Pytorch从入门到放弃(7)——可视化模型训练过程中的loss变化
深度学习就像炼丹,一次模型的训练需要很长时间,任何人都无法做到一直盯着模型的训练。通常都是开启模型训练之后,只要不报错并且随着迭代次数的增加模型的loss在下降,这时我都会去干别的了让它跑去吧,第二天再来看我的丹炼的怎么样。这时怎么在一堆仙丹(经过一天的训练会保存许多模型的权重,每迭代多少个batch或每个epoch保存一次权重)中找到最好的那一个。如果盲目的取最后几次保存的,容易取到过拟合的模型;相反如果随机在前中期取一个,则容易取到欠拟合的模型。因此,我们需要可以直观的看到模型训练过程中(训练阶段、验证阶段)loss值与accuracy值的变化曲线,选取一个在训练阶段与验证阶段均达到收敛的权重。
通过查找资料,发现可以借助tensorflow的tensorboard工具实现训练过程的可视化。由于是Caffe起家后来转用Pytorch,期间也学过一段时间的Tensorflow,由于不是一个好的TFBOY对TF的一些函数也不是太清楚,有幸在github上找到一位大神封装好的代码(https://github.com/yunjey/pytorch-tutorial/tree/master/tutorials/04-utils/tensorboard),所以我就无耻的拿了过来。
首先需要再已有Pytorch环境的基础上安装tensorflow,安一个cpu版本的tensorflow即可,因为只需要tensorflow带的tensorboard工具箱。(强烈建议安装低版本的tensorflow,在实验中我电脑安装的就是1.4版本的即可满足我可视化的需求,pip install tensorflow==1.4.0)。
1、项目代码组织结构

2、logger.py
大佬封装的工具可以实现,loss、accuracy、weight、grad、image在训练过程中变化记录,个人认为loss与accuracy是模型训练时比较关注的主要指标。
# Code referenced from https://gist.github.com/gyglim/1f8dfb1b5c82627ae3efcfbbadb9f514
import tensorflow as tf
import numpy as np
import scipy.misc
try:
from StringIO import StringIO # Python 2.7
except ImportError:
from io import BytesIO # Python 3.x
class Logger(object):
def __init__(self, log_dir):
"""Create a summary writer logging to log_dir."""
self.writer = tf.summary.FileWriter(log_dir)
def scalar_summary(self, tag, value, step):
"""Log a scalar variable."""
summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=value)])
self.writer.add_summary(summary, step)
def image_summary(self, tag, images, step):
"""Log a list of images."""
img_summaries = []
for i, img in enumerate(images):
# Write the image to a string
try:
s = StringIO()
except:
s = BytesIO()
scipy.misc.toimage(img).save(s, format="png")
# Create an Image object
img_sum = tf.Summary.Image(encoded_image_string=s.getvalue(),
height=img.shape[0],
width=img.shape[1])
# Create a Summary value
img_summaries.append(tf.Summary.Value(tag='%s/%d' % (tag, i), image=img_sum))
# Create and write Summary
summary = tf.Summary(value=img_summaries)
self.writer.add_summary(summary, step)
def histo_summary(self, tag, values, step, bins=1000):
"""Log a histogram of the tensor of values."""
# Create a histogram using numpy
counts, bin_edges = np.histogram(values, bins=bins)
# Fill the fields of the histogram proto
hist = tf.HistogramProto()
hist.min = float(np.min(values))
hist.max = float(np.max(values))
hist.num = int(np.prod(values.shape))
hist.sum = float(np.sum(values))
hist.sum_squares = float(np.sum(values**2))
# Drop the start of the first bin
bin_edges = bin_edges[1:]
# Add bin edges and counts
for edge in bin_edges:
hist.bucket_limit.append(edge)
for c in counts:
hist.bucket.append(c)
# Create and write Summary
summary = tf.Summary(value=[tf.Summary.Value(tag=tag, histo=hist)])
self.writer.add_summary(summary, step)
self.writer.flush()3、main.py
文件中主要定义了:数据处理+网络定义+训练+验证+log记录。看过前几篇博客的只需关注新加的用于log记录部分的代码即可。在这个文件中我是每个epoch保存一次模型的权重,并记录一次模型的loss与accuracy。加入需要每隔若干个Batch就保存一次模型权重并记录模型的loss与accuracy,只需将用于记录loss和acccuracy的代码移到for循环里即可,设置一个变量每迭代若干个Batch则记录一次(这时记录的是当前这个Batch的loss与accuracy)。
import numpy as np
from PIL import Image
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
from torch.optim import lr_scheduler
from torch.autograd import Variable
from torchvision import datasets, models, transforms
import time
import os
# 导入用于记录训练过程的日志类
from logger import Logger
