【机器学习】人工智能实验:SVM分类器人脸识别(sklearn、python读图片、GridSearchCV简单应用)
一、实验基本情况介绍
1、数据集介绍
选取 ORL 人脸数据库作为实验样本,总共 40 个人,每人 10 幅图像,图像大小为112*92 像素。图像本身已经经过处理,不需要进行归一化和校准等工作。实验样本分为训练样本和测试样本。首先设置训练样本集,选择 40 个人前 5 张图片作为训练样本,进行训练。然后设置测试样本集,将 40 个人后 5 张图片作为测试样本,进行选取识别。

数据与源代码百度网盘链接
提取码:kqg2
2、人脸识别算法步骤概述:
(本博客不是按照下述matlab方法实现的!)
(对应matlab文件在网盘中有)
a) 读取训练数据集;
若 flag=0,表述读取原文件的前五幅图作为训练数据,若 flag=1,表述读取原文件的后五幅图作为测试数据,数据存入 f_matrix 中,每一行为一个文件,每行为 112*92 列。参见:ReadFace.m
b) 主成分分析法降维并去除数据之间的相关性;参见:fastPCA.m
c) 数据规格化;参见 scaling.m
d) SVM 训练(选取径向基和函数)得到分类函数;参见multiSVMtrain.m e) 读取测试数据、降维、规格化;参见:multiSVM.m
f) 用步骤 d 产生的分类函数进行分类(多分类问题,采用一对一投票策略,归位得票最多的一类);参见:main.m
g) 计算正确率。
2、实验要求(要求什么的只是个参考)
1) 分别使用 PCA 降维到 20,50,100,200,然后训练分类器,对比分类结果,画出对比曲线;
2) 变换 SVM 的 kernel 函数,如分别使用径向基函数和多项式核函数训练分类器,对比分类结果,画出对比曲线;
3) 使用交叉验证方法,变换训练集及测试集,分析分类结果。
二、实验过程记录与分析
1、对比不同核函数和不同降维维度训练结果准确性的差异
(1)内容介绍
采用题目中所要求的降维到 20,50,100,200,分别使用径向基函数和多项式核函数训练分类器得到实验结果,SVM分类算法通过调用sklearn库中相关函数实现,具体代码实现请参考python源代码相关附件内容。
本小结代码可参考python源文件“正式实验2:对比不同核函数训练结果准确性的差异.py”(下面代码部分2)
(2)实验结果
图1:降维到 20,50,100,200
图2:每间隔5维取一个数

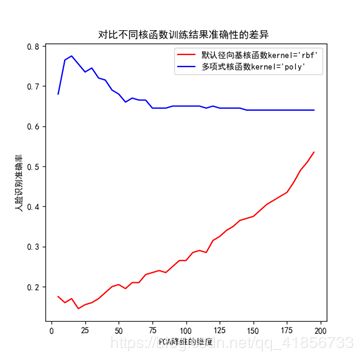
(3)实验结果分析
可见,径向基函数大体呈现随着所降维度的增加而准确率不断上升的趋势;而多项式核函数大约在降维为20左右达到准确率的高峰,之后随着所降维度的增加,而准确率对应下降,最后趋于平缓。
2、对比四种核函数之间降维影响的差异
(1)分析
题目要求中是对比两种核函数的差异,据查资料了解,常见的核函数有线性核函数、径向基核函数、多项式核函数4种,这里很自然的想到,对比一下这4种常见核函数之间的差异。这里采用“交叉验证法”计算正确率,采用的维度间隔3,5,10,20,50,100,200。
本小节代码可参考python源文件“正式实验3:对比四个核函数在不同降维情况下的准确度(采用交叉验证).py”(下面代码部分3)
(2)对比实验结果

