数据结构基础——树、图,堆
树
树是一种非线性的结构,一般来说树形结构中,只有一个根节点,而在树其他节点中有且只能有一个前驱节点。我们常说的树结构,一般说的为二叉树,而实际中我们使用的树形结构不仅仅限于一个二叉树。
定义
对于一个有n个元素的树,当n为0的时候称为空树。其定义有下面要求:
- 树有且仅有一个特定节点为其根节点
- 当n>1时,其余结点可分为m(m>0)个互补交互的有限集T1、T2…Tm,其中每一个集合本身又是一棵树,并称为根的子树
- 子树是没有数量限制的但是,一定不相交
关于树的名词
摘至百科
结点的度:一个结点含有的子树的个数称为该结点的度;
叶结点或终端结点:度为0的结点称为叶结点;
非终端结点或分支结点:度不为0的结点;
双亲结点或父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点;
孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点;
兄弟结点:具有相同父结点的结点互称为兄弟结点;
树的度:一棵树中,最大的结点的度称为树的度;
结点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推;
树的高度或深度:树中结点的最大层次;
堂兄弟结点:双亲在同一层的结点互为堂兄弟;
结点的祖先:从根到该结点所经分支上的所有结点;
子孙:以某结点为根的子树中任一结点都称为该结点的子孙。
森林:由m(m>=0)棵互不相交的树的集合称为森林;
简单的树示例
二叉树
定义
二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆
示例
特点
满二叉树
定义
除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树
示例
完全二叉树
定义
对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。
简单的说,在一棵二叉树中,除最后一层外,若其余层都是满的,并且或者最后一层是满的,或者是在右边缺少连续若干结点,则此二叉树为完全二叉树。
示例
特点
二叉排序树
定义
主要用于查找或排序,其主要有下面特性
- 左子节点所有的值小于其根节点,右子节点所有的值大于其根节点
- 对二叉树进行遍历,可以得到有序的数列
- 左、右子树也分别为二叉排序树
- 没有重复的节点
示例
二叉平衡树 - 红黑树
定义
平衡树:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
红黑树:它是一种自平衡的二叉查找树。在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。它可以在O(logn)时间内做查找,插入和删除。
对于平衡红黑树的要求
- 节点是红色或黑色,
- 根是黑色
- 每个红色节点必须有两个黑色的子节点。
- 从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点(简称黑高)。
- 每个叶子节点(NIL)是黑色
示例
如果一个节点没有儿子,我们称之为叶子节点,因为在直觉上它是在树的边缘上。子树是从特定节点可以延伸到的树的某一部分,其自身被当作一个树。在红黑树中,叶子被假定为 null 或空。
特点
数据的插入:当我们对红黑树进行插入或修改的时候,会违背了红黑树的性质,所以我们需要对树进行旋转来保证其性质。红黑树是牺牲了严格的高度平衡的优越条件为代价,它只要求部分地达到平衡要求,降低了对旋转的要求,从而提高了性能。红黑树能够以O(log2 n)的时间复杂度进行搜索、插入、删除操作。
B树
定义
对于一棵平衡的m路搜索树,要么是空树,要么符合下面定义
- 定义任意非叶子结点可以有超过2个子节点
- 每个节点有M-1个key,并且以升序排列
- 位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
- 其它节点至少有M/2个子节点
示例
每个结点中关键字从小到大排列,并且当该结点的孩子是非叶子结点时,该k-1个关键字正好是k个孩子包含的关键字的值域的分划。
特点
相对于二叉树,B树每个节点能存储的数据更多,有效的降低了树的高度,在查询数据方面比较高效。
B+树
定义
B+树是B树的一种变形形式,B+树上的叶子结点存储关键字以及相应记录的地址,叶子结点以上各层作为索引使用。
其定义主要是
- 其定义基本与B-树相同
- 有k个子结点的结点必然有k个关键码;
- 非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。
- 树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
示例
B树和B+树的区别
数据:B树中数据被分布在整棵树中,而B+树中,非叶节点只保存索引,只有遍历到叶子节点才能获取数据
效率:因为B+树在节点上不包含数据,所以内存上可以存放更多的key。相对的减少了读写次数。提高索引效率
查询:叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。
图的定义
数据结构中存在一种结构是图。图是一个比较复杂的数据结构。相对于线形结构、树状结构,图的数据结构会显得非常复杂。
关于图的定义有
图是由顶点集V和顶点间的关系集合E(边的集合)组成的一种数据结构,可以用二元组定义为:G=(V,E)
将图的结构画出来大概是这个样子

一般图的每个订单认为是一个节点或者交点。边称为连接,一般会给每个边设置一个权重。
可以想象上面城市的图。每一个城市就是一个节点,每个边就是一个航程使用距离设置权重。通过这个图可以实现两点之间通过的方案。然后根据权重我们可以设置最高或者最低权重的数据。
图的内容
无向图
无向图指的是每个边都是无向边,遍历的时候两个节点可以相互通过,边并不限制节点方向。
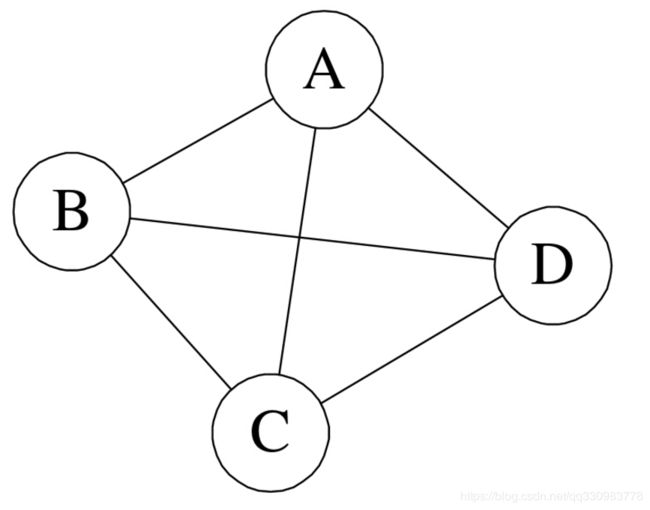
有向图
无向图指的是每个边都是有向边,遍历的时候两个节点存在头尾,必须根据边指向箭头来确定方向。

