iOS 面试之数据结构和算法分析(快排,希尔排序,堆排序,冒泡排序,选择排序)
常见的数据结构类型
1.集合结构 线性结构 树形结构 图形结构
1.1、集合结构 说白了就是一个数学意义上的集合,就是一个圆圈中有很多个元素,元素与元素之间没有任何关系 , 这个很简单
1.2、线性结构 说白了就是一个条线上站着很多个人。 这条线不一定是直的。也可以是弯的。也可以是值的 相当于一条线被分成了好几段的样子 (发挥你的想象力)。 线性结构是一对一的关系
1.3、树形结构 说白了就是一棵倒立的树,子节点是就像是大树的树枝和树叶。 做开发的肯定或多或少的知道xml 解析 树形结构跟他非常类似。也可以想象成一个金字塔。树形结构是一对多的关系
1.4、图形结构 这个就比较复杂了。他呢 无穷。无边 无向(没有方向箭头)图形机构 你可以理解为多对多 类似于我们人的交集关系
2. 数据结构的存储
2.1 顺序存储结构发挥想象力啊。 举个列子。
数组。1-2-3-4-5-6-7-8-9-10。这个就是一个顺序存储结构 ,存储是按顺序的 举例说明啊。
栈。做开发的都熟悉。栈是先进后出 ,后进先出的形式 对不对 ?!他的你可以这样理解hello world 在栈里面从栈底到栈顶的逻辑依次为 h-e-l-l-o-w-o-r-l-d 这就是顺序存储 再比如 队列 ,队列是先进先出的对吧,从头到尾 h-e-l-l-o-w-o-r-l-d 就是这样排对的
2.2 链式存储结构再次发挥想象力 这个稍微复杂一点 这个图片我一直弄好 ,回头找美工问问,再贴上 例如 还是一个数组1-2-3-4-5-6-7-8-9-10 链式存储就不一样了 1(地址)-2(地址)-7(地址)-4(地址)-5(地址)-9(地址)-8(地址)-3(地址)-6(地址)-10(地址)。每个数字后面跟着一个地址 而且存储形式不再是顺序 ,也就说顺序乱了,1(地址) 1后面跟着的这个地址指向的是2,2后面的地址指向的是3,3后面的地址指向是谁你应该清楚了吧。他执行的时候是 1(地址)-2(地址)-3(地址)-4(地址)-5(地址)-6(地址)-7(地址)-8(地址)-9(地址)-10(地址),但是存储的时候就是完全随机的。明白了?!
**3 单向链表\双向链表\循环链表还是举例子。**理解最重要。不要去死记硬背 哪些什么。定义啊。逻辑啊。理解才是最重要滴
3.1 单向链表 A->B->C->D->E->F->G->H. 这就是单向链表 H 是头 A 是尾 像一个只有一个头的火车一样 只能一个头拉着跑
3.2 双向链表 H<- A->B->C->D->E->F->G->H. 这就是双向链表。有头没尾。两边都可以跑 跟地铁一样 到头了 可以倒着开回来
3.3 循环链表 发挥想象力 A->B->C->D->E->F->G->H. 绕成一个圈。就像蛇吃自己的这就是循环 不需要去死记硬背哪些理论知识。
4.二叉树/平衡二叉树
4.1 什么是二叉树
树形结构下,两个节点以内 都称之为二叉树 不存在大于2 的节点 分为左子树 右子树 有顺序 不能颠倒 ,懵逼了吧,你肯定会想这是什么玩意,什么左子树右子树 ,都什么跟什么鬼? 现在我以普通话再讲一遍,你把二叉树看成一个人 ,人的头呢就是树的根 ,左子树就是左手,右子树就是右手,左右手可以都没有(残疾嘛,声明一下,绝非歧视残疾朋友,勿怪,勿怪就是举个例子,i am very sorry) , 左右手呢可以有一个,就是不能颠倒。这样讲应该明白了吧 二叉树有五种表现形式
1. 空的树(没有节点)可以理解为什么都没 像空气一样
