第一部分 Spark介绍
第二部分 Spark的使用基础
第三部分 Spark工具箱
第四部分 使用不同的数据类型
第五部分 高级分析和机器学习
第六部分 MLlib应用
第七部分 图分析
第八部分 深度学习
将原生类型转换为Spark类型
使用 lit 函数进行转换。lit 会获取一个原生语言的类型,并将其转换为Spark表示。
%scala
import org.apache.spark.sql.functions.lit
df.select(lit(5), lit("five"), lit(5.0))
%python
from pyspark.sql.functions import lit
df.select(lit(5), lit("five"), lit(5.0))
在SQL中不需要 等效的函数,可以直接使用值。
SELECT 5, "FIVE", 5.0
使用 Booleans 类型
在数据分析中,Booleans是常用的基础数据类型,因为它们是过滤操作的基本要素。
Booleans语句包含四个元素:and, or ,true, false。
我们使用这些简单的结构 构建逻辑语句 来计算为 true或false。
这些语句通常作为条件要求 ,当一行数据必须 或者通过要求 或这被过滤掉。
我们可以执行相等,或大于、小于某个值。
Scala对==和===的使用有一些特别的语义。在Spark中,如果你想通过 相等条件来过滤,你需要使用===(相等)或=!=(不等)。你也可以使用 not 函数 和 equalTo 方法。
%scala
import org.apache.spark.sql.functions.col
df.where(col("InvoiceNo").equalTo(536365))
.select("InvoiceNo", "Description")
.show(5, false)
import org.apache.spark.sql.functions.col
df.where(col("InvoiceNo") === 536365)
.select("InvoiceNo", "Description")
.show(5, false)
Python则保留了更传统的符号。
%python
from pyspark.sql.functions import col
df.where(col("InvoiceNo") != 536365)\
.select("InvoiceNo", "Description")\
.show(5, False)
另一中选择(可能是最简洁的)是将谓词指定为字符串中的表达式。这在Scala和Python中都有效。这也为我们提供了另一种表达“不等”的方法。
df.where("InvoiceNo = 536365")
.show(5, false)
df.where("InvoiceNo <> 536365")
.show(5, false)
当我们使用 and 和 or 时,我们可以 用多个部分 来指定boolean表达式。在Spark中,你应该始终将过滤器连接在一起为一个 连续的过滤器。
这是因为 尽管 boolean表达式 是串行表达的(一个接一个),但Spark会将所有这些过滤器平展为一条语句,并在同一时间执行所有过滤,为我们创建and语句。 而你喜欢的话,可以明确地使用and来指定你的语句,如果你连续地指定他们,通常更容易进行推理和阅读。or语句需要在相同的语句中指定。
%scala
val priceFilter = col("UnitPrice") > 600
val descripFilter = col("Description").contains("POSTAGE"
df.where(col("StockCode").isin("DOT"))
.where(priceFilter.or(descripFilter))
.show()
%python
from pyspark.sql.functions import instr
priceFilter = col("UnitPrice") > 600
descripFilter = instr(df.Description, "POSTAGE") >= 1
df.where(df.StockCode.isin("DOT"))\
.where(priceFilter | descripFilter)\
.show()
%sql
SELECT
*
FROM dfTable
WHERE
StockCode in ("DOT") AND
(UnitPrice > 600 OR
instr(Description, "POSTAGE") >= 1)
Boolean表达式不仅用于过滤器,为了过滤一个DataFrame我们也可以指定一个boolean列。
%scala
val DOTCodeFilter = col("StockCode") === "DOT"
val priceFilter = col("UnitPrice") > 600
val descripFilter = col("Description").contains("POSTAGE")
df.withColumn("isExpensive",
DOTCodeFilter.and(priceFilter.or(descripFilter)))
.where("isExpensive")
.select("unitPrice", "isExpensive")
.show(5)
%python
from pyspark.sql.functions import instr
DOTCodeFilter = col("StockCode") == "DOT"
priceFilter = col("UnitPrice") > 600
descripFilter = instr(col("Description"), "POSTAGE") >= 1
df.withColumn("isExpensive",
DOTCodeFilter & (priceFilter | descripFilter))\
.where("isExpensive")\
.select("unitPrice", "isExpensive")\
.show(5)
%sql
SELECT
UnitPrice,
(StockCode = ‘DOT’ AND
(UnitPrice > 600 OR
instr(Description, "POSTAGE") >= 1)) as isExpensive
FROM dfTable
WHERE
(StockCode = ‘DOT’ AND
(UnitPrice > 600 OR
instr(Description, "POSTAGE") >= 1))
注意到我们不需要指定 过滤器为表达式,只需要使用一个列名 而无需其他额外的工作。
实际上,与编写DataFrame接口相比,只是用SQL语句来表达过滤器往往更简单。SparkSQL允许我们使用SQL语句而 没有任何性能损失。如下两个语句是等价的。
%scala
import org.apache.spark.sql.functions.{expr, not, col}
df.withColumn("isExpensive", not(col("UnitPrice").leq(250)))
.filter("isExpensive")
.select("Description", "UnitPrice")
.show(5)
df.withColumn("isExpensive", expr("NOT UnitPrice <= 250"))
.filter("isExpensive")
.select("Description", "UnitPrice")
.show(5)
一个可能会出现的“陷阱”是在有空数据时创建boolean表达式。如果存在空数据,你必须以不同的方式来处理。如下展示了如何保证 空值安全(null safe) 的等价测试。
df.where(col("Description").eqNullSafe("hello")).show()
使用 Number 类型数据
当处理大数据时,在执行过过滤后 的 第二个常见的任务是 计算。 大多数情况下,假设我们处理树枝数据类型,我们只需简单地表达我们的计算,这应该是有效的。
制造一个人为的例子,让我们想象我们发现我们忘记记录 零售数据中的数量了,真是数量等于(当前数量 *单价)^2+5。 下面来介绍我们的第一格数值函数 pow 函数,用来取一列的 给定次幂。
%scala
import org.apache.spark.sql.functions.{expr, pow}
val fabricatedQuantity = pow(col("Quantity") * col("UnitPrice"), 2) + 5
df.select(
expr("CustomerId"),
fabricatedQuantity.alias("realQuantity"))
.show(2)
%python
from pyspark.sql.functions import expr, pow
fabricatedQuantity = pow(col("Quantity") * col("UnitPrice"), 2) + 5
df.select(
expr("CustomerId"),
fabricatedQuantity.alias("realQuantity"))\
.show(2)
