Python机器学习:数据科学,机器学习和人工智能的主要发展技术趋势概述
1.介绍
Python因易于学习而广为人知,并且它仍然是数据科学,机器学习和科学计算中使用最广泛的语言。根据最近的一项民意的调查,该调查对1,800多名研究人员分析,数据科学和机器学习偏好的参与者进行了调查,Python在2019 保持其依然使用最广泛的编程语言。
然而,Python编译器和解释器使用最广泛的实现CPython在单个线程中执行CPU绑定代码,并且其多处理程序包还伴随着其他重大的性能折衷。
PyPy 是Python语言的CPython实现的替代方法 。与CPython的解释器不同,PyPy是即时(JIT)编译器,能够使Python代码的某些部分运行得更快。根据PyPy自己的基准测试,在平均pypy2020上,它运行代码的速度是CPython的 四倍。不幸的是,PyPy不支持Python的最新版本(与最新的3.8稳定版本相比,截至本文撰写时支持3.6)。由于PyPy仅与选定的Python库库兼容1http://packages.pypy.org,它通常被认为对数据科学,机器学习和深度学习没有吸引力。
现在收集和生成的数据量非常庞大,而且数量还在以创纪录的速度增长,这导致人们需要使用性能出色且易于使用的工具。充分利用Python的优势(例如在确保计算效率的同时易于使用)的最常见方法是开发高效的Python库,以实现用静态类型的语言(如Fortran,C / C ++和CUDA)编写的低级代码。近年来,在用于科学计算和机器学习的高性能但用户友好的库的开发上花费了大量的精力。
本文的目的是通过向读者简要介绍当前在Python机器学习领域中最相关的主题和趋势来丰富读者。我们对该领域的调查,总结了一些重大挑战,分类法和方法。在本文中,我们旨在在学术研究和行业主题之间找到平衡,同时重点介绍最相关的工具和软件库。但是,这既不是全面的说明,也不是方法,研究或可用库的详尽列表。假定不具备Python知识,但是对计算,统计和机器学习有所了解将是有益的。
本文旨在提供涵盖该领域广度的主要主题的概述。尽管可以单独阅读每个主题,但是鼓励感兴趣的读者按顺序进行阅读,因为它可以提供将技术挑战的演变与其最终解决方案联系在一起的附加好处,以及隐含的趋势的历史和计划背景。叙事。
1.1PYTHON中的科学计算和机器学习
机器学习和科学计算应用通常使用多维数组上的线性代数运算表示,多维数组是用于表示矢量,矩阵和高阶张量的计算数据结构。由于这些操作通常可以在许多处理核心上并行化,因此诸如NumPy之类的库
Oliphant2007和SciPy 2020SciPy-NMeth利用C / C ++,Fortran和第三方BLAS实现在可能的情况下绕过线程和其他Python限制。NumPy是具有基本线性代数例程的多维数组库,SciPy库将NumPy数组装饰有许多重要的原语,从数值优化器和信号处理到统计和稀疏线性代数。截至2019年,发现GitHub virtanen2020scipy上几乎所有机器学习项目中都使用了SciPy。
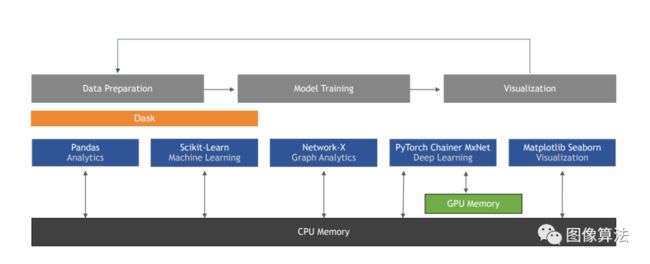
图1:用于机器学习,数据科学和科学计算的标准Python生态系统。
虽然NumPy和Pandas mckinny(图 1)都提供了对数据点集合的抽象,并且其操作对整个数据集都有效,但Pandas通过提供支持异类列类型以及行和列元数据的类数据框对象扩展了NumPy。近年来,Pandas库已成为事实上的格式,用于表示Python中的表格数据以进行提取,转换和加载。
(ETL)上下文和数据分析。自2008年首次发布12年后,又是25个版本之后,熊猫的第一个1.0版本于2020年发布。语义版本控制标准 preston2013semantic(1.0版)表明,库已达到成熟度的主要水平,并具有稳定的API。
尽管NumPy的第一个版本已于25年前发布(以其先前的名称为Numeric),但与Pandas相似,它仍在积极地开发和维护。2017年,NumPy开发团队从摩尔基金会获得了645,000美元的赠款,以帮助进一步开发和维护numfocus2017numpy库 。在撰写本文时,Pandas,NumPy和SciPy仍然是许多数据科学和计算项目中最人性化和推荐的选择。
1.2优化PYTHON在数值计算和数据处理方面的性能
除了其线程限制外,CPython解释器还没有充分利用现代处理器硬件,因为它需要与fedotov2016speeding的大量计算平台 兼容。针对CPU的特殊优化指令集(例如Intel的Streaming SIMD扩展(SSE)和IBM的AltiVec)在许多低级库规范下使用,例如二进制线性代数子例程(BLAS) blackford2002 updated和线性代数包(LAPACK) angerson1990 lapack库,用于有效的矩阵和向量运算。
OpenBLAS的开发上投入了大量心血,OpenBLAS是BLAS API的开源实现,它支持多种不同的处理器类型。尽管所有主要的科学库都可以通过OpenBLAS集成openblas2020进行编译,但是 不同CPU指令集的制造商通常还会提供自己的BLAS和LAPACK子例程的硬件优化实现。例如,英特尔的数学内核库(Intel MKL) intel2020mkl和IBM的Power ESSL diefendorff2000altivec为科学计算应用程序提供可插拔的效率。这种标准化的API设计提供了可移植性,这意味着通过针对不同的实现构建,相同的代码可以在具有不同指令集的不同体系结构上运行。
当数字库(例如NumPy和SciPy)通过硬件优化的子例程获得显着的性能提升时,性能提升会自动扩展到更高级别的机器学习库(例如Scikit-lear),后者主要使用NumPy和SciPy Pedregosa FABIANPEDREGOSA 2011;buitinck2013api。英特尔还提供了一个面向高性能科学计算的Python发行版,其中包括MKL加速 intel2020 python较早前提过。该Python发行版背后的吸引力在于它是免费使用的,可以直接使用,可以加速Python本身,而不是挑选大量的库,并且可以代替标准CPython发行版而无需任何代码需要更改。但是,主要缺点之一是仅限于Intel处理器。
一次操作一组值(而不是单个值)的机器学习算法的开发通常也称为向量化。前述的CPU指令集通过使处理器有可能在多个数据点上并行调度单个指令,而不必为每个数据点调度不同的指令,从而实现矢量化。将单个指令应用于多个数据点的向量运算也称为单指令多数据(SIMD),自1960年代以来,它已存在于并行和高性能计算领域。SIMD范式在库中进一步通用化,用于扩展数据处理工作负载,例如MapReduce dean2008 mapreduce,Spark Zaharia和Dask Rocklin2015,其中将相同的数据处理任务应用于数据点的集合,以便可以并行处理它们。一旦组成,数据处理任务可以在线程或进程级别执行,从而使并行性能够跨越多个物理机。
Pandas的数据框格式使用列来分隔数据集中的不同字段,并允许每一列具有不同的数据类型(在NumPy的ndarray容器中,所有项目都具有相同的类型)。与其连续地将每个记录的字段(例如,在逗号分隔值(CSV)文件中)存储在一起,它不连续地存储列。通过按列连续布置数据,可以通过允许处理器对行级处理的内存访问进行分组或合并来启用SIMD,从而有效利用缓存,同时减少了对主内存的访问次数。
用于内存中数据的Apache Arrow跨语言开发平台 apache2020 arrow对列格式进行了标准化,以便可以在不同的库之间共享数据,而无需花费一定的成本来复制和重新格式化数据。另一个利用列格式的库是Apache Parquet apache2020 parquet。诸如Pandas和Apache Arrow之类的库在设计时考虑到了内存使用,而Parquet则主要是为数据序列化和存储在磁盘上而设计的。Arrow和Parquet彼此兼容,现代高效的工作流程涉及Parquet,用于将磁盘上的数据文件加载到Arrow的列式数据结构中进行内存计算。
类似地,NumPy支持基于行和列的布局,其n维数组(ndarray)格式也将下面的数据与对其进行操作的操作分开。这使NumPy中的大多数基本操作都可以使用SIMD处理。
Dask和Apache Spark zaharia2016 apache为可扩展到多个节点的数据帧和多维数组提供了抽象。与Pandas和NumPy相似,这些抽象也将数据表示与处理操作的执行分开。通过将数据集视为可以在可用硬件上安排的数据转换任务的有向无环图(DAG),可以实现这种分离。Dask之所以吸引许多数据科学家,是因为其API受到Pandas的极大启发,因此很容易集成到现有的工作流程中。但是,喜欢对现有代码进行最少更改的数据科学家也可以考虑使用Modin(https://github.com/modin-project/modin)它可以直接替换Pandas DataFrame对象,即modin.pandas.DataFrame。Modin的DataFrame具有与Pandas相同的API,但是它可以利用外部框架在后台进行分布式数据处理,例如Ray 2020或Dask。开发人员的基准显示,与Pandas相比,在具有四个物理内核modin2020modin的笔记本电脑上,数据处理速度最高可提高四倍 。
本文的其余部分安排如下。在讨论使它既简单又高效的优化方法之前,下一节将介绍Python作为科学计算和机器学习的工具。第2节 介绍了如何将Python用于常规机器学习。第3节 介绍了通过AutoML自动化机器学习管道构建和实验的最新进展。在第4节 ,我们将讨论GPU加速的科学计算和机器学习的发展,以提高计算性能以及由此带来的新挑战。专注于专注于GPU加速的深度神经网络(DNN)训练的机器学习子领域,我们将在第5节中讨论深度学习 。近年来,机器学习和深度学习技术在许多领域都达到了最先进的水平,但是与传统方法相比,这些技术经常被引用的缺点是缺乏可解释性和可解释性。在第6节中 ,我们重点介绍一些使机器学习模型及其预测更可解释的新颖方法和工具。最后,第7节 简要概述了对抗性学习领域的最新发展,旨在使机器学习和深度学习变得更加健壮,其中健壮性是许多与安全相关的实际应用程序中的重要属性。
2.经典机器学习
深度学习代表机器学习的一个子类别,该子类别专注于DNN的参数化。为了提高清晰度,我们将基于非深度学习的机器学习称为经典机器学习(经典ML),而机器学习是一个概括性术语,包括深度学习和经典ML。
尽管在过去几年中深度学习已迅速普及,但是经典ML(包括决策树,随机森林,支持向量机等)在不同的研究领域和行业中仍然非常流行。在大多数应用中,从业人员使用的数据集不适用于当代深度学习方法和体系结构。深度学习对于处理大型非结构化数据集(例如文本和图像)特别有吸引力。相反,大多数经典机器学习技术是在头脑中的结构化数据;也就是说,以表格形式的数据,其中训练示例存储为行,而随附的观察值(特征)存储为列。
在本节中,我们将回顾Scikit-learn的最新发展,Scikit-learn仍然是经典ML最受欢迎的开源库之一。在简短介绍了Scikit-learn核心库之后,我们讨论了开源社区开发的几个扩展库,重点是用于处理类不平衡,集成学习和可扩展的分布式机器学习的库。
2.1SCIKIT-LEARN,经典机器学习的行业标准
Scikit-learn Pedregosa FABIANPEDREGOSA 2011(图 1)已成为行业标准Python库,用于对中小型数据集进行特征工程和经典ML建模,
在此情况下,根据经验,我们认为训练少于1000的数据集小型示例,
而数据集包含中等规模的1000到100,000个示例
