BERT与其他预训练模型
上一期我们讲到BERT的原理与应用
这一期我们讲一下其他预训练模型~

8.1.3 RoBERTa
语言模型的预训练带来了可观的性能提升,但是不同方法之间的仔细比较却是一项艰巨的任务。
Yinhan Liu等人[1]认为超参数的选择对最终结果有重大影响,为此他们提出了BERT预训练的重复研究,其中包括对超参数调整和训练集大小的影响的仔细评估。最终,他们发现了BERT的训练不足,并提出了一种改进的模型来训练BERT模型(称为RoBERTa(A Robustly Optimized BERT Pre-training Approach)),该模型可以媲美或超过所有Post-BERT的性能。而且他们对超参数与训练集的修改也很简单,它们包括:
(1) 训练模型时间更长,Batch Size更大,数据更多。
(2) 删除下一句预测目标(Next Sentence Prediction)。
(3) 对较长序列的训练。
(4) 动态掩盖应用于训练数据的掩盖模式。在BERT源码中,随机掩盖和替换在开始时只执行一次,并在训练期间保存,我们可以将其看成静态掩盖。BERT的预训练依赖于随机掩盖和预测被掩盖字或者单词。为了避免在每个epoch中对每个训练实例使用相同的掩盖,论文作者将训练数据重复10次,以便在40个epoch中以10种不同的方式对每个序列进行掩码。因此,每个训练序列在训练过程中都会看到相同的掩盖四次。他们将静态掩盖与动态掩盖进行了比较,实验证明了动态掩盖的有效性。
(5) 他们还收集了一个大型新数据集(CC-NEWS),其大小与其他私有数据集相当,以更好地控制训练集大小效果。
(6) 使用Sennrich[2]等人提出的Byte-Pair Encoding (BPE)字符编码,它是字符级和单词级表示之间的混合体,可以处理自然语言语料库中常见的大词汇,避免训练数据出现更多的“[UNK]”标志符号,从而影响预训练模型的性能。其中,“[UNK]”标记符表示当在BERT自带字典vocab.txt找不到某个字或者英文单词时,则用“[UNK]”表示。
8.1.4 ERNIE
受到BERT掩盖策略的启发,Yu Sun等人[3]提出了一种新的语言表示模型ERNIE(Enhanced Representation through kNowledge IntEgration)。
ERNIE旨在学习通过知识掩盖策略增强模型性能,其中包括实体级掩盖和短语级掩盖,两者对比如图 8.7所示。实体级策略可掩盖通常由多个单词组成的实体。短语级策略掩盖了由几个单词组合成一个概念单元组成的整个短语。实验结果表明,ERNIE优于其他基准方法,在五种中文自然语言处理上获得了最新的最新结果任务包括自然语言推理,语义相似性,命名实体识别,情感分析和问题解答。他们还证明ERNIE在完形填空测试中具有更强大的知识推理能力。知识掩盖策略如图 8.8所示。

图 8.7 三种掩盖策略对比
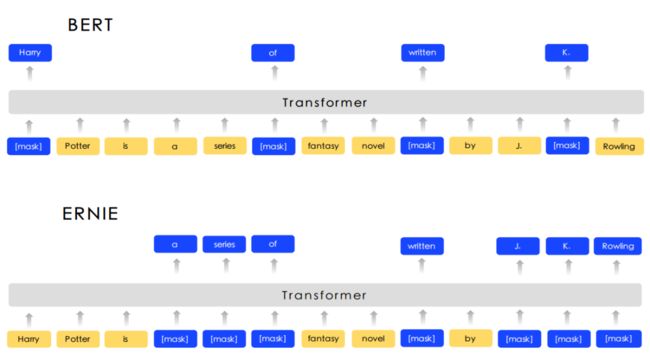
图 8.8 知识掩盖策略
8.1.5 BERT_WWM
BERT已在各种NLP任务中取得了惊人的改进,因此基于BERT的改进模型接踵而至,带有全字掩码(Whole Word Masking)的BERT升级版本BERT_WWM便是其中之一,它减轻了预训练过程中掩码部分Word Piece字符的弊端。其中,Word Piece字符其实就是笔者在8.1.2节介绍的英文单词分词,在将英文单词灌入模型之前,我们需要将其转换成词根词缀形式,如“Playing”转换成“Play”+“# #ing”。如果我们使用原生BERT的随机掩盖,可能会掩盖“Play”或者“# #ing”或者同时掩盖两者,但如果我们使用全字掩盖,则一定是掩盖两者。
Yiming Cui等人[4]对中文文本也进行了全字掩码,这会掩盖整个词组,而不是掩盖中文字符。实验结果表明,整个中文词组被掩盖可以带来显着的收益。BERT_WWM的掩盖策略本质上和ERNIE是相同的,所以笔者在此就不进行过多的分析了。BERT_WWM掩盖策略如图 8.9所示。

图 8.9 BERT_WWM掩盖策略
8.1.6 NLP预训练模型对比
Word2Vec等模型已经比不上BERT与后续改进BERT的预训练模型了,除非我们对时间与空间复杂度要求非常苛刻,只能用小模型去完成某些特定任务,不然一般都是考虑用BERT之类的大模型来提升整体任务的准确率。
参考文献
[1] Liu Y, Ott M, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J]. arXiv preprint arXiv:1907.11692, 2019.
[2] Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with subword units[J]. arXiv preprint arXiv:1508.07909, 2015.
[3] Sun Y, Wang S, Li Y, et al. ERNIE: Enhanced Representation through Knowledge Integration[J]. arXiv preprint arXiv:1904.09223, 2019.
[4] Cui Y, Che W, Liu T, et al. Pre-Training with Whole Word Masking for Chinese BERT[J]. arXiv preprint arXiv:1906.08101, 2019.

下一期,我们将继续讲授自然语言处理四大下游任务

敬请期待~

关注我的微信公众号~不定期更新相关专业知识~


内容 |阿力阿哩哩
编辑 | 阿璃

点个“在看”,作者高产似那啥~
