笔记合集 爬虫基础系列 临近结束 课件直接合一起 方便自己寻找 有空再整理
day01
一、爬虫的定义:程序或者脚本---》自动的爬取万维网的数据的程序或者脚本。
二、爬虫可以解决的问题:
(1)解决冷启动问题。
(2)搜索引擎的根基。---通用爬虫。
(3)帮助机器学习建立知识图谱。
(4)制作各种比价软件。
三、爬虫工程师的进阶之路:
初级爬虫工程师
1.web 前端的知识: HTML、CSS、JavaSc1ipt、 DOM、 DHTML 、Ajax、jQuery、json 等;
2、正则表达式, 能提取正常一般网页中想要的信息,比如某些特殊的文字, 链接信息, 知道什么是懒惰, 什么是贪婪型的正则;
3、会使用 XPath 等获取一些DOM 结构中的节点信息;
4、知道什么是深度优先, 广度优先的抓取算法, 及实践中的使用规则;
5、能分析简单网站的结构, 会使用urllib或requests 库进行简单的数据抓取。
中级爬虫工程师:
1、了解什么事HASH,会简单地使用MD5,SHA1等算法对数据进行HASH一遍存储
2、熟悉HTTP,HTTPS协议的基础知识,了解GET,POST方法,了解HTTP头中的信息,包括返回状态码,编码,user-agent,cookie,session等
3、能设置user-agent进行数据爬取,设置代理等
4、知道什么事Request,什么事response,会使用Fiddler等工具抓取及分析简单地网络数据包;对于动态爬虫,要学会分析ajax请求,模拟制造post数据包请求,抓取客户端session等信息,对于一些简单的网站,能够通过模拟数据包进行自动登录。
5、对于一些难搞定的网站学会使用phantomjs+selenium抓取一些动态网页信息
6、并发下载,通过并行下载加速数据爬取;多线程的使用。
高级爬虫工程师:
1、能够使用Tesseract,百度AI,HOG+SVM,CNN等库进行验证码识别。
2、能使用数据挖掘技术,分类算法等避免死链。
3、会使用常用的数据库进行数据存储,查询。比如mongoDB,redis;学习如何通过缓存避免重复下载的问题。
4、能够使用机器学习的技术动态调整爬虫的爬取策略,从而避免被禁IP封禁等。
5、能使用一些开源框架scrapy,scrapy-redis等分布式爬虫,能部署掌控分布式爬虫进行大规模数据爬取。
四、搜索引擎
1、什么是搜索引擎:
搜索引擎通过特定算法,从互联网上获取网页信息,将其保存到本地,为用户提供检索服务的一种程序。
2、搜索引擎的组成:搜索引擎主要是是由通用爬虫组成的。
(1)通用爬虫:将互联网上的网页信息【整体】爬取下来的爬虫程序。
(2)搜索引擎的工作步骤:
1、抓取网页
2、数据存储
3、预处理
提取文字
中文分词
消除噪音
。。。
4、设置网站排名(访问量),为用户提供检索服务。
(3)为什么搜索引擎可以爬取所有的网页?---搜索引擎的通用是如何来爬取所有网页的。
一个网页就是一个url,这个问题其实在问,【url的获取来源】。
url的获取来源:
1、新网站会主动提交网址给搜索引擎。
2、网页中的一些外链,这些url全部都会加入到通用爬虫的爬取队列。
3、搜索引擎和dns解析服务商合作,如果有新网站注册,搜索引擎就可拿到网址。
3、通用爬虫的缺陷:
(1)通用爬虫是爬取整个网页,但是网页中90%的内容基本是没用。
(2)不能满足不同行业,不同人员的不同需求。
(3)只能获取文字,不能获取音频,视频,文档等信息。
(4)只能通过关键字查询,无法通过语义查询。
4、聚焦爬虫:在实施网页抓取的过程中,【会对内容进行筛选】,尽量保证只抓取与【需求相关】的信息的爬虫程序。
五、robots协议:
定义:网络爬虫排除标准
作用:告诉搜索引擎那些可以爬那些不能爬。
六、http协议
1、什么是http协议:
是一种规范——————>约束发布和接受html的规范。
2、http和https。
http:超文本传输协议。
https:安全版的http协议。---ssl---
对称加密---密钥
非对称---私钥+公钥
数字签证---
3、https:443
http:80
Upgrade-Insecure-Requests: 1:可以将http升级成https请求。
4、http的特点:
(1)应用层协议。
(2)无连接:http每次发送请求和响应的过程都是独立。
在http 1.0以后,有请求头:connection:keep-alive:客户端和服务建立长连接。
(3)无状态:http协议不记录状态。
cookie和session做到请求状态的记录。
cookie是在客户端保存,session是在服务器保存。
5、url:统一资源定位符。
(1)主要作用:用来定位互联网上的任意资源的位置。
(2)为什么url可以定位任意资源?
组成:https://www.baidu.com/index.html?username=123&password=abc#top
scheme:协议---https
netloc:网络地址:ip:port---www.baidu.com
通过ip定位电脑,通过port定位应用。
192.168.92.10:
代理ip:ip:port
path:资源路径。---index.html
query:请求参数:---?后面的内容username=123&password=abc
fragment:锚点----top
原因:url包含netloc可以定位电脑,path定位资源,这样就可以找到任意在互联网上的信息。
(3)特殊符号:
?:后面就是请求参数
&:连接请求参数
#:锚点----如果url中有锚点,在爬虫程序中尽量去除。
6、 http的工作过程:
(1)地址解析:
将url的所有组成部分分别解析出来。
(2)封装http请求数据包。
将第一步解析出来的信息进行装包。---http数据包。
(3)封装tcp数据包,通过三次握手建立tcp。
(4)客户端发送请求
(5)服务发送响应
(6)关闭tcp连接。
7、当我们在浏览器输入一个url,浏览器加载出这个页面,中间做了哪些事?
(1)客户端解析url,封装数据包,建立连接,发送请求。
(2)服务器返回url对应资源文件给客户端,比如:index.html。
(3)客户端检查index.html是否有静态资源(引用外部文件),比如js,css,图片。有的话再分别发送请求,来获取这些静态资源。
(4)客户端获取所有静态资源,通过html语法,完全将index.html页面显示出来。
8、 http的请求方法:
get请求:get(获取)-->获取服务器的指定资源--->涉及到筛选一些信息--->请求参数:主要拼接在url中。--->不安全(别人可以通过url获取信息)--->请求参数的大小受限。
post请求:post(邮递)--->向服务器传递数据--->请求数据是放在请求实体中的--->安全--->大小不受限。
9、客户端请求
(1)组成:请求行、请求头、空行、请求数据(实体)
请求头:请求方法;host地址,http协议版本。
(2)请求头:
user-agent:客户端标识。
accept:允许传入的文件类型。
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Referer:标识产生请求的网页来自于哪个网页。
防盗链
cookie:cookie信息。---现在很多网站,必须封装cookie才给数据。
post请求重要的请求头:
content-type:post请求的数据类型
content-length:post请求数据的长度。
ajax请求必须封装的头:
x-requested-with:xmlhttprequest
10、服务器响应:
(1)组成:状态行、响应头、空行、响应正文。
(2)响应头:
Content-Type:text/html;charset=UTF-8
(3)状态码(面试常考):
1XX:表示服务器成功接收部分请求,还需要发剩余请求才能处理整个过程。(处理了一半)
2XX:表示服务器成功接收请求并处理完整个过程。(成功)
200成功
3XX:为了完成请求,客户端需要进一步细化请求。
302:重定向
304:使用缓存资源
4XX:客户端请求错误。(url写错了)
404:服务器无法找到请求内容。
403:服务器拒绝访问,权限不够。
5XX:服务器错误。
502:服务器错误
500:请求未完成,服务器遇到不可知问题。
-----------------------------------------------------------------------
1.笔记
2.
用【递归】的方法实现斐波那契数列。
1,1,2,3,5,8,13.。。。
用【递归】的方法获取一个list的最大值和最小值,return(最大值,最小值)
day02
1、斐波那契数列:
def F(n):
if n==1 or n==2:
return 1
return F(n-1)+F(n-2)
2、
def max_min(L,start,end):
if end-start <=1:
return (max(L[start],L[end]),min(L[start],L[end]))
max1,min1 = max_min(L,start,(start+end)//2)
max2,min2 = max_min(L,(start+end)//2+1,end)
return (max(max1,max2),min(min1,min2))
==================================================================================
第二讲requests模块
文档:从 pythoneer 到 pythonista 的100个模...
链接:http://note.youdao.com/noteshare?id=2b95bb3651c21af80ca1936f8ecb1e0f&sub=635CA99241664308947C4F3BC1B5DDBF
1、使用步骤:
#1.导包
import requests
#2、确定基础url
base_url = 'https://www.baidu.com'
#3、发送请求,获取响应
response = requests.get(base_url)
#4、处理响应内容
2、requests.get()---get请求方法参数详解
(1)requests.get(
url=请求url,
headers =请求头字典,
params = 请求参数字典。
timeout = 超时时长,
)---->response对象
(2)response对象的属性:
服务器响应包含:状态行(协议,状态码)、响应头,空行,响应正文
(1)响应正文:
字符串格式:response.text
bytes类型:response.content
(2)状态码:response.status_code
(3)响应头:response.headers(字典)
response.headers['cookie']
(4)响应正文的编码:response.encoding
response.text获取到的字符串类型的响应正文,其实是通过下面的步骤获取的:
response.text = response.content.decode(response.encoding)
(5)乱码问题的解决办法:
产生的原因:编码和解码的编码格式不一致造成的。
str.encode('编码')---将字符串按指定编码解码成bytes类型
bytes.decode('编码')---将bytes类型按指定编码编码成字符串。
a、response.content.decode('页面正确的编码格式')
<meta http-equiv="content-type" content="text/html;charset=utf-8">
b、找到正确的编码,设置到response.encoding中
response.encoding = 正确的编码
response.text--->正确的页面内容。
(3)get请求项目总结:
a、没有请求参数的情况下,只需要确定url和headers字典。
b、get请求是有请求参数。
在chrome浏览器中,下面找query_string_params,将里面的参数封装到params字典中。
c、分页主要是查看每页中,请求参数页码字段的变化,找到变化规律,用for循环就可以做到分页。
3、post请求:
requests.post(
url=请求url,
headers = 请求头字典,
data=请求数据字典
timeout=超时时长
)---response对象
post请求一般返回数据都是json数据。
#解析json数据的方法:
(1)response.json()--->json字符串所对应的python的list或者dict
(2)用json模块。
json.loads(json_str)---->json_data(python的list或者dict)
json.dumps(json_data)--->json_str
post请求能否成功,关键看请求参数。
如何查找是哪个请求参数在影响数据获取?--->通过对比,找到变化的参数。
变化参数如何找到参数的生成方式,就是解决这个ajax请求数据获取的途径。
寻找的办法有以下几种:
(1)写死在页面。
(2)写在js中。
(3)请求参数是在之前的一条ajax请求的数据里面提前获取好的。
4、代理使用方法 。
(1)代理基本原理:
代理形象的说,他是网络信息中转站。实际上就是在本机和服务器之间架了一座桥。
(2)代理的作用:
a、突破自身ip访问限制,可以访问一些平时访问不到网站。
b、访问一些单位或者团体的资源。
c、提高访问速度。代理的服务器主要作用就是中转,所以一般代理服务里面都是用内存来进行数据存储的。
d、隐藏ip。
(3)代理的分类:
1、按照协议进行划分:
FTP代理服务器---21,2121
HTTP代理服务器---80,8080
SSL/TLS代理:主要用访问加密网站。端口:443
telnet代理 :主要用telnet远程控制,端口一般为23
2、按照匿名程度:
高度匿名代理:数据包会原封不动转化,在服务段看来,就好像一个普通用户在访问,做到完全隐藏ip。
普通匿名代理:数据包会做一些改动,服务器有可能找到原ip。
透明代理:不但改动数据,还会告诉服务,是谁访问的。
间谍代理:指组织或者个人用于记录用户传输数据,然后进行研究,监控等目的的代理。
(4)在requests模块中如何设置代理?
proxies = {
'代理服务器的类型':'代理ip'
}
response = requests.get(proxies = proxies)
代理服务器的类型:http,https,ftp
代理ip:http://ip:port
作业:
1.股吧信息爬取:
url:http://guba.eastmoney.com/
要求:
1、爬取10页内容,保存到guba文件夹下
2、金山词霸:http://www.iciba.com/
做到和有道相似想过。
day03
一、cookie和session
1、什么是cookie?
cookie是指网站为了鉴别用户身份,进行会话跟踪而存储在客户端本地的数据。
2、什么是session?
本来的含义是指有始有终的一些列动作,而在web中,session对象用来在服务器存储特定用户会话所需要的属性及信息。
3、cookie和session产生的原因:
cookie和session他们不属于http协议范围,由于http协议是无法保持状态,但实际情况,我们有需压保持一些信息,作为下次请求的条件,所有就产生了cookie和session。
4、cookie的原理:
由服务器产生,当浏览器第一次登录,发送请求到服务器,服务器返回数据,同时生成一个cookie返回给客户端,客户端将这个cookie保存下来。
当浏览器再次访问,浏览器就会自动带上cookie信息,这样服务器就能通过cookie判断是哪个用户在操作。
cookie的缺陷:
1、不安全--保存在客户端。
2、cookie本身最大支持4096(4kb)---存储大小受限。
5、session的工作原理。
正是因为cookie的缺陷,所有产生了另外一种保持状态的方法---session。
服务器存储session,基于http协议的无状态特征,所以服务器就不知道这个访问者是谁。为了解决这个问题,cookie就起到了桥的作用。cookie在使用的过程中,将一个叫做sessionid的字段放到cookie中,将来服务器可以通过这个id字段来查找到底是那个用户的session。
session的生命周期:当用户第一次登陆时创建(生命开始),到session有效期结束(30min)。
6、当我们浏览器关闭,session是否就失效了?
不失效,原因,session失效使用生命周期决定的。
7、cookie组成:
name:cookie名称,一旦创建,不可更改。
value:该cookie的值
domain:者cookie可以访问网站域名。
maxage:cookie的失效时间。负数是永不失效。
path:这个使用路径
http字段:cookie的httponly,若次属性为true,则只有http头中会带此cookie。
secrue:该cookie是否仅被使用安全传输协议。
size:cookie的大小
8、会话cookie和持久cookie。
持久化:将内存中的数据存储到硬盘(文件中,数据库)上的过程。
序列化:将对象保存到硬盘上。
会话cookie:保存在内存中cookie,浏览器关闭,cookie失效。
持久cookie:保存在硬盘上的cookie。
9、用requests实现登陆:
(1)只需要将【登陆后的】cookie字段封装在请求头中。
(2)使用requests的session对象登陆
session对象可以记录登陆状态。
使用步骤:
#session:记录登陆状态
se = requests.Session()
data = {
'email':'13016031459',
'password':'12345678',
}
#此时se对象就保存了登陆信息
se.post(base_url,data = data,headers = headers)
------------------------------------------
index_url = 'http://www.renren.com/971682585/profile'
#用se对象来进行个人首页的访问,就可以了
response = se.get(index_url,headers=headers)
if '鸣人' in response.text:
print('登陆成功!')
else:
print('登陆失败!')
===================================================================================
第三讲 正则表达式
一、数据的分类
1、结构化数据
特点:数据以行为单位,每一个数据表示一个实体。每一行数据的属性都是一样的。
举例:关系型数据库中的表就是结构化数据。
处理方法:sql
2、半结构化数据
特点:结构化数据的另一种形式。他并不符合关系型数据的特点,不能用关系型模型来描述。但是这种数据包含相关标记,有用来分割语义元素以及字段进行分层的描述。
因此也被称为自描述结构。
举例:xml,html,json,非关系型数据库存储的数据。
处理方法:正则,xpath,jsonpath,css选择器。
3、非结构化数据:
特点:没有固定结构的数据。
举例:文档、图片、音频、视频。
处理方法:常常用二进制形式来做整体保存。
二、json数据
1、json是什么语言的内容?
json是js语言中用来用【字符串格式】来保存对象和数组的一种数据结构。
json数据本质上是字符串。
2、js种数组和对象:
js的数组:var array = ['aaa','bb','cc']----和python列表对应
js的对象:var obj = {name:'zhangsan',age:10}---和python字典对应。
name = obj.name
3、json数据的解析方法:
json模块:
对json字符串的操作“:
json.loads(json_str)--->python的list或者dict
json.dumps(python的list或者dict) --->json_str
------
对json文件的操作:
json.load(fp)--->从json文件中读出json数据,返回一个python的list或者dict
json.dump(python的list或者dict,fp)---》python的list或者dict保存到fp所对应的的文件中。
4、json的意义:
json作为数据格式进行传输,具有较高的效率
json不像xml那样具有严格的闭合标签,所以json作为数据传输的时候,他的数据有效占比(有效数据和总数据的比)比xml高很多。
在相同流量下,json比xml作为数据传输,传输的数据更多。
三、正则表达式
1、元字符
(1)匹配边界:
^ ----行首
$-----行尾
(2)重复次数
?----0次或1次
*----->=0
+---- >=1
{n,}--->=n
{n,m}--->=n,<=m
{n}----n次
(3)各种字符的表示
[]----匹配括号中一个字符,单字符
[abc]--匹配a或者b或者c
[a-z0-9A-Z]
\d---数字
\w---数字字母下划线
\s---空白字符:换行符、制表符、空格
\b---单词边界
.----除换行符以外的任意字符。
abb??
2、re模块的使用。
python中re模块是用来做正则处理的。
(1)re模块的使用步骤:
#1导包
import re