# 是否使用gpu运算
use_gpu = torch.cuda.is_available()
# 定义数据的处理方式
data_transforms = {
'train': transforms.Compose([
# 将图像进行缩放,缩放为256*256
transforms.Resize(256),
# 在256*256的图像上随机裁剪出227*227大小的图像用于训练
transforms.RandomResizedCrop(227),
# 图像用于翻转
transforms.RandomHorizontalFlip(),
# 转换成tensor向量
transforms.ToTensor(),
# 对图像进行归一化操作
# [0.485, 0.456, 0.406],RGB通道的均值与标准差
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
# 测试集需要中心裁剪,甚至不裁剪,直接缩放为224*224for,不需要翻转
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(227),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 定义数据读入
def Load_Image_Information(path):
# 图像存储路径
image_Root_Dir = r'图像文件夹路径'
# 获取图像的路径
iamge_Dir = os.path.join(image_Root_Dir, path)
# 以RGB格式打开图像
# Pytorch DataLoader就是使用PIL所读取的图像格式
# 建议就用这种方法读取图像,当读入灰度图像时convert('')
return Image.open(iamge_Dir).convert('RGB')
# 定义自己数据集的数据读入类
class my_Data_Set(nn.Module):
def __init__(self, txt, transform=None, target_transform=None, loader=None):
super(my_Data_Set, self).__init__()
# 打开存储图像名与标签的txt文件
fp = open(txt, 'r')
images = []
labels = []
# 将图像名和图像标签对应存储起来
for line in fp:
line.strip('\n')
line.rstrip()
information = line.split()
images.append(information[0])
labels.append(int(information[1]))
self.images = images
self.labels = labels
self.transform = transform
self.target_transform = target_transform
self.loader = loader
# 重写这个函数用来进行图像数据的读取
def __getitem__(self, item):
# 获取图像名和标签
imageName = self.images[item]
label = self.labels[item]
# 读入图像信息
image = self.loader(imageName)
# 处理图像数据
if self.transform is not None:
image = self.transform(image)
return image, label
# 重写这个函数,来看数据集中含有多少数据
def __len__(self):
return len(self.images)
# 生成Pytorch所需的DataLoader数据输入格式
train_Data = my_Data_Set(r'train.txt路径', transform=data_transforms['train'],
loader=Load_Image_Information)
val_Data = my_Data_Set(r'val.txt路径', transform=data_transforms['val'],
loader=Load_Image_Information)
train_DataLoader = DataLoader(train_Data, batch_size=10, shuffle=True)
val_DataLoader = DataLoader(val_Data, batch_size=10)
dataloaders = {'train': train_DataLoader, 'val': val_DataLoader}
# 读取数据集大小
dataset_sizes = {'train': train_Data.__len__(), 'val': val_Data.__len__()}
# 初始化路径来记录模型训练过程中训练阶段与验证阶段的loss变化
# 训练阶段的日志文件存储路径
train_log_path = r"./log/train_log"
train_logger = Logger(train_log_path)
# 验证阶段日志文件存储路径
val_log_path = r"./log/val_log"
val_logger = Logger(val_log_path)
# 训练与验证网络(所有层都参加训练)
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 每训练一个epoch,验证一下网络模型
for phase in ['train', 'val']:
running_loss = 0.0
running_corrects = 0.0
if phase == 'train':
# 学习率更新方式
scheduler.step()
# 调用模型训练
model.train()
# 依次获取所有图像,参与模型训练或测试
for data in dataloaders[phase]:
# 获取输入
inputs, labels = data
# 判断是否使用gpu
if use_gpu:
inputs = inputs.cuda()
labels = labels.cuda()
inputs, labels = Variable(inputs), Variable(labels)
# 梯度清零
optimizer.zero_grad()
# 网络前向运行
outputs = model(inputs)
# 获取模型预测结果
_, preds = torch.max(outputs.data, 1)
# 计算Loss值
loss = criterion(outputs, labels)
# 反传梯度
loss.backward()
# 更新权重
optimizer.step()
# 计算一个epoch的loss值
running_loss += loss.item() * inputs.size(0)
# 计算一个epoch的准确率
running_corrects += torch.sum(preds == labels.data)
# 计算Loss和准确率的均值
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = float(running_corrects) / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
torch.save(model.state_dict(), 'The_' + str(epoch) + '_epoch_model.pkl')
