云函数 SCF 与对象存储实现 WordCount 算法
本文将尝试通过 MapReduce 模型实现一个简单的 WordCount 算法,区别于传统使用 Hadoop 等大数据框架,本文使用云函数 SCF 与对象存储 COS 来实现。
MapReduce 在维基百科中的解释如下:
MapReduce 是 Google 提出的一个软件架构,用于大规模数据集(大于 1TB)的并行运算。概念「Map(映射)」和「Reduce(归纳)」,及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
通过这段描述,我们知道,MapReduce 是面向大数据并行处理的计算模型、框架和平台,在传统学习中,通常会在 Hadoop 等分布式框架下进行 MapReduce 相关工作,随着云计算的逐渐发展,各个云厂商也都先后推出了在线的 MapReduce 业务。
理论基础
在开始之前,我们根据 MapReduce 的要求,先绘制一个简单的流程图:
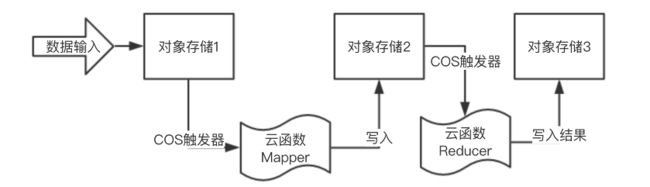
在这个结构中,我们需要 2 个云函数分别作 Mapper 和 Reducer;以及 3 个对象存储的存储桶,分别作为输入的存储桶、中间临时缓存存储桶和结果存储桶。在实例前,由于我们的函数即将部署在广州区,因此在广州区建立 3 个存储桶:
对象存储1 ap-guangzhou srcmr
对象存储2 ap-guangzhou middlestagebucket
对象存储3 ap-guangzhou destcmr为了让整个 Mapper 和 Reducer 逻辑更加清晰,在开始之前先对传统的 WordCount 结构进行改造,使其更加适合云函数,同时合理分配 Mapper 和 Reducer 的工作:

功能实现
编写 Mapper 相关逻辑,代码如下:
# -*- coding: utf8 -*-
import datetime
from qcloud_cos_v5 import CosConfig
from qcloud_cos_v5 import CosS3Client
from qcloud_cos_v5 import CosServiceError
import re
import os
import sys
import logging
logging.basicConfig(level=logging.INFO, stream=sys.stdout)
logger = logging.getLogger()
logger.setLevel(level=logging.INFO)
region = u'ap-guangzhou' # 根据实际情况,修改地域
middle_stage_bucket = 'middlestagebucket' # 根据实际情况,修改bucket名
def delete_file_folder(src):
if os.path.isfile(src):
try:
os.remove(src)
except:
pass
elif os.path.isdir(src):
for item in os.listdir(src):
itemsrc = os.path.join(src, item)
delete_file_folder(itemsrc)
try:
os.rmdir(src)
except:
pass
def download_file(cos_client, bucket, key, download_path):
logger.info("Get from [%s] to download file [%s]" % (bucket, key))
try:
response = cos_client.get_object(Bucket=bucket, Key=key, )
response['Body'].get_stream_to_file(download_path)
except CosServiceError as e:
print(e.get_error_code())
print(e.get_error_msg())
return -1
return 0
def upload_file(cos_client, bucket, key, local_file_path):
logger.info("Start to upload file to cos")
try:
response = cos_client.put_object_from_local_file(
Bucket=bucket,
LocalFilePath=local_file_path,
Key='{}'.format(key))
except CosServiceError as e:
print(e.get_error_code())
print(e.get_error_msg())
return -1
logger.info("Upload data map file [%s] Success" % key)
return 0
def do_mapping(cos_client, bucket, key, middle_stage_bucket, middle_file_key):
src_file_path = u'/tmp/' + key.split('/')[-1]
middle_file_path = u'/tmp/' + u'mapped_' + key.split('/')[-1]
download_ret = download_file(cos_client, bucket, key, src_file_path) # download src file
if download_ret == 0:
inputfile = open(src_file_path, 'r') # open local /tmp file
mapfile = open(middle_file_path, 'w') # open a new file write stream
for line in inputfile:
line = re.sub('[^a-zA-Z0-9]', ' ', line) # replace non-alphabetic/number characters
words = line.split()
for word in words:
mapfile.write('%s\t%s' % (word, 1)) # count for 1
mapfile.write('\n')
inputfile.close()
mapfile.close()
upload_ret = upload_file(cos_client, middle_stage_bucket, middle_file_key,
middle_file_path) # upload the file's each word
delete_file_folder(src_file_path)
delete_file_folder(middle_file_path)
return upload_ret
else:
return -1
def map_caller(event, context, cos_client):
appid = event['Records'][0]['cos']['cosBucket']['appid']