#2将正则表达式编译成一个pattern对象
pattern = re.complie(
r'正则表达式',
'匹配模式'
)
r表示元字符。
#3、用pattern对象来使用相应的方法来匹配内容。
(2)pattern对象的方法:
1.match方法:默认从头开始,只匹配一次,返回一个match对象。
pattern.match(
'匹配的目标字符串',
start,匹配开始的位置--缺省,start = 0
end,匹配结束的位置--缺省,end = -1
)--->match对象
match对象的属性:
match.group()---获取匹配内容。
match.span()--匹配的范围
match.start()---开始位置
match.end()---结束位置
这些方法都可以带一个参数0,但是不能写1,1来表示取分组。
match.group(0)---获取匹配内容。
match.span(0)--匹配的范围
match.start(0)---开始位置
match.end(0)---结束位置
match.groups()--将所有分组的内容,按顺序放到一个元组中返回
2、search方法:从任意位置开始匹配,只匹配一次,返回一个match对象
pattern.search(
'匹配的目标字符串',
start,匹配开始的位置--缺省,start = 0
end,匹配结束的位置--缺省,end = -1
)--->match对象
3、findall方法:全文匹配,匹配多次,将每次匹配到的结果放到list中返回。
pattern.findall(
'匹配的目标字符串',
start,匹配开始的位置--缺省,start = 0
end,匹配结束的位置--缺省,end = -1
)--->list
4、finditer方法:全文匹配,匹配多次,返回一个迭代器。
pattern.finditer(
'匹配的目标字符串',
start,匹配开始的位置--缺省,start = 0
end,匹配结束的位置--缺省,end = -1
)--->list
finditer主要用匹配内容比较多的情况下。
5、split:切分,按照正则所表示内容进行切分字符串,返回切分后的每个子串
pattern.split(
'要切分的字符串',
'切分字数',默认是全部分。
)--->list
6、sub方法:用指定字符串,替换正则表达所匹配到的内容。
pattern.sub(
repl,#替换成什么
content,替换什么
count,替换次数,默认替换所有
)--->替换后的字符串。
repl替换内容可以使函数:
函数要求:
1.函数必须有参数,参数就是正则匹配目标字符串所得到的每个match对象。
2、这个函数必须要有返回值,返回值必须是字符串,这个字符串将来就作为替换的内容。
#zhangsan:3000,lisi:4000
#涨工资每个人涨1000
content = 'zhangsan:3000,lisi:4000'
p = re.compile(r'\d+')
result = p.sub(add,)
7、分组
分组在正则表达式中使用()来表示的,一个括号就是一个分组。
分组的作用:
(1)筛选特定内容
(2)可以在同一个表达式中应用前面的分组:
\1引用第一分组
(3)findall配合分组
import re
content = '正则表达式
'
p = re.compile(r'<(html)><(h1)>(.*)')
# print(p.search(content).group())
print(p.findall(content))#[('html', 'h1', '正则表达式')]
8、贪婪非贪婪模式
(1)贪婪和非贪婪的却别在于匹配内容的多少。贪婪是尽可能多,非贪婪尽可能的少
(2)贪婪使用*来控制匹配次数的。正则默认是贪婪。默认是取数量控制符的最大值。【】
(3)非贪婪使用?来控制的。
(4)在表示数量控制元字符后面加一个?,此时就表示这个数量控制符取最小值,也就是非贪婪。
9.匹配模式:
re.S ----.可以匹配换行符
re.I----忽略大小写。
10、万能正则匹配表达式:.*?(尽可能少匹配任意内容)配合re.S
作业:
1、非负整数
[99,100,-100,-1,90]
2、匹配正整数
3、非正整数
4、qq邮箱:
qq号5位---14
5、匹配11位电话号码
1 3-9
6、匹配日期:
2019-12-19
7、长度为8-10的用户密码:
开头字母:必须大写,每一位可以是数字,字母,_
猫眼其他字段做出来。
股吧:
1、字段
阅读
评论
标题
作者
更新时间
详情页
2.10页内容保存到json文件。
day04
第四讲 xpath
一、什么xml?
1、定义:可扩展标记性语言
2、特点:xml的是具有自描述结构的半结构化数据。
3、作用:xml主要设计宗旨是用来传输数据的。他还可以作为配置文件。
二、xml和html的区别?
1、语法要求不同:xml的语法要求更严格。
(1)html不区分大小写的,xml区分。
(2)html有时可以省却尾标签。xml不能省略任何标签,严格按照嵌套首位结构。
(3)只有xml中有自闭标签(没有内容的标签,只有属性。)<a class='abc'/>
(4)在html中属性名可以不带属性值。xml必须带属性值。
(5)在xml中属性必须用引号括起来,html中可以不加引号。
2、作用不同:
html主要设计用来显示数据以及更好的显示数据。
xml主要设计宗旨就是用传输数据。
3、标记不同:xml没有固定标记,html的标记都是固定的,不能自定义。
三、xpath
1、什么是xpath?
xpath是一种筛选html或者xml页面元素的【语法】。
2、xml和html的一些名词:
元素、标签、属性、内容
3、xml的两种解析方法:
dom和sax。
4、xpath语法:
(1)选取节点:
nodename --- 选取此标签及其所有子标签。
/----从根节点开始选取。
// ----从任意节点开始,不考虑他们的位置。
//book---不管book位置,在xml中取出所有的book标签。
.----当前节点开始找
..----从父节点
@ ---选取属性
text()---选取内容
(2)谓语:起限定的作用,限定他前面的内容。
[]写在谁的后面,就限定谁,一般用于限定元素或者标签。
//book[@class='abc']
常见的谓语:
[@class] ----选取有class
[@class='abc'] ---选取class属性为abc的节点。
[contains(@href,'baidu')] ---选取href属性包含baidu的标签
[1] ---选取第一个
[last()]---选取最后一个
[last()-1]---选取倒数第二
[position()>2]---跳过前两个。
book[price>30]
(3)通配符
* ---匹配任意节点
@* ---匹配任意属性
(4)选取若干路径
| ---左边和右边的xpath选的内容都要---and
5、lxml模块----python处理xml和html的模块。
(1)解析字符串类型xml。
from lxml import etree
text='''
html页面内容
'''
tree = etree.HTML(text)---返回值就是一个element对象
#element对象有xpath方法,可以通过xpath表达式来筛选内容。
#选取class属性为item-1的li下面的a标签的内容
a_contents = tree.xpath('//li[@class="item-1"]/a/text()')
将element对象变成字符串的方法
# html_str = etree.tostring(tree,pretty_print=True).decode('utf-8')
# print(type(html_str))
#elment对象xpath放来筛选,返回值都是一个list。
#xpath表达式最后一个是一个元素(标签),list中都是elment元素
#xpath表达式最后一个是属性,list都是属性字符串
#xpath表达式最后一个是内容,list都是内容字符串
(2)解析xml或者html文件:
from lxml import etree
#parse方法是按照xml的方式来解析,如果语法出问题,就会报错。
html = etree.parse('demo.html')
# print(html)#_ElementTree
li_texts = html.xpath('//li/a/text()')
print(li_texts)
作业:
药网数据爬取:
url:https://www.111.com.cn/categories/953710-a0-b0-c31-d0-e0-f0-g0-h0-i0-j2.html
要求:抓取50页
字段:单价,描述,评论数量,详情页链接,(功能主治 ,有效期 ,用法用量)
(1)用xpath爬取数据。
(2)将数据保存到excel中
day05
1、path环境变量的作用:
为了让cmd找到各种命令exe工具,配path就找exe所在目录配置就可以了。
C:\Anaconda3\Scripts---找pip.exe
C:\Anaconda3----python.exe
多个版本,如何共存?
python3.7
anaconda
放在前面的先被使用。
2.修改完path,要重启cmd
where python
path
pip install redis
pip install aiohttp
pip install asyncio
------------------------------------------------------------------
第五讲:动态html
一、反爬策略:
1、请求头:
---user-agent
---referer
---cookie
2、访问频率限制。
---代理池
---再用户访问高峰期进行爬取,冲散日志。12-13 7-10
---设置等待时长。time.sleep(3)
3、ajax异步请求,用接口获取数据。
4、能一次性获取的数据,绝不发送第二次请求(获取数据的过程中尽量减少请求次数。)
能在列表页获取的数据,绝不进详情页。
5、页面内容是js代码。
selenium+phantomjs的组合进行页面内容的获取。
二、html页面的技术
1、js:
页面在请求html的过程中,服务器返回html,同时还会请求js文件。
2、jqery:js的库,方便js开发。
3、ajax:web的异步请求技术
同步请求,异步请求。
三、selenium和phantomjs
1、什么是selenium?
selenium一个web自动化测试工具。【但是它本身是不带浏览器】。这个工具其实就是作为一些外部工具驱动来使用的,可以控制一些外部应用来完成自动化测试。
2、phantomjs:他其实就是一个内置无界面浏览器引擎。--无界面可以提高程序运行速度。
因为phantomjs是一个浏览器引擎,所以他最大的功能就是执行页面的js代码。
3.安装selenium和phantomjs?
selenium安装:pip install selenium==2.48.0
phantomjs安装:百度phantomjs镜像--->下载一个Windows版本的————>phantomjs-2.1.1-windows.zip
可视化的chrome浏览器插件:---chromedriver安装:
下载:百度:chromedriver镜像
(1)保证chrome是正版。
(2)查看自己chrome的版本号:73.0.3683.86
(3)找一个和自己版本号最接近的版本下载。
将下载好的exe文件复制到:C:\Anaconda3\Scripts
文档:selenuim常用方法总结.note
链接:http://note.youdao.com/noteshare?id=0142a95cf23fadbaea95809ccb5674b2&sub=02896A50836E4995997A821419D9A063
day06
一、selenium的三种等待:
1、强制等待:不管页面是否加载出来,强制让进程等待。
time.sleep(2)
2、隐式等待:driver.implicitly_wait(20)
设置20秒的最大等待时长,他等待的结束条件是:等待到浏览器全部加载完成完成为止,全部加载可以理解为,浏览器不在装圈圈。
弊端:页面的加载其实不单单是页面html,重要还有一些页面静态资源,而静态资源的加载是最耗时。这些静态资源对我们爬取数据又没什么作用,所以隐式等待其实效率并不高。
3、显示等待:满足一些内置的等待条件,这要这些条件满足,就等待结束。这些条件比如:特定页面元素加载出来。
创建显示等待的步骤:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
1、创建wait对象:
wait = WebDriverWait(
driver = 作用的哪个驱动,
20,最大等待时长
0.5,每隔多少秒做页面扫描
)
2.在之前selenium使用步骤的等待位置:
wait.until(EC.presence_of_element_located(
locator = 定位器对象。
))--->返回值是一个webelement对象(locator对象所定位的哪个webelement)
定位器对象是一个元组。
locator = (By.xpath,'xpath表达式')
By.ID
By.CSS_SELECTOR
文档:selenium的三种等待.note
链接:http://note.youdao.com/noteshare?id=8f6a0765e4017a4140a05485a9d80a48&sub=48D9761ED13A49EDAC64D180C8340613
==============================================================================
day06 多线程爬虫
关注:程序运行速度---->主要是由cpu(大脑)来决定。
想要提高程序的运行速度----->提高cpu利用率。
提高cpu的利用率由两种途径:
(1)让cpu不休息。cup每时每刻都在处理任务,这个任务可以理解为线程。这种情况就叫做多线程。
(2)cpu都是分核。每个核就是一个小脑袋。可以理解一心多用。让每个核都作用起来,去干不同的事情,这种方法是就叫多进程。
一、程序、线程、进程?
程序:一个应用就可以理解为一个程序。
进程:程序运行资源分配的最小单位,一个程序可以有多个进程。
线程:cup最小的调度单位,必须依赖进程存在。线程是没有独立资源的,所有的线程共享他所在进程的所有资源。
二、什么是多线程?
程序中包含多个并行的线程来完成不同的任务。
三、python中的threading模块
1、创建多线程的第一种方法:
t = threading.Thread(
target = 方法名,
args = (,)--参数列表,元组
)
t.start()---启动线程
2、查看线程的数量:threading.enumerate()
enumerate(
可迭代对象,
i,----表示索引从i开始。
)---python的内置函数:枚举可迭代对象,同时获取迭代对象的每个值和其索引。
可迭代对象:有__iter__属性的对象。
迭代器:有__iter___和__next__属性的对象。
这两个如何转化:迭代器=iter(可迭代对象)
可迭代对象都有:list,tuple,dict,str,bytesarray,set,fp
3、创建第二种方法: 自定线程类。
python的继承:
(1)继承是通过在定义类的时候,类后面的()中添加父类来实现的。
(2)被继承的类称为父类,继承的类称为子类。
(3)子类继承父类所有非私有的属性及方法。
(4)如果子类重写父类的属性和方法,子类默认是优先拿自己的。
用自定义线程的步骤:
(1)继承threading.Thread
(2)重写run方法:
(3)实例化这个类,就相当于创建了一个线程。
t = MyThread()
t.start()---默认执行就是run方法里面的内容。
(4)如果自定义线程要传参数,这时候必须要写init方法。必须在init中先调用父类的init(初始化父类。)
调用父类的init方法有两种方法:
super().__init__()
threading.Tread.__init__(self)
4、线程的名称:线程.name查看线程的名称。
如果没有给线程自定义名称,默认线程的名称是:Thread-1,Thread-2,....
自定义名称:
t = MyThread(name=str(i))
t.start()
5、线程的五种状态:
线程的执行顺序是混乱:线程是cup调度的最小单位,线程的执行完全是由cpu调度所决定的。cpu如何来调度呢?是由线程状态决定。
【图片】
6、线程间公用数据的共享问题。
多个线程多全局变量的更改,容易造成数据的混乱。
解决办法:
将线程对公有数据更改部分,用互斥锁锁起来,这两就可以解决这种问题。
多线程避免多个线程同时处理公有变量。----解耦。
import threading
mutex = threading.Lock()#创建一个锁对象
if mutex.acquire():#上锁。
'''
公有数据的处理代码
'''
mutex.release()#释放锁
-----------------------------------
mutex.acquire(True):默认情况就是True,线程到锁这里如果没有获取锁状态,就会被阻塞。
mutex.acquire(False):线程到锁这里如果没有获取锁状态,不会被阻塞。
四、多进程和多线程
1、并发和并行
作业:
1、url:https://zu.fang.com/
思路:1、获取区域列表
2、进入区域列表,做分页
3、爬取的字段:
标题
位置
租住方式
规格
大小
朝向
详情页链接
4、将数据保存到excel
5、提交两版本。一个简单py文件,oop(面向对象-class)
6、用selenium来实现。
day07
一、mongo的配置
1、新建文件夹:
C:\MongoDB\Server\3.4\data\db
C:\MongoDB\Server\3.4\data\logs
2、配置环境变量:
C:\MongoDB\Server\3.4\bin配置到path系统环境变量中。
3、测试是否配置成功
mongod --dbpath C:\MongoDB\Server\3.4\data\db
4、配置服务:
mongod --dbpath C:\MongoDB\Server\3.4\data\db --logpath C:\MongoDB\Server\3.4\data\logs\mongo.log --logappend --port 27017 --serviceName "MongoDB" --install
二、客户端和服务端命令
服务器命令使用开启服务器,开启服务器才可以存储数据,查找数据。
客户端用连接服务器,做crud操作。
服务器命令:mongod
--dbpath ---数据库存储数据文件的路径
--port 端口,将来服务器在这个端口上绑定。
客户端命令:mongo
--port 端口号:指定连接哪个端口服务器。
任务:在cmd中开启两个个mongo服务器,端口在27018,27019,用客户端分别连接他们。
--host ---》-h
开启27018,打开一个cmd输入:
mongod --dbpath C:\MongoDB\Server\3.4\data\db --port 27018
开启27019:重新打开cmd,输入:
新建db文件夹:C:\MongoDB\Server\3.4\data\db2
mongod --dbpath C:\MongoDB\Server\3.4\data\db2 --port 27019
开启客户端
连接27018:
mongo --port 27018
连接27019:
mongo --port 27019
作业:
1,笔趣阁小说下载
url:http://www.xbiquge.la/xuanhuanxiaoshuo/
思路:进入首页,获取小说列表,进入小说,获取章节列表,在章节页面下载内容
字段:
小说名称
章节名称
章节内容
保存:
1.一本小说一个txt文件
2.每本小说都是全的。
进阶:
1.用多线程---保证章节目录是有序的。
day08
一、MongoDB简介
SQL术语/概念
MongoDB术语/概念
解释/说明
database
database
数据库
table
collection
数据库表/集合
row
document
数据记录行/文档
column
field
数据字段/域
index
index
索引
table joins
表连接, MongoDB不支持
primary key
primary key
主键, MongoDB自动将_id字段设置为主键
1、mongodb 文档数据库,存储的是文档(Bson->json的二进制化).
{name:'zhangsan',age:'9'}
2、MongoDB特点:内部执行引擎为JS解释器, 把文档存储成bson结构,在查询时,转换为JS对象,并可以通过熟悉的js语法来操作.
2、mongo和传统型数据库相比,最大的不同:
传统型数据库: 结构化数据, 定好了表结构后,每一行的内容,必是符合表结构的,就是说--列的个数,类型都一样.
mongo文档型数据库: 集合中存储的每篇文档,都可以有自己独特的结构(json对象都可以有自己独特的属性和值)
mongo数据库的collection不用提前创建(可以隐式创建。)。关系型数据库的表必须提前创建
3、mongodb数据库bin目录下的文件意义

