3D图形学(11):渲染优化之从瓶颈定位到优化策略
本文章结合了浅墨整理的《Real-Time Rendering 3rd》第十五章“Pipeline Optimization”和《GPU Gem I》第28章“Graphics Pipeline Performance”,整合冯乐乐的《Unity Shader入门精要》第十六章 渲染优化,同时,加上一些自己的整理。
一、渲染管线的瓶颈定位策略
正确定位到了瓶颈,优化工作就已完成了一半,因为可以针对管线上真正需要优化的地方有的放矢 。
提到瓶颈定位,很多人都会想到Profiler工具。Profiler工具可以提供API调用耗时的详细信息,由此可以知道哪些API调用是昂贵费时的,但不一定能准确地确定管道中哪些阶段正在减慢其余部分的速度。
确定瓶颈的方法除了用Profiler查看调用耗时的详细信息这种众所周知的方法外,也可以采用基于工作量变化的控制变量法。设置一系列测试,其中每个测试减少特定阶段执行的工作量。如果其中一个测试导致每秒帧数增加,则已经找到瓶颈阶段。

整个确认瓶颈的过程从渲染管线的尾端,光栅化阶段开始,经过帧缓冲区的操作(也称光栅操作),终于CPU(应用程序阶段)。
下文将按照按照优化定位的一般顺序(即上述图中的流程),按光栅化阶段、几何阶段、应用程序阶段的的顺序来依次介绍瓶颈定位的方法与要点。
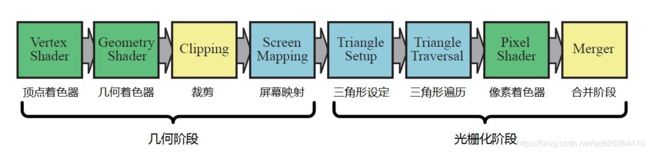
关于渲染管线整个流程的详细解读:https://blog.csdn.net/qq826364410/article/details/88389349
1. 光栅化阶段的瓶颈定位
众所周知,光栅化阶段由四个的阶段组成: 三角形设置,三角形遍历,片元着色器,片元操作(光栅化操作)。
其中三角形设置和遍历阶段几乎不会是瓶颈,因为它只是将顶点连接成三角形。
1.1 光栅化操作的瓶颈定位
光栅化操作的瓶颈主要与帧缓冲带宽(Frame-Buffer Bandwidth)相关。众所周知,位于管线末端的光栅化操作(Raster Operations,常被简称为ROP),用于深度缓冲区和模板缓冲区的读写、比较,颜色缓冲区读写颜色,以及进行alpha 混合和测试。光栅化操作中许多负载都加重了帧缓冲带宽负载。
测试帧缓冲带宽是否是瓶颈所在,比较好的办法是改变颜色缓冲的位深度,或深度缓冲的位深度(也可以同时改变两者)。如果此操作(比如将颜色缓冲或深度缓冲的位深度从32位减少到16位)明显地提高了性能,那么帧缓冲带宽必然是瓶颈所在。
另外,帧缓冲带宽也与GPU显存频率(GPU memory clock)有关,因此,修改该频率也可以帮助识别瓶颈。
补充:位深度
示例:8位颜色的图,位深度就是8,用2的8次幂表示,它含有256种颜色 ( 或256种灰度等级 )。
更通俗的讲,8位颜色的图,每存储1个像素一般需要8位二进制。也就是8个01进行排列组合,排列组合的结果有2的8次幂=256种颜色。我们把每个像素可表示颜色的2的幂指数称为深度。
1.2 片元着色器的瓶颈定位
片元着色关系到产生一个片元的实际开销,与颜色和深度值有关。这就是运行”像素着色器(Pixel Shader )“或”片元着色器(Fragment Shader )“的开销。片元着色(Fragment shading)和帧缓冲带宽(Frame-Buffer Bandwidth)由于填充率(Fill Rate)的关系,经常在一起考虑,因为他们都与屏幕分辨率相关。尽管它们在管线中位于两个截然不同的阶段,区分两者的差别对有效优化至关重要。