# 1. 记录这个epoch的loss值和准确率
info = {'loss': epoch_loss, 'accuracy': epoch_acc}
for tag, value in info.items():
train_logger.scalar_summary(tag, value, epoch)
# 2. 记录这个epoch的模型的参数和梯度
for tag, value in model.named_parameters():
tag = tag.replace('.', '/')
train_logger.histo_summary(tag, value.data.cpu().numpy(), epoch)
train_logger.histo_summary(tag + '/grad', value.grad.data.cpu().numpy(), epoch)
# 3. 记录最后一个epoch的图像
info = {'images': inputs.cpu().numpy()}
for tag, images in info.items():
train_logger.image_summary(tag, images, epoch)
else:
# 取消验证阶段的梯度
with torch.no_grad():
# 调用模型测试
model.eval()
# 依次获取所有图像,参与模型训练或测试
for data in dataloaders[phase]:
# 获取输入
inputs, labels = data
# 判断是否使用gpu
if use_gpu:
inputs = inputs.cuda()
labels = labels.cuda()
inputs, labels = Variable(inputs), Variable(labels)
# 网络前向运行
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
# 计算Loss值
loss = criterion(outputs, labels)
# 计算一个epoch的loss值
running_loss += loss.item() * inputs.size(0)
# 计算一个epoch的准确率
running_corrects += torch.sum(preds == labels.data)
# 计算Loss和准确率的均值
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = float(running_corrects) / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 1. 记录这个epoch的loss值和准确率
info = {'loss': epoch_loss, 'accuracy': epoch_acc}
for tag, value in info.items():
val_logger.scalar_summary(tag, value, epoch)
# 2. 记录这个epoch的模型的参数和梯度
for tag, value in model.named_parameters():
tag = tag.replace('.', '/')
val_logger.histo_summary(tag, value.data.cpu().numpy(), epoch)
val_logger.histo_summary(tag + '/grad', value.grad.data.cpu().numpy(), epoch)
# 3. 记录最后一个epoch的图像
info = {'images': inputs.cpu().numpy()}
for tag, images in info.items():
val_logger.image_summary(tag, images, epoch)
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
# 精调AlexNet
if __name__ == '__main__':
# 导入Pytorch封装的AlexNet网络模型
model = models.alexnet(pretrained=True)
# 获取最后一个全连接层的输入通道数
num_input = model.classifier[6].in_features
# 获取全连接层的网络结构
feature_model = list(model.classifier.children())
# 去掉原来的最后一层
feature_model.pop()
# 添加上适用于自己数据集的全连接层
feature_model.append(nn.Linear(num_input, 260))
# 仿照这里的方法,可以修改网络的结构,不仅可以修改最后一个全连接层
# 还可以为网络添加新的层
# 重新生成网络的后半部分
model.classifier = nn.Sequential(*feature_model)
if use_gpu:
model = model.cuda()
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 为不同层设定不同的学习率
fc_params = list(map(id, model.classifier[6].parameters()))
base_params = filter(lambda p: id(p) not in fc_params, model.parameters())
params = [{"params": base_params, "lr": 0.0001},
{"params": model.classifier[6].parameters(), "lr": 0.001}, ]
optimizer_ft = torch.optim.SGD(params, momentum=0.9)
# 定义学习率的更新方式,每5个epoch修改一次学习率
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=5, gamma=0.1)
train_model(model, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=10)
4、tensorboard可视化
训练完成后可以在train_log与val_log文件家中看到存储的log文件,如下所示(注意:建议整个项目目录中不要出现中文,实验的过程中我的项目中存在中文字符tensorboard一直无法可依正常可视化):
可视化命令:tensorboard --logdir=train_log(日志文件存放的文件夹) --port=6006
--logdir:日志文件存放的文件夹
--port:端口号
在浏览器中输入http://localhost:6006即可实现可视化:
1、loss与accuracy的可视化
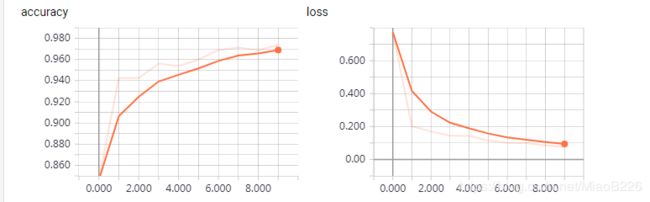
2、最后一次参与训练的图像可视化

3、权重与梯度可视化

直方图可视化

分布可视化
上述所有图均为训练阶段在训练过程中的变化,同样的我们也可以获取到验证阶段的变化,这样的话我们可以对比训练阶段与验证阶段的loss与accuracy变化,从而选取最好的模型权重作为最终训练结果。
以上是,学习过程中的一个记录与总结,如有理解错误,恳请批评指正。
完整代码地址:https://github.com/Sun-DongYang/Pytorch.git