模型压缩与加速的知识结构图与重要论文
从一个比较大的层面看一下模型压缩与加速的知识结构图,梳理一下模型压缩与加速的知识结构。
总的来说,模型压缩与加速分为四大部分,分别是剪枝、量化、低秩和蒸馏。
剪枝
剪枝的目标是减少神经网络中的权重数/特征数,去除相对不重要的权值,减小网络大小同时可以加速运算。
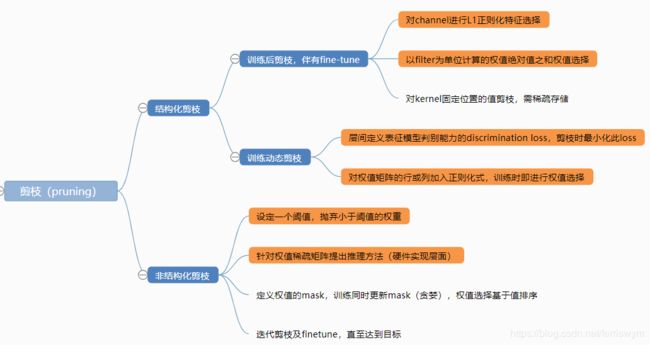
剪枝总体而言分为结构化剪枝和非结构化剪枝,结构化剪枝以整个channel/filter为单位裁剪,在实现时即可做到缩小网络结构的目的;非结构化剪枝则以单个特征/权值为单位裁剪,因而需要引入稀疏矩阵的实现才可以实现压缩。
量化
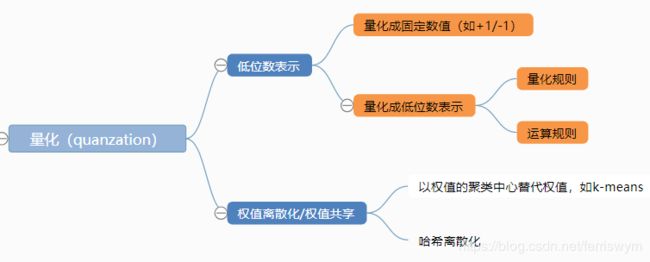
量化的主要目的是用低位数来表示原有的权值/激活值,从而加速运算并压缩网络。量化有两大类思路,一种是用低精度的数表示原来用浮点数表示的权值,另一种是用权值共享的方法,存储离散权值的表以及其索引,在存储网络时则以索引代替值进行存储,达到压缩效果。由于后者并不具备理论上的加速,因而第一种思路为多。
低秩分解
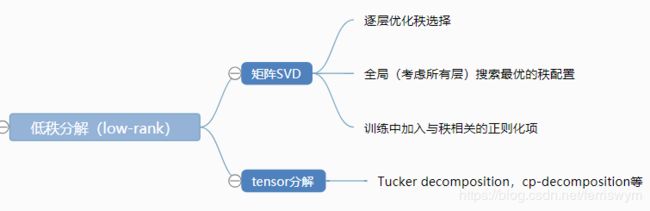
低秩分解的目的是用更少的秩来表示原有矩阵,达到压缩效果。绝大部分低秩分解的研究是基于SVD。
知识蒸馏
蒸馏的思想源于Hinton在2015的一篇论文,属于迁移学习。其主要思想是把teacher模型的知识迁移训练student模型,由于student模型不限定大小,因而也可以达到压缩和加速效果。

以上是目前模型压缩与加速方向的研究,即在既有模型上通过一定方法压缩模型得到一个精度损失可接受的小模型。
还有一类研究思路是从设计模型时就设计成轻量级网络结构的,典型的如MobileNet、ShuffleNet、SqueezeNet。
另外还有一部分研究,是通过自动化搜索优化网络结构,通过自动化设计网络来达到压缩网络的,可以用强化学习或者进化算法。但此部分研究由于耗用资源大,目前并未看到太多。
重要论文:
剪枝:
[1]. He Y, Zhang X, Sun J. Channel pruning for accelerating very deep neural networks[C]//International Conference on Computer Vision (ICCV). 2017, 2(6).
[2]. Luo J H, Wu J, Lin W. Thinet: A filter level pruning method for deep neural network compression[J]. arXiv preprint arXiv:1707.06342, 2017.
[3]. Li H, Kadav A, Durdanovic I, et al. Pruning filters for efficient convnets[J]. arXiv preprint arXiv:1608.08710, 2016.
[4]. Han S, Mao H, Dally W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding[J]. arXiv preprint arXiv:1510.00149, 2015.
[5]. Zhuang Z, Tan M, Zhuang B, et al. Discrimination-aware Channel Pruning for Deep Neural Networks[C]//Advances in Neural Information Processing Systems. 2018: 881-892.
[6]. Pan W, Dong H, Guo Y. Dropneuron: simplifying the structure of deep neural networks[J]. arXiv preprint arXiv:1606.07326, 2016.
[7]. Han S, Liu X, Mao H, et al. EIE: efficient inference engine on compressed deep neural network[C]//Computer Architecture (ISCA), 2016 ACM/IEEE 43rd Annual International Symposium on. IEEE, 2016: 243-254.
量化:
[8]. Courbariaux M, Bengio Y, David J P. Binaryconnect: Training deep neural networks with binary weights during propagations[C]//Advances in neural information processing systems. 2015: 3123-3131.
[9]. Courbariaux M, Hubara I, Soudry D, et al. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or -1[J]. arXiv preprint arXiv:1602.02830, 2016.
[10]. Zhou A, Yao A, Guo Y, et al. Incremental network quantization: Towards lossless cnns with low-precision weights[J]. arXiv preprint arXiv:1702.03044, 2017.
[11]. Jacob B, Kligys S, Chen B, et al. Quantization and training of neural networks for efficient integer-arithmetic-only inference[J]. arXiv preprint arXiv:1712.05877, 2017.
低秩:
[12]. Kim H, Karim M U, Kyung C M. A Framework for Fast and Efficient Neural Network Compression[J]. arXiv preprint arXiv:1811.12781, 2018.
[13]. Kim Y D, Park E, Yoo S, et al. Compression of deep convolutional neural networks for fast and low power mobile applications[J]. arXiv preprint arXiv:1511.06530, 2015.
蒸馏:
[14]. Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv preprint arXiv:1503.02531, 2015.
[15]. Crowley E J, Gray G, Storkey A J. Moonshine: Distilling with cheap convolutions[C]//Advances in Neural Information Processing Systems. 2018: 2890-2900.
其它:
[16]. He Y, Lin J, Liu Z, et al. Amc: Automl for model compression and acceleration on mobile devices[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 784-800.
[17]. Real E, Aggarwal A, Huang Y, et al. Regularized evolution for image classifier architecture search[J]. arXiv preprint arXiv:1802.01548, 2018.
腾讯的PocketFlow有部分方法的实现代码:https://github.com/Tencent/PocketFlow