片元着色器的是否是瓶颈所在可以通过改变屏幕分辨率来测试。如果较低的屏幕分辨率导致帧速率明显上升,片元着色器则是瓶颈,至少在某些时候会是这样。当然,如果是渲染的是LOD系统,就需斟酌一下是否瓶颈确实是片元着色器了。
片元着色的速度与GPU核心频率有关。
1.3 纹理带宽的瓶颈定位
在内存中出现纹理读取请求时,就会消耗纹理带宽(Texture Bandwidth)。
过程:从显存读取纹理到GPU的纹理高速缓冲区
尽管现代GPU的纹理高速缓存设计旨在减少多余的内存请求,但纹理的存取依然会消耗大量的内存带宽。
缩小纹理尺寸,改变纹理过滤方式,如果此修改显著地改善性能,则意味着纹理带宽是瓶颈限制。
纹理带宽也与GPU显存频率相关。
2. 几何阶段的瓶颈定位
几何阶段是最难进行瓶颈定位的阶段。这是因为如果在这个阶段的工作负载发生了变化,那么其他阶段的一个或两个阶段的工作量也常常发生变化。为了避免这个问题,Cebenoyan 提出了一系列的试验工作从光栅化阶段后的管线开始进行瓶颈定位。
在几何阶段有两个主要区域可能出现瓶颈:顶点与索引传输( Vertex and Index Transfer)和顶点着色器。
2.1 顶点着色器的瓶颈定位
渲染管线中的顶点着色器,主要工作是坐标变换,逐顶点光照和输出后续阶段所需的数据。
输入一组顶点属性(如模型空间位置、顶点法线、纹理坐标等等),输出一组适合裁剪和光栅化的属性(如齐次裁剪空间位置,顶点光照结果(正向渲染),纹理坐标等等)。当然,这个阶段的性能与每个顶点完成的工作,以及正在处理的顶点数量有关。
如果减少顶点着色器的指令数量,帧率有明显变化,则说明瓶颈在顶点着色器,这种情况一般不会出现。
如果减少顶点数量,帧率有明显变化,则说明瓶颈可能在顶点过多,或顶点AGP传输限制,此时可能通过模型LOD来解决问题。
另外需要注意,顶点处理的速度与GPU核心频率有关。
2.2 顶点与索引传输的瓶颈定位
GPU渲染管线的第一步,是让GPU获取顶点和索引。而GPU获取顶点和索引的操作性能取决于顶点和索引的实际位置。其位置通常是在系统内存中(通过AGP或PCI Express总线传送到GPU),或在局部帧缓冲内存中。
如果在顶点着色器中访问纹理会比较慢,瓶颈可能在顶点着色器(Shader Model 3.0)。
3. 应用程序阶段的瓶颈定位
使用各种工具来分析项目中存在的性能问题,最常用的工具有:
Unity引擎提供很多测试工具包括Unity Profiler,Unity Memory Profiler,Unity Frame Debugger等,
在ios平台下,XCode Instrument 也包含了很多工具,其中最常用的有Time Profiler,Allocation以及Capture GPU Frame。
在android平台下,最常用的工具有AdrenoProfiler和SnapdragonProfiler,这两个工具都是用来进行GPU性能分析的。
Unity Profiler
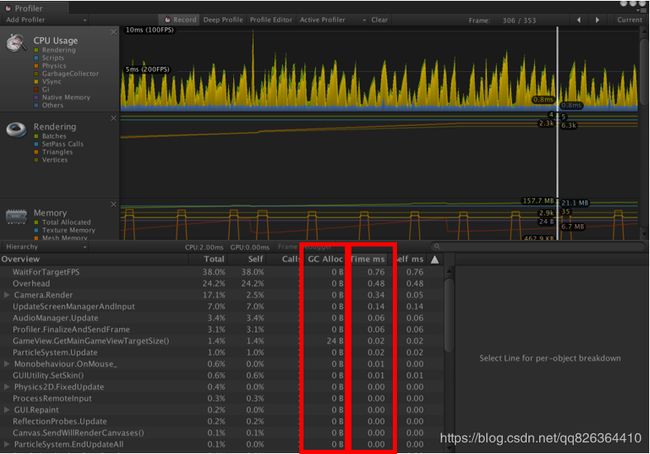
Unity Profiler中最常检查的内容是CPU Usage,其中GC Alloc和Time ms最为重要。GC Alloc展示了每帧在Mono堆上进行内存分配的代码,过于频繁的在堆上分配内存会导致Mono定期触发GC.Collect操作,进而导致游戏卡顿。因此我们建议对单帧2K以上的内存分配,以及每帧20B以上的内存分配进行排查。如果能把堆内存的分配降到最低是最好的。Time ms展示了每一帧CPU耗时最高的函数,通过这项可以找到耗时不合理的代码,然后进一步对代码进行优化。