(3)实验结果分析
如图可见,线性核函数“linear”和多项式核函数“ploy”在所降维维度从低到高的过程中快速增加,在降维为20维度左右的时候就达到一个不错的准确度了。SVM分类器采用线性核函数“linear”不论所降维度为低维度还是高纬度效果都很好,在四种核函数中效果最好。而采用“sigmoid”核函数在本题应用中的效果很差。
3、附加实验:关于先标准化还是先降维的对比实验
本小节实验可参考:基于SVM人脸识别算法的一些对比探究(先降维好还是先标准化好等对比分析)
(1)问题思考
在进行分类实验的数据处理过程,往往都是需要对数据进行标准化和降维的,那么这里我们就产生了一个疑惑:到底是先降维好,还是先标准化好呢?本实验采用两种核函数,在不同降维情况下计算其准确度的方式,具体代码可参考python源代码“附加实验1.2:关于先降维还是先标准化的测试(多项式核函数)”和“附加实验1.1:关于先降维还是先标准化的测试(径向基核函数)”
(2)实验结果

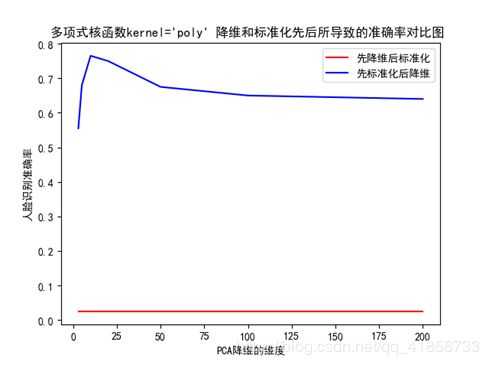
(3)结论与分析
由此可知,确实是先标准化再降维效果更好!
PCA通常是用于高维数据的降维,它可以将原来高维的数据投影到某个低维的空间上并使得其方差尽量大。如果数据其中某一特征(矩阵的某一列)的数值特别大,那么它在整个误差计算的比重上就很大,那么可以想象在投影到低维空间之后,为了使低秩分解逼近原数据,整个投影会去努力逼近最大的那一个特征,而忽略数值比较小的特征。因为在建模前我们并不知道每个特征的重要性,这很可能导致了大量的信息缺失。此外,因为PCA通常是数值近似分解,而非求特征值、奇异值得到解析解,所以当我们使用梯度下降等算法进行PCA的时候,最好先要对数据进行标准化,这有利于梯度下降法的收敛。
因此,一般情况下,先降维再标准化的效果很更好!
4、附加实验:结合GridSearchCV网格化搜索尝试探究本题最优模型
(1)实验描述
结合第二部分的探究实验,我们初步可知采用“linear”线性核函数构造的SVM模型效果最好,对此我们将进行通过GridSearchCV网格化搜索函数进行验证,并尝试构造出最优模型。
这里先采用的方法是间隔五个维度输出结果,确定好高正确率的大致范围,再采用遍历每个维度的方式,找到最高准确率的维度。(这里在进行网格化搜索时已经知道线性核函数的最优降维维度了。)
本小节实现可参考代码“附加实验3.1:使用GridSearchCV调参练习.py”(下面代码部分4)和“附加实验3.3:使用GridSearchCV调参练习(PCA所降维按维度找最优所降维维度).py”
(2)测试结果
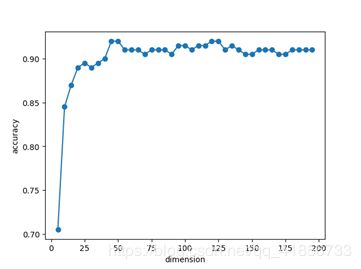