bucket = event['Records'][0]['cos']['cosBucket']['name'] + '-' + appid
key = event['Records'][0]['cos']['cosObject']['key']
key = key.replace('/' + str(appid) + '/' + event['Records'][0]['cos']['cosBucket']['name'] + '/', '', 1)
logger.info("Key is " + key)
middle_bucket = middle_stage_bucket + '-' + appid
middle_file_key = '/' + 'middle_' + key.split('/')[-1]
return do_mapping(cos_client, bucket, key, middle_bucket, middle_file_key)
def main_handler(event, context):
logger.info("start main handler")
if "Records" not in event.keys():
return {"errorMsg": "event is not come from cos"}
secret_id = ""
secret_key = ""
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, )
cos_client = CosS3Client(config)
start_time = datetime.datetime.now()
res = map_caller(event, context, cos_client)
end_time = datetime.datetime.now()
print("data mapping duration: " + str((end_time - start_time).microseconds / 1000) + "ms")
if res == 0:
return "Data mapping SUCCESS"
else:
return "Data mapping FAILED"
同样的方法,建立 reducer.py 文件,编写 Reducer 逻辑,代码如下:
# -*- coding: utf8 -*-
from qcloud_cos_v5 import CosConfig
from qcloud_cos_v5 import CosS3Client
from qcloud_cos_v5 import CosServiceError
from operator import itemgetter
import os
import sys
import datetime
import logging
region = u'ap-guangzhou' # 根据实际情况,修改地域
result_bucket = u'destmr' # 根据实际情况,修改bucket名
logging.basicConfig(level=logging.INFO, stream=sys.stdout)
logger = logging.getLogger()
logger.setLevel(level=logging.INFO)
def delete_file_folder(src):
if os.path.isfile(src):
try:
os.remove(src)
except:
pass
elif os.path.isdir(src):
for item in os.listdir(src):
itemsrc = os.path.join(src, item)
delete_file_folder(itemsrc)
try:
os.rmdir(src)
except:
pass
def download_file(cos_client, bucket, key, download_path):
logger.info("Get from [%s] to download file [%s]" % (bucket, key))
try:
response = cos_client.get_object(Bucket=bucket, Key=key, )
response['Body'].get_stream_to_file(download_path)
except CosServiceError as e:
print(e.get_error_code())
print(e.get_error_msg())
return -1
return 0
def upload_file(cos_client, bucket, key, local_file_path):
logger.info("Start to upload file to cos")
try:
response = cos_client.put_object_from_local_file(
Bucket=bucket,
LocalFilePath=local_file_path,
Key='{}'.format(key))
except CosServiceError as e:
print(e.get_error_code())
print(e.get_error_msg())
return -1
logger.info("Upload data map file [%s] Success" % key)
return 0
def qcloud_reducer(cos_client, bucket, key, result_bucket, result_key):
word2count = {}
src_file_path = u'/tmp/' + key.split('/')[-1]
result_file_path = u'/tmp/' + u'result_' + key.split('/')[-1]
download_ret = download_file(cos_client, bucket, key, src_file_path)
if download_ret == 0:
map_file = open(src_file_path, 'r')
result_file = open(result_file_path, 'w')
for line in map_file:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
word2count[word] = word2count.get(word, 0) + count
except ValueError:
logger.error("error value: %s, current line: %s" % (ValueError, line))
continue
map_file.close()
delete_file_folder(src_file_path)
sorted_word2count = sorted(word2count.items(), key=itemgetter(1))[::-1]
for wordcount in sorted_word2count:
res = '%s\t%s' % (wordcount[0], wordcount[1])
result_file.write(res)
result_file.write('\n')
result_file.close()
upload_ret = upload_file(cos_client, result_bucket, result_key, result_file_path)
delete_file_folder(result_file_path)
return upload_ret
def reduce_caller(event, context, cos_client):
appid = event['Records'][0]['cos']['cosBucket']['appid']
bucket = event['Records'][0]['cos']['cosBucket']['name'] + '-' + appid
key = event['Records'][0]['cos']['cosObject']['key']
key = key.replace('/' + str(appid) + '/' + event['Records'][0]['cos']['cosBucket']['name'] + '/', '', 1)
logger.info("Key is " + key)
res_bucket = result_bucket + '-' + appid
result_key = '/' + 'result_' + key.split('/')[-1]
return qcloud_reducer(cos_client, bucket, key, res_bucket, result_key)
def main_handler(event, context):
logger.info("start main handler")
if "Records" not in event.keys():
return {"errorMsg": "event is not come from cos"}
secret_id = "SecretId"
secret_key = "SecretKey"
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, )
cos_client = CosS3Client(config)
start_time = datetime.datetime.now()
res = reduce_caller(event, context, cos_client)
end_time = datetime.datetime.now()
print("data reducing duration: " + str((end_time - start_time).microseconds / 1000) + "ms")
if res == 0:
return "Data reducing SUCCESS"
else:
return "Data reducing FAILED"
部署与测试
遵循 Serverless Framework 的 yaml 规范,编写 serveerless.yaml:
WordCountMapper:
component: "@serverless/tencent-scf"
inputs:
name: mapper
codeUri: ./code
handler: index.main_handler
runtime: Python3.6
region: ap-guangzhou
description: 网站监控
memorySize: 64
timeout: 20
events:
- cos:
name: srcmr-1256773370.cos.ap-guangzhou.myqcloud.com
parameters:
bucket: srcmr-1256773370.cos.ap-guangzhou.myqcloud.com
filter:
prefix: ''
suffix: ''
events: cos:ObjectCreated:*
enable: true
WordCountReducer:
component: "@serverless/tencent-scf"
inputs:
name: reducer
codeUri: ./code
handler: index.main_handler
runtime: Python3.6
region: ap-guangzhou
description: 网站监控
memorySize: 64
timeout: 20
events:
- cos:
name: middlestagebucket-1256773370.cos.ap-guangzhou.myqcloud.com
parameters:
bucket: middlestagebucket-1256773370.cos.ap-guangzhou.myqcloud.com
filter:
prefix: ''
suffix: ''
events: cos:ObjectCreated:*
enable: true完成之后,通过 sls --debug 指令进行部署。部署成功之后,进行基本的测试:
- 准备一个英文文档:

登录腾讯云后台,打开我们最初建立的存储桶:srcmr,并上传该文件;
上传成功之后,稍等片刻即可看到 Reducer 程序已经在 Mapper 执行之后,产出日志:

此时,我们打开结果存储桶,查看结果:

现在,我们就完成了简单的词频统计功能。
总结
Serverless 架构是适用于大数据处理的。在腾讯云官网,我们也可以看到其关于数据 ETL 处理的场景描述:
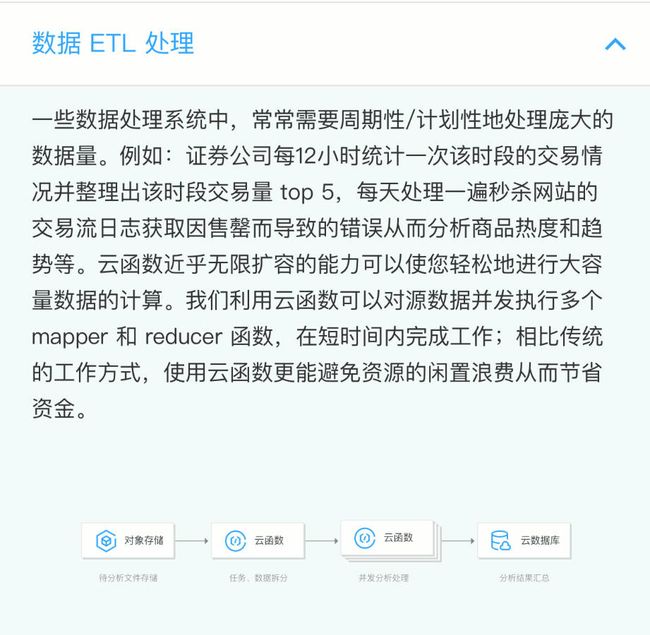
本实例中,有一键部署多个函数的操作。在实际生产中,每个项目都不会是单个函数单打独斗的,而是多个函数组合应用,形成一个 Service 体系,所以一键部署多个函数就显得尤为重要。通过本实例,希望读者可以对 Serverless 架构的应用场景有更多的了解,并且能有所启发,将云函数和不同触发器进行组合,应用在自身业务中。
Serverless Framework 30 天试用计划
我们诚邀您来体验最便捷的 Serverless 开发和部署方式。在试用期内,相关联的产品及服务均提供免费资源和专业的技术支持,帮助您的业务快速、便捷地实现 Serverless!
详情可查阅:Serverless Framework 试用计划
One More Thing
3 秒你能做什么?喝一口水,看一封邮件,还是 —— 部署一个完整的 Serverless 应用?
复制链接至 PC 浏览器访问:https://serverless.cloud.tencent.com/deploy/express
3 秒极速部署,立即体验史上最快的 Serverless HTTP 实战开发!
传送门:
- GitHub: github.com/serverless
- 官网:serverless.com
欢迎访问:Serverless 中文网,您可以在 最佳实践 里体验更多关于 Serverless 应用的开发!
推荐阅读:《Serverless 架构:从原理、设计到项目实战》