Unity Memory Profiler
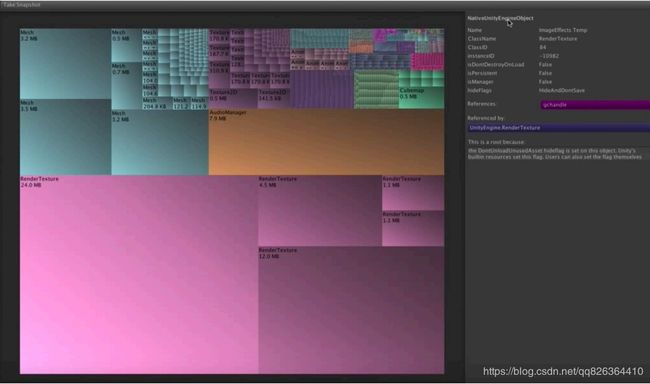
Unity为5.3以上的版本提供了一个新的Memory Profiler工具。这个工具通过图形的方式展示了工程中占用内存最高的资源类型,因此可以很方便的进行资源内存的优化。另外还可以在游戏的不同时间点抓取多个快照,通过比较内存占用的不同,来发现某些资源内存泄漏的情况。
Unity Frame Debug
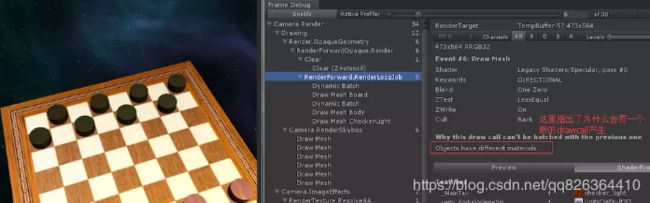
通过Enable按钮可以抓取当前渲染帧的全部数据。 了解不能合批的原因,DrawCall过多的原因。例如,同一张图集,为什么会多一个DrawCall,因为对象的材质不同。
XCode Instrument – Time Profiler
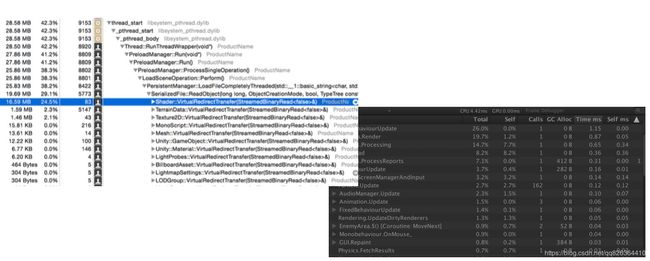
左上角是Instrument的Time Profiler工具,右下角是Unity Profiler,可以发现它们非常像。区别在于Time Profiler可以分析一段时间范围内不同函数的时间消耗,而Unity Profiler只能分析一帧内代码的时间消耗。另外Time Profiler可以显示引擎底层耗时高的代码堆栈,非常方便从底层去理解性能问题的原因。Unity Profiler只能显示引擎代码中添加标签的函数耗时,因此往往在Instrument Time Profiler中可以看到更多有用的数据。
XCode Instrument – Allocation
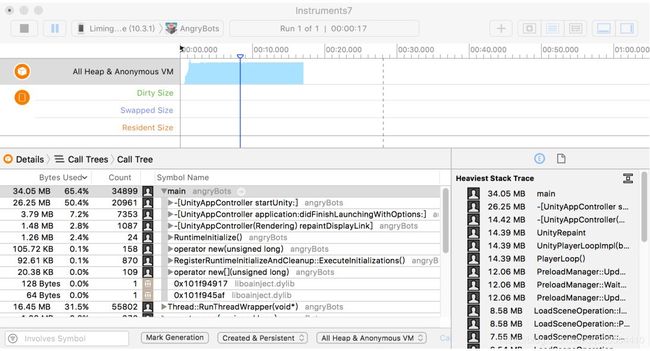
Allocation是用于分析内存分配的工具。默认情况下,它会开启Created & Persistent选项,这代表它会记录一段时间内分配出来但是没有释放的内存。因为有了这个功能,我们可以很方便的检查游戏中存在的内存泄露。一般的使用方法是在游戏主菜单界面开启Allocation检测,进入战斗场景测试一段时间再回到主菜单界面,然后检查有哪些内存分配但是没有被释放。这部分内存就可能包含存在泄漏的内存。
Capture GPU Frame

从XCode内启动游戏在真机运行,通过XCode内的Capture按钮可以抓取当前渲染帧的全部数据。界面左边展示了所有的Drawcall列表,中间上方是当前Drawcall渲染出的画面,下方是当前Drawcall的相关数据,右上方是当前Drawcall用到的纹理数据。这个工具可以显示每个Drawcall的耗时,因此可以用来检查哪些对象渲染耗时太高。进而分析是Shader原因,还是网格体太复杂等等。
使用Profiler精确定位性能热点的优化技巧:https://blog.csdn.net/qq826364410/article/details/81292973
SnapdragonProfiler抓取游戏纹理和shader:https://blog.csdn.net/qq826364410/article/details/88555278
AdrenoProfiler抓取游戏纹理和shader:https://blog.csdn.net/qq826364410/article/details/88553830
二、渲染管线的优化策略
一旦确定了瓶颈位置,就可以对瓶颈所处阶段进行优化,以改善我们游戏的性能。主要分为下面两个大方向的优化:
- 对CPU的优化策略
- 对GPU的优化策略
- 对内存的优化策略
2.1 对CPU的优化策略
使用批处理技术减少DrawCall数目。批处理技术原理是减少每帧需要的DrawCall数目,即每次调用DrawCall时尽可能的处理多个物体。
2.1.1 动态批处理(Unity引擎)
Unity每一帧都会重新合并一次网格,再把合并好的模型数据传递给GPU,然后使用同一种材质对其渲染。经过动态批处理的物体仍然可以移动,这是因为每帧Unity都会重新合并一次网格。
动态批处理条件限制:
(1)进行批处理的网格顶点属性规模要小于900,如果Shader有三个属性,那么顶点数目不能超过300个。
(2)多Pass的Shader会中断批处理。在前向渲染中,我们有时需要使用额外的Pass来为模型添加更多的光照效果,这样一来,模型就不会被动态批处理了。
(3)批在一起的所有的模型应用同样的缩放值
(4)使用相同的材质
(5)相同的一张lightmap
(6)不能接收阴影
2.1.2 静态批处理
在运行开始的阶段,把需要进行静态批处理的模型合并到一个新的网格中,这意味着模型不能再运行时被移动。往往需要占用更多的内存来存储合并后的网格结构。应用静态批处理后,VBO(Vertex Buffer Object)顶点缓冲对象的数目变大了。
无论是动态批处理还是静态批处理,都要求模型之间需要共享同一个材质。如果两个材质之间只是使用的纹理不同,可以把这些纹理合并到一张更大的纹理中,这张更大的纹理叫做图集(atlas)。
补充:
DrawCall:
DrawCall是CPU通过底层图像编程接口发出的渲染命令,GPU读取渲染命令执行渲染操作。
过多的DrawCall影响绘制的原因:
主要是每次绘制时,CPU通过底层图像编程接口发出渲染命令DrawCall,而每个DrawCall需要很多准备工作,检测渲染状态、提交渲染数据、提交渲染状态,而GPU本身可以很快处理完渲染任务。DrawCall过多,CPU负载过多,而GPU性能闲置。
渲染状态:
渲染状态定义场景中的网格是怎样被渲染出来的。例如使用哪个顶点着色器、哪个片元着色器、光源属性、材质等。如果没有更改渲染状态,所有的网格将使用同一种渲染状态。
CPU发送DrawCall需要完成的操作:
- CPU可以向GPU发送命令以将多个已知的变量统一地转换为渲染状态。此命令称为SetPass调用。SetPass调用告诉GPU用于渲染下一个网格的设置。仅当要渲染的下一个网格需要从前一个网格更改渲染状态时,才会发送SetPass调用。
- CPU将绘图调用发送到GPU。绘图调用指示GPU使用最近的SetPass调用中定义的设置呈现指定的网格。
- 在某些情况下,一个批次可能有多次Pass。对于批次中的每个Pass,CPU必须发送新的SetPass调用,然后必须再次发送DrawCall。
同时,GPU执行以下工作:
- GPU按照发送顺序处理来自CPU的任务。
- 如果当前任务是SetPass调用,则GPU更新渲染状态。
- 如果当前任务是DrawCall,则GPU渲染网格。这是分阶段发生的,由着色器代码的不同部分定义。渲染的这一部分很复杂,我们不会详细介绍它,但是我们理解一段称为顶点着色器的代码告诉GPU如何处理网格的顶点,然后是一段代码称为片段着色器告诉GPU如何绘制单个像素。
- 重复此过程,直到GPU处理完所有从CPU发送的任务为止。
2.2 对GPU的优化策略
2.2.1 减少需要的顶点数目
(1)优化模型,尽可能的减少三角形的面数,移除不必要的硬边及纹理衔接,避免边界平滑和纹理分离。
