Hadoop(二) HDFS 底层原理解析
目录
HDFS概念
HDFS优缺点
优点
缺点
HDFS 架构/角色
Client:客户端
NameNode:master,它是一个主管、管理者
DataNode
Secondary NameNode
hdfs启动过程
启动脚本分析
HDFS启动过程--源码分析
HDFS 文件块大小
HDFS的元数据管理
NameNode 元数据存储机制
查看编辑日志
hdfs 不适合存储小文件
HDFS 辅助功能
心跳机制
安全模式
副本存放策略
负载均衡
HDFS读写原理
HDFS写入文件的过程分析
HDFS读取文件的过程分析
HDFS概念
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合用来做网盘应用。
HDFS优缺点
优点
1)高容错性
(1)数据自动保存多个副本。它通过增加副本的形式,提高容错性。
(2)某一个副本丢失以后,它可以自动恢复。
2)适合大数据处理
(1)数据规模:能够处理数据规模达到 GB、TB、甚至PB级别的数据。
(2)文件规模:能够处理百万规模以上的文件数量,数量相当之大。
3)流式数据访问
(1)一次写入,多次读取,不能修改,只能追加。
(2)它能保证数据的一致性。
4)可构建在廉价机器上,通过多副本机制,提高可靠性。
缺点
1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
2)无法高效的对大量小文件进行存储
(1)存储大量小文件的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
(2)小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标。
3)并发写入、文件随机修改
(1)一个文件只能有一个写,不允许多个线程同时写。
(2)仅支持数据 append(追加),不支持文件的随机修改。
HDFS 架构/角色
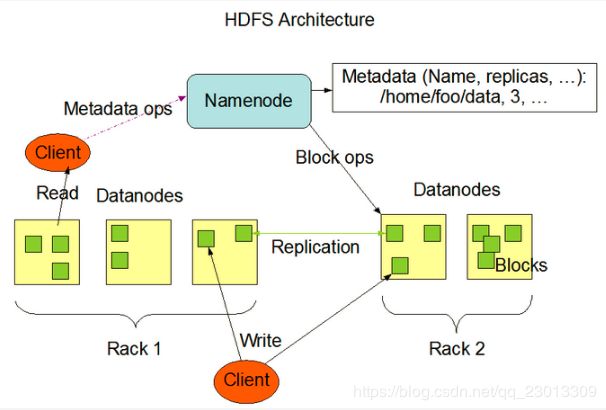
Client:客户端
(1)文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的Block,然后进行存储。
(2)与NameNode交互,获取文件的位置信息。
(3)与DataNode交互,读取或者写入数据。
(4)Client提供一些命令来管理HDFS,比如启动或者关闭HDFS。
(5)Client可以通过一些命令来访问HDFS。
NameNode:master,它是一个主管、管理者
(1)管理HDFS的名称空间。
(2)管理数据块(Block)映射信息
(3)配置副本策略
(4)处理客户端读写请求。
DataNode
Slave节点,NameNode下达命令,DataNode执行实际的操作
(1)存储实际的数据块。
(2)执行数据块的读/写操作。
Secondary NameNode
并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务
(1)辅助NameNode,分担其工作量。
(2)定期合并Fsimage和Edits,并推送给NameNode。
(3)在紧急情况下,可辅助恢复NameNode。
hdfs启动过程
启动脚本分析
start-dfs.sh
namenode: //单独启动 hadoop-daemon.sh start namenode
hdfs getconf -namenode //获取namenode节点
hadoop-daemons.sh --hostnames s101 start namenode ==> hadoop-daemon.sh start namenode
datanode: //单独启动 hadoop-daemons.sh start datanode
hadoop-daemons.sh start datanode
secondarynamenode: //单独启动hadoop-daemon.sh start secondarynamenode
hdfs getconf -secondarynamenodes 2>/dev/null //获取2nn节点地址
hadoop-daemons.sh --hostnames 0.0.0.0 start secondarynamenode ==> hadoop-daemon.sh start secondarynamenode
启动namenode
0)namenode先进入安全模式,在此模式下,文件均处于只读状态
1)namenode将fsimage文件加载到内存
2)将edits_inprogress实例化为edits文件
3)namenode将edits文件加载到内存
4)将fsimage文件与edits文件进行融合,通过旧的fsimage文件重现edits文件的操作步骤,生成新的fsimage文件
5)退出安全模式,文件可写

HDFS启动过程--源码分析
HDFS 文件块大小
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M。
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小128MB
HDFS的元数据管理
NameNode 元数据存储机制