权
在图中的边我们一般会给出一个数值,用来表示这个边的权重。
网
图上的边带权则称为网。
子图
如果有两个图,其中一个A图属于另外一个B图。则图A为图B的子图。
邻接点
若顶点A和顶点B之间存在一条边,则A和B未邻接点。
顶点的度
图中与该顶点相关联的边的数目,称为顶点的度。
入度和出度
在有向图中,以A顶点为终点的边为入度,以A顶点为起点的边成为出度。顶点A的度为入度+出度。
路径
一个图中,从A到B所需经过的顶点为路径
路径长度
路径上的边
连通图
图中任意两个顶点连通,则称该图为连通图
强连通图
在有向图中, 图中任意两个顶点连通,则称该图为强连通图
遍历图
广度优先遍历
其是图遍历算法中基于的思路是尽最大程度辐射能够覆盖的节点。我们先选择一个起点,然后依次遍历其最近的节点,然后在依次遍历第二层的节点,最后完成所有节点遍历。
以下面这张图为例
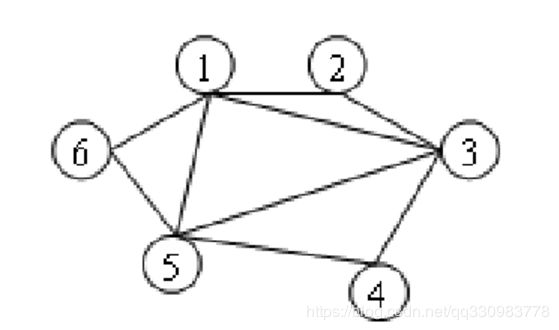
我们尝试以6位起点进行遍历:
- 首先我们遍历到了6。已遍历内容(6)
- 然后遍历6的节点1,5。已遍历内容(6,1,5)
- 然后开始遍历1节点,得到2,3,5,6因为5,6已完成遍历则不再记录。已遍历内容(6,1,2,5,3)
- 然后开始遍历5节点,得到3,4,5,6因为5,6,4已完成遍历则不再记录。已遍历内容(1,2,3,4,5,6)
深度优先遍历
深度遍历是从某个节点触发,遍历此节点,对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。
以下面这张图为例

我们以A为起点,然后优先右边进行遍历
- 首先我们从1开始。已遍历内容(1)
- 然后根据向右边优先的原则,遍历了2,9,6,3然后此时遍历到了1,此节点已经遍历,证明这一条线已经完成遍历。
- 然后我们回到节点6开始遍历,然后遍历到了7,5然后此时遍历到了3,此节点已经遍历,证明这一条线已经完成遍历。
- 后续我们回到节点9,但此节点已经完成遍历,然后回到节点4,发现8没有遍历,继续开始8节点的遍历。
- 完成8遍历后发现周围节点已经完成遍历,回到2节点发现所有内容已经完成遍历。截止到这一步所有节点完成遍历。
图的应用
图这个数据结构在绝大多数开发人员的日常工作中使用的并不算很多,但是并非是没有被使用。像生活我们使用的地图导航以及人脉关系图,以及游戏中的自动寻路等都应用了图的结构。我们通过图可以理清人脉关系图,也可以使用图获得导航的最优解。所以会发现图在我们日常生活中的使用其实是非常普遍的。
堆得定义
堆通常是一个可以被看做一棵完全二叉树的数组对象。
一般推满足下列性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值,这取决于是大根堆还是小根堆的限制。
- 堆总是一棵完全二叉树。
- 当根节点为最大的叫做最大堆或大根堆,当根节点为最小的时候叫做最小堆或小根堆。
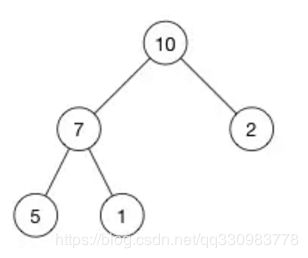
最大堆的例子
堆和树的区别
节点大小
- 二叉搜索树中,左子节点必须比父节点小,右子节点必须必比父节点大。堆中并非如此。在最大堆中两个子节点都必须比父节点小,而在最小堆中,它们都必须比父节点大。
内存占用
堆虽然是一颗完全二叉树,但是通常存放在一个数组中,父节点和子节点通过数组下标确定。
查询
二叉树中搜索会很快,但是在堆中搜索会很慢。因为使用堆的目的是将最大(或者最小)的节点放在最前面,从而快速的进行相关插入、删除操作。
堆得作用
优先队列
最大堆总是将其中的最大值存放在树的根节点。而对于最小堆,根节点中的元素总是树中的最小值。当被当做优先队列使用,因为可以快速的访问到“最重要”的元素。
个人水平有限,上面的内容可能存在没有描述清楚或者错误的地方,假如开发同学发现了,请及时告知,我会第一时间修改相关内容。假如我的这篇内容对你有任何帮助的话,麻烦给我点一个赞。你的点赞就是我前进的动力。