我们可以将列乘在一起,因为他们都是数值的。自然地,我们可以根据需要进行加减。实际上们所有这些都可以通过SQL表达式做到。
%scala
df.selectExpr(
"CustomerId",
"(POWER((Quantity * UnitPrice), 2.0) + 5) as realQuantity")
.show(2)
%python
df.selectExpr(
"CustomerId",
"(POWER((Quantity * UnitPrice), 2.0) + 5) as realQuantity" )
.show(2)
%sql
SELECT
customerId,
(POWER((Quantity * UnitPrice), 2.0) + 5) as realQuantity
FROM dfTable
另一个常见的数值任务是舍入。如果只想舍入为一个整数,通常可以把它转换成Interger 就可以了。 然而Spark还有更细节的函数来 显示地执行 并达到一定的精度。下例中我们舍入到 一位小数。
%scala
import org.apache.spark.sql.functions.{round, bround}
df.select(
round(col("UnitPrice"), 1).alias("rounded"),
col("UnitPrice"))
.show(5)
默认情况下,如果数值恰好在两个树之间,round函数 会向上取进。你可以使用 bround 来向下舍入。
%scala
import org.apache.spark.sql.functions.lit
df.select(
round(lit("2.5")),
bround(lit("2.5")))
.show(2)
%python
from pyspark.sql.functions import lit, round, bround
df.select(
round(lit("2.5")),
bround(lit("2.5")))\
.show(2)
%sql
SELECT
round(2.5),
bround(2.5)
另一个数值任务是 计算两列的相关性。 比如,我们可以看两列的皮尔逊相关系数,看看是否更便宜的东西通常购买的数量更多。 我们可以通过一个函数 或 DataFrame统计方法(DataFrameStatFunctions中的方法)来实现。
%scala
import org.apache.spark.sql.functions.{corr}
df.stat.corr("Quantity", "UnitPrice")
df.select(corr("Quantity", "UnitPrice")).show()
%python
from pyspark.sql.functions import corr
df.stat.corr("Quantity", "UnitPrice")
df.select(corr("Quantity", "UnitPrice")).show()
%sql
SELECT
corr(Quantity, UnitPrice)
FROM
dfTable
一个常见的任务是计算一列或一组列的 汇总统计量。 可以使用describe 方法来实现。
其会取所有数值列,并计算和、均值、标准查、最小最大值。
该方法应该主要用于在控制台中查看 统计数值,因为在以后其模式可能会改变。
%scala
df.describe().show()
%python
df.describe().show()
如果你需要这些准确的数,也可以将其作为 聚合 来执行,通过import函数并将它们用到你需要的列上。
%scala
import org.apache.spark.sql.functions.{count, mean, stddev_pop, min, max}
%python
from pyspark.sql.functions import count, mean, stddev_pop, min, max
这是一些StatFunctions包中可用的统计函数,是允许你用来计算的DataFrame方法。比如,我们可以使用 approxQuatile方法来 计算数据的 准确的或近似的 分位数。
%scala
val colName = "UnitPrice"
val quantileProbs = Array(0.5)
val relError = 0.05
df.stat.approxQuantile("UnitPrice", quantileProbs, relError) // 2.51
%python
colName = "UnitPrice"
quantileProbs = [0.5]
relError = 0.05
df.stat.approxQuantile("UnitPrice", quantileProbs, relError) # 2.51
我们同样可以使用函数来 查看 交叉表 和 频繁相对(其输出规模会很大)
%scala
df.stat.crosstab("StockCode", "Quantity").show()
%python
df.stat.crosstab("StockCode", "Quantity").show()
%scala
df.stat.freqItems(Seq("StockCode", "Quantity")).show()
%python
df.stat.freqItems(["StockCode", "Quantity"]).show()
我们还可以使用monotonically_increasing_id函数 给每行添加一个唯一id。其会从0开始为每行生成一个唯一值。
%scala
import org.apache.spark.sql.functions.monotonically_increasing_id
df.select(monotonically_increasing_id()).show(2)
%python
from pyspark.sql.functions import monotonically_increasing_id
df.select(monotonically_increasing_id()).show(2)
在每个release版本中都会有新增加的函数。搜索API文档来了解更多的信息和函数。
使用 String 类型数据
字符串操作几乎出现在每个数据流中,有必要解释一下你能对字符串做什么。
你可能会操作日志文件 执行正则表达式来进行提取或替换。 或检查某字段是否存在,或调整字符串的大小写。
我们首先一最简单的调整大小写 为例。initcap函数会 将 每格通过空格和其他 单词分开的 单词首字母 大写。
%scala
import org.apache.spark.sql.functions.{initcap}
df.select(initcap(col("Description"))).show(2, false)
%python
from pyspark.sql.functions import initcap
df.select(initcap(col("Description"))).show()
%sql
SELECT
initcap(Description)
FROM
dfTable
同上面一样,我们也可以简单地 调整整个字符串大小写。
%scala
import org.apache.spark.sql.functions.{lower, upper}
df.select(
col("Description"),
lower(col("Description")),
upper(lower(col("Description"))))
.show(2)
%python
from pyspark.sql.functions import lower, upper
df.select(
col("Description"),
lower(col("Description")),
upper(lower(col("Description"))))\
.show(2)
%sql
SELECT
Description,
lower(Description),
Upper(lower(Description))
FROM
dfTable
另一个简单的任务 是 在字符串中 添加或移除空格。使用 lpad, ltrim, rpad, rtrim, trim来实现。
%scala
import org.apache.spark.sql.functions.{lit, ltrim, rtrim, rpad, lpad, trim}
df.select(
ltrim(lit(" HELLO ")).as("ltrim"),
rtrim(lit(" HELLO ")).as("rtrim"),
trim(lit(" HELLO ")).as("trim"),
lpad(lit("HELLO"), 3, " ").as("lp"),
rpad(lit("HELLO"), 10, " ").as("rp"))
.show(2)
%python
from pyspark.sql.functions import lit, ltrim, rtrim, rpad, lpad, trim
df.select(
ltrim(lit(" HELLO ")).alias("ltrim"),
rtrim(lit(" HELLO ")).alias("rtrim"),
trim(lit(" HELLO ")).alias("trim"),