2. 只有根节点。 (理解一个人只有一个头 其他的什么都没,说的有点恐怖)
3. 只有左子树 (一个头 一个左手 感觉越来越写不下去了)
4. 只有右子树
5. 左右子树都有二叉树可以转换成森林 树也可以转换成二叉树。
这里就不介绍了 你做项目绝对用不到数据结构大致介绍这么多吧。理解为主 别死记,死记没什么用
5.算法
5.1 冒泡排序 和选择排序
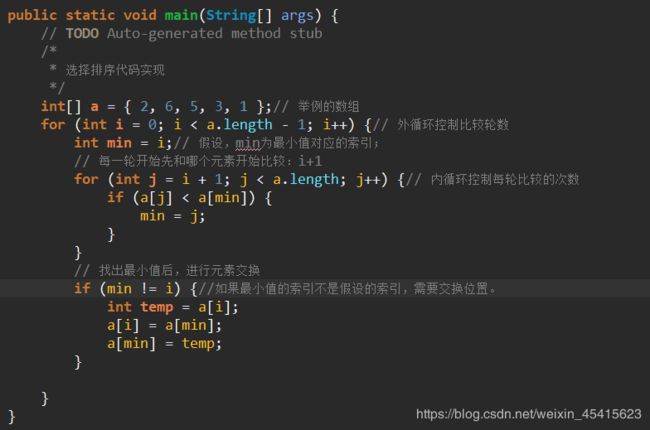
冒泡排序:冒泡排序的定义就不提了,总结起来就一句话(划重点):从左到右,数组中相邻的两个元素进行比较,将较大的放到后面
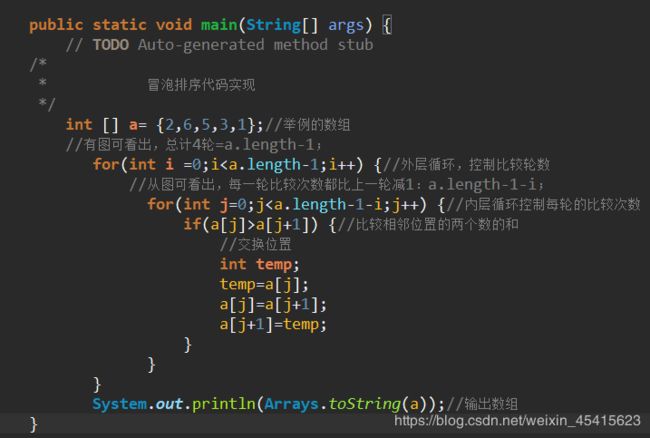
我们同样,以上面的例子为例 int [] a= {2,6,5,3,1};
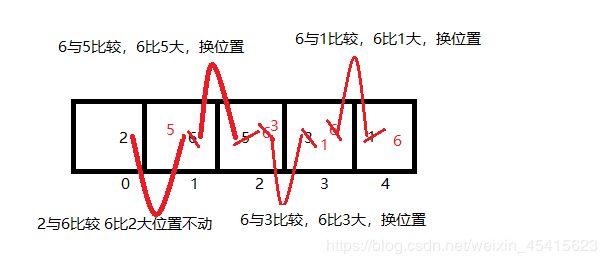
从图可以看出,第一轮比较,比较了4轮,找出了最小数1,与第一个位置的数字进行了换位;
第二轮排序开始时的数组已经变成了{1,6,5,3,2};
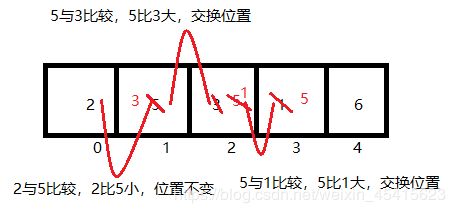
从图可以看出,第二轮比较,比较了3次,确定剩余数中的最小数为2,与第二个位置的数交换。
第三轮排序开始时的数组已经变成了{1,2,5,3,6};
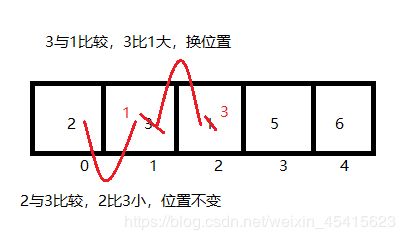
从图可以看出,第三轮比较,比较了2次,确定了剩余数中最小的数3,与第三个位置的数互换位置。
第四轮排序开始时的数组已经变成了{1,2,3,5,6};
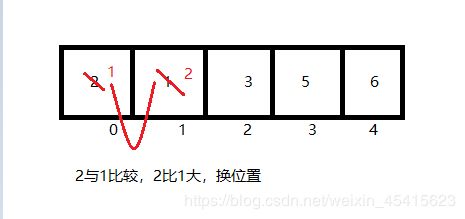
从图可以看出,第四轮比较,比较了1次,确定了剩余数中最小的数5,放在了第4个位置。
这样4轮比较后,这组数已经排序好了,接下来同上,去找规律,实现代码了:
运行结果:

选择排序,总结一句话就是(划重点):从第一个位置开始比较,找出最小的,和第一个位置互换,开始下一轮。
我们同样,以上面的例子为例 int [] a= {2,6,5,3,1};
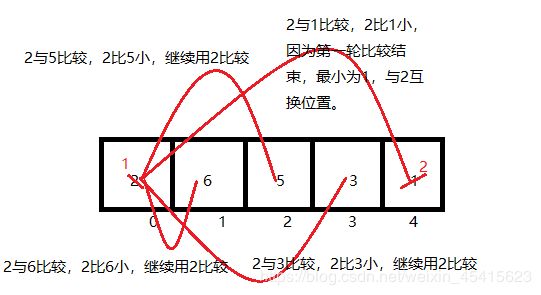
从图可以看出,第一轮比较,比较了4轮,找出了最小数1,与第一个位置的数字进行了换位;
第二轮排序开始时的数组已经变成了{1,6,5,3,2};
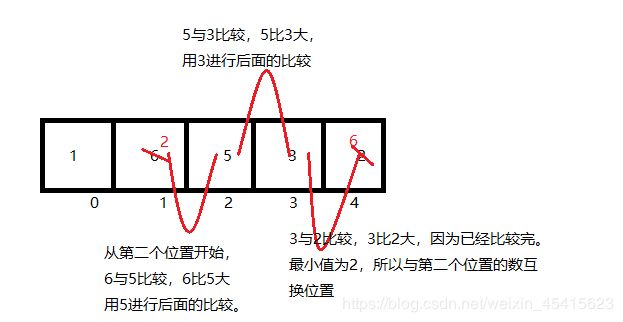
从图可以看出,第二轮比较,比较了3次,确定剩余数中的最小数为2,与第二个位置的数交换。
第三轮排序开始时的数组已经变成了{1,2,5,3,6};
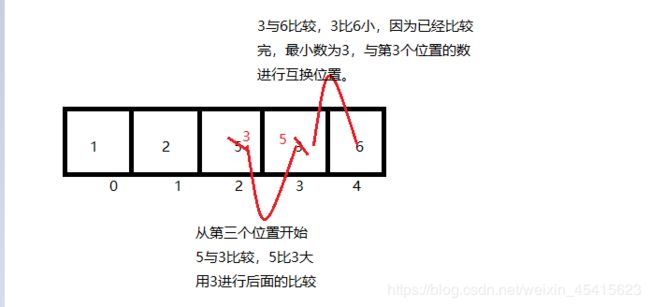
从图可以看出,第三轮比较,比较了2次,确定了剩余数中最小的数3,与第三个位置的数互换位置。
第四轮排序开始时的数组已经变成了{1,2,3,5,6};

从图可以看出,第四轮比较,比较了1次,确定了剩余数中最小的数5,放在了第4个位置。
这样4轮比较后,这组数已经排序好了,接下来同上,去找规律,实现代码了:
运行结果:

选择排序也就结束了,这样一弄有没有更清楚呢?
那么好,是时候来总结下他们的区别了(划重点)。
(1)冒泡排序是比较相邻位置的两个数,而选择排序是按顺序比较,找最大值或者最小值;
(2)冒泡排序每一轮比较后,位置不对都需要换位置,选择排序每一轮比较都只需要换一次位置;
(3)冒泡排序是通过数去找位置,选择排序是给定位置去找数;
冒泡排序优缺点:优点:比较简单,空间复杂度较低,是稳定的;
