链路技术(HCNA)——链路聚合
目录
链路聚合
链路聚合的基本概念
链路聚合技术
链路聚合技术的适用场景
链路聚合的基本原理
链路聚合
链路聚合的基本概念
首先,我们澄清一些常见的说法。大家可能经常听到这样一些说法,例如:标准以太网,FE端口,百兆口,GE端口,千兆口如此等等。那么,这些说法究竟是什么意思呢?
其实,这些说法都是跟以太网技术的规范有关,特别是跟以太网的信息传输率规范有关。IEEE在制定关于以太网的信息传输率的规范时,信息传输率几乎总是按照十倍关系来递增的。目前,规范化的以太网的信息传输率主要有:10Mbit/s,100Mbit/s,1000Mbit/s(1Gbit/s),10Gbit/s,100Gbit/s。这种按十倍关系递增的方式既能很好的匹配微电子技术及光学技术的发展,又能控制关于以太网信息传输率规范的散乱性。
下面是对一些常见说法的澄清。
(1)发送/接收速率为10Mbit/s的以太网端口常被称为标准以太网端口,或标准以太口, 或10兆以太网端口,或10兆以太口,或10M以太网端口,或10M以太口,或10M 口。
(2)发送/接收速率为100Mbit/s的以太网端口常被称为快速以太网端口,或快速以 太口,或100兆以太网端口,或100兆以太口,或100M以太网端口,或100M以太口, 或 FE 端口,或 FED (注:FE 是 Fast Ethernet 的简称)。
(3)发送/接收速率为1000Mbit/s的以太网端口常被称为千兆以太网端口,或千兆以 太口,或千兆口,或吉比特端口,或吉比特口,或GE端口,或GE 口(注:GE是Gigabit Ethernet 的简称)。
(4)发送/接收速率为10Gbit/s的以太网端口常被称为万兆以太网端口,或万兆以太 口,或万兆口,或10GE端口,或10GE 口。
(5)发送/接收速率为100Gbit/s的以太网端口常被称为100GE端口,或100GE口。
以太网链路的说法是与以太网端口的说法相对应的。例如,如果一条链路两端的端 口是GE 口,则这条链路就称为一条GE链路;如果一条链路两端的端口是FE 口,则这 条链路就称为一条FE链路,如此等等。
链路聚合技术
现在说说什么是链路聚合技术。如图所示某个公司的网络结构,交换机S1接入了10个用户,每个用户都通过一条FE链路与S1相连,S1与核心交换机S2之间的链路是一条GE链路。显然,在这种情况下,S1与S2之间的GE链路是不会发生流量拥塞的。但是,当网络扩建后,S1接入的用户增加到了20,如果S1与S2之间仍然只采用GE链路,则这条GE链路上就可能出现流量拥塞的情况(因为现在用户带宽的总需求为2G,但是一条GE链路只能提供最多1G的带宽)。

某公司的网络结构
想要解决这个问题,我们可以将S1与S2之间的链路更换一条10GE链路,但是这需要S1和S2上都有10GE端口。如果S1或者S2上没有10GE端口,或者根本不支持10GE端口,那么就需要更换交换机了。总的来说,这种方法的成本较大,并且10G的带宽相对与2G的需求来说,实在是富于太多,一定程度上造成了带宽的浪费。还有的是,S1与S2之间如果只有一条链路存在的话,网络的可靠性也会面临很大的威胁。一旦这条链路发生了中断,则所有的用户将完全无法访问Internet。