lpad(lit("HELLO"), 3, " ").alias("lp"),
rpad(lit("HELLO"), 10, " ").alias("rp"))\
.show(2)
%sql
SELECT
ltrim(‘ HELLLOOOO ‘),
rtrim(‘ HELLLOOOO ‘),
trim(‘ HELLLOOOO ‘),
lpad(‘HELLOOOO ‘, 3, ‘ ‘),
rpad(‘HELLOOOO ‘, 10, ‘ ‘)
FROM
dfTable
可以注意到,如果lpad或rpad 参数为小于 字符串长度的数,会移除字符串右边的值。
正则表达式
最常执行的一个任务可能就是 查询一个字符串中是否存在指定字符串,或用其他值替换所有指定字符串。这通常通过 存在于很多编程语言中的叫做“正则表达式”的工具来解决。正则表达式 使用户 可以指定一组规则 来 或从一个字符串中提取出特定值 或用其他值来替换它们。
Spark充分利用了Java正则表达式的强大功能。Java RegEx 语法与其他编程语言略有不同,所以在使用之前很值得回顾一下。Spark中有两个核心函数 你可以用来执行 正则表达式任务:regexp_extract 和 regexp_replace。它们分别负责提取 和 替换值。
下面来探索如何使用regexp_replace来替换描述列中的颜色名。
%scala
import org.apache.spark.sql.functions.regexp_replace
val simpleColors = Seq("black", "white", "red", "green", "blue")
val regexString = simpleColors.map(_.toUpperCase).mkString("|")
// the | signifies `OR` in regular expression syntax
df.select(
regexp_replace(col("Description"), regexString, "COLOR")
.alias("color_cleaned"),
col("Description"))
.show(2)
%python
from pyspark.sql.functions import regexp_replace
regex_string = "BLACK|WHITE|RED|GREEN|BLUE"
df.select(
regexp_replace(col("Description"), regex_string, "COLOR")
.alias("color_cleaned"),
col("Description"))\
.show(2)
%sql
SELECT
regexp_replace(Description, ‘BLACK|WHITE|RED|GREEN|BLUE’, ‘COLOR’) as
color_cleaned,
Description
FROM
dfTable
另一个常见的任务是 用其他字符替换给定字符。将其构建为正则表达式可能非常繁琐,所以Spark也提供了translate函数。这是在字符级别完成的,其将用替换字符串中的索引字符替换字符的所有实例。
%scala
import org.apache.spark.sql.functions.translate
df.select(
translate(col("Description"), "LEET", "1337"),
col("Description"))
.show(2)
%python
from pyspark.sql.functions import translate
df.select(
translate(col("Description"), "LEET", "1337"),
col("Description"))\
.show(2)
%sql
SELECT
translate(Description, ‘LEET’, ‘1337’),
Description
FROM
dfTable
我们还可以执行类似的操作,比如将前面提到的颜色提取出来。
%scala
import org.apache.spark.sql.functions.regexp_extract
val regexString = simpleColors
.map(_.toUpperCase)
.mkString("(", "|", ")")
// the | signifies OR in regular expression syntax
df.select(
regexp_extract(col("Description"), regexString, 1)
.alias("color_cleaned"),
col("Description"))
.show(2)
%python
from pyspark.sql.functions import regexp_extract
extract_str = "(BLACK|WHITE|RED|GREEN|BLUE)"
df.select(
regexp_extract(col("Description"), extract_str, 1)
.alias("color_cleaned"),
col("Description"))\
.show(2)
%sql
SELECT
regexp_extract(Description, ‘(BLACK|WHITE|RED|GREEN|BLUE)’, 1),
Description
FROM
dfTable
有时候,相比抽取值,我们更想去检查存在性。可以在每列使用Contains方法来做到。它会返回一个布尔型,来说明在列的字符串中是否能找到 指定字符串。
%scala
val containsBlack = col("Description").contains("BLACK")
val containsWhite = col("DESCRIPTION").contains("WHITE")
df.withColumn("hasSimpleColor", containsBlack.or(containsWhite))
.filter("hasSimpleColor")
.select("Description")
.show(3, false)
在Python中使用instr函数。
%python
from pyspark.sql.functions import instr
containsBlack = instr(col("Description"), "BLACK") >= 1
containsWhite = instr(col("Description"), "WHITE") >= 1
df.withColumn("hasSimpleColor", containsBlack | containsWhite)\
.filter("hasSimpleColor")\
.select("Description")\
.show(3, False)
%sql
SELECT
Description
FROM
dfTable
WHERE
instr(Description, ‘BLACK’) >= 1 OR
instr(Description, ‘WHITE’) >= 1
对于只有两个值的情况,这很简单,但是对于更多的值,情况就复杂得多了。
让我们以一种更动态的方式解决这个问题,并利用Spark接受动态数量参数的能力。
当我们将 一个值的列表 转换为 一组参数 并将它们传给一个函数,我们使用一个叫做varargs的语言特性。该特性允许我们有效地解开 任意长度的数组 并 将其作为参数传给一个函数。加上select 允许我们 动态地创建任意数量的列。
%scala
val simpleColors = Seq("black", "white", "red", "green", "blue")
val selectedColumns = simpleColors.map(color => {
col("Description")
.contains(color.toUpperCase)
.alias(s"is_$color")
}):+expr("*") // could also append this value
df.select(selectedColumns:_*)
.where(col("is_white").or(col("is_red")))
.select("Description")
.show(3, false)
在Python中也可以很容易的做到这一点。下面的例子中,我们会用一个不同的函数 locate 来返回整数位置(基于1的位置)。然后在使用其 作为一个新的基本特性前 将其转化为布尔型。
%python
from pyspark.sql.functions import expr, locate
simpleColors = ["black", "white", "red", "green", "blue"]
def color_locator(column, color_string):
"""This function creates a column declaring whether or
not a given pySpark column contains the UPPERCASED
color.
Returns a new column type that can be used
in a select statement.