bsondump.exe :导出bsondump结构
mongo.exe:客户端---开启一个客户端,连接指定服务,crud
mongod.exe:服务端--开启一个mongo服务器
mongodump.exe:整体数据库导出(备份工具)
mongoexport.exe:导出易识别的json文档
mongofiles.exe:GridFS工具,内建的分布式文件系统
mongoimport.exe:数据导入程序
mongorestore.exe:数据恢复工具
mongos.exe:路由器(分片时使用)
mongostat.exe:监视程序
4、mongo入门命令
show dbs 查看当前的数据库
use databaseName 选库
show collections 查看当前库下的collection,show tables
如何创建库?
Mongodb的库是隐式创建,你可以use 一个不存在的库,然后在该库下创建collection,即可创建库
use dbname ---ues一个不存在的库
db.createCollection(‘collectionName’) ---在该库下面创建集合,就可以创建一个数据库
即可创建一个集合。
其实在MongoDB中,collection也是可以隐身创建的
db.collectionName.insert(document)
如何删除数据库和集合?
db.collectionName.drop()//删除集合
db.dropDatabase()//删除数据库
二、MongoDB基础增删改查操作
1、增:insert方法
首先要明确一点,MongoDB存储的时文档,文档其实就是json格式的对象。
语法:
db.collectionName.insert(document)
增加单篇文档:
db.collectionName.insert({title:’nice day’})
增加单个文档,并指定_id
db.collectionName.insert({_id:8,age:78,name:’lisi’})
增加多个文档
db.collectionName.insert(
[
{time:'friday',study:'mongodb'},
{_id:9,gender:'male',name:'QQ'}
]
)
2、删除:remove
语法:
db.collection.remove(查询表达式, 选项)
选项是指 {justOne:true/false},是否只删一行, 默认为false
注意:
1: 查询表达式依然是个json对象 {age:20}
2: 查询表达式匹配的行,将被删掉.
3: 如果不写查询表达式,collections中的所有文档将被删掉
例1:删除stu表中 sn属性值为’001’的文档
db.stu.remove({sn:’001’})
例2: 删除stu表中gender属性为m的文档,只删除1行.
db.stu.remove({gender:’m’,true});
3、更新:update
语法: db.collection.update(查询表达式,新值,选项)
改谁? --- 查询表达式
改成什么样? -- 新值 或 赋值表达式
操作选项 ----- 可选参数
例:
db.news.update({name:'QQ'},{name:'MSN'});
是指选中news表中,name值为QQ的文档,并把其文档值改为{name:’MSN’},结果: 文档中的其他列也不见了,改后只有_id和name列了,即--新文档直接替换了旧文档,而不是修改
如果是想修改文档的某列,可以用$set关键字:
db.collectionName.update(query,{$set:{name:’QQ’}})
修改时的赋值表达式
$set 修改某列的值
$unset 删除某个列
$rename 重命名某个列
$inc 增长某个列
Option的作用:{upsert:true/false,multi:true/false}
Upsert---是指没有匹配的行,则直接插入该行.
例:
db.stu.update({name:'wuyong'},{$set:{name:'junshiwuyong'}},{upsert:true});
如果有name=’wuyong’的文档,将被修改,如果没有,将添加此新文档
db.news.update({_id:99},{x:123,y:234},{upsert:true});
没有_id=99的文档被修改,因此直接插入该文档
multi: 是指修改多行(即使查询表达式命中多行,默认也只改1行,如果想改多行,可以用此选项)
db.news.update({age:21},{$set:{age:22}},{multi:true});
则把news中所有age=21的文档,都修改
4、查: find
语法: db.collection.find(查询表达式,查询的列);
db.collections.find(表达式,{列1:1,列2:1});
在查询的列参数中,1表示显示,0表示不显示
例1:db.stu.find()
查询所有文档 所有内容
例2: db.stu.find({},{gendre:1})
查询所有文档,的gender属性 (_id属性默认总是查出来)
例3: db.stu.find({},{gender:1, _id:0})
查询所有文档的gender属性,且不查询_id属性
例4: db.stu.find({gender:’male’},{name:1,_id:0});
查询所有gender属性值为male的文档中的name属性
2. MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,及常规 SQL 的 AND 条件。类似于 WHERE 语句:WHERE by='优就业' AND title='MongoDB 教程。
语法格式如下:
db.col.find({key1:value1, key2:value2}).pretty()
3、常用方法:
limit():
db.COLLECTION_NAME.find().limit(NUMBER)
skip()
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
sort()
db.COLLECTION_NAME.find().sort({KEY:1})
count()
db.mycol.count()
5、查询表达式:
最简单的查询表达式
{filed:value} ,是指查询field列的值为value的文档
$lt小于
db.stu.find({age:{$lt:10}},{name:1,age:1})
$lte小于等于
$gt 大于
$gte大于等于
$ne --- != 查询表达式
{field:{$nq:value}} ---作用:查filed列的值 不等于 value 的文档
db.goods.find({cat_id:{$nq:3}},{cat_id:1,goods_id:1,goods_name:1,_id:0})
//查询cat_id不等3的数据
$nin --> not in
db.stu.find({age:{$nin:[1,16]}})
$all:指数组所有单元匹配,就是指我指定的内容都要有,通过一个list来指定
db.stu.insert({name:'xt',age:99,hobby:['aa','bb']})
db.stu.find({hobby:{$all:['aa','bb']}},{name:1,age:1,_id:0})
$exists
语法: {field:{$exists:1}}
作用: 查询出含有field字段的文档
db.stu.find({hobby:{$exists:1}})
$nor
{$nor:[条件1,条件2]} 是指 所有条件都不满足的文档为真返回
$and
{$and:[条件1,条件2]} 是指 所有条件都满足,就为真
$or
{$or:[条件1,条件2]} 是指 条件1和条件2有一个满足,就为真
基础查询 where的练习
练习文档
对应的mysql数据: $sql = 'select goods_id,cat_id,goods_name,goods_number,click_count,shop_price,add_time from ecs_goods';
mongodb数组:
[{"goods_id":1,"cat_id":4,"goods_name":"KD876","goods_number":1,"click_count":7,"shop_price":1388.00,"add_time":1240902890},{"goods_id":4,"cat_id":8,"goods_name":"\u8bfa\u57fa\u4e9aN85\u539f\u88c5\u5145\u7535\u5668","goods_number":17,"click_count":0,"shop_price":58.00,"add_time":1241422402},{"goods_id":3,"cat_id":8,"goods_name":"\u8bfa\u57fa\u4e9a\u539f\u88c55800\u8033\u673a","goods_number":24,"click_count":3,"shop_price":68.00,"add_time":1241422082},{"goods_id":5,"cat_id":11,"goods_name":"\u7d22\u7231\u539f\u88c5M2\u5361\u8bfb\u5361\u5668","goods_number":8,"click_count":3,"shop_price":20.00,"add_time":1241422518},{"goods_id":6,"cat_id":11,"goods_name":"\u80dc\u521bKINGMAX\u5185\u5b58\u5361","goods_number":15,"click_count":0,"shop_price":42.00,"add_time":1241422573},{"goods_id":7,"cat_id":8,"goods_name":"\u8bfa\u57fa\u4e9aN85\u539f\u88c5\u7acb\u4f53\u58f0\u8033\u673aHS-82","goods_number":20,"click_count":0,"shop_price":100.00,"add_time":1241422785},{"goods_id":8,"cat_id":3,"goods_name":"\u98de\u5229\u6d669@9v","goods_number":1,"click_count":9,"shop_price":399.00,"add_time":1241425512},{"goods_id":9,"cat_id":3,"goods_name":"\u8bfa\u57fa\u4e9aE66","goods_number":4,"click_count":20,"shop_price":2298.00,"add_time":1241511871},{"goods_id":10,"cat_id":3,"goods_name":"\u7d22\u7231C702c","goods_number":7,"click_count":11,"shop_price":1328.00,"add_time":1241965622},{"goods_id":11,"cat_id":3,"goods_name":"\u7d22\u7231C702c","goods_number":1,"click_count":0,"shop_price":1300.00,"add_time":1241966951},{"goods_id":12,"cat_id":3,"goods_name":"\u6469\u6258\u7f57\u62c9A810","goods_number":8,"click_count":13,"shop_price":983.00,"add_time":1245297652}]
[{"goods_id":13,"cat_id":3,"goods_name":"\u8bfa\u57fa\u4e9a5320 XpressMusic","goods_number":8,"click_count":13,"shop_price":1311.00,"add_time":1241967762},{"goods_id":14,"cat_id":4,"goods_name":"\u8bfa\u57fa\u4e9a5800XM","goods_number":1,"click_count":6,"shop_price":2625.00,"add_time":1241968492},{"goods_id":15,"cat_id":3,"goods_name":"\u6469\u6258\u7f57\u62c9A810","goods_number":3,"click_count":8,"shop_price":788.00,"add_time":1241968703},{"goods_id":16,"cat_id":2,"goods_name":"\u6052\u57fa\u4f1f\u4e1aG101","goods_number":0,"click_count":3,"shop_price":823.33,"add_time":1241968949},{"goods_id":17,"cat_id":3,"goods_name":"\u590f\u65b0N7","goods_number":1,"click_count":2,"shop_price":2300.00,"add_time":1241969394},{"goods_id":18,"cat_id":4,"goods_name":"\u590f\u65b0T5","goods_number":1,"click_count":0,"shop_price":2878.00,"add_time":1241969533},{"goods_id":19,"cat_id":3,"goods_name":"\u4e09\u661fSGH-F258","goods_number":12,"click_count":7,"shop_price":858.00,"add_time":1241970139},{"goods_id":20,"cat_id":3,"goods_name":"\u4e09\u661fBC01","goods_number":12,"click_count":14,"shop_price":280.00,"add_time":1241970417},{"goods_id":21,"cat_id":3,"goods_name":"\u91d1\u7acb A30","goods_number":40,"click_count":4,"shop_price":2000.00,"add_time":1241970634},{"goods_id":22,"cat_id":3,"goods_name":"\u591a\u666e\u8fbeTouch HD","goods_number":1,"click_count":15,"shop_price":5999.00,"add_time":1241971076}]
[{"goods_id":23,"cat_id":5,"goods_name":"\u8bfa\u57fa\u4e9aN96","goods_number":8,"click_count":17,"shop_price":3700.00,"add_time":1241971488},{"goods_id":24,"cat_id":3,"goods_name":"P806","goods_number":100,"click_count":35,"shop_price":2000.00,"add_time":1241971981},{"goods_id":25,"cat_id":13,"goods_name":"\u5c0f\u7075\u901a\/\u56fa\u8bdd50\u5143\u5145\u503c\u5361","goods_number":2,"click_count":0,"shop_price":48.00,"add_time":1241972709},{"goods_id":26,"cat_id":13,"goods_name":"\u5c0f\u7075\u901a\/\u56fa\u8bdd20\u5143\u5145\u503c\u5361","goods_number":2,"click_count":0,"shop_price":19.00,"add_time":1241972789},{"goods_id":27,"cat_id":15,"goods_name":"\u8054\u901a100\u5143\u5145\u503c\u5361","goods_number":2,"click_count":0,"shop_price":95.00,"add_time":1241972894},{"goods_id":28,"cat_id":15,"goods_name":"\u8054\u901a50\u5143\u5145\u503c\u5361","goods_number":0,"click_count":0,"shop_price":45.00,"add_time":1241972976},{"goods_id":29,"cat_id":14,"goods_name":"\u79fb\u52a8100\u5143\u5145\u503c\u5361","goods_number":0,"click_count":0,"shop_price":90.00,"add_time":1241973022},{"goods_id":30,"cat_id":14,"goods_name":"\u79fb\u52a820\u5143\u5145\u503c\u5361","goods_number":9,"click_count":1,"shop_price":18.00,"add_time":1241973114},{"goods_id":31,"cat_id":3,"goods_name":"\u6469\u6258\u7f57\u62c9E8 ","goods_number":1,"click_count":5,"shop_price":1337.00,"add_time":1242110412},{"goods_id":32,"cat_id":3,"goods_name":"\u8bfa\u57fa\u4e9aN85","goods_number":4,"click_count":9,"shop_price":3010.00,"add_time":1242110760}]