因为它具有干净,一致且直观的API,因此在很多方面都是如此。此外,在开源社区的帮助下,Scikit学习团队仍将重点放在代码质量和综合文档上。开拓简单的“ fit() / 预测()API模型,其设计成为许多库的灵感和蓝图,因为它呈现出熟悉的面孔并在用户探索不同的建模选项时减少了代码更改。
除了用于数据处理和建模的众多类(称为估计器)外,Scikit-learn还包括一流的API,用于统一机器学习管道的构建和执行:管道API(图 2)。
它使一组估计器可以包括数据处理,特征工程和建模估计器,这些估计器可以组合起来以端到端的方式执行。此外,Scikit-learn提供了一个API,用于使用诸如交叉验证之类的通用技术评估经过训练的模型。

图2: Scikit学习管道的图示。一个代码示例,展示了如何从Iris数据集中拟合线性支持向量机特征,这些特征已通过z-score归一化进行了归一化,然后使用管道对象通过主成分分析压缩到了两个新的特征轴上。
b)说明了对训练数据执行拟合方法和对测试数据执行预测方法时管道内部的各个步骤。
为了在提供有用的功能和维护高质量代码的能力之间找到适当的平衡,Scikit-learn开发团队仅考虑将完善的算法纳入库中。然而,过去十年来机器学习和人工智能研究的爆炸式增长创造了许多算法,最好将其作为扩展而不是集成到核心中。更新的和通常为人所知的算法是作为Scikit-learn兼容库或所谓的“ Scikit-contrib”包提供的,后者由Scikit-learn社区在共享的GitHub组织Scikit-learn-contrib下(https://github.com/scikit-learn-contrib)当这些单独的软件包遵循Scikit-learn API时,它们可以从Scikit-learn生态系统中受益,使用户能够免费继承Scikit-learn的某些高级功能,例如流水线和交叉验证。
在以下各节中,我们重点介绍其中一些最著名的,与Scikit-learn兼容的库。
2.2解决班级失衡
当使用真实数据集Lematre 2016时,倾斜的类标签分布是最重大的挑战 之一。这样的标签分布偏斜或类别失衡会导致强烈的预测偏差,因为模型可以通过学习大多数时间来预测多数标签来优化训练目标。为防止此问题,通常手动实施重采样技术以平衡标签。修改数据还需要验证哪种重采样策略对结果模型产生最积极的影响,同时确保不会由于重采样而引入其他偏差。
不平衡学习Lematre2016 是Scikit-contrib库,用于通过四种用于平衡偏斜数据集中的类的技术来解决上述问题。前两种技术通过减少造成过分代表类的数据样本的实例数(欠采样)或生成代表不足类的新数据样本(过采样)来对数据进行重新采样。由于过采样往往会训练过拟合数据的模型,因此第三种技术将过采样与清除欠采样技术结合在一起,从而消除了大多数分类中的极端离群值。不平衡学习为平衡类提供的最终技术是将袋装与AdaBoost相结合
Galar2011,其中模型集合是由多数类的不同欠采样集合构成的,而少数类的整个数据集则用于训练每个学习者。此技术允许将来自过多代表的类的更多数据用作单独重采样的替代方法。尽管研究人员在此方法中使用AdaBoost,但此方法的潜在增强可能涉及其他集成技术。在下一节中,我们将讨论最近开发的集成方法的实现。
2.3集成学习:梯度提升机和模型组合
被称为集成技术的多种机器学习算法或模型的组合被广泛用于提供稳定性,提高模型性能以及控制偏差-方差折衷
raschka 2018 model。众所周知,高度可并行化的引导聚合元算法(也称为装袋) breiman1996 bagging的集成技术传统上已用于诸如随机森林 breiman2001 random之类的算法中
对单个决策树的预测取平均,同时成功减少过度拟合。与装袋相反,增强型元算法本质上是迭代的,可以逐步拟合弱学习者,例如预修剪的决策树,其中模型会根据先前迭代的较差预测(叶节点)相继进行改进。梯度增强对早期的自适应增强算法(例如AdaBoost)进行了改进
freund1995年的决定,通过添加梯度下降的元素来逐步建立新的模型,该模型优化了与以前的迭代 Friedman2001中的误差有区别的成本函数 。
最近,在许多Kaggler的工具带中,梯度提升机(GBM)已成为 瑞士军刀;陈2016。梯度提升的一个主要性能挑战是它是一种迭代而不是并行算法,例如装袋。梯度提升算法中另一个耗时的计算是在构造决策树Ke时评估用于分割节点的不同特征阈值 。Scikit-learn的原始梯度提升算法特别低效,因为它会枚举每个功能的所有可能分割点。这种方法被称为精确贪婪
该算法昂贵,浪费内存,无法很好地扩展到较大的数据集。由于Scikit-learn的实现存在明显的性能缺陷,因此出现了XGBoost和LightGBM之类的库,它们提供了更有效的替代方法。当前,这是用于梯度提升机的两个最广泛使用的库,并且它们都与Scikit-learn很大程度上兼容。
XGBoost于2014年Chen2016引入开源社区, 并为精确的贪婪拆分查找算法提供了有效的近似值,该算法仅在每个节点上使用一部分可用的训练示例将特征分类为直方图。LightGBM被介绍给开源社区在2017年,并在深度优先的方式建立的树木,而不是使用广度优先的方法,因为它在许多其他GBM库进行 柯。LightGBM还实施了升级的拆分策略,以使其与XGBoost竞争,XGBoost是当时使用最广泛的GBM库。LightGBM拆分策略的主要思想是仅保留具有较大渐变的实例,因为它们对信息增益的贡献最大,而对较低渐变的实例进行了欠采样。这种更有效的采样方法有可能显着加快训练过程。
XGBoost和LightGBM都支持分类功能。虽然LightGBM可以直接解析它们,但是XGBoost要求类别必须是一键编码的,因为其列必须是数字。这两个库均包含可有效利用稀疏特征(例如已进行一次热编码的稀疏特征)的算法,从而可以更有效地利用基础特征空间。Scikit-learn(v0.21.0)最近还添加了新的梯度提升算法受LightGBM启发的HistGradientBoosing具有与LightGBM相似的性能,但唯一的缺点是它不能直接处理分类数据类型,并且需要类似于XGBoost的一键编码。
已经证明将多个模型组合到集合中可以提高泛化精度,并且如上所述,通过结合重采样方法/ citeraschka2019python可以改善类不平衡。模型组合是集成学习的一个子领域,它允许不同的模型为共享的目标做出贡献,而与构成它们的算法无关。例如,在模型组合算法中,逻辑回归模型可以与k最近邻分类器和随机森林组合。
堆叠算法是组合模型的一种较常用的方法,它在一组单个模型的预测上训练聚合器模型,以便学习如何将单个预测组合为一个最终预测 Wolpert1992。常见的堆叠变体还包括sill2009 feature元特性 或实现多层的lorbieski2018 impact堆叠 ,这也称为多层堆叠。自2016年以来,Mlxtend中已提供Scikit-learn兼容的堆栈分类器和回归器 raschka2018 mlxtend并且最近也在v0.22中添加到了Scikit-learn中。叠加的另一种选择是动态选择算法,该算法仅使用最胜任的分类器或整体来预测样本的类别,而不是组合预测 Cruz2018。
Combo是一个相对较新的专门用于集成学习的库,它在统一的Scikit-learn-compatible API下提供了几种常用算法,因此它与Scikit-learn生态系统zhao2019cominging的许多估计器都兼容。
Combo库提供了能够组合用于分类,聚类和异常检测任务的模型的算法,并且在Kaggle预测建模社区中已得到广泛采用。使用单个库(例如Combo)的好处是可以为方便的实验和模型比较提供便利,该库可以为不同的集成方法提供统一的方法,同时仍与Scikit-learn兼容。
2.4可扩展的分布式机器学习
尽管Scikit学习针对中小型数据集,但现代问题通常需要可以扩展到更大数据量的库。使用Joblib https://github.com/joblib/joblib ,可以通过Python的多处理并行化Scikit-learn中的一些算法。不幸的是,这些算法的潜在规模受限于一台机器上的内存和物理处理核心的数量。
Dask-ML通过Scikit-learn兼容的API提供了Scikit-learn的经典ML算法的子集的分布式版本。这些包括监督学习算法,如线性模型,无监督学习算法,如k均值,和降维算法,如主成分分析和截断奇异向量分解。Dask-ML使用多重处理,其附加好处是算法的计算可以分布在计算集群中的多个节点上。
许多经典的ML算法都与拟合一组参数有关,这些参数通常假定小于训练数据集中的数据样本数量。在分布式环境中,这是一个重要的考虑因素,因为模型训练通常需要各个工人共享本地状态时进行交流,以便收敛于一组全局学习参数。训练后,模型推理通常可以以令人尴尬的并行方式执行。
超参数调整是机器学习中非常重要的用例,需要在许多不同的配置上对模型进行训练和测试,以找到具有最佳预测性能的模型。如第2.3节所述,当组合多个模型时,并行训练多个较小模型的能力变得尤为重要,尤其是在分布式环境中 。
Dask-ML还提供了支持任何Scikit-learn兼容API的超参数优化(HPO)库。Dask-ML的HPO在Dask工人集群上分配针对不同参数配置的模型训练,以加快模型选择过程。第3节“自动机器学习” 中讨论了它使用的确切算法以及其他用于HPO的方法 。
PySpark将Apache Spark的MLLib的功能与Python的简单性结合在一起。尽管API的某些部分与Scikit-learn函数的命名约定有点相似,但该API与Scikit-learn不兼容 Meng1980。尽管如此,由于这种相似性,Spark MLLib的API仍然非常直观,使用户能够在分布式环境中轻松训练高级机器学习模型,例如推荐器和文本分类器。用Scala编写的Spark引擎在每个工作者上使用C ++ BLAS实现来加速线性代数运算。
与Dask和Spark这样的系统形成对比的是消息传递接口(MPI)。MPI提供了一个经过时间测试的标准API,可用于编写分布式算法,在该算法中,可以实时在工作线程(称为等级)之间传递内存位置,就好像它们是共享相同内存空间的所有本地进程一样 barker2015message。LightGBM利用MPI进行分布式训练,而XGBoost可以在Dask和Spark环境中进行训练。H2O机器学习库能够使用MPI在分布式环境中执行机器学习算法。通过名为Sparkling Water https://github.com/h2oai/sparkling-water的适配器,H2O算法也可以与Spark一起使用。
虽然深度学习在机器学习的当前研究中占主导地位,但它远未使经典的ML算法变得无用。尽管确实存在用于表格数据的深度学习方法,但CNN和LSTM始终在从图像分类到语言翻译的任务中始终展示出一流的性能。但是,经典的ML模型往往更易于分析和反思,通常用于深度学习模型的分析中。在第6节中,经典ML与深度学习之间的共生关系将变得尤为明显。
3.自动机器学习(AUTOML)
诸如Pandas,NumPy,Scikit-learn,PyTorch和TensorFlow之类的库以及具有Scikit-learn兼容API的各种库集合,为用户提供了手动执行端到端机器学习管道的工具。自动机器学习(AutoML)工具旨在自动化这些机器学习管道的一个或多个阶段(图 3),使非专家更容易构建机器学习模型,同时消除重复的任务,并使经验丰富的机器学习工程师能够更快地构建更好的模型。
自2013年首次引入Auto-Weka thornton2013auto以来,几个主要的AutoML库已经变得非常流行 。目前,Auto-sklearn feurer2019auto, TPOT olson2019tpot,H2O-AutoML h2o2020h2o,Microsoft的NNI