"""
return locate(color_string.upper(), column)\
.cast("boolean")\
.alias("is_" + c)
selectedColumns = [color_locator(df.Description, c) for c in simpleColors]
selectedColumns.append(expr("*")) # has to a be Column type
df.select(*selectedColumns)\
.where(expr("is_white OR is_red"))\
.select("Description")\
.show(3, False)
这个简单的特性 可以以一种易于推理和扩展的方式,经常帮助你 用编程的方式 生成列或布尔过滤器。 我们可以将其扩展到 计算给定输入的最小公分母 或 检查一个数是否是质数。
使用 Dates 和 Timestamp 类型数据
日期 和时间 是 程序语言和数据库中 持续的挑战。经常需要 跟踪时区 和保证形式正确有效。Spark通过明确地关注两中时间相关的信息 来 尽力保持这些事情简单。 这两种信息就是 dates,只关注日历日期,timestamps 包含日期和时间信息。
正如我们在当前数据集中看到的,Spark会尽最大努力正确识别列类型,包括日期和时间戳,当我们可以使用 inferschema时。我们可以看到 其在我们当前数据集上效果非常好,因为它能够在不需要我们给出一些规范的情况下,识别和读取我们的日期格式。
正如我们在前面所暗示的,处理日期和时间戳 与处理字符串关系密切,因为我们经常将 字符串或日期存储为 字符串,并在运行时将它们转化为日期类型。
这在处理数据库和结构化数据是不太常见,但处理text和csv文件是很常见。
不幸的是,在处理日期和时间戳时有很多需要注意的地方,特别是在遇到时区处理时。在2.1及之前的版本中,如果在解析的值中没有明确地指定时区,Spark会根据计算机的时区来进行解析。如果必要的话,你可以设置一个会话本地时区,通过在SQL配置中设置spark.conf.sessionLocalTimeZone。这需要根据Java的时区格式进行设置。
df.printSchema()
>>>
root
|-- InvoiceNo: string (nullable = true)
|-- StockCode: string (nullable = true)
|-- Description: string (nullable = true)
|-- Quantity: integer (nullable = true)
|-- InvoiceDate: timestamp (nullable = true)
|-- UnitPrice: double (nullable = true)
|-- CustomerID: double (nullable = true)
|-- Country: string (nullable = true)
尽管Spark会尽最大努力做到这一点,但有时却无法处理格式奇怪的日期和时间。
推断出你所需要用到的转换形式的关键 是要确保你准确地知道 在整个过程中的每一步 你拥有什么类型和格式。另一个普遍的陷阱是Spark的Timestamp类型 只支持二级精度,这意味这如果你想要处理秒或毫秒,你必须通过将它们作为longs来进行处理以解决这个问题。任何时候强制转换为Timestamp类型,都会损失更多的精度。
Spark在对 任何时间点上你所拥有的格式 有一点特别。在解析和转换时 必须 显示地说明,以确保执行过程没有问题。Spark使用Java的日期和时间戳,因此符合符合这些标准。我们从基础开始,获取当前日期和当前时间戳。
%scala
import org.apache.spark.sql.functions.{current_date, current_timestamp}
val dateDF = spark.range(10)
.withColumn("today", current_date())
.withColumn("now", current_timestamp())
dateDF.createOrReplaceTempView("dateTable")
%python
from pyspark.sql.functions import current_date, current_timestamp
dateDF = spark.range(10)\
.withColumn("today", current_date())\
.withColumn("now", current_timestamp())
dateDF.createOrReplaceTempView("dateTable")
>>>
root
|-- id: long (nullable = false)
|-- today: date (nullable = false)
|-- now: timestamp (nullable = false)
现在我们有了一个简单的DataFrame用来进行处理,让我们从今天起加减5天。这些函数以 一列 及 要加减的数目 为参数。
%scala
import org.apache.spark.sql.functions.{date_add, date_sub}
dateDF
.select(
date_sub(col("today"), 5),
date_add(col("today"), 5))
.show(1)
%python
from pyspark.sql.functions import date_add, date_sub
dateDF\
.select(
date_sub(col("today"), 5),
date_add(col("today"), 5))\
.show(1)
%sql
SELECT
date_sub(today, 5),
date_add(today, 5)
FROM
dateTable
另一个常见的任务是查看两个日期间的差距。我们使用datediff函数来解决这个问题,它会返回两个日期间的天数。大多数情况下,尽管我们只关心天数,因为月份可以有奇怪的天数,但还是有一个函数months_between可以给出两个日期之间的月数。
%scala
import org.apache.spark.sql.functions.{datediff, months_between, to_date}
dateDF
.withColumn("week_ago", date_sub(col("today"), 7))
.select(datediff(col("week_ago"), col("today")))
.show(1)
dateDF
.select(
to_date(lit("2016-01-01")).alias("start"),
to_date(lit("2017-05-22")).alias("end"))
.select(months_between(col("start"), col("end")))
.show(1)
%python
from pyspark.sql.functions import datediff, months_between, to_date
dateDF\
.withColumn("week_ago", date_sub(col("today"), 7))\
.select(datediff(col("week_ago"), col("today")))\
.show(1)
dateDF\
.select(
to_date(lit("2016-01-01")).alias("start"),
to_date(lit("2017-05-22")).alias("end"))\
.select(months_between(col("start"), col("end")))\
.show(1)
%sql
SELECT
to_date(‘2016-01-01’),
months_between(‘2016-01-01’, ‘2017-01-01’),
datediff(‘2016-01-01’, ‘2017-01-01’)
FROM
dateTable
你会注意到上面介绍了一个新的函数to_date。它允许你将一个字符串转换为日期,可选地使用指定的格式。我们在Java simpleDataFormat中指定了我们的格式,如果你使用这个函数,那么引用该格式非常重要。
%scala
import org.apache.spark.sql.functions.{to_date, lit}
spark.range(5).withColumn("date", lit("2017-01-01"))
.select(to_date(col("date")))
.show(1)
%python
from pyspark.sql.functions import to_date, lit
spark.range(5).withColumn("date", lit("2017-01-01"))\
.select(to_date(col("date")))\