cageory表 ,对应的mysql数据: select cat_id,cat_name from ecs_category;
[{"cat_id":1,"cat_name":"\u624b\u673a\u7c7b\u578b"},{"cat_id":2,"cat_name":"CDMA\u624b\u673a"},{"cat_id":3,"cat_name":"GSM\u624b\u673a"},{"cat_id":4,"cat_name":"3G\u624b\u673a"},{"cat_id":5,"cat_name":"\u53cc\u6a21\u624b\u673a"},{"cat_id":6,"cat_name":"\u624b\u673a\u914d\u4ef6"},{"cat_id":7,"cat_name":"\u5145\u7535\u5668"},{"cat_id":8,"cat_name":"\u8033\u673a"},{"cat_id":9,"cat_name":"\u7535\u6c60"},{"cat_id":11,"cat_name":"\u8bfb\u5361\u5668\u548c\u5185\u5b58\u5361"},{"cat_id":12,"cat_name":"\u5145\u503c\u5361"},{"cat_id":13,"cat_name":"\u5c0f\u7075\u901a\/\u56fa\u8bdd\u5145\u503c\u5361"},{"cat_id":14,"cat_name":"\u79fb\u52a8\u624b\u673a\u5145\u503c\u5361"},{"cat_id":15,"cat_name":"\u8054\u901a\u624b\u673a\u5145\u503c\u5361"}]
练习题目
//主键为32的商品
db.goods.find({goods_id:32});
//不属第3栏目的所有商品($ne)
db.goods.find({cat_id:{$ne:3}},{goods_id:1,cat_id:1,goods_name:1});
//本店价格高于3000元的商品{$gt}
db.goods.find({shop_price:{$gt:3000}},{goods_name:1,shop_price:1});
//本店价格低于或等于100元的商品($lte)
db.goods.find({shop_price:{$lte:100}},{goods_name:1,shop_price:1});
//取出第4栏目或第11栏目的商品($in)
db.goods.find({cat_id:{$in:[4,11]}},{goods_name:1,shop_price:1});
//取出100<=价格<=500的商品($and)
db.goods.find({$and:[{price:{$gt:100},{$price:{$lt:500}}}]);
//取出不属于第3栏目且不属于第11栏目的商品($and $nin和$nor分别实现)
db.goods.find({$and:[{cat_id:{$ne:3}},{cat_id:{$ne:11}}]}
,{goods_name:1,cat_id:1})
db.goods.find({cat_id:{$nin:[3,11]}},{goods_name:1,cat_id:1});
db.goods.find({$nor:[{cat_id:3},{cat_id:11}]},{goods_name:1,cat_id:1});
//取出价格大于100且小于300,或者大于4000且小于5000的商品()
db.goods.find({
$or:[
{
$and:[
{shop_price:{$gt:100}},
{shop_price:{$lt:300}}
]
},
{
$and:[
{shop_price:{$gt:4000}},
{shop_price:{$lt:5000}}
]
}
]},{goods_name:1,shop_price:1});
//取出goods_id%5 == 1, 即,1,6,11,..这样的商品
db.goods.find({goods_id:{$mod:[5,1]}});
//取出有age属性的文档
db.stu.find({age:{$exists:1}});
含有age属性的文档将会被查出
6、MongoDB 聚合(db.col.aggregate())
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
语法:
db.COLLECTION_NAME.aggregate(
[
{管道1},
{管道2},
{管道3},
...
]
)
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理,管道操作是可以重复的。
聚合框架中常用的几个管道操作:
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
group中的一下操作表达式:
表达式
描述
$sum
计算总和。
$avg
计算平均值
$min
获取集合中所有文档对应值得最小值。
$max
获取集合中所有文档对应值得最大值。
$first
根据资源文档的排序获取第一个文档数据。
$last
根据资源文档的排序获取最后一个文档数据
聚合操作练习:
1.查询每个栏目下的商品数量
db.collection.aggregate(); [{$group:{_id:"$cat_id",total:{$sum:1}}}]
2.查询goods下有多少条商品
db.goods.aggregate([{$group:{_id:null,total:{$sum:1}}}])
3.查询每个栏目下价格大于50元的商品个数
db.goods.aggregate([{$match:{shop_price:{$gt:50}}}, {$group:{_id:"$cat_id",total:{$sum:1}}}])
4.查询每个栏目下的库存量
db.goods.aggregate([{$group:{_id:"$cat_id" , total:{$sum:"$goods_number"}}}])
5.查询每个栏目下 价格大于50元的商品个数 #并筛选出"满足条件的商品个数" 大于等于3的栏目
(1)价格大于50:
{$match:{shop_price:{$gt:50}}}
(2)要想查出个数大于3的栏目,必须先对cat_id进行分组:
{$group:{_id:"$cat_id",total:{$sum:1}}}
(3)最后用match来去除大于3个的栏目
{$match:{total:{$gte:3}}}
6.查询每个栏目下的库存量,并按库存量排序
思路:
(1)按栏目的库存量分组(2)排序
{$group:{_id:"$cat_id" , total:{$sum:"$goods_number"}}}
{$sort:{total:1}}
db.goods.aggregate([{$group:{_id:"$cat_id" , total:{$sum:"$goods_number"}}}, {$sort:{total:1}}])
1是正序,-1是逆序
7.查询每个栏目的商品平均价格,并按平均价格由高到低排序
db.goods.aggregate([{$group:{_id:"$cat_id",avg:{$avg:"$shop_price"}}},{$sort:{avg:-1}}])
三、游标操作
前面给大家讲过,MongoDB在底层上时用js来实现的,所以我们可以通过以下代码,在数据库中插入1000条数据。
for (var i=0;i<1000;i++){
db.bar.insert({_id:i+1,title:'hello world'+i,content:'aaa'+i})
}
我们可以看出,上面就是js的for循环代码。所以在MongoDB中可以将js代码和我们的数据库做操作指令一起配合来使用。
如果数据库中很多数据,比如刚刚插入的1000条,我们执行以下命令:
db.bar.find()
他会将所有的数据都查询出来给我们,此时我们考虑是否能让我们在查询的时候,像python中生成器那样,每次给我们返回一个数据。其实在MongoDB中也有类似生成器这样的东东,他叫游标
1、游标是什么?
mongo的游标相当于python中的迭代器。通过将查询结构定义给一个变量,这个变量就是游标。通过这个游标,我们可以每次获取一个数据。
2、游标的声明:
var curor_name = db.bar.find()
3、游标的操作:
curor.hasNext()//判断游标是否已经取到尽头,|true表示没有到尽头。
curor.next()//取出游标的下一个单元
例如:
var mycusor = db.bar.find().limit(5)
print(mycusor.next())//会显示是一个bson格式的数据
printjson(mycusor.next())
我们可以写一个while循环来打印游标结果:
while(mycusor.hasNext()){
printjson(mycusor.next())
}
游标还有一个toArray()方法,方便我们可以看到所有行
print(mycusor.toArray())//看到所有行
print(mycusor.toArray()[2])//看到第二行
注意不要使用toArray(),原因是会把所有的行立即以对象的形式放在内存中,可以再取出少数几行时,使用此功能。
4、cursor.forEach(回调函数)
var gettile = function(obj){print(obj.goods_name)}
var cursor = db.goods.find()
cursor.forEach(gettile)
5、游标在分页中的应用
一般的,我们假设每页N行,当前是page页,就需要跳过(page-1)*N,再取N行,在mysql中,用limit,offset,N来实现,在MongoDB中,用skip(),limit()函数来实现。
var mycusor = db.bar.find().skip(90).limit(10)//跳过90条,取10条。
var mycursor = db.bar.find().skip(9995);
则是查询结果中,跳过前9995行
查询第901页,每页10条
则是 var mytcursor = db.bar.find().skip(9000).limit(10);
四、索引创建
索引提高查询速度,降低写入速度,[权衡常用的查询字段,不必在太多列上建索引]
在mongodb中,索引可以按字段升序/降序来创建,便于排序
默认是用btree来组织索引文件,2.4版本以后,也允许建立hash索引
常用命令:
(1)查看当前索引状态:db.collection.getIndexes()
(2)创建普通单列索引:db.collection.ensureIndex({field:1/-1})//1为正序,-1为逆序
(3)删除单个索引:db.collection.dropIndex({field:1/-1})
(4)删除所有索引:db.collection.dropIndexes()
_id所在的列的索引不能删除。
(5)创建多列索引:db.collection.ensureIndex({field1:1/-1,field2:1/-1})
多列索引的使用范围更广,因为一般情况下,我们都是通过多个字段来进行查询数据的,这时候单列索引其实用不到。
两个列一起建立索引其实就是将两个列绑定到一起,来创建索引
(6)子文档索引:
子文档查询:
1.插入两条带子文档的数据
db.shop. insert({name: 'N0kia' , SPC: {weight: 120 , area: ' taiwan ' } } ) ;
db.shop. insert({name: 'sanxing ' , SPC :{weight: 100 , area: 'hanguo'} } ) ;
2.查询出产地在台湾的手机
db.shop.find({'spc.area':'taiwan'})
给子文档加索引:
db.shop.ensureIndex({'spc.area':1})//子文档就点就可以了
(7) 唯一索引:{unique:true}
db.collection.ensureIndex({field:1/-1},{unique:true})
唯一索引的列不能重复插入
(8)hash索引:
db.collection.ensureIndex({field:'hashed'})
五、MongoDB数据的导入导出
1、通用选项:
导入/导出可以操作的是本地的mongodb服务器,也可以是远程的.
所以,都有如下通用选项:
--host host 主机
--port port 端口
-u username 用户名
-p passwd 密码
2、mongoexport 导出json格式的文件
-d 库名
-c 表名
-f field1,field2...列名
-q 查询条件
-o 导出的文件名
--type csv 导出csv格式(便于和传统数据库交换数据)
例1:
mongoexport -d test -c news -o test.json
例2: 只导出goods_id,goods_name列
mongoexport -d test -c goods -f goods_id,goods_name -o goods.json
例3: 只导出价格低于1000元的行
mongoexport -d test -c goods -f goods_id,goods_name,shop_price -q ‘{shop_price:{$lt:200}}’ -o goods.json
注: _id列总是导出
当初csv文件的时候,需要指定导出哪些列。
mongoexport -d shop -c goods -o goods.csv --type csv -f goods_id,cat_id,goods_name,shop_price
3、Mongoimport 导入
-d 待导入的数据库
-c 待导入的表(不存在会自己创建)
--file 备份文件路径
例1: 导入json
mongoimport -d test -c goods --file ./goodsall.json
例2: 导入csv
mongoimport -d test -c goods --type csv -f goods_id,goods_name --file ./goodsall.csv
4、mongodump 导出二进制bson结构的数据及其索引信息
-d 库名
-c 表名
mongodum -d test [-c 表名] 默认是导出到mongo下的dump目录
规律:
导出的文件放在以database命名的目录下
每个表导出2个文件,分别是bson结构的数据文件, json的索引信息
如果不声明表名, 导出所有的表
5、mongorestore 导入二进制文件
mongorestore -d shop -c goods --dir ./dump/shop/goods.bson
二进制备份,不仅可以备份数据,还可以备份索引,备份数据比较小.速度比较快。
六、replaction复制集
一般情况下,我们通常在机器上安装了一个数据库,这是我们的数据都是存在这个数据库中的,如果有一天,因为一些不可控因素导致数据库宕机或者数据库的文件丢失,此时损失就很大了。针对于这种问题,我们希望有一个数据库集,在我们其中一个数据库进行插入的时候,其他数据库也能插入数据,这样其中一台服务器宕机了,也能够使我们的数据正常存取。
在MongoDB中,是通过replaction复制集来实现此功能的。
在Windows下实现复制集的方法:
创建复制集之前,把所有的mongo服务器都关掉
1、创建三个存储数据库的文件夹,用来保存数据文件