https://github.com/microsoft/nni,而AutoKeras jin2019auto是从业者中最受欢迎的,本节将对此进行进一步讨论。
虽然AutoKeras提供Scikit学习般的类似于自动sklearn API,它的重点是AutoML与训练有素的DNNs Keras以及神经结构的搜索,这是第单独讨论 。Microsoft的神经网络智能(NNI)AutoML库除了提供经典ML之外,还提供神经体系结构搜索,支持Scikit-learn兼容模型和自动化特征工程。
Auto-sklearn的API与Scikit-learn直接兼容,而H2O-AutoML,TPOT和auto-keras提供类似于Scikit-learn的API。这三种工具中的每一种在提供的机器学习模型的集合方面有所不同,这些模型可以通过AutoML搜索策略进行探索。尽管所有这些工具都提供了受监督的方法,并且某些工具(例如H20-AutoML)将堆叠或集成最佳性能的模型,但是开源社区目前缺乏自动进行无监督模型调整和选择的库。
随着对AutoML的研究和创新方法的数量不断增加,它遍及不同的学习目标,并且社区开发用于比较这些目标的标准化方法非常重要。这是在2019年完成的,开源基准的贡献是在39个分类任务gijsbers2019open的数据集上比较AutoML算法 。
以下各节涵盖了可以自动化的机器学习管道的三个主要组成部分:
(1)初始数据准备和特征工程
(2)超参数优化和模型评估以及
(3)神经体系结构搜索。
3.1数据准备和特征工程
机器学习管道通常从数据准备步骤开始,该步骤通常包括数据清理,将各个字段映射到数据类型以进行特征工程准备以及估算缺失值
费勒 ; He2019automl。一些库(例如H2O-AutoML)试图通过自动推断不同的数据类型来自动化数据准备过程的数据类型映射阶段。其他工具,例如Auto-Weka和Auto-sklearn,要求用户手动指定数据类型。

图3:(a)AutoML过程的不同阶段,用于选择和调整经典ML模型。(b)使用神经体系结构搜索生成和调整模型的AutoML阶段。
一旦知道了数据类型,特征工程过程就会开始。在特征提取阶段,通常会转换这些字段以创建具有改进的信噪比的新特征,或者对特征进行缩放以帮助优化算法。常见的特征提取方法包括特征归一化和缩放,将特征编码为一种或另一种格式以及生成多项式特征组合。特征提取也可以用于降维,例如,使用类似主成分分析,随机投影,线性判别分析和决策树的算法对特征进行去相关和减少。这些技术可能会增加功能的判别能力,同时减少来自维数的诅咒。
上面提到的许多工具都试图使要素工程过程的至少一部分自动化。像TPOT这样的库直接在端到端机器学习管道中建模,因此除了通过预测性能选择模型外,他们还可以评估功能工程技术的变化。但是,尽管在建模管道中包含要素工程非常引人注目,但这种设计选择还大大增加了要搜索的超参数的空间,这在计算上可能会被禁止。
对于需要大量数据的模型(例如DNN),AutoML的范围有时可能包括数据合成和扩充的 自动化He2019 automl。数据扩充和合成在计算机视觉中尤其常见,在计算机视觉中,通过翻转,裁剪或对图像数据集的各个部分进行过采样而引入了干扰。最近,这还包括使用生成对抗网络根据训练数据分布生成全新的图像 antoniou2017 data。
3.2超参数优化和模型评估
超参数优化(HPO)算法构成了AutoML的核心。最幼稚的寻找最佳性能模型的方法将详尽地选择和评估所有可能的配置,以最终选择最佳性能模型。HPO的目标是通过优化对超参数配置的搜索或对所得模型的评估来改进这种详尽的方法。网格搜索是一种基于蛮力的搜索方法,可探索用户指定参数范围内的所有配置。通常,搜索空间用固定的端点均匀地划分。尽管可以从粗到精的方式对网格进行量化和搜索,但是网格搜索已显示出对不重要的超参数bergstra2012random进行了过多的试验 。
与网格搜索有关,随机搜索是一种蛮力方法。但是,与其完全穷尽用户指定参数范围内的所有配置,不如从总搜索空间的边界区域中随机选择配置。在这些选定配置上评估模型的结果将用于迭代地改进将来的配置选择并进一步限制搜索空间。理论和经验分析表明,随机搜索比网格搜索更有效 bergstra2012random ; 也就是说,在短短的计算时间内就可以找到具有相似或更好的预测性能的模型。
一些算法(例如,Dask-ML,Auto-sklearn和H2O-AutoML中使用的超带算法)求助于随机搜索,并专注于优化模型评估阶段以获得良好的结果。Hyperband使用一种称为早期停止的评估策略,其中针对多个配置的多轮交叉验证并行启动 Li2018a。在交叉验证分析完成之前,将终止具有较差的初始交叉验证准确性的模型,从而释放资源以探索其他配置。从本质上讲,超带宽可以概括为一种方法,该方法首先随机运行超参数配置,然后为更长的运行选择候选配置。与纯随机搜索He2019automl相比,Hyberband是优化资源利用以更快地获得更好结果的理想选择 。与随机搜索相反,贝叶斯优化(BO)等方法着重于使用概率模型选择更好的配置。正如Hyperband的开发者所描述的那样,贝叶斯优化技术始终优于随机搜索策略。但是,他们只做少量 Li2018a。实验结果表明,与贝叶斯优化方法( snoek2015scalable)相比,进行随机搜索的时间长两倍是更好的结果 。
几个库使用BO的形式主义,即基于顺序模型的优化(SMBO),通过反复试验来建立概率模型。该Hyperopt库带来SMBO星火ML,使用被称为一种算法概率密度函数估计的树 NIPS2011_4443。该贝叶斯优化的超频(BOHB)falkner2018 bohb库将BO和超频带,同时提供其自身的内置分布式优化能力。Auto-sklearn使用一种称为顺序模型算法配置(SMAC) Feurer的SMBO方法。与提前停止类似,SMAC使用一种称为自适应赛车的技术仅在需要与其他竞争模型进行比较时评估模型https://github.com/automl/SMAC3
BO和Hyperband随机搜索是广义HPO中用于配置选择的最广泛使用的优化技术。作为一种选择,TPOT已被证明是一种非常有效的方法,它利用进化计算来随机搜索合理参数的空间。由于其固有的并行性,TPOT算法也可以在Dask中执行 https://examples.dask.org/machine-learning/tpot.html 可以在分布式计算群集中的其他资源可用时缩短总运行时间。
3.3神经架构搜索
先前讨论的HPO方法由通用HPO算法组成,这些算法与基础机器学习模型完全无关。这些算法的基本假设是,如果要考虑一个超参数配置的子集,则可以客观地验证该模型。
最近的AutoML深度学习研究不是从一组经典的ML算法或著名的DNN架构中进行选择,而是专注于从一组预定义的低层构建块组成主题或整个DNN架构的方法。这种类型的模型生成称为神经架构搜索(NAS) Zoph2017,它是real2019regularized的架构搜索 的子字段;Negrinho2019。
架构搜索算法开发的总体主题是定义搜索空间,该搜索空间是指可以组成的所有可能的网络结构或超参数。搜索策略是搜索空间上的HPO,用于定义NAS算法如何生成模型结构。与经典ML模型的HPO一样,神经体系结构搜索策略也需要一种模型评估策略,当给定要评估的数据集时,该模型可以产生模型的客观得分。
根据事先提供的神经网络结构多少,神经搜索空间可以分为四类之一:
-
整个结构:通过选择并将一系列原语(例如卷积,串联或池化)链接在一起,从头开始生成整个网络。这称为宏搜索。
-
基于单元的:搜索固定数量的手工构建块(称为单元)的组合。这称为微搜索。
-
层次结构:通过引入多个级别并链接固定数目的单元格来扩展基于单元格的方法,迭代地使用较低层中定义的基元来构造较高层。这结合了宏搜索和微搜索。
-
基于形态的结构:将知识从现有性能良好的网络转移到新的体系结构。
与上面所述的传统HPO相似 ,NAS算法可以利用各种通用优化和模型评估策略从神经搜索空间中选择性能最佳的体系结构。
Google已参与NAS的大部分开创性工作。2016年,来自Google Brain项目的研究人员发布了一篇论文,描述了如何将强化学习用作整个结构搜索空间的优化器,能够构建递归和卷积神经网络(CNN)
zoph2016neural。一年后,同一位作者发表了一篇论文,介绍了基于细胞的NASNet搜索空间,该研究使用卷积层作为主题并进行了强化学习,以寻找可对其进行配置和堆叠的最佳方式 Zoph2017。
进化计算是在AmoebaNet-A的NASNet搜索空间中进行的,Google Brain的研究人员在其中提出了一种新颖的比赛选择 Goldberg方法。分层搜索空间由Google的DeepMind团队 Liuc提出。这种方法使用进化计算来导航搜索空间,而斯坦福大学的Melody Guan和GoogleBrain团队的成员一起使用强化学习以一种称为ENAS Pham2018的方法来导航分层搜索空间。
由于所有生成的网络都用于同一任务,因此ENAS使用转移学习来减少训练所花费的时间,从而研究了不同生成模型之间权重共享的影响。
渐进式神经体系结构搜索(PNAS)研究了贝叶斯优化策略SMBO的使用,它通过在确定是否搜索更复杂的单元Liub之前探索更简单的单元来使CNN体系结构的搜索效率 更高。同样,NASBOT为生成的体系结构定义了距离函数,该函数用于构建内核以将高斯过程用于BO Liu。AutoKeras引入了基于形态学的搜索空间,从而可以修改而不是重新生成高性能模型。与NASBOT一样,AutoKeras为NAS体系结构定义了一个内核,以便对BO jin2019auto使用高斯过程 。
谷歌DeepMind团队在2018年发表的另一篇论文中提出了DARTS,它允许使用基于梯度的优化方法(例如梯度下降)直接优化神经架构空间 Liua。在2019年提出了SNAS,它对DARTS进行了改进,使用采样来实现梯度Xie的更平滑近似 。
4.GPU加速的数据科学和机器学习
有一个连接硬件,软件及其市场状态的反馈环。构建软件体系结构以利用可用的硬件,而构建硬件以启用新的软件功能。当性能至关重要时,将对软件进行优化,以最低的成本使用最有效的硬件选件。2003年,当硬盘存储商品化时,谷歌GFS ghemawat2003 google和MapReduce dean2004 mapreduce之类的软件系统 利用快速顺序的读写操作,利用服务器集群(每个服务器都有多个硬盘)来实现规模化。2011年,磁盘性能成为瓶颈,内存商品化,Apache Spark Zaharia等库 优先考虑在内存中缓存数据,以尽可能减少磁盘的使用。
从1999年首次引入GPU时起,计算机科学家就开始利用其潜力来加速高度可并行化的计算。但是,直到2007年CUDA发行,通用GPU计算(GPGPU)才开始普及。上述示例来自推动更快地支持更多数据,同时提供了扩展和扩展的能力,从而使硬件投资可以随着用户的个人需求而增长。以下各节介绍在Python环境中使用GPU计算。在简要概述GPGPU之后,我们讨论了GPU在端到端加速数据科学工作流中的使用。我们还将讨论GPU如何在Python中加速数组处理以及各种可用工具如何协同工作。
4.1机器学习的通用GPU计算
即使使用高效的库和优化,通过CPU绑定计算可以实现的并行性数量也受到物理内核数量和内存带宽的限制。此外,很大程度上受CPU限制的应用程序也可能与操作系统争用。
在GPU上使用机器学习的研究早于深度学习的兴起。CUDA的创建者伊恩·巴克(Ian Buck)曾在2005年尝试2层全连接神经网络,然后在2006年以steinkraus2005的身份加入NVIDIA 。此后不久,在GPU之上实现了卷积神经网络,与高度优化的CPU实现相比,观察到了惊人的端到端加速。。此时,在存在专用的GPU加速的BLAS库之前就已经获得了性能优势。第一个CUDA工具包的发布赋予了GPU通用并行计算的生命力。最初,只能通过C,C ++和Fortran接口访问CUDA,但是在2010年,PyCUDA库开始使CUDA可以通过Python和klockner2010pycuda进行访问 。