针对以上的问题,一个既能满足带宽需求,又能节省成本,而且还能提高S1与S2连接可靠性的方法便是采用链路聚合技术。例如,如下图所示,我们可以在S1和S2之间使用3条GE链路(当然,S1和S2上都至少需要有3个GE端口),然后通过链路聚合技术,将这3条GE链路整合(这里的整合是指逻辑意义上的整合)成为一条最大带宽可达3G的逻辑链路(相应的,交换机上的3个GE端口也被整合成为一个逻辑端口)。一方面,这条逻辑链路可以满足2G的带宽需求,另一方面,当某条GE链路发生故障而中断之后,这条逻辑链路仍然存在,只是能够提供的带宽值有所下降,但是不会导致所有的用户完全不能访问Internet的糟糕情况。
简而言之,利用链路聚合技术,我们可以:
(1)根据需要灵活的增加网络设备之间的带宽供给。
(2)增强网络设备之间连接的可靠性。
(3)节约成本。

链路聚合
链路聚合技术的适用场景
链路聚合也称为链路绑定,英文的说法有:Link Aggregation、Link Trunking、Link Bonding。需要说明的是,这里所说的链路聚合技术,针对的都是以太网链路。
上面的例子中,我们是将链路聚合技术应用到在两台交换机之间。事实上,链路聚合技术还可以应用到交换机和路由器之间,路由器与路由器之间,交换机与服务器之间,路由器与服务器之间,服务器与服务器之间。如图所示,注意,从理论上讲,个人计算机(PC)上也是可以实现链路聚合的,但是实际上考虑到成本等等因素,没人会在现实中去真正实现。另外,从原理性角度来看,服务器的地位是非常重要的,我们必须保证服务器与其设备之间的连接具有非常高的可靠性。因此,服务器上经常需要用到链路聚合技术。

链路聚合技术的适用场景
链路聚合的基本原理
如图所示中我们可以看到,总共有N条物理链路被聚合成了一条逻辑链路。通常,我们把我们把聚合后得到的逻辑链路称为聚合链路,而把聚合链路中的每一条物 理链路称为成员链路。相应地,我们把聚合后得到的逻辑端口称为聚合端口,而把聚合端口中的每一个物理端口称为成员端口。另外,聚合链路也称为Eth-Trunk链路(注: 其中的Eth是Ethernet的简写),聚合端口也称为Eth-Trunk端口。
需要说明的是,虽然从理论上讲,同一聚合链路中的各成员链路的带宽可以是不相同的, 但在实际中,由于实现难度和实现成本等方面的原因,我们总是要求各成员链路的带宽保持 一致。在以下的分析和描述中,我们假定同一聚合链路中各成员链路的带宽总是相同的。

两台交换机之间的链路聚合
现在,我们来看看交换机A是如何利用自己的Eth-Trunk端口向交换机B的Eth-Trunk端口发送帧的,如图所示,首先,来自交换机A的其他端口的帧进入到 Eth-Trunk端口的帧发送队列。然后,Eth-Trunk端口的帧分发器(Frame Distributor, FD) 将这些帧按照某种算法依次分发给成员端口。FD的分发顺序为:先将Frame a分发给某 个成员端口,再将Frame b分发给某个成员端口,再将Frame c分发给某个成员端口, 以此类推。最后,每个成员端口会按照常规方式将来自FC的帧发送到自己的物理链路 上去。注意,图中没有显示出Eth-Trunk端口的帧收集器(Frame Collector, FC) 和帧接收队列。显然,如果FD能够足够均匀地将帧分发给不同的成员端口,那么 Eth-Trunk端口的带宽就等于各成员端口带宽的总和,相应地,Eth-Trunk链路的带宽就 等于各成员链路带宽的总和。然而,在实际实现中,FD对帧的分发不可能那么均匀, 所以Eth-Trunk链路实际能够提供的最大带宽一般会小于各成员链路带宽的总和。