缺点:时间复杂度太高,效率慢;
选择排序优缺点:优点:一轮比较只需要换一次位置; 缺点:效率慢,不稳定(举个例子5,8,5,2,9 我们知道第一遍选择第一个元素5会和2交换,那么原序列中2个5的相对位置前后顺序就破坏了)
5.2 插入排序
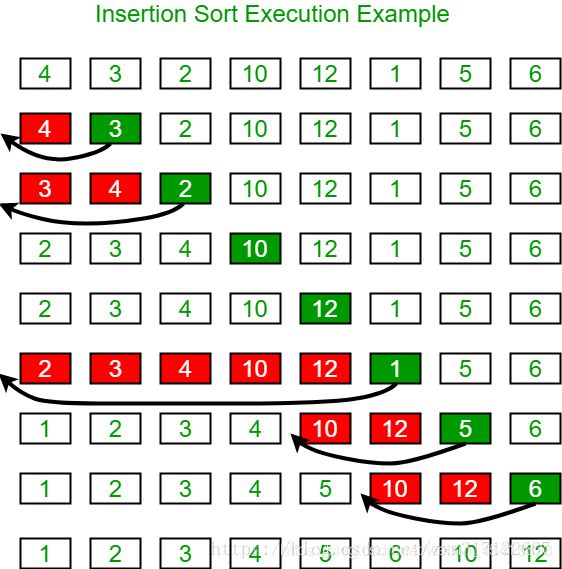
**算法思路:**插入排序的工作方式非常像人们排序一手扑克牌一样。开始时,我们的左手为空并且桌子上的牌面朝下。然后,我们每次从桌子上拿走一张牌并将它插入左手中正确的位置。为了找到一张牌的正确位置,我们从右到左将它与已在手中的每张牌进行比较,
算法步骤:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
代码实现:
class InsertionSort
{
/*Function to sort array using insertion sort*/
void sort(int arr[])
{
int n = arr.length;
for (int i=1; i=0 && arr[j] > key)
{
arr[j+1] = arr[j];
j = j-1;
}
arr[j+1] = key;
}
}
/* A utility function to print array of size n*/
static void printArray(int arr[])
{
int n = arr.length;
for (int i=0; i 5.3 希尔排序
(1)希尔排序(shell sort)这个排序方法又称为缩小增量排序,是1959年D·L·Shell提出来的。该方法的基本思想是:设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入排序。然后缩小间隔increment,重复上述子序列划分和排序工作。直到最后取increment=1,将所有元素放在同一个子序列中排序为止。
(2)由于开始时,increment的取值较大,每个子序列中的元素较少,排序速度较快,到排序后期increment取值逐渐变小,子序列中元素个数逐渐增多,但由于前面工作的基础,大多数元素已经基本有序,所以排序速度仍然很快。
(3)希尔排序举例:
1>下面给出一个数据列:

2>第一趟取increment的方法是:n/3向下取整+1=3(关于increment的取法之后会有介绍)。将整个数据列划分为间隔为3的3个子序列,然后对每一个子序列执行直接插入排序,相当于对整个序列执行了部分排序调整。图解如下:
3>第二趟将间隔increment= increment/3向下取整+1=2,将整个元素序列划分为2个间隔为2的子序列,分别进行排序。图解如下:
4>第3趟把间隔缩小为increment= increment/3向下取整+1=1,当增量为1的时候,实际上就是把整个数列作为一个子序列进行插入排序,图解如下:
5>直到increment=1时,就是对整个数列做最后一次调整,因为前面的序列调整已经使得整个序列部分有序,所以最后一次调整也变得十分轻松,这也是希尔排序性能优越的体现。
(4)希尔排序算法的代码实现(C++)
//函数功能,希尔排序算法对数字递增排序
//函数参数,数列起点,数列终点
void shell_sort(const int start, const int end) {
int increment = end - start + 1; //初始化划分增量