GPU改变了传统机器学习和深度学习的格局。从1990年代末到2000年代末,支持向量机一直保持着大量的研究兴趣 lloyd2010svm,并被认为是最新技术。在2010年,GPU为claudiu2010深度学习领域注入了新的活力,推动了大量研究和开发。
与SIMD相比,GPU支持单指令多线程(SIMT)编程范例,更高的吞吐量和更多的并行模型,并且高速内存跨越多个多处理器(块),每个多处理器包含多个并行内核(线程)。内核还具有与同一多处理器中其他内核共享内存的能力。与CPU领域中一些经过硬件优化的BLAS和LAPACK实现所使用的基于CPU的SIMD指令集一样,SIMT架构可以很好地并行化机器学习算法(例如BLAS子例程)所需的许多基本操作,从而加速GPU天生的合身。
4.2端到端数据科学:RAPIDS
GPU加速数据科学工作流的能力所占空间比机器学习任务大得多。通常由高度可并行化的转换组成,这些转换可以充分利用SIMT处理的优势,已证明数据科学流水线的整个输入/输出和ETL阶段在性能上均取得了巨大的进步。通过针对不同的实现进行设置。
RAPIDS https://rapids.ai于2018年引入,是一项开源工作,旨在支持和发展用于数据科学,机器学习和科学计算的GPU加速Python工具生态系统。RAPIDS支持现有的库,通过为开源库提供Python社区所缺少的关键组件来填补空白,并通过支持跨库的互操作性来促进整个生态系统的凝聚力。
受到Scikit-learn统一的API外观及其启用的功能强大的API的多样化集合的积极影响,RAPIDS建立在一组行业标准Python库的核心之上,将基于CPU的实现交换为GPU加速的变体。通过使用Apache Arrow的列格式,它使多个库能够利用此功能并完全在GPU上构成端到端的工作流。结果是,主机内存和GPU内存之间的传输和转换被最小化,并且很多时候被完全消除了,如图4所示 。
RAPIDS核心库包括分别替换为cuDF,cuML和cuGraph的Pandas,Scikit-learn和Network-X库的直接替代品。其他组件填补了更集中的空白,同时在适用的情况下仍然可以替代行业标准的Python API。cuIO提供许多流行数据格式的存储和检索,例如CSV和Parquet。cuStrings使在GPU上表示,搜索和处理字符串成为可能。cuSpatial提供了用于构建和查询空间数据结构的算法,而cuSignal提供了对SciPy信令子模块scipy.signal的近乎替代。

图4: RAPIDS是开源工作,旨在支持和发展用于数据科学,机器学习和科学计算的GPU加速Python工具生态系统。RAPIDS支持现有的库,通过为开源库提供Python社区所缺少的关键组件来填补空白,并通过支持跨库的互操作性来促进整个生态系统的凝聚力。
4.3NDARRAY和向量化运算
虽然NumPy可以调用BLAS实现来优化SIMD操作,但其矢量化功能的能力有限,几乎没有提供性能优势。Numba库提供即时(JIT)编译 lam2015numba,使矢量化函数能够利用SSE和AltiVec等技术。将计算与数据分开描述的这种分离还使Numba能够在GPU上编译和执行这些功能。除了JIT之外,Numba还定义了DeviceNDArray,在NumPy的NDArray中提供GPU加速的许多常用功能的实现。
CuPy定义了GPU加速的NDArray,其作用域与Numba nishino 2017 cupy略有不同 。CuPy是为GPU专门构建的,遵循NumPy的相同API,并包括SciPy API的许多功能,例如scipy.stats和scipy.sparse,它们会尽可能使用相应的CUDA工具包库。CuPy还包装了NVRTC https://docs.nvidia.com/cuda/nvrtc/index.html,以提供能够在运行时编译和执行CUDA内核的Python API。CuPy的开发旨在为深度学习库Chainer tokui2015chainer提供多维数组支持 ,此后已被许多库用作NumPy和SciPy的GPU加速直接替换。
TensorFlow和PyTorch库定义Tensor对象,它们是多维数组。这些库与Chainer一起提供类似于NumPy的API,但构建计算图以允许将张量上的操作序列与其执行分开定义。这是由于它们在深度学习中的使用而引起的,在深度学习中,跟踪操作之间的依赖性使他们能够提供自动区分等功能,而在一般的数组库(如Numba或CuPy)中则不需要。深度学习和自动分化的更详细讨论可以在第5节中找到 。
Google的加速线性代数(XLA)库 google 2017 xla提供了自己的特定于域的格式,用于表示和JIT编译计算图;还为优化器提供了了解操作之间的依赖关系的好处。TensorFlow和Google的JAX库frostig2018compiling都使用XLA ,该库 使用NumPy填充程序为Python提供自动区分和XLA,该NumPy填充程序根据连续的转换构建计算图,类似于TensorFlow,但直接使用NumPy API。
4.4互操作性
像Pandas和Scikit-learn这样的库都建立在NumPy的NDArray之上,继承了在高性能核心之上构建NumPy的统一性和性能优势。NumPy和SciPy的GPU加速版本多种多样,为用户提供了许多选择。最广泛使用的选项是CuDF,CuPy,Numba,PyTorch和TensorFlow库。正如本文简介中所讨论的那样,过去每次使用不同的库时都需要复制数据集或显着更改其格式,这已阻碍了互操作性。对于GPU库而言尤其如此,因为这些库的复制和翻译需要CPU与GPU之间的通信,这常常会抵消GPU中高速内存的优势。
最近发现有两个标准可以在这些库之间交换指向设备内存的指针-__cuda_array_interface__
https://numba.pydata.org/numba-doc/latest/cuda/cuda_array_interface.html和DLPack
https://github.com/dmlc/dlpack。这些标准使设备内存可以轻松表示并在不同库之间传递,而无需复制或转换基础数据。这些序列化格式的灵感来自于NumPy的适当名称__array_interface__,该名称自2005年以来一直存在。有关Numba,CuPy和PyTorch库之间的互操作性的Python示例,请参见图 5。

图5:不同GPU加速的Python库之间的零复制互操作性示例。
4.5GPU上的经典机器学习
矩阵乘法在计算机科学领域中,矩阵乘法扩展到矩阵-矩阵和矩阵-矢量乘法
从凸优化到特征值分解,线性模型,贝叶斯统计到基于距离的算法,这是机器学习操作的重要部分。因此,机器学习算法需要高性能的BLAS实现。GPU加速的库需要以与NumPy和SciPy在下面使用C / C ++和Fortran代码的方式相同的方式使用有效的低级线性代数基元,主要区别在于调用的库需要GPU加速。其中包括CUDA Toolkit中包含的选项,例如cuBLAS,cuSparse和cuSolver库。
适用于Python的GPU加速的机器学习库的空间分散了不同类别的专用算法。在GBM 类别中,XGBoost Chen2016和LightGBM Zhang都提供了GPU加速的实现 。IBM的SnapML和H2O为线性模型Dunner2018提供了高度优化的GPU加速实现 。ThunderSVM具有支持向量机的GPU加速实现,以及用于分类和回归任务的标准内核集。它还包含一类SVM,这是一种用于检测离群值的无监督方法。SnapML和ThunderSVM都具有与Scikit-learn兼容的Python API。
Facebook的FAISS库加速了最近邻居的搜索,提供了近似和精确的实现以及K-Means Johnson2019的高效版本 。CannyLabs提供了非线性降维算法T-SNE maaten2008visualizing的有效实现,该算法 已被证明对于可视化和学习任务都是有效的。T-SNE通常禁止在CPU上使用,即使对于百万个数据样本Chan2019的中型数据集也是 如此。
cuML被设计为用于机器学习的通用库,其主要目标是填补Python社区中缺少的空白。除了用于构建机器学习模型的算法之外,它还在Scikit-learn中提供了GPU加速的其他软件包的版本,例如preprocessing,feature_extraction和model_selection蜜蜂。通过关注GPU加速工具生态系统中缺少的重要功能,cuML还提供了Scikit学习中未包含的一些算法,例如时间序列算法。尽管仍保持类似于Scikit-learn的界面,但仍使用某些更特定算法的其他行业标准API来捕获可提高可用性的细微差异,例如Statsmodels seabold 2010 。
4.6GPU上的分布式数据科学和机器学习
GPU已成为高性能和灵活的通用科学计算中的关键组件。尽管GPU提供了诸如高速内存带宽,共享内存,极端并行性以及对其全局内存进行合并的读写等功能,但单个设备上可用的内存量小于主机(CPU)内存中可用的容量。此外,即使CUDA流允许并行执行不同的CUDA内核,在具有大量数据工作负载的环境中,高度可并行化的应用程序也可能会受到单个设备上可用内核数量的限制。
可以组合使用多个GPU来克服此限制,从而为更大的数据集上的计算提供总体上更多的内存。例如,可以通过在单个计算机上安装多个GPU来扩展单个计算机。使用这项技术,重要的是这些GPU能够直接访问彼此的内存,而不会因通过诸如PCI-express这样的慢速传输而造成性能负担。但是向上扩展可能还不够,因为可以在一台计算机上安装的设备数量有限。为了保持较高的横向扩展性能,GPU能够跨物理机器边界共享其内存也很重要,例如通过NIC(如以太网)和高性能互连(如Infiniband)。
Nvidia在2010年推出了GPUDirect Shared Access shainer2011development,这是一组硬件优化和低级驱动程序,用于加速GPU和同一PCI Express桥上的第三方设备之间的通信。在2011年,引入了GPUDirect对等技术,从而可以通过高速DMA传输在多个GPU之间移动内存。CUDA进程间通信(CUDA IPC)使用此功能,因此同一物理节点中的GPU可以访问彼此的内存,从而提供了扩展能力。在2013年,启用GPUDirect RDMA的网卡绕过CPU并直接在GPU上访问内存。这消除了多余的副本,并在不同的物理机器上创建的GPU之间的直线 potluri2013efficient,正式为横向扩展提供支持。
尽管自1999年SETI @ home发明并于2002年成立之初就存在使用GPU进行分布式计算的幼稚策略 ,但是通过让多个工作人员运行本地CUDA内核,GPUDirect提供的优化使包含多个GPU的分布式系统具有更加全面的编写方式可扩展算法。
可以在CUDA支持下构建第2.4节中介绍的MPI库
https://www.open-mpi.org/faq/?category=runcuda,从而可以在多个GPU设备之间传递CUDA指针。例如,LightGBM(第2.3节 )使用OpenCL支持AMD和NVIDIA设备,对具有MPI的GPU进行分布式训练。Snap ML还可以通过MPI Dunner2018执行分布式GPU训练 。通过将CUDA支持添加到OpenMPI康达包装中,Mpi4py库
https://github.com/mpi4py/mpi4py现在向Python公开了支持CUDA的MPI ,从而减轻了科学家在Python数据生态系统中构建分布式算法的障碍。