(3)分析与感想
在本小结的实验探究中,考虑到本题SVM分类器实际需要调节的参数并不多,所以这里只是发挥了网格化搜索的一小部分功能。虽说寻找到最优降维维度主要还是单纯的手动遍历实现的,但网格化搜索确实在调参中发挥着很大的作用。
通过本小节的实验,我们可以知道,在本题中最优的降维维度是46维,准确率可达到0.92。可见,SVM分类器在人脸识别的应用上通过一定的优化,确实可以达到一个满意的结果,不失为一种好办法!
三、主要代码
因为网盘里有,所以这里记录一些比较关键且典型的部分:
1、正式实验:SVM实现人脸识别,并输出测试集预测结果的正确率
import cv2 #opencv库,用于读取图片等操作
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler #标准差标准化
from sklearn.svm import SVC #svm包中SVC用于分类
from sklearn.decomposition import PCA #特征分解模块的PCA用于降维
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签
if __name__ == '__main__':
#1、获取数据
face_data_train,face_target_train=get_data(1,6) #读取前五张图片为训练集
face_data_test,face_target_test=get_data(6,11) #读取后五张图片为测试集
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
#stdScaler = StandardScaler().fit(face_data_test)
face_testStd = stdScaler.transform(face_data_test)
#3、PCA降维
pca = PCA(n_components=20).fit(face_trainStd)
face_trainStd = pca.transform(face_trainStd)
face_testStd = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
#svm = SVC().fit(face_trainStd,face_target_train)
svm = SVC(kernel='poly').fit(face_trainStd,face_target_train)
print('建立的SVM模型为:\n',svm)
#4、预测训练集结果
face_target_pred = svm.predict(face_testStd)
print('预测前10个结果为:\n',face_target_pred[:10])
face_target_test=face_target_test.values #Dataframe转ndarray方便后面准确率的判断
true=0
## 求出预测和真实一样的数目
#true = np.sum(face_target_pred == face_target_test )
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true=true+1
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', face_target_test.shape[0]-true)
print('预测结果准确率为:', true/face_target_test.shape[0])

2、正式实验2:对比不同核函数训练结果准确性的差异
(这个代码写的有些冗长了,实际上两种不同核函数情况没必要写两遍)
import cv2 #opencv库,用于读取图片等操作
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler #标准差标准化
from sklearn.svm import SVC #svm包中SVC用于分类
from sklearn.decomposition import PCA #特征分解模块的PCA用于降维
import matplotlib.pyplot as plt #用于绘制图形
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签
def draw_chart(dimension,accuracy):
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(6,6))
plt.plot(dimension,accuracy,"r-")
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('对比不同核函数训练结果准确性的差异 ')
#plt.savefig("./tmp/采用默认径向基核函数kernel=\'rbf\' 先降维后标准化.png")
#plt.show()
def face_fuc(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
#dimension=[3,5,10,20,50,100,200]
dimension=[20,50,100,200]
'''
dimension=[]
for i in range(1,40):
dimension.append(i*5)
'''
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
svm = SVC(kernel='linear').fit(face_trainPca,face_target_train)
#svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
draw_chart(dimension,accuracy)
def face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
#dimension=[3,5,10,20,50,100,200]
dimension=[20,50,100,200]
'''
dimension=[]
for i in range(1,40):
dimension.append(i*5)
'''
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
#svm = SVC().fit(face_trainPca,face_target_train)
svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
plt.plot(dimension,accuracy,"b-")
plt.legend(['默认径向基核函数kernel=\'rbf\'','多项式核函数kernel=\'poly\''])
#draw_chart1(dimension,accuracy)
if __name__ == '__main__':
#1、获取数据
face_data_train,face_target_train=get_data(1,6) #读取前五张图片为训练集
face_data_test,face_target_test=get_data(6,11) #读取后五张图片为测试集
face_target_test=face_target_test.values #将DataFrame类型转成ndarrayl类型
face_fuc(face_data_train,face_target_train,face_data_test,face_target_test)
face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test)