边界平滑(smoothing splits,一个顶点可能会对应多个法线信息或切线信息,在Unity导入模型时,有一个Smoothing Angles(光滑组)的设置,当Smoothing Angles的值为0时,就没有共用的顶点,拆分出更多新的顶点,可以展示更多细节。当这个值越来越大,共用顶点越多,细节就更少一些。)
纹理分离(uv splits,一个顶点可能有多个纹理坐标。面与面的交界处使用的一些相同顶点,在不同面上,同一个顶点的纹理坐标可能并不相同 ,GPU会把这个顶点拆分成多个具有不同纹理坐标的顶点)。
(2)使用模型的LOD技术
LOD允许当模型逐渐远离摄像机时,减少模型上的面片数量,从而提高性能。
(3)使用遮挡剔除技术
消除在其他物体后面看不到的物体,也就不会渲染这个看不到的顶点,从而提高性能。注意:在移动平台,遮挡剔除开销太大,不建议使用。
(4)Camera.layerCullDistances
相机跟每一层的剔除距离。比如,在视野中有很多npc,可以把npc设置到npc层,并在代码中为npc层设置较小的layerCullDistances剔除距离,这样就可以只渲染npc层剔除距离内的npc,减少性能开销。
(5)视椎体越小越好,注意远裁减面的距离,顶点数量最多80k-100k之间
(6)Culling Mask ,剔除不需要渲染的层,减少性能开销
(7)使用视椎体检测,裁剪场景中不需要渲染的特效。
场景的中特效,在摄像机看不到的地方也在渲染,就会造成不必要的性能开销。
2.2.2 优化光照计算
考虑光照的影响可以每顶点,每像素的进行计算,光照计算可以通过多种方式进行优化:
- 实时光源越少越好,甚至不用实时光
- 利用离线烘焙,light mapping
- Spotlight(聚光灯)开销很大,少用
- 限制像素光的数量
- Culling Mask ,取消不需要进行光照计算的层
- 谨慎使用实时阴影
- 尽量用Hard Shadow
- 减少Shadow Distance
- 不用Shadow Castcade
补充:
Shadow Castcade
Shadow Castcade,就是远处的阴影用分辨率比较小的贴图,近处的阴影用分辨率比较大的贴图,提升了近处阴影的质量,但增加了性能开销。
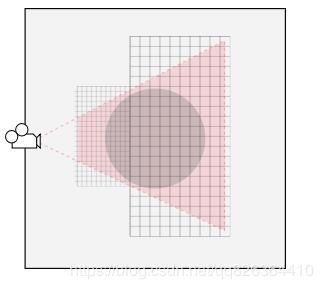
Shadow Distance
超出此距离的物体(来自相机)不投射阴影,因为远处的对象不需要渲染到阴影贴图中。将阴影距离设置的尽可能低,可以提高渲染性能。
2.2.3 加速片元着色
如果你正在使用长而复杂的片元着色器,那么往往瓶颈就处于片元着色器中。若果真如此,那么可以试试如下这些建议:
- 优先渲染深度。在渲染主要着色通道(Pass)前,先进行仅含深度的通道(depth-only (no-color) pass)的渲染,能显著地提高性能,尤其是在高深度复杂性的场景中。因为这样可以减少需要执行的片元着色量,以及帧缓冲存储器的存取量,从而提高性能。而为了发挥仅含深度的通道的全部优势,仅仅禁用颜色写入帧缓冲是远远不够的,同时也应该禁用所有片元的着色,甚至禁用影响到深度以及颜色的着色(比如 alpha test)。
- 帮助early-z优化(即Z缓冲优化),来避免多余片元处理 。现代GPU配有设计良好的芯片,以避免对被遮挡片元的着色,但是这些优化依赖场景知识。而以粗略地从前向后的顺序进行渲染,可以明显提高性能。以及,先在单独的pass中先渲染深度,通过将着色深度复杂度减少到1,可以有效地帮助之后的pass(主要的昂贵的shader计算的位置)进行加速。