但是,即使使用支持CUDA的MPI,也可以在主机上执行诸如减少和广播之类的集体通信操作,这些操作允许一组等级共同参与数据操作。NVIDIA集体通信库(NCCL)提供了类似于MPI的API,可完全在GPU上执行这些简化操作。这使得NCCL在诸如PyTorch,Chainer,Horovod和TensorFlow之类的分布式深度学习库中非常受欢迎。它也用在许多具有分布式算法的经典ML库中,例如XGBoost,H2OGPU和cuML。
MPI和NCCL均假设等级可用于实时同步通信。用于通用可伸缩分布式计算的异步(延迟)任务计划系统(例如Dask和Apache Spark)与该设计形成了鲜明的对比,方法是构建有向非循环计算图(DAG),该图表示任意任务之间的依赖关系并执行它们懒惰或异步。在执行图形之前,这些任务的返回类型以及由此产生的尺寸是未知的。PyTorch和TensorFlow也构建DAG,并且由于假定张量用于输入和输出,因此通常在执行图形之前就知道尺寸。
端到端数据科学需要ETL作为开发流程的主要阶段。这个事实与PyTorch和TensorFlow等张量处理库的范围背道而驰。RAPIDS通过为Dask和Spark等系统中的GPU提供更好的支持来填补这一空白,同时促进使用互操作性在这些系统之间移动,如第4.4节所述 。
每个GPU的单进程(OPG)范例是使用GPU进行多处理的一种流行布局,因为它允许在单节点多GPU和多节点多GPU环境中使用相同的代码。RAPIDS提供了一个名为Dask-CUDA的库,该库可以轻松初始化OPG工人群集,自动检测每台物理计算机上的可用GPU,并且仅将一个GPU映射到每个工人。
RAPIDS提供了由cuDF支持的Dask DataFrame。通过在其分布式数组而不是NumPy 下支持CuPy ,Dask可以立即使用GPU进行多维数组的分布式处理。Dask支持使用Unified Communications-X(UCX) shamis2015ucx传输抽象层,允许工作人员使用最快的机制传递CUDA支持的对象,例如cuDF DataFrame,CuPy NDArray和Numba DeviceNDArrays。Dask中的UCX支持由RAPIDS UCX-py项目提供,该项目使用干净简洁的界面将UCX中的低级C代码包装起来,因此可以轻松地与其他基于Python的分布式系统集成。在同一物理机(节点内)的不同GPU之间传递GPU内存时,UCX将使用CUDA IPC。如果已安装GPUDirect RDMA,则将用于跨物理机(节点间)的通信,但是,由于它需要在操作系统中安装兼容的网络设备和内核模块,因此内存将转储到主机上。
通过结合Dask对通用分布式GPU计算的全面支持以及第2.4节中概述的分布式机器学习的通用方法 ,RAPIDS cuML能够端到端分布和加速机器学习流程。图 6示出了DASK系统在训练阶段的状态下,通过对包含从训练数据集的数据分区的DASK工人执行训练任务。训练后的DASK系统的状态在图中示出 6湾 在此阶段,参数仅保留在单个工作程序的GPU上,直到在模型上调用预测为止。图 6c显示了预测过程中的系统状态,其中,训练后的参数会广播给所有拥有预测数据集分区的工作人员。通常,只有fit()任务或一组任务才需要与其他工作人员共享数据。同样,预测阶段通常不需要工人之间的任何通信,从而使每个工人都可以独立运行其本地预测。该设计涵盖了大多数经典的ML模型算法,只有少数例外。
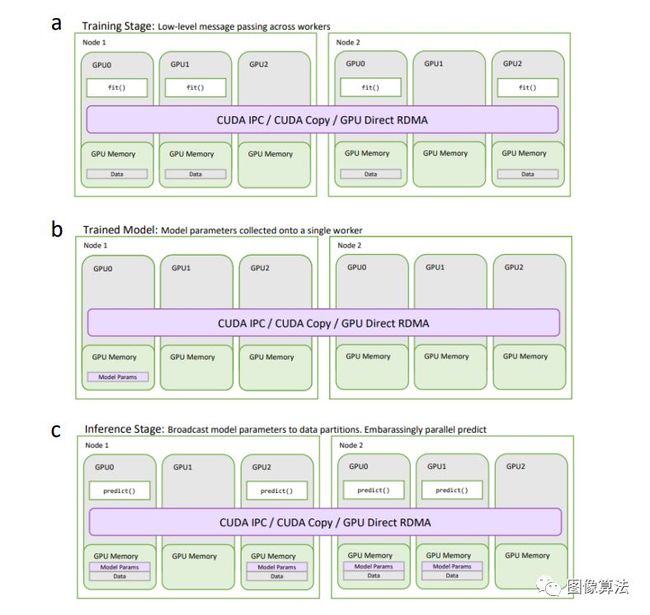
图6:使用Dask的通用分布式GPU计算。(a)分布式cuML训练。该拟合()函数是在包含在训练数据集数据的所有工人执行。(b)训练后的分布式cuML模型参数。将训练后的参数带给一个工人。(c)分布式cuML模型用于预测。训练后的参数会广播到预测数据集中包含分区的所有工作人员。预测以一种令人尴尬的并行方式进行。
Apache Spark的MLLib支持GPU,尽管集成不如Dask全面,缺少对本机序列化或GPU内存传输的支持,因此每个功能都需要从主机到GPU再到主机的不必要副本。Ray Project
https://github.com/ray-project/ray是相似的–尽管TensorFlow间接支持GPU计算,但集成不再进行。2016年,Spark引入了与Ray类似的概念,他们将其命名为TensorFrame。此功能已被弃用。RAPIDS当前正在Spark 3.0中增加对分布式GPU计算的更全面的支持
https://medium.com/rapids-ai/nvidia-gpus-and-apache-spark-one-step-closer-2d99e37ac8fd,内置对GPU的感知调度以及对端到端列式布局的支持,从而在整个处理阶段将数据保留在GPU上。
XGBoost(第2.3节 )支持在GPU上进行分布式训练,并且可以与Dask和Spark一起使用。除了MPI,Snap ML库还为Spark提供了一个后端。如2.4节 所述,使用Sparkling库使H2O能够在Spark上运行,并且GPU支持自动继承。Dask可以使用通用库cuML中的分布式算法,其中也包括数据准备和特征工程。
5.深度学习
使用经典ML,预测性能在很大程度上取决于数据处理和用于构建将用于训练模型的数据集的特征工程。第2节中提到的经典ML方法 在处理高维数据集时通常会出现问题-该算法对于从原始数据(例如文本和图像lecun2015 deep)中提取知识而言不是 最理想的。另外,将训练数据集转换为合适的表格(结构化)格式通常需要人工特征工程。例如,为了构建表格数据集,我们可以将文档表示为单词频率的向量 raschka2014 naive,或者我们可以通过制表叶子尺寸的表格来表示(虹膜)花,而不是使用照片中的像素作为输入 fisher1936use。
对于大多数基于表格数据集的建模任务,经典ML仍然是推荐的选择。但是,除了上面第3节中提到的AutoML工具外 ,它还取决于仔细的功能工程,这需要大量的领域专业知识。数据预处理和特征工程可以被视为一门艺术,其目的是从收集的原始数据中提取有用且重要的信息,从而保留与进行预测有关的大多数信息。粗心或无效的特征工程可能会导致删除重要信息,并严重阻碍预测模型的性能。
虽然某些深度学习算法能够接受表格数据作为输入,但是大多数发现最佳预测性能的最新方法都是通用的,并且能够以某种自动化的方式从原始数据中提取重要信息。这种自动特征提取是其优化任务和建模体系结构的固有组成部分。因此,深度学习通常被描述为一种表示或特征学习方法。但是,深度学习的一个主要缺点是它不适用于较小的表格数据集,而参数化DNN可能需要较大的数据集,而有效训练需要5万至1500万个训练示例。
以下各节回顾了基于GPU和Python的深度学习库的早期开发,这些库着重于通过静态图的计算性能,向动态图的融合以提高用户友好性,以及当前为提高计算效率和可伸缩性而做出的努力,以应对不断增长的数据集和架构大小。
5.1静态数据流图
Caffe深度学习框架于2014年首次发布,旨在提高计算效率,同时提供易于使用的API来实现常见的CNN架构。
Caffe在计算机视觉社区中非常受欢迎。除了专注于CNN之外,它还支持循环神经网络和长短期记忆单元。尽管Caffe的核心部分是用C ++实现的,但它通过使用配置文件作为实现深度学习架构的接口来实现用户友好。这种方法的一个缺点是很难开发和实现自定义计算。
Theano最初于2007年发布,是另一个学术深度学习框架,在2010年代获得了发展 team 2016 theano。与Caffe相比,Theano允许用户直接在Python运行时中定义DNN。但是,为了提高效率,Theano将深度学习算法和架构的定义与执行分开了。Theano和Caffe都将计算表示为静态计算图或数据流图,在执行之前先对其进行编译和优化。在Theano中,此编译可能需要花费几秒钟到几分钟的时间,并且在调试深度学习算法或体系结构时可能会成为主要的摩擦点。此外,将图形表示与执行分离开来,很难与代码进行实时交互。
在2016 abadi2016tensorflow中,谷歌发布了TensorFlow,它采用了与Theano类似的方法,即使用了静态图形模型。虽然图形定义与执行之间的这种分离仍然不允许实时交互,但TensorFlow减少了编译时间,使用户可以更快地迭代不同的想法。TensorFlow还专注于分布式计算,当时很少有DNN库提供。这种支持使深度学习模型可以一次定义并部署在不同的计算环境中,例如服务器和移动设备,这一功能使其对行业特别有吸引力。TensorFlow还被学术界广泛采用,变得如此受欢迎,以至于Theano的开发在2017年停止了发展。
在2016年至2019年之间的几年中,发布了其他几个带有静态图范式的开源深度学习库,包括微软的CNTK seide2016cntk,索尼的Nnabla :
https://github.com/sony/nnabla,
Neon :https://github.com/NervanaSystems/neon、
Facebook的Caffe2 markham2017 caffe2和百度的PaddlePaddle ma2019 paddle。与其他深度学习库不同,Nervana Neon(后来被英特尔收购,现已停产)没有使用cuDNN来实现神经网络组件。相反,它具有通过英特尔MKL(第1.2节)优化的CPU后端 。MXNet chen2015mxnet受Amazon,Baidu和Microsoft的支持,它是Apache Software Foundation的一部分,并且仍然是唯一一家主要由主要的营利性技术公司开发的,主动开发的,主要的开源深度学习库。
虽然静态计算图对于在生产环境中应用代码优化,模型导出和可移植性很有吸引力,但是缺乏实时交互性仍然使它们在研究环境中难以使用。下一节重点介绍了一些主要的深度学习框架,这些框架正在拥抱一种称为动态计算图的替代方法,该方法允许用户直接实时地与计算交互。
5.2具有急切执行的动态图库
Torch在将近二十年前的2002年首次发布,是一个非常有影响力的开源机器学习和深度学习库。在像其他深度学习框架一样使用C / C ++和CUDA的同时,Torch基于脚本语言Lua,并利用即时编译器LuaJIT
collobert 2011 torch7。与Python相似,Lua是一种易于学习和使用的解释型语言。使用自定义C / C ++代码进行扩展也很容易,以提高科学计算环境中的效率。使Lua特别吸引人的是它可以被嵌入到不同的计算环境中,例如移动设备和Web服务器-使用Python不太容易实现的功能。
Torch 7(于2011年发布)由于对计算图collobert 2011 torch7的动态处理,因此在很大一部分深度学习研究社区中特别有吸引力 。与上一节(第5.1节)中提到的深度学习框架相反 ,Torch 7允许用户直接与计算交互,而不是定义在执行之前需要显式编译的静态图(图 7)。随着Python在整个2010年代逐渐发展成为用于科学计算,机器学习和深度学习的通用语言,尽管其用户友好的静态图方法不那么受欢迎,但许多研究人员似乎仍然更喜欢Theano而不是Torch等基于Python的环境。

图7:(a)TensorFlow 1.15中的静态计算图与(b)由PyTorch 1.4中的动态图启用的命令式编程范例之间的比较。
Torch 7最终在2017 paszke2017automatic中被PyTorch取代 ,它最初是围绕Torch 7的较低级C / C ++代码的用户友好的Python包装器。受动态和基于Python的深度学习框架(例如 Chainer tokui2015chainer和DyNet neubig2017dynet)的先驱启发,PyTorch采用命令式编程风格,而不是使用图元编程.