A、内存中有一份完整的元数据(内存 metadata)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在 namenode 的工作目录中)
C、用于衔接内存 metadata 和持久化元数据镜像 fsimage 之间的操作日志(edits 文件)
(PS:当客户端对 hdfs 中的文件进行新增或者修改操作,操作记录首先被记入 edits 日志 文件中,
当客户端操作成功后,相应的元数据会更新到内存 metadata 中)
操作日志(存放在硬盘中):
数据历史操作日志文件: edits_000000000000000000*, 可通过运算日志文件算出元数据
每次滚动都会产生一些历史操作日志文件
预写操作日志文件:edits_inprogress_0000000000000000*(当前正在使用的编辑日志文件)
磁盘元数据镜像文件:fsimage_0000000000000000*
元数据与操作日志存在下列关系:
fsimage = 所有的历史操作日志文件之和
metadata = 最新fsimage + edits_inprogress_0000000000000000*
metadata = 所有的历史操作日志文件之和 + edits_inprogress_0000000000000000*
日志滚动:
1.滚动正在使用的编辑日志edits_inprogress_0000000000000000*, 生成新的历史操作日志文件edits_000000000000000000*
并产生一个新的正在使用的编辑日志edits_inprogress_0000000000000000*
2.将所有的历史操作日志文件edits_000000000000000000*与正在使用镜像文件fsimage_0000000000000000* 加载到内存进行合并
最终产生一个检查点文件 *.ckpt
3.将检查点文件发送到namenode, namenode将其重命名为新的镜像文件
查看编辑日志
edits:编辑日志
hdfs oev -i -o
-63
OP_START_LOG_SEGMENT
38233
fsimage
hdfs oiv -i -o
1000
4602
0
1073745405
38232
28077
16385
DIRECTORY
1571783352984
centos:supergroup:rwxr-xr-x
9223372036854775807
-1
...
1073742492
1668
378
hdfs 不适合存储小文件
HDFS集群的namenode中存储元数据的信息,元数据的信息主要包括以下3部分:
1)抽象目录树
文件和目录自身的属性信息,例如文件名、目录名、父目录信息、文件大小、创建时间、修改时间等。
2)文件和数据块的映射关系,一个数据块的元数据大小大约是150byte
3)数据块的多个副本存储地
件内容存储相关信息,例如文件块情况、副本个数、每个副本所在的Data Node 信息等
假设元数据的大小是150byte
对于100个1M的小文件其元数据大小是 100 * 150byte, 也就是用了15k才存储100M的文件
对于1个100M的大文件,其元据大小是150byte, 也就是我只使用了150byte就可以存储100M的文件
由此可以看出hdfs不适合存储小文件,存储小文件就是浪费namenode内存空间,而且也不利于hdfs查找文件
HDFS 辅助功能
心跳机制
1、 Hadoop 是 Master/Slave 结构,Master 中有 NameNode 和 ResourceManager,Slave 中有 Datanode 和 NodeManager
2、 Master 启动的时候会启动一个 IPC(Inter-Process Comunication,进程间通信)server 服 务,等待 slave 的链接
3、 Slave 启动时,会主动链接 master 的 ipc server 服务,并且每隔 3 秒链接一次 master,这 个间隔时间是可以调整的,参数为 dfs.heartbeat.interval,这个每隔一段时间去连接一次 的机制,我们形象的称为心跳。Slave 通过心跳汇报自己的信息给 master,master 也通 过心跳给 slave 下达命令,
4、 NameNode 通过心跳得知 Datanode 的状态 ,ResourceManager 通过心跳得知 NodeManager 的状态
5、 如果 master 长时间都没有收到 slave 的心跳,就认为该 slave 挂掉了。
最终NameNode判断一个DataNode死亡的时间计算公式:
timeout = 10 * 心跳间隔时间 + 2 * 检查一次消耗的时间
心跳间隔时间:dfs.heartbeat.interval 心跳时间:3s,检查一次消耗的时间:heartbeat.recheck.interval checktime : 5min,最终宕机之后630s后显示死亡状态。
安全模式
1、HDFS的启动和关闭都是先启动NameNode,在启动DataNode,最后在启动secondarynamenode。
2、决定HDFS集群的启动时长会有两个因素:
1)磁盘元数据的大小
2)datanode的节点个数
当元数据很大,或者 节点个数很多的时候,那么HDFS的启动,需要一段很长的时间,那么在还没有完全启动的时候HDFS能否对外提供服务?