int temp{ 0 };
do { //每次减小增量,直到increment = 1
increment = increment / 3 + 1;
for (int i = start + increment; i <= end; ++i) { //对每个划分进行直接插入排序
if (numbers[i - increment] > numbers[i]) {
temp = numbers[i];
int j = i - increment;
do { //移动元素并寻找位置
numbers[j + increment] = numbers[j];
j -= increment;
} while (j >= start && numbers[j] > temp);
numbers[j + increment] = temp; //插入元素
}
}
} while (increment > 1);
}
上面的函数的第一个do……while控制increment每次的缩小,其内部便是直接插入排序算法的使用,与直接插入排序算法稍有不同的一点是:其j每次的变化量是increment而不是1。
(5)关于希尔排序increment(增量)的取法。
增量increment的取法有各种方案。最初shell提出取increment=n/2向下取整,increment=increment/2向下取整,直到increment=1。但由于直到最后一步,在奇数位置的元素才会与偶数位置的元素进行比较,这样使用这个序列的效率会很低。后来Knuth提出取increment=n/3向下取整+1.还有人提出都取奇数为好,也有人提出increment互质为好。应用不同的序列会使希尔排序算法的性能有很大的差异。
(6)希尔排序应该注意的问题
从上面图解希尔排序的过程可以看到,相等的排序码25在排序前后的顺序发生了颠倒,所以希尔排序是一种不稳定的排序算法。
5.4 二分查找
二分查找法实质上是不断地将有序数据集进行对半分割,并检查每个分区的中间元素。在以下介绍的实现方法中,有序数据集存放在sorted中,sorted是一块连续的存储空间。参数target是要查找的数据。
此实现过程的实施是通过变量left和right控制一个循环来查找元素(其中left和right是正在查找的数据集的两个边界值)。首先,将left和right分别设置为0和size-1。在循环的每次迭代过程中,将middle设置为left和right之间区域的中间值。如果处于middle的元素比目标值小,将左索引值移动到middle后的一个元素的位置上。即下一组要搜索的区域是当前数据集的上半区。如果处于middle的元素比目标元素大,将右索引值移动到middle前一个元素的位置上。即下一组要搜索的区域是当前数据集的下半区。随着搜索的不断进行,left从左向右移,right从右向左移。一旦在middle处找到目标,查找将停止;如果没有找到目标,left和right将重合。图示如下:

5.5 快排
快速排序原理:从一组数中任意选出一个数,将大于它的数放右边,小于它的数放左边,然后再从左边和右边的俩组数中分别执行此操作,知道组中元素数为1,此时,数组就是有序的了。
实现代码:
int partsort(int a[],int l,int r){ //将比a[r]小的元素放左边,比它大的放右边,最后把a[r]放中间
2
3 int i=l; //i为比a[r]大的元素的下标,初始为开始位置l
4
5 for(int j=l;j4、堆排序
要想理解堆排序,首先你要知道最大堆,要想理解最大堆,你得知道二叉树。
