Zynq7020主控板中Cache问题的解决
一、 运行环境说明
1、 硬件环境
数字信号处理板(主控板)以Xilinx Zynq7020作为处理器,有2路高速ADC信号输入,2路千兆以太网传输,每路网络传输速率约334Mbps。简化的硬件模型图如下: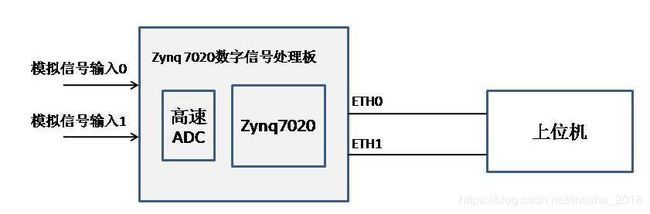
2、 软件版本
集成开发工具:Vivado 2014.2
U-boot:来自于xilinx的github,版本:u-boot-xlnx-xilinx-v2015.4
Linux内核:来自于xilinx的github,版本:linux-xlnx-xilinx-v2015.4
软件架构:Zynq7020双核运行于AMP模式,CPU0跑Linux,管理ETH0;CPU1裸跑,管理ETH1.
二、 问题1:zynq7020双核运行时,cpu0常出现内核崩溃
现象描述:
1、 主控板的2路网口与上位机连接,主控板上电启动,Zynq7020的cpu0会随机出现kernel崩溃,概率较大,但Zynq7020的cpu1启动、运行正常;
2、 如果cpu1控制的eth1不插网线,则cpu0不出现内核崩溃,Zynq7020的双核可正常启动运行;
3、 接步骤2,当cpu0正常运行后,再插上eth1的网线,则cpu0又出现kernel崩溃,概率较大;
分析:
表象上看,CPU0是否出现崩溃与ETH1是否插网线有关:不插网线,可以正常运行;插网线后,则较大概率出现崩溃。
进一步分析可知:ETH1不插网线时,cpu1此时一直死循环在phy检测阶段;当ETH1网线插上后,cpu1的phy检测通过并往下执行后续代码,所以,应该是cpu1中某部分代码的执行,导致了cpu0的崩溃,并且经过进一步的跟踪,发现这部分代码与eth1的网口相关。
考虑了如下可能的原因:
1、 cpu0、cpu1的DDR内存分配
主控板配置的物理内存是512MB,限制cpu0 linux使用的内存是384MB,且是512M的低地段地址,限制cpu1的代码是从0x19000000开始(通过链接文件控制),cpu1的链接结果如下:
| text | data | bss | dec | hex | /filename |
|---|---|---|---|---|---|
| 128852 | 3256 | 50438224 | 50570332 | 303a45c | cpu1.elf |
可知:
Cpu1的可执行文件cpu1.elf的大小加上0x1900000远小于剩余的128M (512-384=128)。内存分配上是没有冲突的。
2、 cpu0、cpu1对其他公共资源的使用冲突
重点嫌疑是L2 cache,在zynq7020中,两个核的L1 cache是独立的,每个核有各自的L1 cache,但512KB的L2cache则是两个核公共的。
根据现象,通过在cpu1代码中增加调试代码,终于定位出来cpu0发生崩溃是当cpu1在做网口初始化时。在cpu1的网口初始化代码中,有对MAC的dma初始化,在函数xemacpsif_dma.c::init_dma()中,分配dma内存时,内存需要分配在non-cache中,其中,有对L2 cache的flush操作。正是这个L2 cache的flush操作,导致了cpu0的崩溃!