我们再来看看交换机B是如何利用自己的Eth-Trunk端口接收来自交换机A的 Eth-Trunk端口发送的帧的,如图所示。首先,每个成员端口会按照常规方式接收 来自物理链路上的帧,接收到的帧都会被送往Eth-Trunk端口的帧收集器(Frame Collector, FC)。某一个帧完全进入FC后(注:所谓“完全进入”,是指这个帧的末尾 都己经进入了 FC), FC就会把它送往Eth-Trunk端口的帧接收队列。图10-6显示,最先 完全进入FC的帧是Frame a,其次是Frame b,再其次是Frame c,如此等等。最后,Eth-Trunk端口的帧接收队列中的帧会被依次送往交换机B的其他端口。注意,图10-6 中没有显示出Eth-Trunk端口的帧分发器(Frame Distributor, FD)和帧发送队列。
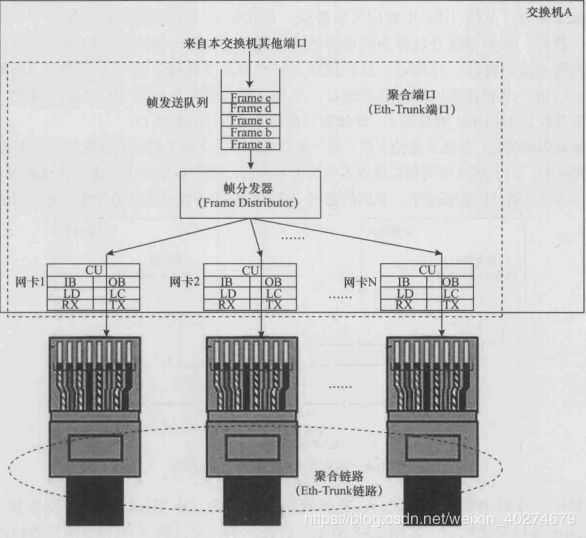
交换机A通过聚合端口发送帧
从上面的描述中我们可以看到,链路聚合的基本原理其实就是“流量分担"原理: 多条成员链路共同分担了聚合链路的总流量。另外,如果聚合链路中的某条成员链路发 生了故障而中断,则聚合链路的总流量会继续被其他成员链路来分担(或者说,本该由 故障链路分担的流量将会被FD转移给其他的成员链路)。
链路聚合技术看似非常简单,其实并非如此。链路聚合技术需要面临的一个主要问 题是“乱序”问题。我们先来说明一下什么是乱序问题。
如图所示,交换机A的帧发送队列中,帧的先后排列顺序是:a、b、c、d、e。 假设FD将Frame a分发给了成员链路1.将Frame b分发给了成员链路2,将Frame c分发 给了成员链路3,将Frame d分发给了成员链路1,将Frame e分发给了成员链路1。再假 设Frame a是一个长度较长的帧,而Frame b和Frame c都是长度较短的帧。由于Frame b 和Frame c的长度较短,所以它们需要的传输时间也就较短,而Frame a需要的传输时间相 对较长。这样一来,就完全可能会出现这样的情况:Frame b最先完全进入交换机B的FC, 然后是Frame c,然后是Frame a,然后是Frame d,然后是Frame e«最后,这些帧在交换 机B的帧接收队列中的排序就成了: b、c、a、d、e。显然,交换机B的帧接收队列中帧的排列不同于它们在交换机A的帧发送队列中的排序,这种现象就称为帧的乱序现象。

交换机B通过聚合端口接收帧

链路聚合过程中的乱序现象
乱序现象又分两种情况,一种是“有害”的乱序,另一种是“无害”的乱序。我们 先来看看什么是有害乱序。