2、打开三个cmd窗口,分别启动三个mongodb
mongod --dbpath C:\MongoDB\Server\3.4\data\m1 --logpath C:\MongoDB\Server\3.4\data\logs\mongo1.log --port 27017 --replSet rs
mongod --dbpath C:\MongoDB\Server\3.4\data\m2 --logpath C:\MongoDB\Server\3.4\data\logs\mongo2.log --port 27018 --replSet rs
mongod --dbpath C:\MongoDB\Server\3.4\data\m3 --logpath C:\MongoDB\Server\3.4\data\logs\mongo3.log --port 27019 --replSet rs
其中的--replSet就表示创建的数据集的名称,必须指定相同的名称才可以。
3、配置
var rsconf = {
_id:'rs',
members:[
{_id:0,host:'127.0.0.1:27017'},
{_id:1,host:'127.0.0.1:27018'},
{_id:2,host:'127.0.0.1:27019'}
]
}
这时候我们可以打印rsconf来看一下
printjson(rsconf)
接下来需要将配置初始化
rs.initiate(rsconf)
现在我们看到,现在登录客户端已经不是哪台机器,而是rs复制集
我们在主机上插入一条数据,再从机上必须输入rs.slaveOk()之后才能被允许查看数据
5、删除复制集
rs.remove('127.0.0.1:27019')
删除节点后,如果想再添加,必须重新配置才可以。
var rsconf = {
_id:'rs',
members:[
{_id:0,host:'127.0.0.1:27017'},
{_id:1,host:'127.0.0.1:27018'},
{_id:2,host:'127.0.0.1:27019'}
]
}
在输入:rs.reconfig(rsconf)
在输入rs.status(),可以看到数据集现在又是三个了。
day09
一、Redis基础知识
redis的客户端和服务端命令:
redis-server :服务器命令
启动一个redis的命令是:redis-server redis.windows.conf
redis-cli:客户端命令
启动一个客户端的redis命令:redis-cli -p 6379
一个redis.windows.conf配置就是一个redis服务器。需要启动多个服务器时,只需要修改一下这个配置文件redis.windows.conf的名称,更改端口号,再用redis-server就可以启动。
要求:启动一个端口号在6380上的redis服务器。
1.创建配置文件如下:
![]()