在图元编程中,图的部分或全部结构是在编译时提供,并且在运行时仅生成或添加最少的代码。。这对研究人员特别有吸引力,因为它为Python用户提供了熟悉的界面,简化了实验和调试,并且与其他基于Python的工具直接兼容。DyNet,Chainer和PyTorch之类的库与常规的GPU加速的数组库(如CuPy)的区别在于,它们包括用于计算标量值函数梯度的反向模式自动微分(autodiff)
标量值函数接收一个或更多输入值,但返回单个值关于多元输入。自2017年以来,PyTorch已被广泛采用,现在被认为是最受欢迎的深度学习研究库。在2019年,PyTorch是在所有主要的深度学习会议中最常用的深度学习库 he2019stateofml。
动态计算图允许用户实时与计算交互,这在实现或开发新的深度学习算法和体系结构时是一个优势。尽管此特定功能可增强功能,但像这样的急切执行却需要很高的计算成本。此外,执行需要使用Python运行时,这使得在移动设备和其他未配备最新Python版本的环境中部署DNN变得很困难。尽管独立基准测试表明,与静态图形库(如TensorFlow coleman2017dawnbench)相比,PyTorch在GPU上进行DNN训练的速度已经更快 ,但Facebook在过去几年中做出了许多显着的性能提升
由于Python代码仅用于通过对较低级CUDA和cuDNN库的回调将操作排队在GPU上以异步执行,因此所有主要深度学习框架的计算性能差异都将大致相似。。例如,原始的Torch 7核心张量库在很大程度上是从头开始重写的,而PyTorch最终与Caffe2的代码库合并在一起。
至此,Caffe2变得专注于计算性能和移动部署。这种合并允许PyTorch自动继承这些功能。在2019年,PyTorch除了其他功能外还添加了JIT(即时)编译功能,进一步增强了其计算性能 paszke2019 pytorch。
此后,一些最初使用静态数据流图的现有深度学习库(例如TensorFlow,MXNet和PaddlePaddle)增加了对动态图的支持。用户的要求和PyTorch越来越受欢迎的原因促成了这一变化。动态计算图非常有效,现在它已成为TensorFlow 2.0中的默认行为。
5.3 JIT与计算效率
尽管由于其易用性而受到研究的青睐,但上述所有动态图库都通过为特定的神经网络组件和深度学习算法提供固定的构建块来达到所需的计算效率水平。虽然可以从较低级别的构建模块开发自定义功能(例如,使用库的数组子模块公开的线性代数运算来实现自定义神经网络层),但是这种方法的缺点是它很容易引入计算瓶颈。但是,在一行代码中,通过启用JIT编译(通过Torch脚本),可以在PyTorch中避免这些瓶颈。
可定制性和计算效率的另一种体现是Google最近发布的开源库JAX frostig2018compiling。如第4.5节中所述 ,JAX向以自动微分(正向和反向模式自动diff),XLA(加速线性代数;线性代数的特定领域编译器)为中心的常规Python和NumPy代码中添加了可组合元素作为GPU和TPU计算
TPU是Google定制开发的用于机器学习和深度学习的芯片。。JAX能够区分朴素的Python和NumPy函数,包括循环,闭包,分支和递归函数。除了反向模式微分外,autodiff模块还支持正向模式微分这样可以高效地计算高阶导数,例如Hessian;其他主要的深度学习库尚不支持此功能,但它是一项受到高度要求的功能,目前正在PyTorch中实现
(https://github.com/pytorch/pytorch/issues/10223)。
前向模式autodiff可以自动区分具有多个输出的功能,这在当前利用反向传播的深度学习研究中并不常用 rumelhart 1986学习。
JAX是一个相对较新的库,尚未得到广泛采用。但是,JAX的设计选择是完全采用NumPy的API,而不是开发像PyTorch这样的类似NumPy的API,这可能会降低熟悉NumPy生态系统的用户的进入门槛。JAX面向具有自动diff支持的数组计算,与PyTorch不同,因为它不依赖于Flax专注于提供全套深度学习功能,因此https://github.com/google-research/flax/tree/预发这样做。
例如卷积层,批处理规范
ioffe2015batch,attention vaswani2017attention等,它实现了常用的优化算法,包括具有动量 qian1999动量的 SGD,Lars efron2004least和ADAM kingma2014adam。重要的是,本节的结尾必须指出所有主要的深度学习框架现在都基于Python。另一个值得注意的趋势是,学术界使用的所有深度学习库现在都由大型科技公司提供支持。学术界和行业的不同需求可能导致开发此类设计模式所需的复杂性和工程工作。根据对主要发布场所,社交媒体和搜索结果的详尽分析,许多研究人员正在放弃TensorFlow,转而使用PyTorch he2019stateofml。Horace He进一步建议,尽管PyTorch目前在深度学习研究中占据主导地位-在主要的计算机视觉和自然语言处理会议上超过TensorFlow 2:1和3:1 -TensorFlow仍然是业界最受欢迎的框架
he2019stateofml。TensorFlow和PyTorch似乎相互启发,并在各自的长处和短处交汇。PyTorch添加了用于生产和移动部署的静态图功能(最近由TorchScript启用),而TensorFlow添加了动态图,以便于研究。预计在未来几年中,这两个库仍将是最受欢迎的选择。
5.4深度学习API
位于5.1 和 5.2节中讨论的深度学习库的顶部 是几个不同的包装器库,这些库使从业者更易于使用深度学习。这些API的主要设计目标之一是在代码详细程度和可定制性之间提供更好的折衷。现有的深度学习框架可能非常强大且可自定义,但也会使新手感到困惑。Lasagne是Theano
https://github.com/Lasagne/Lasagne的“轻量级”包装器,是一种抽象的方法,用于提取看似复杂的代码。在Lasagne首次发布后的2015年,Keras库
https://github.com/keras-team/keras引入了另一种方法,使Theano更易于为广大用户所使用,其API设计使人联想到Scikit-learn的面向对象方法。在首次发布后的几年中,Keras API确立了自己作为最受欢迎的Theano包装器的地位。在2016年初,即TensorFlow发布后不久,Keras还开始支持它作为另一个可选的后端。在第二年的2017年,微软的CNTK seide2016cntk被添加为第三个后端选择。在这段时间里,TensorFlow开发人员正在尝试抽象库,希望简化模型的构建和训练,并使非专家更容易访问它们。经过多次尝试和废弃的设计后,TensorFlow 2.0在2019年加强了与Keras的集成,最终公开了一个子模块(tensorflow.keras),并制作了面向用户的官方API tensorflow2019tf2。因此,不再积极开发Keras的独立版本。
由于PyTorch首先非常注重用户友好性,这是由于Chainer采用动态方法tokui2015chainer的简洁方法所 激发的,因此研究社区没有强烈的动机来拥抱扩展API。尽管如此,这些年来出现了几个基于PyTorch的项目,这些项目有助于在不同用例下实现神经网络,从而使代码更紧凑,同时简化了模型训练。此类库的著名示例是Skorch
https://github.com/skorch-dev/skorch,它在PyTorch,Ignite之上提供了Scikit-learn兼容的API
https://github.com/pytorch/ignite
https://github.com/pytorchbearer/torchbearer harris2018torchbearer,Catalyst33
https://github.com/catalyst-team/catalyst和PyTorch Lightning
https://github.com/PyTorchLightning/pytorch-lightning。
2020年,软件公司Explosion发布了其开源深度学习库Thinc的主要版本。版本8.0 35
https://github.com/explosion/thinc/releases/tag/v8.0.0a0承诺使用支持PyTorch,MXNet和TensorFlow代码的轻量级API进行深度学习的全新功能。该版本还通过Mypy 36
https://github.com/python/mypy包含了静态类型检查。
,使深度学习代码更易于调试。与独立版本的Keras相似,Thinc支持多个深度学习库。与Keras相比,Thinc强调定义模型的功能性而非面向对象的方法。Thinc进一步提供了对底层反向传播组件的访问,并且能够同时组合不同的框架,而不是提供像Keras这样的可插拔外观,一次只能利用单个深度学习库的功能。
Fastai库将用户友好的API与模型训练的最新改进和最佳实践相结合。初始版本基于Keras,尽管2018年它在1.0版本中进行了重大改进,现在在PyTorch之上提供了直观的API。Fastai还提供允许用户轻松可视化DNN模型以进行发布和调试的功能。此外,它通过提供有用的训练功能(如自动学习率调度程序)提高了DNN的预测性能,这些训练功能配备了最佳实践,可缩短训练时间并加速融合。Fastai的路线图包括深度学习算法,这些算法可以在不进行大量调整和实验的情况下即开即用地工作,从而通过减少对昂贵的计算资源的需求,使深度学习更加容易实现。
DAWNbench coleman2017dawnbench是一个基准套件,它不仅考虑了预测性能,还考虑了深度学习模型的速度和训练成本。
5.5加速大规模深度学习的新算法
利用Transformer架构的最新研究进展,例如BERT devlin2018bert和GPT-2 radford2019语言
,已经表明,对于某些架构,预测性DNN模型的性能可以与模型大小高度相关。在短短三年(从2014年到2017年)的过程中,ImageNet视觉识别挑战的模型规模russakovsky2015 imagenet赢家来自大约。400万 szegedy2015达到1.46亿 hu2018的挤压参数,大约是 增加了36倍。同时,GPU内存仅增长了约一个倍。3x并提出了单GPU深度学习研究 google2020 gpipe的瓶颈。
