案例五:摩拜单车停放点(聚类分析)
摩拜单车停放点
- 案例背景
- 数据预处理
- DBSCAN
- 要求
- 模型参数
- 寻找DBSCAN的eps参数
- 进行聚类
- KMEANS
- 要求
- 模型建立
- 画图
- 类中心
- 数量最多的十个类中心点
案例背景
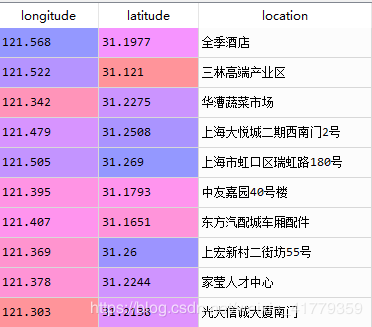
数据集 mobike 给出了上海市某日 27 万辆摩拜单车的实时位置(经纬度),请利用聚类分析找到由摩拜单车用户自发形成的单车停放点,其中停放点定义为在某一区域内停放的摩拜单车超过 50 辆。
数据预处理
- 导入库
import pandas as pd
import numpy as np
import os
from sklearn.cluster import KMeans
from sklearn import cluster
from sklearn import metrics
from sklearn.neighbors import NearestNeighbors
import matplotlib.pyplot as plt
- 读取数据
df=pd.read_csv('mobike.csv',header=None)
- 增加列名
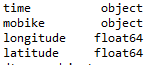
df.columns=['time','mobike','longitude','latitude']
- 每列的数据类型
df.dtypes
- 处理缺失值
- 查看缺失值情况
df.isna().sum()

DBSCAN
要求
请利用 DBSCAN 聚类,结合 DBI 指数确定单车停放点数量
模型参数
cluster.DBSCAN().get_params()
{‘algorithm’: ‘auto’,
‘eps’: 0.5,
‘leaf_size’: 30,
‘metric’: ‘euclidean’,
‘metric_params’: None,
‘min_samples’: 5,
‘n_jobs’: None,
‘p’: None}
寻找DBSCAN的eps参数
- 将原始数据的经度和维度提取出来
data=df.loc[:,['longitude','latitude']]
- 画出每个点附近距离第50个点的距离
nbrs=NearestNeighbors(n_neighbors=50).fit(data) #找到距离最近的50个点
distances,indices=nbrs.kneighbors(data) #计算每个点最近的50个点的距离
dist=distances[:,49]
dist_=np.sort(dist)
plt.plot(dist_)
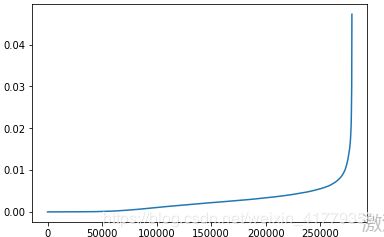
拐点大概在0.005的位置
进行聚类
mdl_dbscan=cluster.DBSCAN(eps=0.004,min_samples=50).fit(data)
count=pd.Series(mdl_dbscan.labels_).value_counts() #展示有多少类,每类有多少个样本
plt.figure()
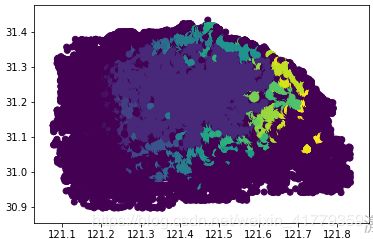
plt.scatter(x='longitude',y='latitude',data=data,c=mdl_dbscan.labels_)
print(metrics.davies_bouldin_score(data,mdl_dbscan.labels_))
DBI=1.441
停放点数量:165

KMEANS
要求
在上一题得到的停放点数量基础上,使用 kmeans 算法重新对数据集进行聚类,计算每个停放点的单车数量。
模型建立
from sklearn.cluster import KMeans
mdl_kmeans=KMeans(n_clusters=165).fit(data)
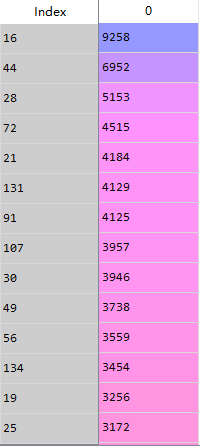
- 统计每个类的个数
count2=pd.Series(mdl_kmeans.labels_).value_counts()
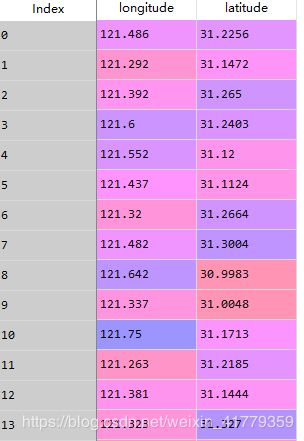
- 每个类中的坐标
km_centor=pd.DataFrame(mdl_kmeans.cluster_centers_,columns=['longitude','latitude'])
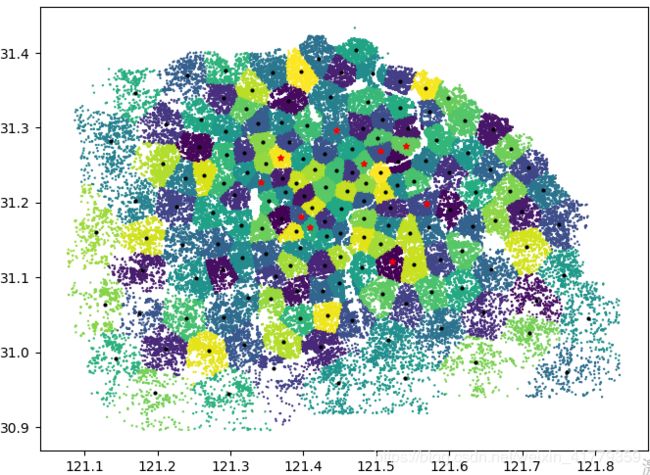
画图
plt.rcParams['savefig.dpi']=300 #像素
plt.rcParams['figure.dpi'] = 100 #分辨率
plt.rcParams['figure.figsize']=(8.0,6.0) #图片大小比例
plt.figure()
plt.scatter(x='longitude',y='latitude',data=data,c=mdl_kmeans.labels_ ,s=0.5)
plt.scatter(x='longitude',y='latitude',data=km_centor,c='k',s=4)
plt.scatter(x='longitude',y='latitude',data=center_10_cordinate,c='r',marker='*',s=20)
plt.savefig('mobike.png')
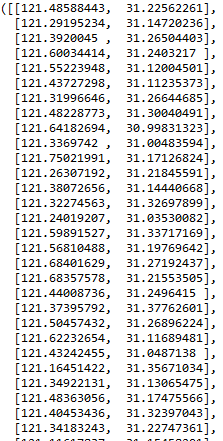
类中心
mdl_kmeans.cluster_centers_
数量最多的十个类中心点
center_10=list(count2.index[:10])
center_10_cordinate=[]
for index in center_10:
cordinate=mdl_kmeans.cluster_centers_[index]
print(cordinate)
center_10_cordinate.append(cordinate)