括模块的介绍、包含的内容、子模块、版本以及文件路径;
3.7 import使用
如果你从 Python 解释器退出再进入,那么你定义的所有的方法和变量就都消失了。
为此 Python 提供了一个办法,把这些定义存放在文件中,为一些脚本或者交互式的解释器实例使用,这个文件被称为模块。
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。这也是使用 python 标准库的方法。模块导入方式
(1)import pandas
(2)import pandas as pd
(3)from pandas import *
(4)from matplotlib import pyplot
(5)from matplotlib import pyplot as plt
3.8 pep8介绍
总体原则,新编代码必须按下面命名风格进行,现有库的编码尽量保持风格。
尽量以免单独使用小写字母'l',大写字母'O',以及大写字母'I'等容易混淆的字母。
模块命名尽量短小,使用全部小写的方式,可以使用下划线。包命名尽量短小,使用全部小写的方式,不可以使用下划线。
类的命名使用CapWords的方式,模块内部使用的类采用_CapWords的方式。
异常命名使用CapWords+Error后缀的方式。
全局变量尽量只在模块内有效,类似C语言中的static。实现方法有两种,一是__all__机制;二是前缀一个下划线。对于不会发生改变的全局变量,使用大写加下划线。
函数命名使用全部小写的方式,可以使用下划线。
常量命名使用全部大写的方式,可以使用下划线。
使用 has 或 is 前缀命名布尔元素,如: is_connect = True; has_member = False
用复数形式命名序列。如:members = ['user_1', 'user_2']
用显式名称命名字典,如:person_address = {'user_1':'10 road WD', 'user_2' : '20 street huafu'}
避免通用名称。诸如 list, dict, sequence 或者 element 这样的名称应该避免。又如os, sys 这种系统已经存在的名称应该避免。
类的属性(方法和变量)命名使用全部小写的方式,可以使用下划线。
对于基类而言,可以使用一个 Base 或者 Abstract 前缀。如BaseCookie、AbstractGroup
内部使用的类、方法或变量前,需加前缀'_'表明此为内部使用的。虽然如此,但这只是程序员之间的约定而非语法规定,用于警告说明这是一个私有变量,外部类不要去访问它。但实际上,外部类还是可以访问到这个变量。import不会导入以下划线开头的对象。
类的属性若与关键字名字冲突,后缀一下划线,尽量不要使用缩略等其他方式。
双前导下划线用于命名class属性时,会触发名字重整;双前导和后置下划线存在于用户控制的名字空间的"magic"对象或属性。
为避免与子类属性命名冲突,在类的一些属性前,前缀两条下划线。比如:类Foo中声明__a,访问时,只能通过Foo._Foo__a,避免歧义。如果子类也叫Foo,那就无能为力了。
类的方法第一个参数必须是self,而静态方法第一个参数必须是cls。
一般的方法、函数、变量需注意,如非必要,不要连用两个前导和后置的下线线。两个前导下划线会导致变量在解释期间被更名。两个前导下划线会导致函数被理解为特殊函数,比如操作符重载等。
要用断言来实现静态类型检测。断言可以用于检查参数,但不应仅仅是进行静态类型检测。 Python 是动态类型语言,静态类型检测违背了其设计思想。断言应该用于避免函数不被毫无意义的调用。
不要滥用 *args 和 **kwargs。*args 和 **kwargs 参数可能会破坏函数的健壮性。它们使签名变得模糊,而且代码常常开始在不应该的地方构建小的参数解析器
缩进。优先使用4个空格的缩进(编辑器都可以完成此功能),其次可使用Tap,但坚决不能混合使用Tap和空格。
每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
一个函数 : 不要超过 30 行代码, 即可显示在一个屏幕类,可以不使用垂直游标即可看到整个函数;一个类 : 不要超过 200 行代码,不要有超过 10 个方法;一个模块 不要超过 500 行。
模块内容的顺序:模块说明和docstring—import—globals&constants—其他定义。其中import部分,又按标准、三方和自己编写顺序依次排放,之间空一行。
不要在一句import中多个库,比如import os, sys不推荐。如果采用from XX import XX引用库,可以省略‘module.’。若是可能出现命名冲突,这时就要采用import XX。
总体原则,避免不必要的空格。
各种右括号前不要加空格。
函数的左括号前不要加空格。如Func(1)。
序列的左括号前不要加空格。如list[2]。
逗号、冒号、分号前不要加空格。
操作符(=/+=/-+/==//!=/<>/<=/>=/in/not in/is/is not/and/or/not)左右各加一个空格,不要为了对齐增加空格。如果操作符有优先级的区别,可考虑在低优先级的操作符两边添加空格。
函数默认参数使用的赋值符左右省略空格。
不要将多句语句写在同一行,尽管使用‘;’允许。
if/for/while语句中,即使执行语句只有一句,也必须另起一行。
总体原则,错误的注释不如没有注释。所以当一段代码发生变化时,第一件事就是要修改注释!避免无谓的注释
注释必须使用英文,最好是完整的句子,首字母大写,句后要有结束符,结束符后跟两个空格,开始下一句。如果是短语,可以省略结束符。
行注释:在一句代码后加注释,但是这种方式尽量少使用。。比如:x = x + 1 # Increment
块注释:在一段代码前增加的注释。在‘#’后加一空格。段落之间以只有‘#’的行间隔。比如:
# Description : Module config.
#
# Input : None
#
# Output : None
为所有的共有模块、函数、类、方法写docstrings;非共有的没有必要,但是可以写注释(在def的下一行)。
编码中考虑到其他python实现的效率等问题,比如运算符‘+’在CPython(Python)中效率很高,都是Jython中却非常低,所以应该采用.join()的方式。
与None之类的单件比较,尽可能使用‘is’‘is not’,绝对不要使用‘==’,比如if x is not None 要优于if x。
使用startswith() and endswith()代替切片进行序列前缀或后缀的检查。比如:建议使用if foo.startswith('bar'): 而非if foo[:3] == 'bar':
使用isinstance()比较对象的类型。比如:建议使用if isinstance(obj, int): 而非if type(obj) is type(1):
判断序列空或不空,有如下规则:建议使用if [not] seq: 而非if [not] len(seq)
字符串不要以空格收尾。
二进制数据判断使用 if boolvalue的方式。
使用基于类的异常,每个模块或包都有自己的异常类,此异常类继承自Exception。错误型的异常类应添加"Error"后缀,非错误型的异常类无需添加。
异常中不要使用裸露的except,except后跟具体的exceptions。
异常中try的代码尽可能少。比如:
try:
value = collection[key]
except KeyError:
return key_not_found(key)
else:
return handle_value(value)
4. python基本数据类型
Python3 中有六个标准的数据类型:
Number(数字)
String(字符串)
List(列表)
Tuple(元组)
Set(集合)
Dictionary(字典)
Python3 的六个标准数据类型中:
不可变数据(3 个):
Number(数字)、String(字符串)、Tuple(元组);
可变数据(3 个):
List(列表)、Dictionary(字典)、Set(集合);
数值类型
数值类型有int、float、bool和complex;
整型(Int) - 通常被称为是整型或整数,是正或负整数,不带小 数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用。
浮点型(float) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
布尔型(bool)-True和False;
复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
5. 数值运算
5.1 算术运算符