大规模模型训练的一种方法是数据并行性,其中在不同批次的数据集上并行使用多个设备。尽管这可以加快模型收敛速度,但该方法仍然无法训练大型模型,因为只有数据集在设备之间划分,并且模型参数仍需要适合每个设备的内存 hegde2016parallel。模型的并行性,而另一方面,涂在不同的设备模型,使模型与大量的参数以适合单个GPU的存储器 ben2019 demystifying。
Google在2019年3月发布了GPipe huang2019gpipe开源社区,使训练大型神经网络模型的效率更高。GPipe超越了数据和模型并行性,实现了基于同步随机梯度下降的流水线并行技术 huang2019gpipe。在GPipe中,模型分布在不同的硬件加速器上,并且训练数据集的微型批次进一步细分为微型批次,并且梯度在这些微型批次上始终保持累积(同步数据并行性)。在一项令人印象深刻的案例研究中,研究人员能够在23万多个云TPU上训练具有超过十亿个参数的AmoebaNet-B real2019正规化模型。在AmoebaNet-D real2019规范化基准上,研究人员观察到使用GPipe将模式划分为8个分区,而使用朴素的模型并行方法将模型 huang2019gpipe拆分,则计算性能提高了3倍 。
改善DNN预测性能的传统方法是增加最新架构的层数。例如,将Res2016的heNet架构 从ResNet-18扩展到ResNet-200(通过添加更多的层),导致ImageNet deng2009 imagenet的 top-1精度提高了4倍 https://github.com/tensorflow/privacy。
改进预测性能的更原则的方法是使用所谓的复合系数以Tan和Le在EfficientNet神经体系结构搜索方法tan2019ficientnet中提出的结构化方式缩放CNN 。复合缩放方法不是使用任意缩放CNN的输入分辨率,深度和宽度,而是首先使用网格搜索来确定这些不同架构参数之间的关系。从此初始搜索中,可以基于用户指定的计算预算或模型大小tan2019efficiency来导出复合缩放系数以调整基线体系结构 。据说EfficientNets模型产生的性能要优于当前的最新方法,通过缩小参数大小并增加整个tan2019efficiencynet的计算,可以将效率提高10倍 。Google工程团队进一步推动了实施,开发了一个EfficientNet变体,可以更好地利用其所谓的Edge TPU硬件加速器 google2020efficiencyedge –边缘计算是分布式系统的一种范式,其重点是使计算和数据存储与实际操作所在的位置紧密相邻。
量化通常用于加速训练并降低模型的内存占用量,该方法描述了将连续信号或数据转换为具有固定大小或精度的离散数的过程。
量化的典型示例是将数据表示为将64位浮点数转换为8位整数格式。这个概念已经存在了数十年,但最近对深度学习的兴趣不断增加。虽然通常与精度的损失相关,花样繁多已经发展到这种损耗降至最低 choi2018pact ; jacob2018量化 ; rastegari2016xnor ; zhang2018lq ; zhou2017增量 ;周2016dorefa。大多数深度学习库的最新版本(例如TensorFlow v2.0和PyTorch 1.4)都支持Int8(8位)量化,与Float32(32位)模型相比,它们可以将内存带宽需求降低4倍。。
除了通过改进的软件实现来提高深度学习的可扩展性和速度之外,算法改进最近还集中在优化算法的近似方法等方面。其中包括新概念,例如SignSGD bernstein2018signsgd,它是SGD的改进版本,用于分布式培训,工人仅可以传达坡度的符号。研究人员发现,SignSGD每次迭代的通信量要比分布式SGD的完全精确度低32倍,而其收敛速度却可以与SGD竞争。
6.机器学习模型的可解释性,可解释性和公平性
简单来说,可解释性是指对模型在幕后的工作方式的理解,而可解释性是指观察输入或参数变化对预测输出的影响的能力。尽管相互关联,但每个人都假定对模型有不同的知识-可解释性使我们能够理解模型的机制,而可解释性使我们能够交流如何从一组学习的参数中生成模型的输出。可解释性意味着可解释性,但反面不一定总是正确的。除了理解决策过程之外,可解释性还需要识别偏见。透明度要求规则用于生成预测的模型是完整且易于理解的 nguyen2019mononet。
6.1功能重要性
线性模型背后的主要吸引力在于输入,学习重量参数和输出之间线性关系的简单性。这些模型通常隐含可解释的,因为它们可以自然加权每个特征的影响,并干扰该输入或学习参数对输出规定的(线性)效应 ribeiro2016should。但是,多个特征之间的不同相关性可能使得难以分析每个特征对结果预测的独立归属。特征重要性的形式有很多种,但是一般的概念是使参数和特征更容易解释。根据此定义,所产生的功能重要性的确切特征可能会根据目标而有所不同。
在可解释性领域,本地模型和全局模型之间存在区别。尽管局部模型仅提供对特定数据点的解释(通常更容易理解),但全局模型通过概述决策过程nguyen2019mononet来提供透明度 。
LIME ribeiro2016应该是解释非线性模型(已经过事后)后解释非线性模型的最简单算法之一。该算法根据特定数据实例周围的扰动预测训练线性模型(称为替代模型),以了解该实例周围的非线性决策函数的形状。通过学习单个点附近的局部决策函数,我们可以更好地解释原始模型中的参数如何将输入与输出相关联。
与LIME相比,SHAP lundberg2017unified是一种事后算法,可通过提供所有数据点的平均值来全局解释 NIPS2017-7062。SHAP不是单一算法,而是多种算法。结合SHAP变体的方法是使用Shapley值shapley1953值 ,通过计算模型在不同预测中每个特征的平均贡献来确定特征重要性或归因。SHAP Python库
https://github.com/slundberg/shap提供了不同的变体,它建立在其他功能归因方法(例如LIME,Integrated Gradients sundararajan2017 axiomatic和DeepLift ShrikumarGK17)的基础上 用于模型不可知论。
特定于多类别分类问题,模型不可知线性竞争者(MALC) Rafique算法训练一个单独的线性分类器,以学习每个类别的决策边界,并且仅当线性竞争者的预测为足够自信。这项技术类似于“一对多”分类-这些线性模型将在推理过程中使用,从而将可解释性集成到了机器学习管道中,从而为那些可以使用竞争对手进行分类的预测提供了透明度和特征归因。
Captum
https://captum.ai是一个Python库,用于解释PyTorch中的模型,其中包含大量受支持的算法,包括但不限于LIME,SHAP,DeepLift和Integrated Gradients。
6.2约束非线性模型
在线性模型中对目标函数施加约束是提高学习参数之间的可分辨性(从而提高可解释性)的常用方法。例如,套索和脊等算法使用正则化来使所得的权重向量保持接近零,从而使彼此之间的特征重要性更加直接可辨。
尽管正则化可以增加线性模型中的可分辨性,但是非线性模型可以在输入变量之间引入相关性,这可能使得很难预测输入和输出之间的因果关系。MonoNet nguyen2019mononet在非线性分类器中对特征和输出之间的单调性施加约束,目的是在特征与其输出之间建立更独立的可分辨关系。MonoNet是此约束的神经网络实现,使用作者称为单调网络。
上下文分解解释罚分(CDEP)rieger2019解释 为优化目标添加了一个术语,该术语对神经网络的参数施加了约束,因此除预测正确的值外,他们还学会了如何产生良好的解释。而不是仅仅捕捉个人特征归因,这种方法还采用分数称为上下文分解分数 murdoch2018beyond学习功能是如何结合在一起,使每一个预测。CDEP的魅力在于可以将约束项添加到任何可微分的目标中。
将神经网络分类器约束为可逆的可以实现可解释性和可解释性。可逆神经网络由堆叠的可逆块组成,并在每一层保留足够的信息以从输出重构输入。通过将线性层附加到神经网络的输出层,可逆性约束可用于近似局部决策边界并构造特征重要性 zhuang2019decision。
6.3逻辑与推理
特征重要性分数通常是根据决策树中的信息增益和基尼杂质准则构建的,因此,对预测影响最大的拆分将更靠近树的根。因此,决策树被称为白盒模型,因为它们已经包含了解释所需的信息。Silas 新娘2019silas ; 新娘2018在此概念的基础上,通过将沿从根到叶子的预测的路径上的学习拆分谓词组合为逻辑连接,并将一类的所有路径组合为逻辑分叉,从树的集合中提取逻辑公式。可以使用逻辑推理技术来分析这些逻辑公式,以提供有关决策过程的信息,从而可以对模型进行微调,以消除不一致之处并执行某些用户提供的要求。这种方法属于被称为知识级学习Dietterich1986learning的类别, 因为经过训练的模型的内部结构已经模仿了逻辑表达。
虽然深度学习方法主导着图像分类的最新技术,但仅通过视觉反馈来解释模型,方法是突出显示导致分类的图像区域,这给人类带来了繁琐的解释任务。结合视觉解释和口头解释,例如,通过在图像中纳入导致预测的不同对象之间的关系,已被证明对人类层面的解释非常有效。LIME算法能够生成可突出显示图像中像素块(称为超像素)的特征重要性。可以从归纳逻辑编程中提取超像素之间的空间关系 像Aleph这样的系统,目的是构建一组简单的逻辑表达式来口头解释预测 rabold2018 ; rabold2019丰富。
6.4使用交互式可视化进行解释
可视化模型的学习参数的特征以及对模型与一组数据的交互的解释通常很有用。以视觉形式进行分析时,特征重要性和归因分数可以提供更有用的见解,从而暴露出原本很难辨认的模式。在Python机器学习社区,Matplotlib Hunter2007,Seaborn
https://github.com/seaborn/seaborn,
散景https://github.com/bokeh/bokeh,和 Altair2018被广泛用于可视化数据中绘图和图表。
尽管来自图像分类器的视觉解释可能会提示为什么进行单个预测,以便人们可以更好地理解决策边界,但交互式可视化可以实现对模型学习参数的实时探索。对于黑盒模型(例如神经网络),这对于钻研和了解所学内容尤其重要。
交互式可视化工具,例如Graphistry