二叉树:每个节点最多有俩个孩子节点。
最大堆:父亲节点的值总是大于孩子节点的值。
当然在这里二叉树的存储结构不是链表,是使用数组存的:
(1)数组下标为0处是根节点。
(2)父亲节点下标2为左孩子下标,父亲节点下标2+1为右孩子下标。
根据这俩条准则我们就可以将二叉树存在数组了。
堆排序原理:我们知道最大堆的性质(父亲节点的值总是大于孩子节点的值),那么根节点处不就是当前数列的最大值吗,那么我们每次取根节点的值放在末尾,然后将最大堆的大小-1,更新最大堆,取根节点放后边…不断执行这个过程,直到最大堆中只剩一个元素,此时数组就是一个有序数组了。
根据原理可以看出我们需要编的操作有
(1)建最大堆
(2)更新最大堆,其实建立最大堆就是不断更新最大堆的过程,如果我们将每个结点都执行一遍更新最大堆操作(即父亲节点的值总是大于孩子节点的值,不符合的话将父亲节点与最大的孩子交换位置),当然执行顺序必须是从下往上,然后只需从非叶子节点开始执行就好了(非叶子节点就是有孩子的结点)。
堆排序代码如下:
//更新最大堆操作
2
3 void dfDui(int x) { //参数为父亲节点下标
4
5 int lchild=x*2; //左孩子下标
6
7 int rchild=x*2+1; //右孩子下标
8
9 int max=x; //最大值下标初始为父亲下标
10
11 if(lchilda[max]) //比较找出最大值
12
13 max=lchild;
14
15 if(rchilda[max])
16
17 max=rchild;
18
19 if(max!=x){ //若父亲节点为最大值,则符合性质,否则交换,将最大值移到父亲节点处,然后因为孩子节点处已改变,更新此节点。
20
21 int t=a[max];
22
23 a[max]=a[x];
24
25 a[x]=t;
26
27 dfDui(max);
28
29 }
30
31 }
32
33 //建最大堆操作
34
35 void creatDui(){
36
37 for(int i=a.length/2+1;i>=0;i--){ //叶子结点数为结点总数一半且都在最后(可以从孩子节点下标的算法为父亲节点*2看出),因此 duDui(i); // a.length/2+1处开始为非叶子节点
38
39 }
40
41 }
42
43 //堆排序操作
44
45 void sort(){
46
47 creatDui(); //建最大堆
48
49 for(int i=size-1;i>=1;i--){ //每次将第一个数与最后一个数交换,然后大小-1,更新已经改变的根节点
50
51 int t=a[0];
52
53 a[0]=a[size-1];
54
55 a[size-1]=t;
56
57 size--;
58
59 dfDui(0);
60
61 }
62
63 }
转载链接:https://www.jianshu.com/p/1b43f4eac8d8
参考原文:https://blog.csdn.net/zxm317122667/article/details/83344178
参考原文:https://blog.csdn.net/weixin_37818081/article/details/79202115
给大家推荐一个优秀的iOS交流平台,平台里的伙伴们都是非常优秀的iOS开发人员,我们专注于技术的分享与技巧的交流,大家可以在平台上讨论技术,交流学习。欢迎大家的加入(密码:001)