在HDFS的启动命令start-dfs.sh执行的时候,HDFS会自动进入安全模式
为了确保用户的操作是可以高效的执行成功的,在HDFS发现自身不完整的时候,会进入安全模式。保护自己。
在正常启动之后,如果HDFS发现所有的数据都是齐全的,那么HDFS会启动的退出安全模式
3、对安全模式进行测试
安全模式常用操作命令:
hdfs dfsadmin -safemode leave //强制 NameNode 退出安全模式
hdfs dfsadmin -safemode enter //进入安全模式
hdfs dfsadmin -safemode get //查看安全模式状态
hdfs dfsadmin -safemode wait //等待,一直到安全模式结束4、安全模式下测试上传下载,得出结论:
如果一个操作涉及到元数据的修改的话。都不能进行操作,如果一个操作仅仅只是查询。那是被允许的。所谓安全模式,仅仅只是保护namenode,而不是保护datanode。
副本存放策略
第一副本:放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上;
第二副本:放置在于第一个副本不同的机架的节点上;
第三副本:与第二个副本相同机架的不同节点上;
如果还有更多的副本:随机放在节点中;
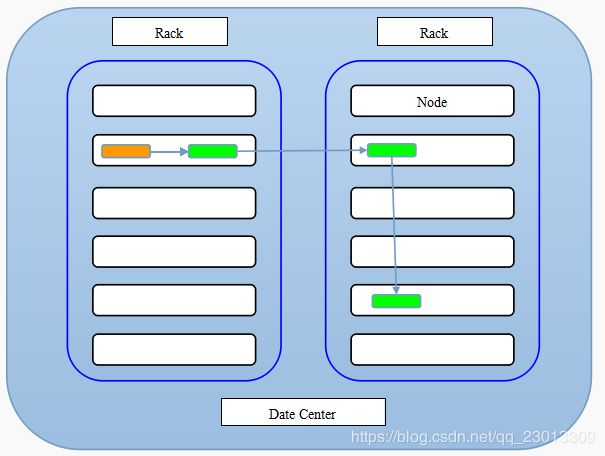
负载均衡
HDFS读写原理
HDFS写入文件的过程分析
1、使用 HDFS 提供的客户端 Client,向远程的 namenode 发起 RPC 请求
2、namenode 会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会 为文件创建一个记录,否则会让客户端抛出异常;
3、当客户端开始写入文件的时候,客户端会将文件切分成多个 packets,并在内部以数据队列“data queue(数据队列)”的形式管理这些 packets,并向 namenode 申请 blocks,获 取用来存储 replicas 的合适的 datanode 列表,列表的大小根据 namenode 中 replication 的设定而定;
每个packet大小 = 33byte(头) + 504byte(126个校验和空间) + 63K(126个chunk) < 64K---packet取值64k
4、开始以 pipeline(管道)的形式将 packet 写入所有的 replicas 中。客户端把 packet 以流的 方式写入第一个 datanode,该 datanode 把该 packet 存储之后,再将其传递给在此 pipeline 中的下一个 datanode,直到最后一个 datanode,这种写数据的方式呈流水线的形式。
5、最后一个 datanode 成功存储之后会返回一个 ack packet(确认队列),在 pipeline 里传递 至客户端,在客户端的开发库内部维护着"ack queue",成功收到 datanode 返回的 ack packet 后会从"data queue"移除相应的 packet。
6、如果传输过程中,有某个 datanode 出现了故障,那么当前的 pipeline 会被关闭,出现故 障的 datanode 会从当前的 pipeline 中移除,剩余的 block 会继续剩下的 datanode 中继续 以 pipeline 的形式传输,同时 namenode 会分配一个新的 datanode,保持 replicas 设定的 数量。
7、客户端完成数据的写入后,会对数据流调用 close()方法,关闭数据流;
8、只要写入了 dfs.replication.min(最小写入成功的副本数)的复本数(默认为 1),写操作 就会成功,并且这个块可以在集群中异步复制,直到达到其目标复本数(dfs.replication 的默认值为 3),因为 namenode 已经知道文件由哪些块组成,所以它在返回成功前只需 要等待数据块进行最小量的复制。
HDFS读取文件的过程分析
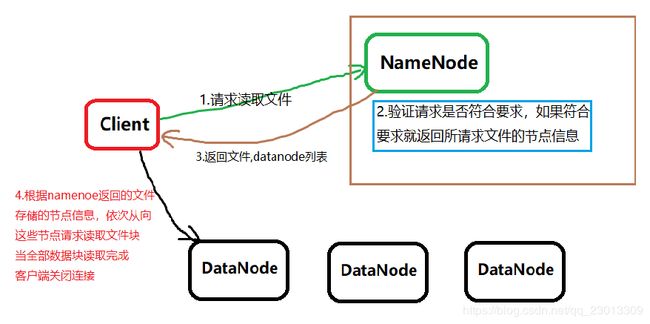
1、客户端调用FileSystem 实例的open 方法,获得这个文件对应的输入流InputStream。
2、通过RPC 远程调用NameNode ,获得NameNode 中此文件对应的数据块保存位置,包括这个文件的副本的保存位置( 主要是各DataNode的地址) 。
3、获得输入流之后,客户端调用read 方法读取数据。选择最近的DataNode 建立连接并读取数据。
4、如果客户端和其中一个DataNode 位于同一机器(比如MapReduce 过程中的mapper 和reducer),那么就会直接从本地读取数据。
5、到达数据块末端,关闭与这个DataNode 的连接,然后重新查找下一个数据块。
6、不断执行第2 - 5 步直到数据全部读完。
7、客户端调用close ,关闭输入流DFS InputStream。