- 把纹理作为查找表( lookup tables),存储数据。其实非常好用,而且可以无消耗地过滤它们的结果。一个典型例子便是单位立方体贴图,它仅允许以一个单一纹理查找的代价来高精度地对任意向量进行标准化。
- 将更多每片元的工作移到顶点着色器。对于优化的大方向而言,正如顶点着色器中的每个物体的计算量工作应该尽可能地移到CPU中一样,每顶点的计算也应该尽量被移到顶点着色器(连同在屏幕空间中线性插值计算)。常见的例子包括计算向量和坐标系之间的变换向量。
- 使用必需的最低精度。诸如DirectX之类的API允许我们在着色器代码中指定精度,以减少精度高所带来的额外计算量。很多GPU都可以利用这些提示来减少内部精度以及提高性能。
- 避免过度归一化(Normalization)。在写shader时,对每个步骤的每个矢量都进行归一化的习惯,常常被调侃为“以归一化为乐(Normalization-Happy)”。这个习惯通常来说其实是不太好的习惯。我们应该意识到不改变长度的变换(例如标准正交基上的变换)和不依赖矢量长度的计算(例如正方体贴图的查询)是完全没必要进行归一化后再进行的。
- 考虑使用片元着色器的LOD层次细节。虽然片元着色器的层次细节不像顶点着色器的层次细节影响那么大(由于投射,在远处物体本身的层次细节自然与像素处理有关),但是减少远处着色器的复杂性和表面的通道数,可以减少片元处理的负载。
- 在不必要的地方禁用三线性过滤。在现代GPU结构的片元着色器中计算三线性过滤(Trilinear filtering),即使不消耗额外的纹理带宽,也要消耗额外的循环。在mip级别转换不容易辨别的纹理上,关掉三线性过滤,可以节省填充率。
补充:
LUT(Look Up Table)指的是“颜色查找表”,是原始颜色通过LUT的颜色查找表映射到新的色彩上去。是单独针对色彩空间的一种管理和转换。
2.2.4 优化帧缓冲带宽
管线的最后阶段,片元操作或光栅化操作,与帧缓冲存储器直接衔接,是消耗帧缓冲带宽的主要阶段。因此如果带宽出了问题,经常会追踪到光栅化操作。下面几条技巧将讲到如何优化帧缓冲带宽。
- 首先渲染深度。这个步骤不但减少片元着色的开销,也会减少帧缓冲带宽的消耗。
- 减少Alpha混合,尽量不要使用Alpha测试。当alpha混合的目标混合因子非0时,则要求对帧缓冲区进行读取和写入操作,因此可能消耗双倍的带宽。所以只有在必要时才进行alpha混合,并且要防止高深度级别的alpha混合复杂性。
- 在移动平台,渲染透明物体,Alpha混合性能比Alpha测试更好。
- 尽可能关闭深度写入。深度写入会消耗额外的带宽,应该在多通道的渲染中被禁用(且多通道渲染中的最终深度已经在深度缓冲区中了)。比如在渲染alpha混合效果(例如粒子)时,也比如将物体渲染进阴影映射时,都应该关闭深度写入。另外,渲染进基于颜色的阴影映射也可以关闭深度读取。
- 避免无关的颜色缓冲区清除。如果每个像素在缓冲区都要被重写,那么就不必清除颜色缓冲区,因为清除颜色缓冲区的操作会消耗昂贵的带宽。但是,只要是可能就应该清除深度和模板缓冲区,这是因为许多早期z值优化都依赖被清空的深度缓冲区的内容。
- 默认大致上从前向后进行渲染。除了上文提到的片元着色器会从默认大致上从前向后进行渲染这个方法中受益外,帧缓冲区带宽也会得到类似的好处。早期z值硬件优化能去掉无关的帧缓冲区读出和写入。实际上,没有优化功能的老硬件也会从此方法中受益。因为通不过深度测试的片元越多,需要写入帧缓冲区的颜色和深度就越少。