.show(1)
如果不能解析日期,Spark会抛出错误,只返回null。这在较大的pipeline中可能有点棘手,因为你可能希望使用一种格式的数据,同事有另一种格式来获取它。举例来说,让我们看看日期格式从year-month-day 到 year-day-month的转换。Spark将无法解析此日期,并将返回null。
我们发现这对于一个bug来说是非常棘手的情况,因为一些数据匹配正确的格式而另一些数据不匹配。如上图,第二个时间被显示为12月11日而不是正确的日期11月12日。Spark不会抛出错误,因为它不知道时间是否混淆,或特定的列是否不正确。
让我们一步一步修复这个pipeline,并给出一种鲁棒的方法彻底地避免这种问题。
第一步记得我们需要根据Java SimpleDateFormat标准(记录在https://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html
)来指定我们的日期格式。
我们会使用两个函数来解决这个问题,to_date和to_timestamp。前者需要一种可选的格式,而后者需要一种。
%scala
import org.apache.spark.sql.functions.{unix_timestamp, from_unixtime}
val dateFormat = "yyyy-dd-MM"
val cleanDateDF = spark.range(1)
.select(
to_date(lit("2017-12-11"), dateFormat)
.alias("date"),
to_date(lit("2017-20-12"), dateFormat)
.alias("date2"))
cleanDateDF.createOrReplaceTempView("dateTable2")\
%python
from pyspark.sql.functions import unix_timestamp, from_unixtime
dateFormat = "yyyy-dd-MM"
cleanDateDF = spark.range(1)\
.select(
to_date(unix_timestamp(lit("2017-12-11"), dateFormat).cast("timestamp"))\
.alias("date"),
to_date(unix_timestamp(lit("2017-20-12"), dateFormat).cast("timestamp"))\
.alias("date2"))
cleanDateDF.createOrReplaceTempView("dateTable2")
%sql
SELECT
to_date(date, ‘yyyy-dd-MM’),
to_date(date2, ‘yyyy-dd-MM’),
to_date(date)
FROM
dateTable2
to_timestamp的例子,同样需要指定格式。
%scala
import org.apache.spark.sql.functions.to_timestamp
cleanDateDF
.select(
to_timestamp(col("date"), dateFormat))
.show()
%python
from pyspark.sql.functions import to_timestamp
cleanDateDF\
.select(
to_timestamp(col("date"), dateFormat))\
.show()
%sql
SELECT
to_timestamp(date, ‘yyyy-dd-MM’),
to_timestamp(date2, ‘yyyy-dd-MM’)
FROM
dateTable2
在所有语言中,日期和时间戳之间的转换都很简单,在SQL中,用一下的方式来实现
%sql
SELECT cast(to_date("2017-01-01", "yyyy-dd-MM") as timestamp)
一旦我们将日期或时间戳转换为正确的格式和类型。对它们进行比较实际上很简单。我们只需要确定 要么使用日期/时间戳类型,或根据正确的格式yyyy-MM-dd来指定字符串。
隐式的配型转换是 自找麻烦,特别是在处理 不同时区或形式的 空数据或日期时。我们鼓励使用显示的方式进行解析 而不是依赖隐式转换。
使用数据中的 Null
作为最佳实践,你应该经常使用nulls来代表DataFrame中的丢失数据和空数据。相比于使用空字符串或其他值代替nulls,Spark更好地优化了处理空值的情况。最基本的处理null值的方法,在DataFrame中,是使用DataFrame中的.na分包。其中也有几个函数可以执行操作,并显示地指定Spark应该如何处理空值。请参阅前一章中讨论排序的部分,以及本章前面关于布尔表达式的部分。
Nulls 对所有程序都是一个挑战,Spark也不例外。我们建议 在处理null值时,显式地总比隐式地好。例如,在本部分我们看到我们可以如何定义含有null类型的列。然而,这是存在隐患的。当我们声明一个列不能含有null时,这实际上并没有强制执行。
再次重申,当你定义了一个schema,声明所有列不含null值——spark不会强制执行,并会很高兴地让空值进入该列。nullable信号 可以帮助SparkSQL优化列的处理。如果你有null值在列中,但不应该有null值时,会得到不正确的结果 或 可能会看到 难以调试的 奇怪异常。
对于null值有两件事你可以做。你可以指明丢弃控制 或 你可以使用其它值来填充它们(全局地 或给予每列地)。
Coalesce
Spark可以允许你通过coalesce函数 从一组列中选择第一个null值。在本例中没有null值,所以只返回第一列。
%scala
import org.apache.spark.sql.functions.coalesce
df.select(coalesce(col("Description"), col("CustomerId"))).show()
%python
from pyspark.sql.functions import coalesce
df.select(coalesce(col("Description"), col("CustomerId"))).show()
nullIf, Ifnull, nvl, and nvl2
有几个SQL函数允许我们时间类似的事情。
ifnull允许你在第一个值为null时,选择第二个值,默认为第一个。
nullif允许你 在两个值相等是返回null 或 在他们不等时返回第二个值。
nvl会在第一个值为null时返回第二个值,默认返回第一个。
nvl2会在第一个值为null时返回第二个,否则 返回最后指定值(下例中为 else_value)。
SELECT
ifnull(null, ‘return_value’),
nullif(‘value’, ‘value’),
nvl(null, ‘return_value’),
nvl2(‘not_null’, ‘return_value’, "else_value")
FROM dfTable
LIMIT 1
>>>
+------------+----+------------+------------+
| a| b| c| d|
+------------+----+------------+------------+
|return_value|null|return_value|return_value|
+------------+----+------------+------------+
自然地,我们也可以在DataFrame的select表达式中使用它们。
Drop
最简单的可能就是drop了,它只是删除包含null的行。默认删除 任意值为null的任意行。
df.na.drop()
df.na.drop("any")
SQL中我们必须一列一列地做。
%sql
SELECT
*
FROM
dfTable
WHERE
Description IS NOT NULL
传入“any”为参数,当任意值为null时就会 丢弃一行。
传入“all”为参数,只要当一行的所有值为null或NaN时 才丢弃该行。
还可以通过传入列数组 将其应用于指定的列。
%scala
df.na.drop("all", Seq("StockCode", "InvoiceNo"))
%python
df.na.drop("all", subset=["StockCode", "InvoiceNo"])
Fill
Fill允许你用一组值 填充一列或多列。这个可以通过指定一个map来实现,指定值和列匹配。
比如填充null值为 字符串。
df.na.fill("All Null values become this string")
我们可以做同样的事在 integer列 df.na.fill(5:Integer) 或 doubles列上df.na.fill(5:Double)。
为了指定列,我们只需要传递一个列名的数组。
%scala