如图所示,PC 1和PC 3上运行了某个网络应用程序X (假定X的传输层协议 是UDP协议)。为此,PC 1向PC 3发送了两个单播帧XI和X2 (XI先发送,X2后发 送)。同时,PC 2和PC 4上运行了某个网络应用程序Y (假定Y的传输层协议是UDP 协议)。为此,PC 2向PC 4发送了两个单播帧Y1和Y2 (Y1先发送,Y2后发送)。交 换机A的Eth-Trunk端口的帧发送队列中,帧的先后顺序是:XI、Yl、X2、Y2»假设 交换机A的FD将XI分发给了成员链路1,将Y1分发给了成员链路2,将X2分发给 了成员链路2,将Y2分发给了成员链路2,并且,XI是一个长度较长的帧,Y1和X2 都是比较短的帧,那么交换机B的帧接收队列中的排序就有可能是:Yl、X2、XI、Y2o 也就是说,交换机B的帧接收队列中发生了乱序现象。由于B的帧接收队列中的排序是: Yl、X2、XI、Y2,这必然会导致PC 3会先收到X2,后收到XI。我们知道,当初PC 1 是先发的XI,后发的X2,但到达PC 3时顺序却发生了改变。显然,这种改变必然会或 多或少地有害于网络应用程序X。也就是说,在这个例子中,交换机B的帧接收队列中 发生的乱序现象是一种有害乱序。
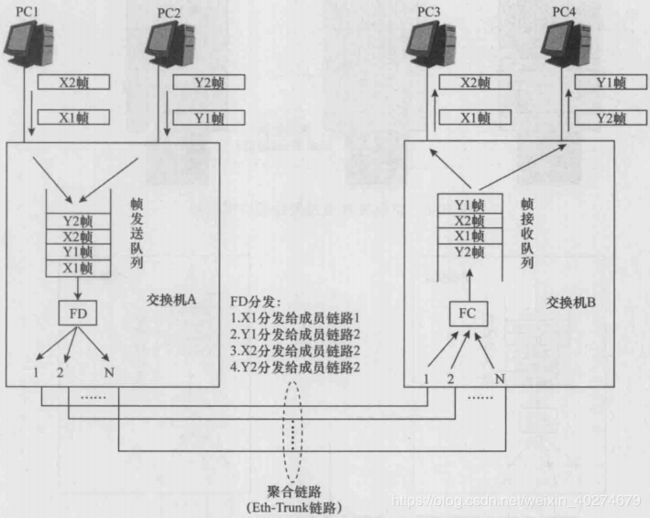
有害乱序现象举例
我们再来看看什么是无害乱序。如图10-9所示,在这个例子中,除了交换机A的FD的分发情况有所变化外,其他的各种条件都假定跟图中的例子完全一样。这一次,FD的分发情况是:将XI分发给了成员链路1,将Y1分发给了成员链路2,将X2分发给了成员链路1,将Y2分发给了成员链路2。由于XI是一个较长的帧,所以需要 的传输时间较长,所以Y1最先进入了交换机B的FC。接着,Y2也进入了交换机B的 FC。然后,XI才进入交换机B的FC,最后是X2 (注意,X2不可能比XI先进入交换 机B的FOo虽然,与交换机A的帧发送队列中的顺序相比,交换机B的接收队列中 的帧排列顺序已经发生了改变,但是这种改变并不会影响到上层应用。从图10-9中我们 可以看到,PC3先收到XI,后收到X2; PC4先收到Y1,后收到Y2。也就是说,在这 个例子中,交换机B的帧接收队列中发生的乱序现象是一种无害乱序。
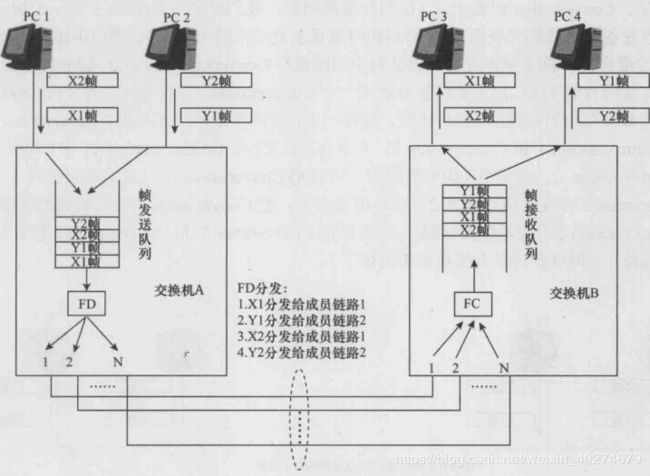
无害乱序现象举例
在明白了什么是有害乱序现象和什么是无害乱序现象后,我们来进行一个简要的总 结。聚合链路在工作过程中,由于帧的长度有长有短,于是帧的传输时间就有长有短, 而不同的帧所经过的成员链路又可能不同,所以一般情况下总是会出现乱序现象。我们 无法避免乱序现象,但我们必须避免有害乱序现象。
是否能避免有害乱序现象,关键是看聚合端口的FD是如何将帧分发给不同的成员端口 的。为此,人们引入了 Conversation这个概念。一个Conversation,是指由若干个帧组成的 一个集合,该集合中的不同的帧在接收端的聚合端口的帧接收队列中的先后顺序必须与它们 在发送端的聚合端口的帧发送队列中的先后顺序保持一致。如果保持了一致,则一定不会发 生有害乱序现象;如果没有保持一致,则一定会发生有害乱序现象。需要强调的是,不同的 Conversation之间的交集必须是空集。也就是说,同一个帧,不能既属于这个Conversation, 又属于另外一个Conversation0还有就是,一个帧不能不属于任何Conversation«
