Python爬虫实战——今日头条图片下载
目前正在自学爬虫,在b站上看到网课都比较过时,页面情况早已改变,对于新手比较不友好,经过尝试成功爬取今日头条图片并下载。
首先是在今日头条下进行搜索:https://www.toutiao.com/search/?keyword=美女
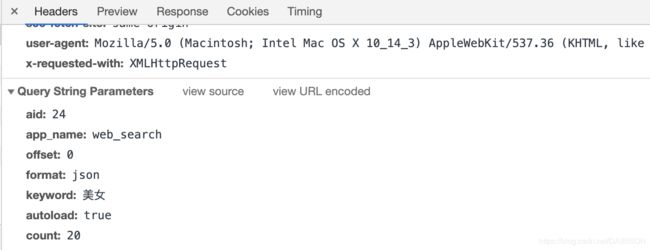
右键点击查看网页源代码后发现并不是我们需要的,经过分析,应该是该数据是通过异步加载Ajax实现的。右键点击检查,点击Network并切换到XHR,此时再刷新页面可以看到offset=0且为json格式的数据,往下滑动可以看到出现offset=20 40,代表页面持续加载。右侧的Request URL链接就是我们需要的。

下图中的aid等数据就是Request URL后面的参数。
Preview里的data就是我们需要提取的每条搜索结果的数据内容。
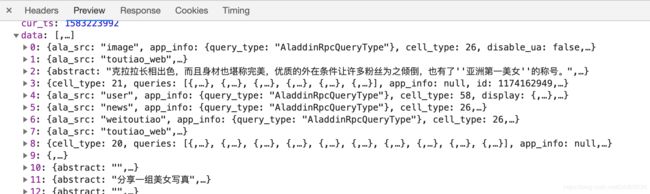
因此,
def get_page(offset, keyword):
data = {
'aid': 24,
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'en_qc': '1',
'cur_tab': '1',
'from': 'search_tab',
'pd': 'synthesis',
'timestamp': '1583216771755',
}
url = "https://www.toutiao.com/api/search/content/?" + urlencode(data)
kv = {'cookie': '这里是自己的cookie,登录后在headers里可以找到',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
r = requests.get(url, headers = kv)
try:
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.json()
except:
return ""
def parse_page(offset, keyword, fpath):
html = get_page(offset, keyword)
if html and 'data' in html.keys():
for item in html.get('data'):
if item.get('image_list'):
title = item.get('title')
urls = item.get('image_list')
urlList = []
for i in range(len(urls)):
download_images(urls[i]['url'])
urlList.append(urls[i]['url'])
dict = {'title':title,
'urls':urlList}
with open(fpath, 'a', encoding = 'UTF-8') as f:
f.write(str(dict) + "\n" + "\n")
这里是提取了页面内容并用json()转换成字典格式,通过查看data的结构提取出来组图的title以及url,将这些储存到了本地txt。
接下来下载、储存图片,储存在当前文件夹。其中r.content表示二进制图片,r.text是页面文本。
def download_images(url):
kv = {'cookie': '自己的cookie',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
r = requests.get(url, headers = kv)
if r.status_code == 200:
r.encoding = r.apparent_encoding
save_images(r.content)
else:
print("请求图片出错")
return ""
def save_images(content):
file_path = "{0}/{1}.{2}".format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
最后执行main
def main():
offset = 0
keyword = "美女"
fpath = "/Users/jinritoutiao.txt"
parse_page(offset, keyword, fpath)
main()
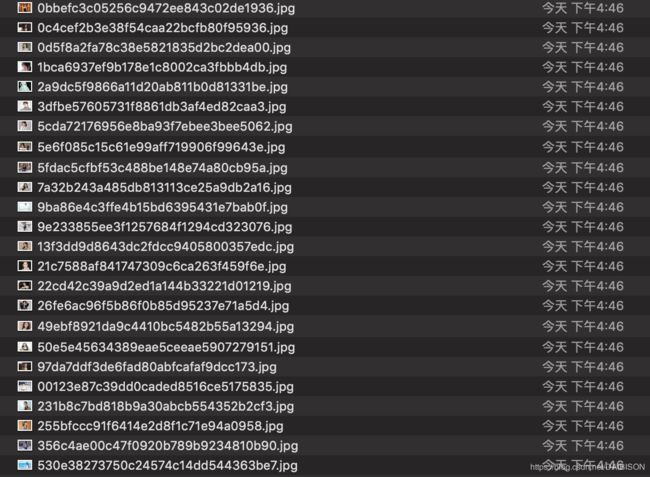
这时候就已经将图片全部下载好了。