df.na.fill(5, Seq("StockCode", "InvoiceNo"))
%python
df.na.fill("all", subset=["StockCode", "InvoiceNo"])
我们也可以用scala 的 Map来做这件事。Map中 key是列名,value是我们想用来替换null值的数值。
%scala
val fillColValues = Map(
"StockCode" -> 5,
"Description" -> "No Value"
)
df.na.fill(fillColValues)
%python
fill_cols_vals = {
"StockCode": 5,
"Description" : "No Value"
}
df.na.fill(fill_cols_vals)
Replace
除了使用drop 和 fill 来替换null值,我们可以使用更灵活的选择 来不仅处理null值。可能更厂家你的使用情况是 根据根据当前值 替换指定列中的所有值。唯一的要求是 用来替换的值必须同 原始值同一类型。
%scala
df.na.replace("Description", Map("" -> "UNKNOWN"))
%python
df.na.replace([""], ["UNKNOWN"], "Description")
Ordering
正如前面章节所讨论的,可以使用asc_nulls_first, desc_nulls_first, asc_nulls_last或desc_nulls_last 来指定 希望空值出现在有序DataFrame中的什么位置
使用复杂数据类型
Complex Types 可以帮助你 以一种对你希望解决的问题更有意义的方式 来 组织 和构建 你的数据。
有三种复杂类型: structs, arrays, maps。
Structs
你可以把 structs 视作DataFrames中的DataFrames。一个例子可以更清晰地阐述这点。我们可以通过 将一组列包装在查询的圆括号中 来创建一个struct。
df.selectExpr("(Description, InvoiceNo) as complex", "*")
df.selectExpr("struct(Description, InvoiceNo) as complex", "*")
%scala
import org.apache.spark.sql.functions.struct
val complexDF = df
. select(struct("Description", "InvoiceNo").alias("complex"))
complexDF.createOrReplaceTempView("complexDF")
%python
from pyspark.sql.functions import struct
complexDF = df\
.select(struct("Description", "InvoiceNo").alias("complex"))
complexDF.createOrReplaceTempView("complexDF")
这样我们现在拥有了一个包含 complex列的 DataFrame。 我们可以像对其他DataFrame一样查询它,唯一的不同是 我们使用 点语法 或 列方法getField。
complexDF.select("complex.Description")
complexDF.select(col("complex").getField("Description")
我们也可以用 * 来查询struct中的所有值。这将把所有列显示为DataFrame。
complexDF.select("complex.*")
%sql
SELECT
complex.*
FROM
complexDF
Arrays
我们通过一个例子来定义Arrays。根据目前的数据,我们的目标是将Description列中的每个单词记下来,并转换成一个DataFrame中的row。
第一个任务是将Description列转换为一个 复杂类型,一个 Array。
1.split
我们使用split函数来做这件事,并指定分隔符。
%scala
import org.apache.spark.sql.functions.split
df.select(split(col("Description"), " ")).show(2)
%python
from pyspark.sql.functions import split
df.select(split(col("Description"), " ")).show(2)
%sql
SELECT
split(Description, ‘ ‘)
FROM
dfTable
>>>
+---------------------+
| split(Description, )|
+---------------------+
| [WHITE, HANGING, ...|
| [WHITE, METAL, LA...|
+---------------------+
这非常强大,因为Spark允许我们 将复杂类型作为另一个列 来进行操作。我们也可以 通过类-python语法 对array的值进行查询。
%scala
df.select(split(col("Description"), " ").alias("array_col"))
.selectExpr("array_col[0]")
.show(2)
%python
df.select(split(col("Description"), " ").alias("array_col"))\
.selectExpr("array_col[0]")\
.show(2)
%sql
SELECT
split(Description, ‘ ‘)[0]
FROM
dfTable
>>>
+------------+
|array_col[0]|
+------------+
| WHITE|
| WHITE|
+------------+
2.Array Length
可以通过查询array的size来查询 array的长度。
%scala
import org.apache.spark.sql.functions.size
df.select(size(split(col("Description"), " "))).show(2) // shows 5 and 3
%python
from pyspark.sql.functions import size
df.select(size(split(col("Description"), " "))).show(2) # shows 5 and 3
3.Array Contains
例如,我们可以看到这个数组是否包含一个值。
%scala
import org.apache.spark.sql.functions.array_contains
df.select(array_contains(split(col("Description"), " "), "WHITE")).show(2)
%python
from pyspark.sql.functions import array_contains
df.select(array_contains(split(col("Description"), " "), "WHITE")).show(2)
%sql
SELECT
array_contains(split(Description, ‘ ‘), ‘WHITE’)
FROM
dfTable
LIMIT 2
>>>
+--------------------------------------------+
|array_contains(split(Description, ), WHITE)|
+--------------------------------------------+
| true|
| true|
+--------------------------------------------+
但这 没能解决我们现在的问题。为了将一个 复杂类型转换为一组row(数组中每格值一个row),我们使用explode函数。
3.Explode
explode函数 接受一个由arrays组成的列,并为数组中的每个值创建一个row(其余的值都是重复的)。下图描述了这个过程。
%scala
import org.apache.spark.sql.functions.{split, explode}
df.withColumn("splitted", split(col("Description"), " "))
.withColumn("exploded", explode(col("splitted")))
.select("Description", "InvoiceNo", "exploded")
.show(2)
%python
from pyspark.sql.functions import split, explode