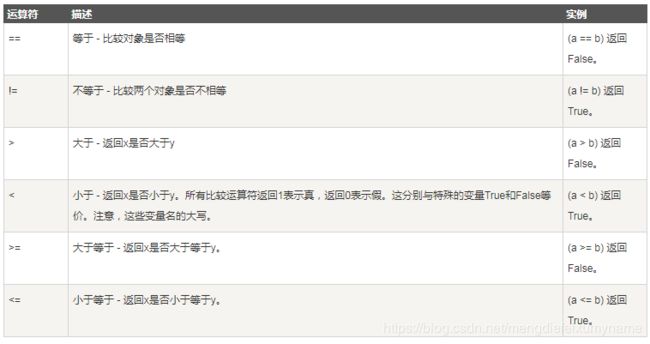
5.2比较运算
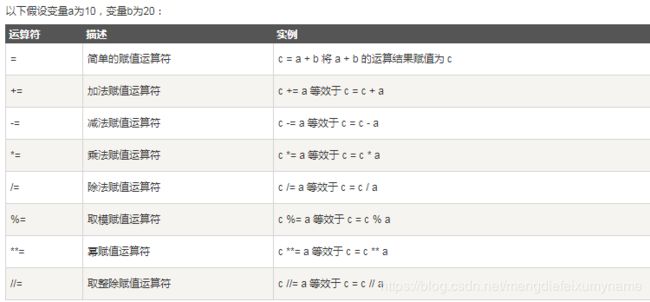
5.3 赋值运算
5.4 位运算

5.5 成员运算

5.6身份运算

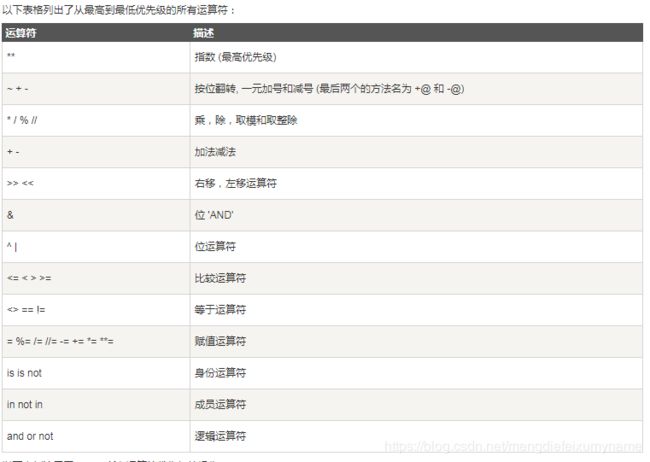
5.7运算优先级

参考文献:
https://www.cnblogs.com/amanda-x/p/7739467.html
https://blog.csdn.net/larry233/article/details/81088765
https://blog.csdn.net/liang19890820/article/details/75127738
http://www.runoob.com/python3/python3-module.html
https://www.cnblogs.com/kungfupanda/p/5267802.html
https://blog.csdn.net/ratsniper/article/details/78954852
http://www.runoob.com/python3/python3-basic-operators.html