3、用如下命令启动


1、redis和memcached相比,的独特之处:
redis可以持久化数据到硬盘,memcached只能做缓存。
redis可以用来做存储(storge),也就是redis可以将数据持久化到硬盘。 而memccached是用来做缓存(cache) 这个特点主要因为其有”持久化”的功能.
redis相比于memcached,其支持的数据类型更多。
存储的数据有”结构”,对于memcached来说,存储的数据,只有1种类型--”字符串”, 而redis则可以存储字符串,链表,哈希结构,集合,有序集合.
2、redis的优点
读写速度快. 数据存放在内存中,数据结构类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
支持丰富的数据类型,string,hash,list,set,sorted
支持简单事务,watch
丰富的特性:可以用于缓存,消息队列,按key设置过期时间,到期后自动删除
支持数据持久化(将内存数据持久化到磁盘),支持AOF和RDB两种持久化方式,从而进行数据恢复操作,可以有效地防止数据丢失
支持主从(master-slave)复制来实现数据备份,主机会自动将数据同步到从机
2、Redis目录下的重要文件的意义:
redis-benchmark 性能测试工具
redis-check-aof 日志文件检测工(比如断电造成日志损坏,可以检测并修复)
redis-check-dump 快照文件检测工具,效果类上
redis-cli 客户端
redis-server 服务端
redis.windows.conf redis配置文件,在启动redis服务器的时候,必须要指定配置文件,那么相当于于一个配置文件就是一个redis数据库服务器。
redis服务器启动命令:
redis-server redis.windows.conf
3、redis基础命令:
keys * //返回键(key)
keys list* //返回名以list开头的所有键(key)
exists list1 //判断键名为list1的是否存在 存在返回1, 不存在返回0
del list1 //删除一个键(名为list1)
expire list1 10 //设置键名为list1的过期时间为10秒后
ttl list1 //查看键名为list1的过期时间,若为-1表示已过期 或 永不过期
move age 1 //将键名age的转移到1数据库中。
select 1 //表示进入到1数据库中,默认在0数据库
persist age //移除age的过期时间。
flushdb:删除所有的数据 清除当前所在库的所有数据
flushall 清空所有数据
二、redis数据类型
(一)String字符串
set
get
mset
mget
setnx
msetnx
incr
decr
incrby
decrby
setrange
getrange
set方法:设置key对应的值为string类型的value,如果该key已经存在,则覆盖key对应的value值。所以在redis中key只能有一个。
127.0.0.1:6379> set name lijie
get:根据key获取value值
127.0.0.1:6379> get name
Setnx:设置一个不存的字符串,返回0 表示设置失败,已存在。返回1 表示设置新值成功,nx是not exist的意思。
127.0.0.1:6379> setnx name zs
(integer) 0
127.0.0.1:6379> setnx age 20
(integer) 1
setex:设置字符串,同时设置有效期。ex---expire(有效期)
127.0.0.1:6379> setex color 10 red
OK
立即查询
127.0.0.1:6379> get color"red"
10秒后查询
127.0.0.1:6379> get color
(nil)
Setrange:替换字符串。
setrange 替换什么 从哪里开始(0) 替换成什么
127.0.0.1:6379> set email jalja@sina.com
OK
127.0.0.1:6379> get email
"[email protected]"
127.0.0.1:6379> setrange email 6 163.com
(integer) 14
127.0.0.1:6379> get email
"[email protected]"
Mset:一次设置多个key-value,返回OK表示全部设置成功,返回0表示全部失败。如果存在则替换。m--multi
127.0.0.1:6379> mset name1 zs name2 ls
OK
127.0.0.1:6379> get name1
"zs"
127.0.0.1:6379> get name2
"ls"
msetnx:一次设置多个不存在的key-value,返回1表示全部设置成功,返回0表示全部失败。
127.0.0.1:6379> msetnx name3 kk name4 mm name2 LL
(integer) 0
127.0.0.1:6379> get name3
(nil)
127.0.0.1:6379> get name4
(nil)
getset:获取原值,并设置新值
127.0.0.1:6379> getset name4 UU
(nil)
127.0.0.1:6379> get name4
"UU"
127.0.0.1:6379> getset name4 RR
"UU"
getrange:获取key对应value的子字符串
127.0.0.1:6379> get email
"[email protected]"
127.0.0.1:6379> getrange email 0 4
"jalja"
mget:一次获取多个key对应的value值,不存在返回nil
127.0.0.1:6379> mget name1 name2 name3 name4 name5
1) "zs"
2) "ls"
3) (nil)
4) "RR"
5) (nil)
incr:对key对应的value做加1操作,并返回新值
127.0.0.1:6379> get age
"20"
127.0.0.1:6379> incr age
(integer) 21
incrby:与incr类似,加指定值,key不存在的时候会设置key,并认为该key原来的value=0
127.0.0.1:6379> get age
"21"
127.0.0.1:6379> incrby age 9
(integer) 30
127.0.0.1:6379> incrby age -5
(integer) 25
127.0.0.1:6379> incrby height 10
(integer) 10
decr:对key对应的value做减1操作
127.0.0.1:6379> get height
"10"
127.0.0.1:6379> decr height
(integer) 9
127.0.0.1:6379> decr height
(integer) 8
decrby:对key对应的value减去指定的值
127.0.0.1:6379> get height
"8"
127.0.0.1:6379> decrby height 3
(integer) 5
127.0.0.1:6379> decrby height -3
(integer) 8
append:对key对应的vlaue字符串追加,返回新字符串的长度
127.0.0.1:6379> get name1
"zs"
127.0.0.1:6379> append name1 ML
(integer) 4
127.0.0.1:6379> get name1
"zsML"
strlen:获取key对应value的长度
127.0.0.1:6379> get name1
"zsML"
127.0.0.1:6379> strlen name1
(integer) 4
(二)Hash类型
Redis hash 是一个string类型的filed和value的映射表、它的添加、删除操作都是O(1)(平均操作)。Hash特别适合存储对象。相较于对象的每个字段存成单个string类型。将一个对象存储在hash类型中会占用更少的内存,并且可以更方便存取整个对象。
1、hset:设置hash filed 为指定值,如果key不存在,则先创建。key存在则替换
127.0.0.1:6379> hset user:001 name zs
(integer) 1
127.0.0.1:6379> hget user:001 name
"zs"
#设置一个user:001 的用户的name为zs(可以将user:001看做一个表)
2.hget:获取指定field字段的值
127.0.0.1:6379> hget user:001 name
(nil)
3、 hsetnx:设置hash filed 为指定值,如果key不存在,则先创建。如果存在则返回0表示设置失败。
127.0.0.1:6379> hsetnx user:001 name ML
(integer) 0
127.0.0.1:6379> hsetnx user:001 age 1
(integer) 1
3、hmset:同时设置hash的多个file
127.0.0.1:6379> hmset user:002 name MM age 20
OK
127.0.0.1:6379> hget user:002 name
"MM"
127.0.0.1:6379> hget user:002 age
"20"
4、hmget:获取全部指定的hash filed,必须指定获取的key的名称
127.0.0.1:6379> hmget user:002 name age
1) "MM"
2) "20"
5、hincrby:对hash filed加上指定的值
127.0.0.1:6379> hget user:002 age
"20"
127.0.0.1:6379> hincrby user:002 age 5
(integer) 25
127.0.0.1:6379> hincrby user:002 age -5
(integer) 20
6、hexists:测试指定的filed是否存在,返回1表示存在,返回0表示不存在
127.0.0.1:6379> hexists user:002 name
(integer) 1
127.0.0.1:6379> hexists user:002 age
(integer) 1
127.0.0.1:6379> hexists user:002 height
(integer) 0
7、hlen:返回指定hash的field的数量
127.0.0.1:6379> hlen user:002
(integer) 2
8、hdel 删除指定hash 的filed字段,返回1表示删除成功0:表示删除失败
127.0.0.1:6379> hget user:002 age
"20"
127.0.0.1:6379> hdel user:002 age
(integer) 1
127.0.0.1:6379> hdel user:002 age
(integer) 0
127.0.0.1:6379> hget user:002 age
(nil)
9、hkeys:返回hash 的所有filed
127.0.0.1:6379> hkeys user:001
1) "name"
2) "age"
127.0.0.1:6379> hkeys user:002
1) "name"
10、hvals:返回hash的所有value
127.0.0.1:6379> hvals user:001
1) "zs"
2) "1"
127.0.0.1:6379> hvals user:002
1) "MM"
(三)List类型
List是一个链表结构,主要功能是push、pop,获取一个范围的所有值等等,操作中key理解为链表的名字。Redis的list类型其实就是一个每个子元素都是string类型的双向链表。我们可以通过push、pop操作链表的头部或者链表尾部添加元素,这样list既可以作为栈,又可以作为队列。
1、lpush:在key对应list的头部添加字符串元素,返回list中元素的个数
127.0.0.1:6379> lpush list1 "hello"
(integer) 1
127.0.0.1:6379> lpush list1 "word"
(integer) 2
2、lrange:获取list中的元素,
127.0.0.1:6379> lrange list1 0 -1(0:第一个,-1:最后一个)
1) "word"
2) "hello"
3、rpush:在key对应的list尾部添加元素
127.0.0.1:6379> rpush list2 10
(integer) 1
127.0.0.1:6379> rpush list2 11
(integer) 2
127.0.0.1:6379> lrange list2 0 -1
1) "10"
2) "11"
4、linsert:在key对应list的特定位置前或后添加字符串
127.0.0.1:6379> lrange list2 0 -1
1) "10"
2) "11"
127.0.0.1:6379> linsert list2 before 11 10.5
(integer) 3
127.0.0.1:6379> linsert list2 after 11 11.5
127.0.0.1:6379> lrange list2 0 -1
1) "10"
2) "10.5"
3) "11"
4)"11.5"
5、lset:更改list中指定下标的元素,返回ok表示设置成功
127.0.0.1:6379> lrange list2 0 -1
1) "10"
2) "10.5"
3) "11"
127.0.0.1:6379> lset list2 1 10.00
OK
127.0.0.1:6379> lrange list2 0 -1
1) "10"
2) "10.00"
3) "11"
6、lrem:从key对应list中删除n个和value相同的元素(n<0 从尾部删除,n=0 全部删除,n>0从头部删除。)
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
3) "one"
127.0.0.1:6379> lrem list 1 one
(integer) 1
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
7、ltrim:保留list中指定范围的数据,其他的都不要了
127.0.0.1:6379> lrange list2 0 -1
1) "10"
2) "10.00"
3) "11"
4) "12"
127.0.0.1:6379> ltrim list2 1 2
OK
127.0.0.1:6379> lrange list2 0 -1
1) "10.00"
2) "11"
8、lpop:从list的头部删除元素,并返回该元素
127.0.0.1:6379> lrange list 0 -1
1) "two"
2) "one"
127.0.0.1:6379> lpop list
"two"
127.0.0.1:6379> lrange list 0 -1
1) "one"
9、rpop:从list尾部删除元素,并返回该元素
10、rpoplpush:从第一个list的尾部删除元素,并添加到第二个list的头部
127.0.0.1:6379> lrange list 0 -1
1) "one"
127.0.0.1:6379> lrange list1 0 -1
1) "word"
2) "hello"
127.0.0.1:6379> rpoplpush list1 list
"hello"
127.0.0.1:6379> lrange list 0 -1
1) "hello"
2) "one"
127.0.0.1:6379> lrange list1 0 -1
1) "word"
11、lindex 返回名称为key的list中index位置的元素<===>list[index]
127.0.0.1:6379> lrange list 0 -1
1) "hello"
2) "one"
127.0.0.1:6379> lindex list 1
"one"
12、llen:返回指定key对应list的长度<====> len(list)
127.0.0.1:6379> lrange list 0 -1
1) "hello"
2) "one"
127.0.0.1:6379> llen list
(integer) 2
(三)Sets类型
Set是一个string类型的无序集合,不允许重复。Set是通过hash table实现的。添加、删除、查找的复杂度都是0(1)。对集合我们可以取并集、交集、差集。
1、 sadd:向key对应的set集合中添加元素,返回1表示添加成功,返回0 表示失败
127.0.0.1:6379> sadd myset1 one
(integer) 1
127.0.0.1:6379> sadd myset1 two
(integer) 1
2、 Smembers:查看set集合中的元素
127.0.0.1:6379> smembers myset1
1) "two"
2) "one"
3、srem:删除key对应set集合中的元素,返回1表示删除成功 0表示失败
127.0.0.1:6379> srem myset1 two
(integer) 1
4、spop:随机删除set中的一个元素并返回该元素
127.0.0.1:6379> smembers myset1
1) "three"
2) "one"
3) "four"
127.0.0.1:6379> spop myset1
"four"
127.0.0.1:6379> smembers myset1
1) "three"
2) "one"
5、sdiff:返回给定set集合的差集 (以在前的set集合为标准)
127.0.0.1:6379> smembers myset1
1) "three"
2) "one"
127.0.0.1:6379> smembers myset2
1) "two"
2) "one"
127.0.0.1:6379> sdiff myset1 myset2
1) "three"
127.0.0.1:6379> sdiff myset2 myset1
1) "two"
6、sdiffstore:返回所有给定set集合的差集,并将差集添加到另外一个集合中
127.0.0.1:6379> smembers myset1
1) "three"
2) "one"
127.0.0.1:6379> smembers myset2
1) "two"
2) "one"
127.0.0.1:6379> sdiffstore myset3 =myset1 -myset2
(integer) 1
127.0.0.1:6379> smembers myset3
1) "three"
7、sinter:返回所有给定集合的交集
127.0.0.1:6379> smembers myset1
1) "three"
2) "one"
127.0.0.1:6379> smembers myset2
1) "two"
2) "one"
127.0.0.1:6379> sinter myset1 myset2
1) "one"
8、sinterstore:返回所有给定集合key的交集,并将结果存为另一个key
127.0.0.1:6379> smembers myset1
1) "three"
2) "one"
127.0.0.1:6379> smembers myset2
1) "two"
2) "one"
127.0.0.1:6379> sinterstore myset4 =myset1 myset2
(integer) 1
9、sunion 返回所有给定集合的并集
127.0.0.1:6379> smembers myset1
1) "three"
2) "one"
127.0.0.1:6379> smembers myset2
1) "two"
2) "one"
127.0.0.1:6379> sunion myset1 myset2
1) "three"
2) "two"
3) "one"
10、sunionstore 返回所有给定集合的并集,并将结果存入另一个集合
127.0.0.1:6379> smembers myset1
1) "three"
2) "one"
127.0.0.1:6379> smembers myset2
1) "two"
2) "one"
127.0.0.1:6379> sunionstore myset5 myset1 myset2
(integer) 3
11、smove:从第一个集合中移除元素并将该元素添加到另一个集合中。
127.0.0.1:6379> smembers myset1
1) "three"
2) "one"
127.0.0.1:6379> smembers myset5
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> smove myset5 myset1 two
(integer) 1
127.0.0.1:6379> smembers myset5
1) "three"
2) "one"
127.0.0.1:6379> smembers myset1
1) "three"
2) "two"
3) "one"
12、Scard:返回set集合中元素的个数 llen(list) strlen (str) hlen(hash)
127.0.0.1:6379> smembers myset1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> scard myset1
(integer) 3
13、sismember:测试member元素是否是名称为key的set集合 返回1:表示是 0:不是
127.0.0.1:6379> smembers myset1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> sismember myset1 tree
(integer) 0
127.0.0.1:6379> sismember myset1 three
(integer) 1
14、srandmember:随机返回set集合中的一个元素,但不删除该元素
127.0.0.1:6379> smembers myset1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> srandmember myset1
"one"
(四)Sorted set (zset)类型
Sorted set是set的一个升级版,他在set的基础上增加了一个顺序属性,这一属性在添加元素的时候可以指定,每次指定后,zset会自动重新按新的值挑战顺序。可以理解为有两列的mysql表,一列存value,一列存顺序。操作key理解为zset的名字
1、zadd:向有序集合zset中添加元素并指定顺序,如果该元素已存在就更新元素顺序。
127.0.0.1:6379> zadd myzset1 1 one
(integer) 1
127.0.0.1:6379> zadd myzset1 2 two
(integer) 1
2、zrange:从zset集合中取元素 [withscores] 输出元素顺序号
127.0.0.1:6379> zadd myzset1 1 one
(integer) 1
127.0.0.1:6379> zadd myzset1 2 two
(integer) 1
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
3、zrem:删除zset集合中指定的元素
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
127.0.0.1:6379> zrem myzset1 two
(integer) 1
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "1"
4、zincrby:若zset中已经存在元素member、则该元素的score增加incrment否则向该集合中添加该元素,其score的值为increment
例:改变myset1中one元素的顺序值
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "1"
127.0.0.1:6379> zincrby myzset1 2 one
"3"
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
5、zrank:正序方式,获取指定元素的索引下标
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
3) "four"
4) "4"
5) "five"
6) "5"
127.0.0.1:6379> zrank myzset1 four
(integer) 1
5、zrevrank:逆序的方式获取指定元素的索引下标,rev--reverse
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
3) "four"
4) "4"
5) "five"
6) "5"
127.0.0.1:6379> zrevrank myzset1 four
(integer) 1
127.0.0.1:6379> zrevrank myzset1 five
(integer) 0
6、zrevrange:从zset集合中倒叙(score倒叙)获取元素
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
3) "four"
4) "4"
5) "five"
6) "5"
127.0.0.1:6379> zrevrange myzset1 0 -1 withscores
1) "five"
2) "5"
3) "four"
4) "4"
5) "one"
6) "3"
8、zrangebyscore:从zset集合中根据score顺序获取元素
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
3) "four"
4) "4"
5) "five"
6) "5"
127.0.0.1:6379> zrangebyscore myzset1 4 5 withscores
1) "four"
2) "4"
3) "five"
4) "5"
9、zcount:返回集合中score在给定区间的数量
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
3) "four"
4) "4"
5) "five"
6) "5"
127.0.0.1:6379> zcount myzset1 3 4
(integer) 2
10:zcard:返回zset集合中所有元素个数
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
3) "four"
4) "4"
5) "five"
6) "5"
127.0.0.1:6379> zcard myzset1
(integer) 3
12、zremrangebyrank:删除集合中排名(下标)在给定区间的元素
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
3) "four"
4) "4"
5) "five"
6) "5"
127.0.0.1:6379> zremrangebyrank myzset1 1 2
(integer) 2
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
12、zremrangebyscore::删除集合中顺序(score值)在给定区间的元素
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "one"
2) "3"
3) "four"
4) "4"
5) "five"
6) "5"
127.0.0.1:6379> zremrangebyscore myzset1 3 4
(integer) 2
127.0.0.1:6379> zrange myzset1 0 -1 withscores
1) "five"
2) "5"
rank是指下标索引:他是从0开始的
score是指分数。
day10
一、Redis事物及乐观锁
1、Redis支持简单的事务
2、Redis与 mysql事务的对比
Mysql
Redis
开启
start transaction
muitl
语句
普通sql
普通命令
失败
rollback 回滚
discard 取消
成功
commit
exec
redis的事务,在用multi开启之后,之后输入的所有命令,其实都是将其添加到一个执行队列中,当使用exec这个命令时,这个队列中的命令就会按顺序执行,使用discard这个命令式,这个队列就会被清空。
注: rollback与discard 作用:
discard和rollback都可以做到回滚。但是dicard其实就是将开启事物后的队列里面的命令清空。rollback是真正的回滚,就是回到开启事务之前的状态。
3、在mutil后面的语句中, 语句出错可能有2种情况:
(1)语法就有问题,此时,在输入命令时,就会报错。
(2)语法本身没错,但适用对象有问题. 比如 zadd 操作list对象,这个命令也会被加入队列。exec之后,出错的那个命令之前的命令是会被执行的