df.withColumn("splitted", split(col("Description"), " "))\
.withColumn("exploded", explode(col("splitted")))\
.select("Description", "InvoiceNo", "exploded")\
.show(2)
%sql
SELECT
Description,
InvoiceNo,
exploded
FROM
(SELECT
*,
split(Description, " ") as splitted
FROM
dfTable)
LATERAL VIEW explode(splitted) as exploded
LIMIT 2
>>>
+--------------------+---------+--------+
| Description|InvoiceNo|exploded|
+--------------------+---------+--------+
|WHITE HANGING HEA...| 536365| WHITE|
|WHITE HANGING HEA...| 536365| HANGING|
+--------------------+---------+--------+
4.Map
Maps的使用频率相对低些,但仍然是重要的内容。我们通过 map 函数 和 列的键值对 来创建它。然后我们就可以像 选择array一样 选择它们。
%scala
import org.apache.spark.sql.functions.map
df.select(map(col("Description"), col("InvoiceNo")).alias("complex_map"))
.selectExpr("complex_map[‘Description’]")
.show(2)
%python
from pyspark.sql.functions import create_map
df.select(create_map(col("Description"), col("InvoiceNo")).alias("complex_map"))\
.show(2)
%sql
SELECT
map(Description, InvoiceNo) as complex_map
FROM
dfTable
WHERE
Description IS NOT NULL
+--------------------+
| complex_map|
+--------------------+
|Map(WHITE HANGING...|
|Map(WHITE METAL L...|
+--------------------+
我们可以使用合适的key来查询它们。缺失的key返回null。
%scala
df.select(map(col("Description"), col("InvoiceNo")).alias("complex_map"))
.selectExpr("complex_map[‘WHITE METAL LANTERN’]")
.show(2)
%python
df.select(map(col("Description"), col("InvoiceNo")).alias("complex_map"))\
.selectExpr("complex_map[‘WHITE METAL LANTERN’]")\
.show(2)
>>>
+--------------------------------+
|complex_map[WHITE METAL LANTERN]|
+--------------------------------+
| null|
| 536365|
+--------------------------------+
我们也可以对map类型 使用explode,这回将map转换为 列。
%scala
df.select(map(col("Description"), col("InvoiceNo")).alias("complex_map"))
.selectExpr("explode(complex_map)")
.show(2)
%python
df.select(map(col("Description"), col("InvoiceNo")).alias("complex_map"))\
.selectExpr("explode(complex_map)")\
.show(2)
>>>
+--------------------+------+
| key| value|
+--------------------+------+
|WHITE HANGING HEA...|536365|
| WHITE METAL LANTERN|536365|
+--------------------+------+
使用 JSON 数据
Spark 对JSON数据有一些特别的支持。你可以在Spark中直接操作JSON字符串 并 从JSON中解析 或提取JSON对象。让我们从创建一个JSON列开始。
%scala
val jsonDF = spark.range(1)
.selectExpr("""
‘{"myJSONKey" : {"myJSONValue" : [1, 2, 3]}}’ as jsonString
""")
%python
jsonDF = spark.range(1)\
.selectExpr("""
‘{"myJSONKey" : {"myJSONValue" : [1, 2, 3]}}’ as jsonString
""")
我们可以使用get_json_object内联查询一个JSON对象,使其称为一个 字典 或 数组。
可以使用json_tuple,如果对象只有一级嵌套。
%scala
import org.apache.spark.sql.functions.{get_json_object, json_tuple}
jsonDF.select(
get_json_object(col("jsonString"), "$.myJSONKey.myJSONValue[1]"),
json_tuple(col("jsonString"), "myJSONKey"))
.show(2)
%python
from pyspark.sql.functions import get_json_object, json_tuple
jsonDF.select(
get_json_object(col("jsonString"), "$.myJSONKey.myJSONValue[1]"),
json_tuple(col("jsonString"), "myJSONKey"))\
.show(2)
在SQL中等价于
jsonDF.selectExpr("json_tuple(jsonString, ‘$.myJSONKey.myJSONValue[1]’) as res")
>>>
+------+--------------------+
|column| c0|
+------+--------------------+
| 2|{"myJSONValue":[1...|
+------+--------------------+
我们还可以使用to_json函数 将一个StrucType转换为一个JSON字符串。
%scala
import org.apache.spark.sql.functions.to_json
df.selectExpr("(InvoiceNo, Description) as myStruct")
.select(to_json(col("myStruct")))
%python
from pyspark.sql.functions import to_json
df.selectExpr("(InvoiceNo, Description) as myStruct")\
.select(to_json(col("myStruct")))
to_json函数 也可以接受一个 与JSON数据源相同的 参数字典(或 map)。
我们可以使用from_json函数将其(或其他json)解析回来。这自然需要我们指定一个schema,还可以选择指定选项的映射。
%scala
import org.apache.spark.sql.functions.from_json
import org.apache.spark.sql.types._
val parseSchema = new StructType(Array(
new StructField("InvoiceNo",StringType,true),
new StructField("Description",StringType,true)))
df.selectExpr("(InvoiceNo, Description) as myStruct")
.select(to_json(col("myStruct")).alias("newJSON"))
.select(from_json(col("newJSON"), parseSchema), col("newJSON"))
