自编码神经网络相似图片检索
目的
传统的相似图片检索利用图片的统计特征对比图片, 检索的复杂度高,检索速度慢, 检索效果差。
为了高效准确,从端到端地对相似图片进行检索。本文利用为了降低分析的复杂性,加快检索速度
本文利用自编码神经网络和局部敏感hash算法对图片进行检索。
自编码神经网络
在有监督学习中,训练样本是有类别标签的。现在假设我们只有一个没有带类别标签的训练样本集合 ![]() ,其中
,其中 ![]() 。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如
。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如 ![]() 。下图是一个自编码神经网络的示例。通过训练,我们使输出
。下图是一个自编码神经网络的示例。通过训练,我们使输出 ![]() 接近于输入
接近于输入 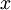 。当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张 张8*8 图像(共64个像素)的像素灰度值,于是 n=64,其隐藏层
。当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张 张8*8 图像(共64个像素)的像素灰度值,于是 n=64,其隐藏层 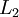 中有25个隐藏神经元。注意,输出也是64维的
中有25个隐藏神经元。注意,输出也是64维的 ![]() 。由于只有25个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从25维的隐藏神经元激活度向量
。由于只有25个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从25维的隐藏神经元激活度向量 ![]() 中重构出64维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入
中重构出64维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入 ![]() 都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。网络训练好以后,每一个输入
都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。网络训练好以后,每一个输入![]() 对应的LayerL2
对应的LayerL2 ![]() 就相当于降维后的数据。(跟pca理解差不多,只是pca 是线性降维,这里因为有sigmoid非线性激活函数的原因,所以这里应该可看做是非线性的降维。)
就相当于降维后的数据。(跟pca理解差不多,只是pca 是线性降维,这里因为有sigmoid非线性激活函数的原因,所以这里应该可看做是非线性的降维。)
python自编码神经网络代码实现
from keras.layers import Input, Dense from keras.models import Model, load_model import numpy as np def build_auto_encode_model(shape=[48 * 64 * 3], encoding_dim=100): ''' 建立自编码神经网络模型 :param shape: :param encoding_dim: :return: ''' input_img = Input(shape=shape) encoded = Dense(encoding_dim, activation='relu')(input_img) out_shape = np.product(shape) decoded = Dense(out_shape, activation='sigmoid')(encoded) autoencoder = Model(input=input_img, outputs=decoded) encoder = Model(inputs=input_img, outputs=encoded) autoencoder.compile(optimizer='adam', loss='binary_crossentropy') return encoder, autoencoder def train_auto_encode_model(X = np.load("data/train.npy"), encoder_model_path="./data/encoder.h5"): ''' 图片数据训练自编码神经网络 :param encoder_model_path: :return: ''' X = X.reshape(X.shape[0], -1) X_train = X[int(round(X.shape[0] * 0.2)):, :] X_test = X[0:int(round(X.shape[0] * 0.2)), :] encoder, autoencoder = build_auto_encode_model() autoencoder.fit(X_train, X_train, epochs=10, batch_size=256, shuffle=True, validation_data=(X_test, X_test)) encoder.save(encoder_model_path)
算法具体代码见github仓库https://github.com/zuoxiaolei/swj_room_match.git
利用自编码神经网络可以获取图片的底维空间的向量表示,把提取图片有用的特征作为后续相似图片对比的特征
https://github.com/zuoxiaolei/swj_room_match.git
https://github.com/zuoxiaolei/swj_room_match.git
https://github.com/zuoxiaolei/swj_room_match.git
局部敏感哈希算法(LSH)
LSH不像树形结构的方法可以得到精确的结果,LSH所得到的是一个近似的结果,因为在很多领域中并不需非常高的精确度。即使是近似解,但有时候这个近似程度几乎和精准解一致。LSH的主要思想是,高维空间的两点若距离很近,那么设计一种哈希函数对这两点进行哈希值计算,使得他们哈希值有很大的概率是一样的。同时若两点之间的距离较远,他们哈希值相同的概率会很小。
所有相似图片检索的代码见https://github.com/zuoxiaolei/swj_room_match.git
实验结果
query room id is data\image\00908484.pngsimilar room id is 01542568 and the distance is 4.084017746208701e-08
similar room id is 02960112 and the distance is 4.084017746208701e-08
similar room id is 07676626 and the distance is 4.084017746208701e-08
similar room id is 04738073 and the distance is 4.084017746208701e-08
similar room id is 06724367 and the distance is 4.084017746208701e-08

可以看到算法能在短时间内在大量图片中匹配到相似的图片