相当于只要事务的所有命令中出现任何语法错误,在exec时都会回滚,所有命令都不会执行。
4、乐观锁
思考:我正在买票,Ticket = 1, money =100,而票只有1张, 如果在我multi之后,和exec之前, 票被别人买了---即ticket变成0了。我该如何观察这种情景,并不再提交。
悲观的想法:
世界充满危险,肯定有人和我抢, 给 ticket上锁, 只有我能操作. [悲观锁]
乐观的想法:
没有那么人和我抢,因此,我只需要注意,有没有人更改ticket的值就可以了 [乐观锁]
Redis的事务中,启用的是乐观锁,只负责监测key没有被改动
具体的命令---- watch命令
redis 127.0.0.1:6379> watch ticket
OK
redis 127.0.0.1:6379> multi
OK
redis 127.0.0.1:6379> decr ticket
QUEUED
redis 127.0.0.1:6379> decrby money 100
QUEUED
redis 127.0.0.1:6379> exec
(nil) // 返回nil,说明监视的ticket已经改变了,事务就取消了.
redis 127.0.0.1:6379> get ticket
"0"
redis 127.0.0.1:6379> get money
"200"
步骤:
创建ticket和money 字符串,分别是1和100
打开两个客户端:一个客户端执行上述代码,另一个客户端在exec之前,更改一下ticket的值。
watch key1 key2 ... keyN
作用:监听key1 key2..keyN有没有变化,如果有变, 则事务取消
unwatch
作用: 取消所有watch监听
二、消息订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:

当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端。

使用办法:
订阅端: Subscribe 频道名称
发布端: publish 频道名称 发布内容
客户端例子:
redis 127.0.0.1:6379> subscribe news
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "news"
3) (integer) 1
1) "message"
2) "news"
3) "good good study"
1) "message"
2) "news"
3) "day day up"
服务端例子:
redis 127.0.0.1:6379> publish news 'good good study'
(integer) 1
redis 127.0.0.1:6379> publish news 'day day up'
(integer) 1
消息的意义:建立客户端之间的通信
client1 :处理计算的第一步
client2:处理计算的第二步
client3:处理计算的最后一步
client1--->将计算结果当成一个消息发送client2
三、Redis持久化配置
redis启动之后,就从硬盘上将所有数据读出来,加载到内存中。
持久化:将内存中的数据保存到硬盘上。
序列化:就对象保存到硬盘上。
redis是一个内存数据库,他最大的特点就是可以将内存的上的数据持久化的硬盘。这是为了保证数据在系统重启或者电脑电源关闭,数据不会被丢失。
当redis启动的启动的时候,他会将硬盘的数据,全部加载到内存,在内存上运行。
redis持久化是通过两种方式来完成的:
RDB快照
日志
(一)RDB快照
Rdb快照的配置选项:
save 900 1 // 900内,有1条写入,则产生快照
save 300 1000 // 如果300秒内有1000次写入,则产生快照
save 60 10000 // 如果60秒内有10000次写入,则产生快照
(这3个选项都屏蔽,则rdb禁用)
和持久化相关的redis配置:
stop-writes-on-bgsave-error yes // 后台备份进程出错时,主进程停不停止写入?
rdbcompression yes // 导出的rdb文件是否压缩
Rdbchecksum yes // 导入rbd恢复时数据时,要不要检验rdb的完整性
dbfilename dump.rdb //导出来的rdb文件名
dir ./ //rdb的放置路径
(二)aof日志
Aof 的配置:
appendonly no # 是否打开 aof日志功能
appendfsync always # 每1个命令,都立即同步到aof. 安全,速度慢
appendfsync everysec # 折衷方案,每秒写1次
appendfsync no # 写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到 aof. 同步频率低,速度快。
no-appendfsync-on-rewrite yes: # 正在导出rdb快照的过程中,要不要停止同步aof
auto-aof-rewrite-percentage 100 #aof文件大小比起上次重写时的大小,增长率100%时,重写
auto-aof-rewrite-min-size 64mb #aof文件,至少超过64M时,重写
两种持久化机制的比较:
RDB持久化
AOF持久化
全量备份,一次保存整个数据库
增量备份,一次保存一个修改数据库的命令
保存的间隔较长
保存的间隔默认一秒
数据还原速度快
数据还原速度一般
更适合数据备份,默认开启
更适合用来保存数据,和一般SQL持久化方式一样,默认关闭
启动优先级 : 低
启动优先级 : 高
体积 : 小
体积 : 大
恢复速度 : 快
恢复速度 : 慢
数据安全性 : 丢数据
数据安全性 : 根据策略决定
(三)redis持久化相关的问题
1、在dump rdb过程中,aof如果停止同步,会不会丢失数据?
答: 不会,所有的操作缓存在内存的队列里, dump完成后,统一操作.
2、aof重写是指什么?
答: aof重写是指把内存中的数据,逆化成命令,写入到.aof日志里。题。以解决 aof日志过大的问。
3、如果rdb文件,和aof文件都存在,优先用谁来恢复数据?
答: 在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件完整。
4、 2种是否可以同时用?
答: 可以,而且推荐这么做
5、恢复时rdb和aof哪个恢复的快
答: rdb快,因为其是数据的内存映射,直接载入到内存,而aof是命令,需要逐条执行
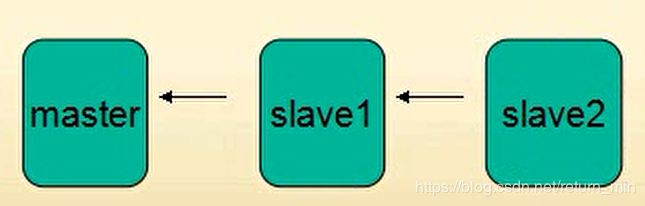
四、Redis主从复制(集群)
1、集群的作用:
主从备份----防止主机宕机
读写分离----分担master 的任务
任务分离----如从服分别分担备份工作与计算工作
集群布局1:

集群布局2:
2、主从通信过程:

步骤:
1,salve会自动的发送一个同步的指令并连接master。
2,master收到同步指令后,会dumprdb(内存镜像),并传送给slave,slave拿到整块的内存镜像塞到自己的内存中。
3,如果在dumprdb的过程中,master中还有新的操作命令对其操作,那么这些命令将会缓存到aof日志中,dump结束后就统一发送给slave。
4,此后,如果master再改变,就由一个叫:replicationFeedSlaves的进程去维护之间数据的同步。
3、主从配置
主服务器:
rdb禁用
#save 900 1
#save 300 10
#save 60 1000
aof打开
appendonly yes
从服务器:
设置端口
port 6380
有一台启用rdb
两台都禁用aof
设置slave-of
slaveof localhost 6379
redis-server redis.windows.conf --maxheap 200m
redis-server redis.windows6380.conf --maxheap 200m
redis-server redis.windows6381.conf --maxheap 200m
启动客户端:
redis-cli
redis-cli -p 6380
redis-cli -p 6381
配置如下:
1、服务关闭
2、复制两个配置文件,名字如下:

3、该端口号
4、主机配置更改:
禁用rdb
打开aof




5、配置从机
6380—启用rdb
两台都禁用aof
两台都要配置
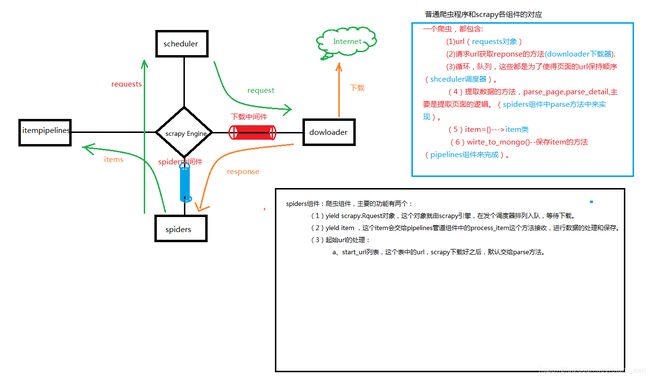
day11 scrapy
- 创建项目 Scrapy startproject [项目名]

将创建好的项目拖到pycharm中,目录结构如下:

2、创建spiders,爬虫文件。
3、打开spider文件。将待爬取的url放到start_urls中。
Spider文件的主要内容如下:
4、更改settings.py中的配置。
(1)Scrapy默认是遵守robots,将rotbos协议改为False
(2)设置下载的请求头。
5、在parse方法中,验证response中是否有数据。
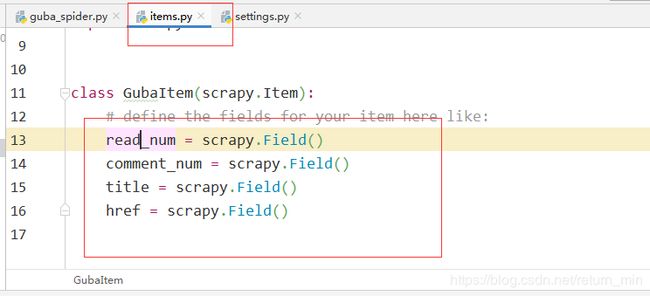
6、在item.py中定义要爬取的字段。
7、在parse方法中实现数据提取逻辑。
Response有xpath方法
[Selector对象]= Response.xpath(‘xpath表达式’)
从selector对象汇总提取字符串的方法有两个:
Extract()----从一个列表中提取每个selector对象的内容
Extract_first()—提取出列表中获取第一个selector对象的内容。
提取样板:
8、可以通过命令直接将爬取的保存到对应文件中。
首先:
保存到json文件:
保存到csv文件
Scrapy crawl guba_spider -o guba.csv
Last、启动scrapy项目
Scrapy crawl spider文件的name属性
如果不想查看配置信息,增加一个–nolog参数








day11
1、客户端启动和服务端开启命令:
mongod 服务端
--dbpath
--port
--logpath
mongo 客户端
--port
--host
2、基础命令:
show dbs
show collections
show tables
如何创建库?
1、use 数据库名
2、添加一条数据
db.collectionName.insert({文档})
db.createCollection(name)
删除数据库:db.dropDatabase()
删除集合:db.collectionName.drop()
3、CRUD
(1)insert---插入
db.collectionName.insert({文档})
插入多条文档:
db.collectionName.insert([{文档1},{文档2},{文档3},....])
(2)查找--find
db.collectionName.find({查询表达式},{field1:1/0}) --1显示,0不显示
查询表达式:
= {key:value}
< $lt
> $gt
<= $lte
>= $gte
!= $ne
{$nin:{age:[1,2,3]}} 查询不在数组中的数据
{$in:{age:[12,13,14]} 查询在数组中的数据
{$all:{hobby:['a','b','c']}} 满足数组中的所有内容的条件
{$mod:{age:[5,1]}
{$and:[{},{},{}]}
{$or:[{},{},{}]}
{$nor:[{},{},{}]}
(3)聚合
db.collectionName.aggregate([{管道1},{管道2},{管道3}])
{$match:{查询表达式}}
{$group:{_id:'$field',avg/sum/max/min:{$avg/$sum/$max/$min:1/'$field'}}}
(4)游标
将查询结果赋值给一个变量,这个标量就是游标,游标就相当于python中迭代器,我们可以从中一个一个取出查询结果。
var cursor = db.collectionName.find()
cursor.hasNext()---是否有下一个(如果游标到结尾,才为false)
cursor.next()---获取下一个。
cursor.forEach(回调函数)
作用:回调函数接收游标中每一个查询结果,并做批量操作。
(5)hash
(1)什么是hash。
Hash :散列,通过关于键值(key)的函数,将数据映射到内存存储中一个位置来访问。这个过程叫做Hash
(2)特点:
正向快速
逆向困难
输入敏感
冲突避免
(3)作用:
给数据打指纹---指纹就是唯一标识--->去除重复
密码存储
(4)什么叫hash碰撞?
(5)字符串加密和文件加密?
第10天作业
1、作业
将下面的项目改装到scrapy框架中:
笔趣阁项目
2、爬取瓜子二手车车辆信息
url :https://www.guazi.com/bj/buy/
要求
1.先获取区域列表,然后在区域列表下获取每一页的车辆信息
2、爬取字段:
列表页字段:
名称
价格
里程数
详情页链接
详情页字段:
排量
上牌时间
产商
驱动方式
发动机型号
3、完成3个版本的代码
(1)简单py文件
(2)类
(3)多线程
选做:用scrapy实现
4、数据保存到mongodb中。
day12 增量爬虫
一、增量爬虫
1、定义:通过更改爬取策略,使得爬取到数据库的数据增量式增长的一种爬虫程序。
2、策略:
(1)在发送请求之前判断这个URL是不是之前爬取过;
用redis去重
(2)在解析内容后判断这部分内容是不是之前爬取过
用redis去重
def response_seen(response.text)
(3)写入存储介质时判断内容是不是已经在介质中存在分析
用update方法
这三个策略的本质---->判重。
3、判重的方法:
1、python中的set来判重吗?
缺点:
set的add操作没有返回值,无法找到到底add成功了没有。
set是运行内存上的,当前程序一旦关闭,这个set就会请求,下载启动爬虫,set又会重新创建,无法记录上次爬取的内容。
2、用文件保存:
非常麻烦
list_ = ['abcdef','abcdefg','abcdef']
fp_w = open('demo.txt','a+',encoding='utf-8')
for l in list_:
fp_w.write(l+'\n')
fp_r = open('demo.txt','r')
a = [x for x in fp_r]
if 'abcdefg\n' in a:
print('yes')
3、redis中的set---效果最好
步骤:
(1)写一个获取数据hash指纹的方法
def get_md5():
pass
(2)在redis中用set来添加数据,
sadd s1 name ---->成功返回1,不成功返回0
def url_seen(url):
re = redis.Redis()
result = re.sadd('set的名称',get_md5(url))
return 0==result
二、scrapy-redis分布式
1、什么分布式?
分布式数据库:将数据库部署在多台计算机上,多台计算机组成一个系统,这个系统就是分布式数据库。
分布式出现的原因:原来有单台电脑完成的任务已经无法达到我们想要性能要求了,所以就想到是否可以用多台电脑,通过扩展硬件的方式来提高性能。
2、scrapy-redis的分布式原理。
见图
3、scrapy-redis安装
pip install scrapy-redis
4、scrapy分布式项目部署。
(1)主要配置如下:
#配置scrapy-redis调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#配置url去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#配置优先级队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
ITEM_PIPELINES = {
#如果配置redispipelines,就会将item数据保存到redis中。
'scrapy_redis.pipelines.RedisPipeline': 300
}
#主机名
REDIS_HOST = 'localhost'
##端口号
REDIS_PORT = 6379
(2)部署流程:
1、导入from scrapy_redis import spiders包
spiders继承spiders.RedisSpider
2、start_urls注释掉,设置redis_key = 'picture_caixi:start_urls'
redis-key就表示将来scrapy启动,会去这个key所指定的redis的list中取任务url。
3、添加配置:
这三条主机和从机都要添加
#配置scrapy-redis调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#配置url去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#配置优先级队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
##端口号
REDIS_PORT = 6379
MONGO_DATABASE = 'caixi'
主机:
#主机名
REDIS_HOST = 'localhost'
MONGO_URI = 'localhost'
从机里面: 10.10.92.157
REDIS_HOST = '目标主机的ip'
MONGO_URI = '目标主机的ip'
在启动scrapy-redis分布式项目之前,一定要远程连接一个主机的mongo和redis
day13
xml的名词

并发和并行
产生死锁的条件
代理服务器
递归
生产者和消费者
数组
同步请求和异步请求
网易云思路
线程的五种状态









MONGOOB图片
btree索引和hash索引
hash
mongodb存储数据的过程
noql数据库的应用
redis持久化机制
redis数据结构
scrapy框架图
迭代器
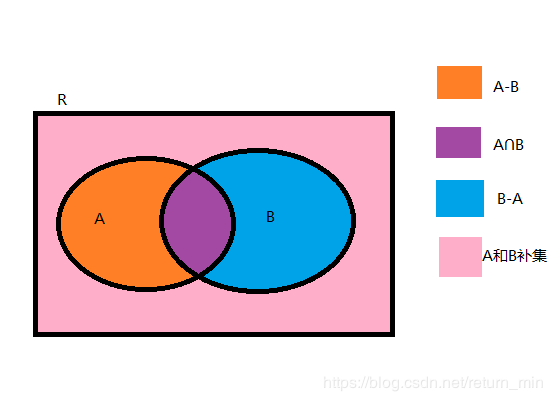
交集并集和补集
数据结构
组合索引