%python
from pyspark.sql.functions import from_json
from pyspark.sql.types import *
parseSchema = StructType((
StructField("InvoiceNo",StringType(),True),
StructField("Description",StringType(),True)))
df.selectExpr("(InvoiceNo, Description) as myStruct")\
.select(to_json(col("myStruct")).alias("newJSON"))\
.select(from_json(col("newJSON"), parseSchema), col("newJSON"))\
>>>
+----------------------+--------------------+
|jsontostructs(newJSON)| newJSON|
+----------------------+--------------------+
| [536365,WHITE HAN...|{"InvoiceNo":"536...|
| [536365,WHITE MET...|{"InvoiceNo":"536...|
+----------------------+--------------------+
自定义函数
Spark最强大的功能之一 是你可以在Spark 中定义你自己的函数。这允许你使用Python 或 Scala编写自定义的转换,甚至利用外部库如numpy来实现这一点。
这些函数被叫做UDFs,可以接受 和返回 一个或多个列。
Spark UDFs 难以置信地强大,因为他们可以用多种不同的编程语言来编写,而且不必须以一种难懂的格式 或 DSL 来进行编写。他们只是作用在数据上的函数,一条记录接着一条记录。
默认地,这些函数被注册为临时函数,使用在特定的SparkSession 或 Context中。
虽然我们可以用Scala、Python或Java编写函数,但是您应该注意一些性能方面的考虑。为了说明这点,我们会详细介绍 创建UDF是会发生什么,将其传入Spark,然后使用该UDF执行代码。
第一步是 实现函数,这里举一个简单的例子。编写一个power3函数,接受一个数,并取其3次幂。
%scala
val udfExampleDF = spark.range(5).toDF("num")
def power3(number:Double):Double = {
number * number * number
}
power3(2.0)
%python
udfExampleDF = spark.range(5).toDF("num")
def power3(double_value):
return double_value ** 3
power3(2.0)
在这个例子中,我们可以看到函数像预期的那样 工作。
现在我们创建这些函数并测试他们,我们需要在Spark中注册他们,让我们可以在我们所有的 工作机器上使用他们。Spark会在driver上序列化函数,并通过网络将它们传递给所有的executor进程。不管使用什么语言。
一旦我们使用函数,本质上有两种不同的情况。
如果函数是使用Scala或Java来编写的,我们可以在JVM中使用函数。这意味着除了我们不能利用Spark为内置函数提供的代码生成功能之外, 几乎不会有性能损失。如果你创建或使用了很多对象,可能会有性能问题,我们会在优化长些进行介绍。
如果函数使用Python编写,会发生一些完全不同的事情。Spark会在工作节点 启动 一个python进程,将所有数据序列化为python能理解的格式(请记住,它以前是在JVM中)。在python进程中会一行一行地在数据上执行函数,最后返回行操作的结果到JVM和Spark。
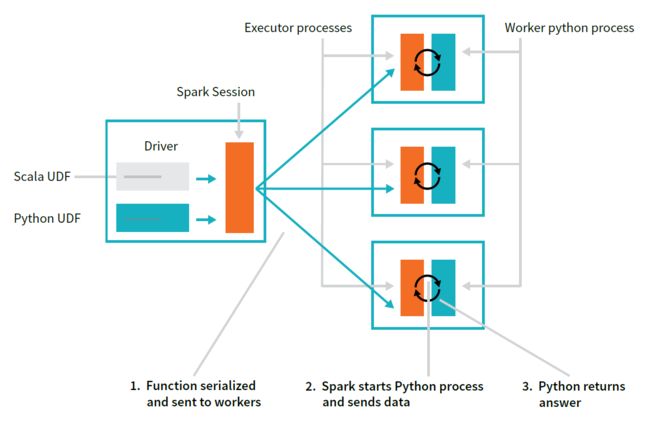
启动这个Python进程代价很高,但真正的成本是在为Python序列化数据上。有两个原因使其代价昂贵,这是一个代价高昂的计算,且一旦数据进入Python,Spark就不能管理工作节点的内存。
这意味着,如果一个工作节点的资源受限(因为JVM和python在同一台机器上竞争资源),其就有失败的潜在可能。我们建议你使用Scala编写UDFs——在编写函数上花费的少量时间往往会显著提升速度,而且最重要的是,用Scala编写时你仍然可以使用Python中的函数。
首先需要注册这个函数,来使其可以作为一个DataFrame函数。
%scala
import org.apache.spark.sql.functions.udf
val power3udf = udf(power3(_:Double):Double)
接下来,我们想使用其他DataFrame一样来使用它。
%scala
udfExampleDF.select(power3udf(col("num"))).show()
上述情况也是用与Python,我们首先注册它:
%python
from pyspark.sql.functions import udf
power3udf = udf(power3)
接下来我们在DataFrame代码中使用它
%python
from pyspark.sql.functions import col
udfExampleDF.select(power3udf(col("num"))).show()
>>>
+-----------+
|power3(num)|
+-----------+
| 0|
| 1|
+-----------+
到目前为止,我们只能用其作为DataFrame函数。这就是说,我们不能在字符串表达式中使用它。然而,我们可以注册一个UDF为SparkSQL函数。这很有意义,因为这使得在SQL内部 及跨语言 使用这个函数变得非常容易。
我们用Scala语言注册函数。
%scala
spark.udf.register("power3", power3(_:Double):Double)
udfExampleDF.selectExpr("power3(num)").show(2)
因为该函数已用SparkSQL注册,并且我们已经了解到,在处理DataFrames时,任何SparkSQL或表达式都可以作为转换表达式有效地使用,我们可以转而 在Python中 使用用Scala编写的UDF。但是我们将其用作SQL表达式,而不是一个DataFrame函数。
%python
udfExampleDF.selectExpr("power3(num)").show(2)
# registered in Scala
我们同样可以将Python函数注册为SQL函数,并同样地用在任何其他语言中。
为了确保函数正常运行,我们还可以指定函数的返回类型。正如我们在本节开头所看到的的,Spark管理自己的类型信息,这些信息与Python的类型 不完全一致。因此在定义函数时指定返回类型是一钟最佳实践。值得注意的是,指定返回类型不是必须的,但是最佳的做法。
如果你指定类型 与函数实际返回的类型不匹配,Spark不会报错而是只返回null来指明一个错误。你会看到这个现象,如果将下面函数的返回类型设置为DoubleType。
%python
from pyspark.sql.types import IntegerType, DoubleType
spark.udf.register("power3py", power3, DoubleType())
%python
udfExampleDF.selectExpr("power3py(num)").show(2)
# registered via Python
这是因为上面的udfExampleDF创建的是整型。当整型在Python进行操作时,Python不会将它们装换为floats(相当于Spark中的Double type),因此我们会看到null。我们可以通过保证Python函数返回一个float来进行补救,而后函数会正常运行。
注册后的函数,也可以在SQL中使用。
%sql
SELECT
power3py(12), -- doesn’t work because of return type
power3(12)
当你想要从UDF中选择性地返回一个值时,您应该在python中返回None,在Scala中返回一个选项类型。
- Hive UDFs
最后一点,用户还可以使用 由Hive语法创建的UDF/UDAF。考虑到这一点,当它们创建SparkSession时,您必须启用Hive支持(通过 SparkSession.builder( ).enableHiveSupport( )),然后你可以在SQL中注册UDFs。这只支持预编译的Scala和Java包,因此必须将它们指定为依赖项。
CREATE TEMPORARY FUNCTION myFunc AS ‘com.organization.hive.udf.FunctionName’
此外,你可以通过移除‘TEMPORARY’将其注册为Hive Metestore中的一个永久函数。