3、正式实验3:对比四个核函数在不同降维情况下的准确度(采用交叉验证)
(相比于上面那个代码,这个代码就稍微简洁了些)
import cv2 #opencv库,用于读取图片等操作
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler #标准差标准化
from sklearn.model_selection import cross_val_score #用于交叉验证
from sklearn.svm import SVC #svm包中SVC用于分类
from sklearn.decomposition import PCA #特征分解模块的PCA用于降维
import matplotlib.pyplot as plt #用于绘制图形
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签
def face_fuc(face_data_train,face_target_train,k,c):
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
dimension=[3,5,10,20,50,100,200]
#dimension=[20,50,100,200]
'''
dimension=[]
for i in range(1,40):
dimension.append(i*5)
'''
accuracy=[]
for i in dimension:
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
#默认为径向基核函数kernel='rbf' 多项式核函数'poly' 线性核函数'linear' sigmoid核函数
svm = SVC(kernel=k)
scores = cross_val_score(svm,face_trainPca,face_target_train,cv=3)
print(scores)
accuracy.append(scores.mean())
print(accuracy)
plt.plot(dimension,accuracy,c)
if __name__ == '__main__':
face_data_train,face_target_train=get_data(1,11) #读取所有图片
kernel= [ 'poly','linear', 'rbf', 'sigmoid' ]
color=['r','y','b','g']
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(6,6))
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('对比不同核函数训练结果准确性的差异 ')
for i in range(0,4):
face_fuc(face_data_train,face_target_train,kernel[i],color[i])
plt.legend(['poly','linear', 'rbf', 'sigmoid'])

4、附加实验3.1:使用GridSearchCV调参练习
初学了点GridSearchCV调参的皮毛,在这里稍微记录一下:
import cv2 #opencv库,用于读取图片等操作
from time import time
import numpy as np
import pandas as pd
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler #标准差标准化
import matplotlib.pyplot as plt
from sklearn.svm import SVC #svm包中SVC用于分类
from sklearn.decomposition import PCA #特征分解模块的PCA用于降维
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签
if __name__ == '__main__':
#1、获取数据
face_data_train,face_target_train=get_data(1,6) #读取前五张图片为训练集
face_data_test,face_target_test=get_data(6,11) #读取后五张图片为测试集
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
#stdScaler = StandardScaler().fit(face_data_test)
face_testStd = stdScaler.transform(face_data_test)
#3、PCA降维
'''#测试结果表明:网格化搜索不能用于PCA降维维度最优值选择
dimension=[]
for i in range(1,40):
dimension.append(i*5)
pcag= GridSearchCV(estimator=PCA(), param_grid={ 'n_components': [5,20,100]})
pca = pcag.fit(face_trainStd)
print("pca.best_params_ ",pca.best_params_)
'''
pca = PCA(n_components=46).fit(face_trainStd)
face_trainStd = pca.transform(face_trainStd)
face_testStd = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 这里为多项式核函数kernel='poly'
#clf_svc = GridSearchCV(estimator=SVC(), param_grid={ 'C': [1, 2, 4, 5], 'kernel': [ 'linear', 'rbf', 'sigmoid' ] }, cv=5, verbose=2 )
clf_svc = GridSearchCV(estimator=SVC(), param_grid={ 'C': [1, 2, 3,10], 'kernel': [ 'poly','linear', 'rbf', 'sigmoid' ] }, cv=3 )
svm = clf_svc.fit(face_trainStd,face_target_train)
print("clf_svc.best_params_ ",clf_svc.best_params_)
#svm = SVC(kernel='poly').fit(face_trainStd,face_target_train)
print('建立的SVM模型为:\n',svm)
#4、预测训练集结果
face_target_pred = svm.predict(face_testStd)
#print('预测前10个结果为:\n',face_target_pred[:10])
face_target_test=face_target_test.values #Dataframe转ndarray方便后面准确率的判断
true=0
## 求出预测和真实一样的数目
#true = np.sum(face_target_pred == face_target_test )
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true=true+1
print('预测对的结果数目为:', true)
print('预测错的的结果数目为:', face_target_test.shape[0]-true)
print('预测结果准确率为:', true/face_target_test.shape[0])