解决方法:
问题定位了,则解决起来就比较容易了。我改写了init_dma()函数中调用的Xil_SetTlbAttributes((int)endAdd_aligned, 0xc02)函数,去掉了其中对L2 cache的flush操作,这个操作其实不需要,Cpu0的内核崩溃现象不再出现。
三、问题2:上位机接收到的数据有少量错误
现象描述:
在系统测试中发现:当主控板的通道0外部输入正弦波时,在上位机的图形界面上观察到:本应平滑的正弦波形有时会发生波形跳变。
分析:
第一感觉就是怀疑是fpga数据采样问题,或者是fpga到cpu的数据拷贝问题。
作了如下实验来定位:
1、 fpga自己产生固定数据,每一帧数据相同,此时,从上位机保存的数据看,2个通道的数据正确无误;
2、 fpga自己产生数据,每一帧数据相同,但不同帧的数据递增,此时,从上位机保存的数据看,通道0数据正确,但通道1存在数据与产生的数据不一致,但未发现规律;
3、 fpga自己产生数据,每一帧数据相同,每一帧分别设置为0xaaaa、0x5555交替。此时,从上位机保存的数据看,通道0数据正确,通道1有数据错误。
仔细分析通道1数据(用ultraedit),发现本应全部0xaaaa的数据帧中,会出现0x5555,反之亦然,错误的数据个数总是32的整数倍!我忽然联想到:cache line的大小就是32,会不会是cache捣鬼?
检查cpu1代码,发现cpu1与fpga进行dma传输的乒乓内存块,没有设置为non-cache(这一类的内存应该设置为non-cache),会不会就是这个导致的呢?从现象上看是完全相符的。循此思路,在初始化中,增加了对dma 乒乓内存的non-cache操作,如下:
/* Set dma ping-pang buffer as uncached memory */
Xil_DCacheInvalidateRange((unsigned int)DmaRxBufBase, (unsigned)DMARXBUF_SIZE);
经过上述修改,上述1,2,3的测试步骤不再有错误数据了,看似问题得到解决。
但是,当主控板的通道1在输入连续的正弦波形时,上位机的图形界面上还是会出现波形跳变!
只好再逐一排摸,又经过艰苦的debug,深入分析了很多方面,包括:
- dma IP与zynq芯片的内部架构,dma IP的数据位宽
- Zynq内部HP总线与DDR、OCM的传输优先级设置
- 是否是cpu0的相关操作影响了cpu1的数据
总而言之,对各种可能的情况都进行了梳理、排查,但都没有找到原因。茫然没有思路了,有点走投无路的感觉!只好又回过头来,将目光又瞄向了cache。终于发现,还是cache的问题:之前只在初始化代码中,对ping-pang buffer进行了cache invalid操作,是一次性的,而只执行一次是不够的,还需要在dma的中断中,每次对该buffer进行cache invalid操作!
(后来反思:在该问题的解决过程中,其实有一个失误:因思维定势,认为cache导致的问题已经消除了,故这次没有再考虑它,但是,恰恰还是cache的问题!)
经过这样处理,通道1在输入连续正弦波信号时,终于不再有错误数据了。
但是,cache导致的问题似乎注定是一波三折。
又有新问题出现:发现cpu1对dma ip的中断响应时间达到500us(用示波器检测中断信号的脉宽),而正常情况下,中断响应时间最多不超过20us!500us的中断响应时间将严重影响设备的性能,是不可接受的。
经过分析,发现还是cache问题导致!
定位过程如下:
尝试屏蔽掉对ping-pang buffer的cache invalid操作,发现中断响应时间正常了。是cache invalid操作导致cpu1的中断响应时间异常。经过思考,做了如下修改:
设计中,Dma ip发送给cpu1的数据是写入ping-pang buffer的,每次在进行cache invalid操作时,只需要对dma ip将要写入的目标ping buffer或者pang buffer进行cache invalid操作。而之前,不管写入目标是ping还是pang,对ping和pang buffer一起进行cache invalid操作的。
如此修改后,用示波器监测,只是在上电启动、cpu1开始数据传输的1~2秒内,中断响应时间长(500us),随后就正常了。该现象的解释:一开始中断时间长,是因为在初始化时的cache invalid操作导致的。
修改后,dma ip中断响应时间长的问题得到解决。
四、 小结
在Zynq7020芯片中,L1 cache是每个核独立的,而L2 cache是两个核共享的,这也是绝大多数多核处理器的设计方式。在多核处理器的软件设计中,如果采用AMP架构,由于软件中每个核都有可能要操作L2 cache,所以,必须特别仔细地考虑L2 cache使用中的冲突问题。本文所描述的2个问题都与L2 cache的应用有关,很典型,但也有所区别:第一个问题是双核使用L2 cache的冲突问题,第二个问题则是外设(dma IP)向内存传输数据时,如何在正确的时机、正确的代码位置地进行L2 cache操作的问题。