理论基础 —— 二叉树 —— 哈夫曼树与哈夫曼编码
【哈夫曼树】
1.相关概念
1)叶结点的权值:对叶结点赋予的一个有意义的数值量
2)二叉树的带权路径长度(WPL):设二叉树具有 n 个带权叶结点,从根结点到各叶结点的路径长度与相应叶节点权值的乘积之和
即: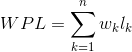 ,其中 Wk 为第 k 个叶结点的权值,Lk 为从根结点到第 k 个叶结点的路径长度
,其中 Wk 为第 k 个叶结点的权值,Lk 为从根结点到第 k 个叶结点的路径长度
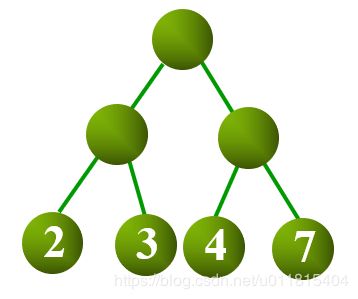
如图所示,WPL=2*2+3*2+4*2+7*2=4+6+8+14=32
3)哈夫曼树:给定一组具有确定权值的叶结点,可以构造出不同的二叉树,其中 WPL 最小的二叉树称为哈夫曼树。
2.哈夫曼树特点
1)权值越小,离根越远;权值越大,离根越近。
2)只有度为 0 的叶结点和度为 2 的分支结点,不存在度为 1 的结点
3.哈夫曼算法
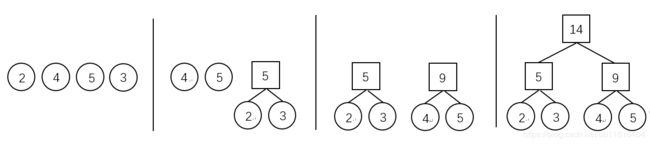
1)初始化:由给定的 n 个权值构造 n 棵只有一个根节点的二叉树,得到一个二叉树集合 F
2)选取与合并:从二叉树集合 F 中选取根节点权值最小的两棵二叉树分别作为左右子树构造一棵新的二叉树,这棵新二叉树的根节点的权值为其左、右子树根结点的权值和
3)删除与加入:从 F 中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到 F 中
4)重复 2)、3) 步,当集合中只剩下一棵二叉树时,这棵二叉树就是哈夫曼树
4.计算WPL
给出 n 个叶结点的权值,计算构成哈夫曼树的 WPL
int main() {
int n;
cin>>n;
priority_queue,greater > huffman;
for(int i=1;i<=n;i++){
int x;
cin>>x;
huffman.push(x);
}
int res=0;
for(int i=1;i 【哈夫曼编码】
1.编码
在进行程序设计时,通常给每一个字符标记一个单独的代码来表示一组字符,即编码。
在进行二进制编码时,假设所有的代码都等长,那么表示 n 个不同的字符需要 ![]() 位,这称为等长编码。
位,这称为等长编码。
如果每个字符的使用频率相等,那么等长编码无疑是空间效率最高的编码方法,而如果字符出现的频率不同,则可以让频率高的字符采用尽可能短的编码,频率低的字符采用尽可能长的编码,来构造出一种不等长编码,从而获得更好的空间效率。
在设计不等长编码时,要考虑解码的唯一性,如果一组编码中任一编码都不是其他任何一个编码的前缀,那么称这组编码为前缀编码,其保证了编码被解码时的唯一性。
2.哈夫曼编码
哈夫曼树可用于构造最短的前缀编码方案,即哈夫曼编码,具体做法如下:
1)设需要编码的字符集为:![]() ,他们在字符串中出现的频率为:
,他们在字符串中出现的频率为:![]()
2)以 ![]() 作为叶结点,
作为叶结点,![]() 作为叶结点的权值,构造一棵哈夫曼树
作为叶结点的权值,构造一棵哈夫曼树
3)规定哈夫曼编码树的左分支代表 0,右分支代表 1,则从根结点到每个叶结点所经过的路径组成的 0、1 序列即为该叶结点对应字符的编码

3.实现
struct Node{
int weight;
Node *lchild,*rchild;
};
typedef Node *tree;
tree create(int arr[],int n){
tree forest[N];
tree root=NULL;
for (int i=0; iweight = arr[i];
temp->lchild = temp->rchild = NULL;
forest[i]=temp;
}
for(int i=1; iweight < forest[minn]->weight){
minnSub=minn;
minn=j;
}
else if(forest[j]->weight < forest[minnSub]->weight){
minnSub=j;
}
}
}
//建新树
root = (tree)malloc(sizeof(Node));
root->weight = forest[minn]->weight + forest[minnSub]->weight;
root->lchild = forest[minn];
root->rchild = forest[minnSub];
forest[minn]=root;//指向新树的指针赋给minn位置
forest[minnSub]=NULL;//minnSub位置为空
}
return root;
}
int getWPL(tree &root,int len){//计算哈夫曼树带权路径长度WPL
if(root==NULL)
return 0;
else {
if(root->lchild==NULL&&root->rchild==NULL)//叶节点
return root->weight*len;
else
return getWPL(root->lchild,len+1)+getWPL(root->rchild,len+1);
}
}
void HuffmanCoding(tree &root,int len,int arr[]){//哈夫曼树编码
if(root!=NULL){
if(root->lchild==NULL&&root->rchild==NULL){
printf("结点为%d的字符的编码为: ",root->weight);
for(int i=0;ilchild,len+1,arr);
arr[len]=1;
HuffmanCoding(root->rchild,len+1,arr);
}
}
}
int main(){
int n=6;//长度
int arr[]={3,9,5,12,6,15};//权值
tree root=create(arr,n);
int WPL=getWPL(root,0);
printf("WPL=%d\n",WPL);
printf("==========各节点的哈夫曼树编码==========\n");
HuffmanCoding(root,0,arr);
return 0;
}