- 优化天空盒的渲染。天空盒经常是帧缓冲带宽的瓶颈,因此必须决定如何对其进行优化,以下有两种策略:
(1)最后渲染天空盒,读取深度,但不写入深度,而且允许和一般的深度缓冲一起进行早期early-z优化,以节省带宽。(2)首先渲染天空盒,而且禁用所有深度读取和写入。
以上两种策略,究竟哪一种会节省更多开销,取决于目标硬件的功能和在最终帧中有多大部分的天空盒可见。如果大部分的天空盒被遮挡,那么策略(1)更好,否则,策略(2)可以节省更多带宽。 - 仅在必要时使用浮点帧缓冲区。显然,这种格式比起较小的整数格式来说,会消耗更多的带宽,所以,能不用就不用。对多渲染目标( Multiple Render Targets,MRT)也同样如此。
- 尽可能使用16位的深度缓冲区。深度处理会消耗大量带宽,因此使用16位代替32位是极有好处的,且16位对于小规模、不需要模板操作的室内场景往往就足够了。对于需要深度的纹理效果,16位深度缓冲区也常常足够渲染,如动态的立方体贴图。
- 尽可能使用16位的颜色。这个建议尤其适用于对纹理的渲染效果,因为这些工作的大多数,用16位的颜色能工作得很好,例如动态立方体贴图和彩色投射阴影贴图。
2.2.5 减少计算复杂度
(1)使用Shader的LOD技术
Shader的LOD技术可以控制使用的Shader等级。原理是只有Shader的LOD值小于某个设定值,这个Shader才会被使用。在某些情况下,我们可能需要去掉一些使用复杂计算的Shader渲染。这时,我们可以使用Shader.maximumLOD或Shader.globalMaximumLOD来设置允许的最大LOD值。
(2)代码方面的优化
- 尽可能使用低精度的浮点值进行计算。
- 使用插值寄存器把数据从顶点着色器传递给下一个阶段时,应该使用尽可能少的插值变量。
- 尽量不要使用全屏的屏幕后处理效果,如果真的需要使用,尽量使用低精度计算,高精度计算可以使用查找表(LUT)或者转移到顶点着色器中进行处理。
- 尽可能不要使用分支或循环语句。
- 尽可能避免使用类似sin、tan、pow、log等较为复杂的数学计算,请考虑使用查找纹理(lookup texture, LUT)作为复杂数学计算的替代方法。
2.3 对内存的优化策略
节省内存带宽
(1)减少纹理大小,考虑目标分辨率和纹理坐标,长宽值最好是2的整数幂。这样很多优化策略才可以发挥最大效用。
(2)针对不同平台,采用压缩纹理来减少纹理大小,可以加快加载速度,减少内存占用,显著提高渲染性能。
在不同移动GPU平台下选择GPU支持的压缩纹理,就可以在不需要CPU解压的情况下直接被GPU采样,节省CPU内存和带宽,也可以节省存储的体积。如果目标平台不支持设置的压缩格式,纹理将解压为RGBA32或者RGB24,浪费CPU时间和内存。
(3)利用Mip Maps,始终为3D场景中使用的纹理启用Mip Maps。但此规则例外的是:UI元素或2D游戏中,不要使用。
Mip Maps(多级渐远纹理),根据摄像机远近不同而生成对应的八个贴图,运行会加载到内存中。远离相机时,使用较模糊的纹理。使用Mip maps需要使用33%以上的内存,但不使用它会导致巨大的性能损失。
优点:优化显存带宽,用来减少渲染。因为可以根据距离摄像机远近,选择适合的贴图来渲染。
利用Mip maps,对处理锯齿和闪烁的很有用。
(3)对于特定机型进行分辨率缩放,Screen.SetResolution,过高的屏幕分辨率是造成性能下降的原因之一,尤其对于很多低端手机。
根据不同的硬件平台,设置不同的配置,控制特效显示,分辨率大小设置等等。