https://graphistry.com和RAPIDS的cuDataShader库,可以在GPU上进行通用数据浏览。钻取一组数据对于可视化黑匣子模型的不同部分特别有用。例如,神经网络中每一层的激活向量可以针对不同的输入进行可视化布局,从而使用户能够探索它们之间的关系,从而洞悉神经网络正在学习什么。
作为通用数据可视化的替代方法,特定于模型的工具灵活性较差,但提供了更具针对性的见解。首脑
hohman2019s通过交互式和针对性的可视化揭示了CNN分类器中有影响力的特征的关联。它基于功能可视化 的常规技术
https://distill.pub/2017/feature-visualization/和激活地图集
https://ai.googleblog.com/2019/03/exploring-neural-networks。html
,以不同的粒度提供视图,以汇总和总结有关每个类别标签的最具影响力的神经元的信息。细粒度的可视化总结了网络各层中最有影响力的神经元的连接,而粗粒度的可视化则通过汇总神经元信息并使用UMAP突出显示了各个类别中这些有影响力的神经元的相似性。
McInnes2018是非线性降维技术中的最新技术,可嵌入适合可视化的空间。
变形金刚模型(BERT)的双向编码器表示法是语言表示学习模型devlin2018bert的最新技术,该模型 旨在学习可用于其他任务的单词的上下文表示法。它来自使用称为vaswani2017attention的策略的基于LSTM网络(称为Transformers)的模型模型。通过将输入序列中的不同标记置于序列中的其他标记上来改善学习效果。像其他黑盒深度学习模型一样,模型在给定的测试集上可能具有高性能,但在部分学习的参数空间中仍然存在明显的偏差。从这种方法学到的语言特性还不是很容易理解。exBERT hoover2019exbert提供了有针对性的交互式可视化功能,以与前面提到的Summit相似的方式总结了学习到的参数。exBERT通过对不同输入序列的不同层中的注意力机制进行交互探索,并提供对所学习嵌入的最近邻搜索,来帮助做出解释。
6.5隐私
机器学习使我们能够在许多领域推动最先进的技术,例如自然语言处理 vaswani2017的关注度;howard2018universal ; radford2019语言 ; 对adiwardana2020和计算机视觉的 理解 ; huang2017密集 ; joo2018total ; huang2019神经,某些应用程序涉及需要负责任处理的敏感数据。除了存储整个训练集的基于最近邻居的方法之外,DNN尤其容易记忆有关特定训练示例的信息(而不是提取或学习一般模式)。此类信息的隐式存在问题,因为它可能侵犯用户的隐私并可能被用于恶意目的。为了在技术基于潜在敏感培训数据的基础上提供强大的隐私保证,Google最近发布了TensorFlow Privacy
https://github.com/tensorflow/privacy mcmahan2018general,这是用于TensorFlow的工具箱,该工具箱实现了基于差异隐私的技术。差异隐私框架提供了强有力的数学保证,以确保模型不会记住或了解有关任何特定用户的详细信息 mcmahan2018general。
6.6公平
尽管机器学习推动了惊人技术的发展,但最近受到越来越多关注的一个主要问题是训练数据集可以加强或反映不公平的(人为)偏见。例如,最近的一项研究表明,人脸识别方法会根据种族和性别属性进行区分 。
buolamwini2018gender。Google最近发布了一套名为“公平指标”的工具
https://github.com/tensorflow/fairness-indicators
帮助实现公平性指标和分类模型的可视化。例如,“公平指标”实施了相当普遍的指标来检测公平偏差,例如误报率和误报率(包括置信区间),并将其应用于数据集的不同部分(例如,具有敏感特征的组,例如性别,国籍和收入)
google2020 fairness-b。
随着机器学习在行业中的发现越来越广泛,可解释性和可解释性这一主题变得越来越重要。具体来说,随着深度学习在不断增长的不同任务列表上继续超越人类水平的表现,因此对它们的需求也可以得到解释。该分析中还非常普遍的是经典ML与深度学习之间的共生关系,因为前者仍然对特征重要性的计算,替代建模以及支持DNN的可视化提出了很高的要求。
7.对抗学习
尽管对抗性学习是一个通用概念,但通常会在计算机视觉和深度学习的背景下最直观地解释和展示对抗性学习。例如,在给定输入图像的情况下,对抗性攻击可以描述为增加了一些小的扰动,这些扰动通常对人类来说是微不足道的或无法察觉的,它们会使愚弄机器学习模型做出某些(通常是不正确的)预测。在欺骗DNN模型的情况下,“对抗性示例”一词由Szegedy 等人提出。2013年 szegedy 2013引人入胜。在安全性的上下文中,对抗性学习与可解释性紧密相关,需要对训练后的模型的学习参数进行分析,以便更好地理解特征映射和决策边界对模型安全性的影响。
对抗性攻击可能对许多与安全性相关的应用程序以及物理世界产生严重影响。例如,2018年,Eykholt等人。结果表明,在交通标志上贴上小贴纸(此处为停车标志)会在实验室环境中引起100%的误分类率,而在从移动车辆eykholt2018捕获的视频帧健壮的现场测试中会导致85%的误分类率 。
对抗攻击可以在训练(中毒攻击)过程中或训练后的预测(测试)阶段(逃避攻击)发生。规避攻击可以进一步分为白盒和黑盒攻击。白盒攻击假定对方法和DNN体系结构有全面的了解。在黑盒攻击中,攻击者除了了解机器学习系统的工作方式外,不知道它所输入的数据类型。
基于Python的对抗性学习库包括Cleverhans papernot2016cleverhans,FoolBox rauber2017foolbox,ART nicolae2018adversarial,DEEPSEC ling2019deepsec和AdvBox goodman2020advbox。除了Cleverhans和FoolBox之外,所有库都支持对抗攻击和对抗防御机制。根据Cleverhans的代码文档,开发人员的目标是将来增加常见防御机制的实现。尽管Cleverhans's与TensorFlow和PyTorch兼容,而DEEPSEC仅支持MXNet,但FoolBox和ART支持上述所有三个主要的深度学习框架。此外,最新发布的库AdvBox还增加了对百度PaddlePaddle深度学习库的支持。
尽管对这些框架中实现的各种对抗性攻击和防御方法的详尽列表的详细讨论超出了本文的讨论范围,但表 1总结了受支持的方法以及对研究论文的引用,以供进一步研究。
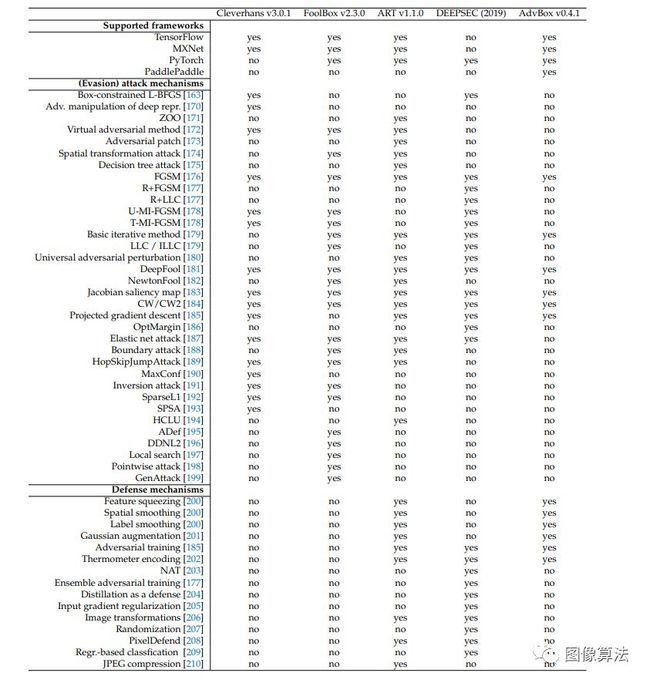
表1.在对抗学习中实现的规避攻击和防御机制的选择工具包。
8.结论
本文回顾了机器学习,数据科学和科学计算方面的一些最著名的进展。它提供了主要主题的简要背景,同时调查了各种挑战以及每种挑战的解决方案现状。在本文的范围之外,还有其他一些更专业的应用和研究领域。例如,基于注意力的Transformer架构以及专用工具
https://github.com/huggingface/transformers
最近已经开始在深度学习vaswani 2017 attention的自然语言处理子领域中占主导地位 ;radford2019语言。
图形数据的深度学习已成为人们关注的一个增长领域,图卷积神经网络目前正积极地用于计算生物学中,用于对raschka2020 machine分子结构进行建模 。该领域的热门库包括基于TensorFlow的Graph Nets battaglia2018关系库和PyTorch Geometric fey2019fast。时间序列分析在Python中被众所周知地忽略了,它以可扩展的StumPy库law2019stumpy的形式重新引起了人们的兴趣 。另一个被忽略的领域,即频繁的模式挖掘,在MLxtend raschka2018 mlxtend中与Pandas兼容的Python实现受到了一些关注 。UMAP McInnes2018,新的Scikit-learn兼容特征提取库已被广泛用于可视化二维流形上的高维数据集。为了提高大型数据集的计算效率,RAPIDS
https://github.com/rapidsai/cuml中包含了基于GPU的UMAP版本。
近年来,人们对Python 中的概率编程,贝叶斯推理和统计建模也越来越感兴趣。该领域的著名软件包括PyStan
STAN Carpenter2016的https://github.com/stan-dev/pystan, 基于Theano的PyMC3 Salvatier2016库,基于TensorFlow的Edward tran2016edward库和Pomegranate schreiber2017 pomegranate,它具有用户友好的Scikit-learn-像API。作为用于在深度学习和AI研究中实现概率模型的下层库,Pyro Bingham2019提供了一个基于PyTorch的概率编程API。NumPyro phan2019composable为Pyro提供了一个NumPy后端,它使用JAX进行JIT编译并优化了CPU和GPU上NumPy操作的执行。
强化学习(RL)是一个研究领域,可以训练代理解决复杂而具有挑战性的问题。由于RL算法基于反复试验的方法以最大化长期奖励,因此RL是机器学习中特别耗费资源的领域。此外,由于RL旨在解决的任务特别具有挑战性,因此RL难以扩展-学习一系列的步骤来玩棋盘或视频游戏,或训练机器人在复杂的环境中导航,这比识别固有的任务要复杂得多。图像中的对象。深度Q网络是Q学习算法和深度学习的结合,一直处于RL最新进展的最前沿,其中包括击败世界冠军玩棋盘游戏Go silver2017 mastering并与排名最高的《星际争霸II》玩家 vinyals2019 grand master竞争。由于现代RL主要基于深度学习,因此大多数实现都利用第5节中讨论的流行的深度学习库之一 ,例如PyTorch或TensorFlow。
我们希望在未来几年内,RL能够实现更多惊人的突破。此外,我们希望用于训练代理人玩棋盘或视频游戏的算法可以用于重要的研究领域,例如蛋白质折叠,这是DeepMind quach2018deepmind当前探索的一种可能性 。作为一种易于学习和使用的语言,Python在许多研究和应用领域中已发展成为通用语言,我们在本文中着重介绍了该语言。随着CPU和GPU计算的进步以及不断增长的用户社区和库生态系统的推动,我们期望Python在未来多年内仍将是科学计算机的主要语言。
更多论文地址源码地址:关注“图像算法”微信公众号