为了避免有害乱序现象的产生,同时又能实现流量分担,聚合端口的FD必须遵从 如下的分发原则。
(1)同一个Conversation中的帧,必须被分发给同一条成员链路(这样就避免了有 害乱序现象)。
(2)不同Conversation中的帧,可以被分发给同一条成员链路,也可以被分发给不 同的成员链路(这样就实现了流量分担)。
从上述FD的分发原则来看,同一个Conversation中的帧是不会乱序的,这就避免 了有害乱序现象的产生。另一方面,不同Conversation中的帧是有可能会乱序的,但这 种乱序只是无害乱序。
有了 Conversation的概念及FD的分发原则后,我们再来看看图10-9所示的例子。 为了方便起见,我们先将之前图所示的网络重新显示在下图中。下图中,交换 机A的聚合端口首先应该对帧发送队列中的帧进行Conversation的划分,划分的方法是: 把具有相同目的MAC地址的帧划分进同一个Conversation,且保证同一个Conversation 中的帧都具有相同的目的MAC地址。这样一来,就产生了两个不同的Conversation,分 别为 Conversation 1 和 Conversation 2,并且 XI 和 X2 属于 Conversation 1, Y1 和 Y2 属 于Conversation 2。根据FD的分发原则,可以把Conversation 1分发给成员链路1,把 Conversation 2分发给成员链路2;也可以反过来,把Conversation 1分发给成员链路2, 把Conversation 2分发给成员链路1;还可以把Conversation 1和Conversation 2都分发给 成员链路1 (但这样就没有流量分担效果了)。

属于同一个Conversation的帧必须分发给同一条成员链路
关于聚合端口的FD的分发原则,在下图显示了一种更为普遍的情况。在图中,如果成员链路4发生了中断,则FD会将Conversation 5分发给成员端口 2,将 Conversation 6分发给成员端口 3。
在实际实现链路聚合时,聚合链路的FD需要根据一种HASH算法来定义出恰当的 Conversation,然后再对不同的Conversation进行分发。定义出恰当的Conversation并不 是一件容易的事情。在图所示的例子中,帧的目的MAC地址被选择成为了用来 定义Conversation的参考量。然而,在实际的网络环境中,聚合链路两端的设备属性(例如,交换机跟交换机聚合,路由器跟路由器聚合,服务器跟服务器聚合,交换机跟路由 器聚合,交换机跟服务器聚合,如此等等)以及上层应用的属性,都需要成 为确定Conversation的参考量的考虑因素,而最终的参考量可能是目的MAC地址,也 可能是源MAC地址,也可能是目的IP地址,也可能是源IP地址,也可能是几种不同 地址的组合,还可能是上层协议中的某些参数,如此等等。

(本篇内容作为了解,只要了解链路聚合的含义、为何实现、有什么痛点这些,感兴趣的童鞋可以深入了解。)