2020大数据数据处理综合练习
2020大数据数据处理综合练习
1.数据的预处理阶段
Mapper:
public class Mapper02 extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//每行按:切分
String[] line = value.toString().split(":");
//
if (line.length>=10){
//处理 视频类别
//调用Uitl方法切分重组 视频类别
String Category=Util.replacedata(line[3]);
//处理相关视频id
String RelatedIds="";
//相关视频数量id=1 不需要切分重组
if (line.length==10){
RelatedIds=line[9];
//相关视频数量id>1
}else if (line.length>10){
String newRelatedId="";
//从第一个相关视频id遍历重组
for (int i = 9; i < line.length; i++) {
newRelatedId+=line[i]+",";
}
RelatedIds=newRelatedId.substring(0,newRelatedId.lastIndexOf(","));
}
//处理整段数据
//第一次处理:将原视频类别替换
String data=value.toString().replace(line[3],Category);
//第二次处理:将原相关视频id替换
//原相关视频id数据段
String ORelatedIds=value.toString().substring(value.toString().indexOf(line[9]));
//最终数据
String finalData=data.replace(ORelatedIds,RelatedIds);
//
context.write(key,new Text(finalData));
}
}
}
Reducer:
public class Reducer02 extends Reducer {
@Override
protected void reduce(LongWritable key, Iterable values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value,null);
}
}
}
Driver:
public class Driver02 extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration configuration=new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(Driver02.class);
job.setMapperClass(Mapper02.class);
job.setReducerClass(Reducer02.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job,new Path("E:\\资料\\14_201912\\作业\\考试练习题\\video.txt"));
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job,new Path("E:\\资料\\14_201912\\作业\\考试练习题\\output\\video2"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(),new Driver02(),args);
}
}
Util:
public class Util {
public static String replacedata(String Category) {
String Categorys="";
if (Category.contains("&")){
String[] CategoryList = Category.split("&");
for (String s : CategoryList) {
String trim = s.trim();
Categorys+=trim+",";
}
return Categorys.substring(0,Categorys.lastIndexOf(","));
}
return Category;
}
}
2.数据的入库操作阶段
把预处理之后的数据进行入库到hive中
2.1创建数据库和表
ROI:
create table video_user_ori(
uploader string,
videos string,
friends string)
row format delimited
fields terminated by ","
stored as textfile;
ORC:
create table video_user_orc(
uploader string,
videos string,
friends string)
row format delimited
fields terminated by ","
stored as ORC;
2.2导入预处理之后的数据到原始表
load data local inpath '/opt/user.txt' into table video_user_ori;
2.3从原始表查询数据并插入对应的ORC表中
insert into table video_user_orc select * from video_user_ori;
3.数据的分析阶段
对入库之后的数据进行hivesql查询操作
从视频表中统计出视频评分为5分的视频信息,把查询结果保存
hive -e "select * from video.video_orc where rate=5 " > 5.txt
4.数据保存到数据库阶段
把hive分析出的数据保存到hbase中
4.1创建hive对应的数据库外部表
创建rate外部表的语句:
create external table rate(
videoId string,
uploader string,
age string,
category string,
length string,
views string,
rate string,
ratings string,
comments string,
relatedId string)
row format delimited
fields terminated by "\t"
stored as textfile;
4.2加载第3步的结果数据到外部表中
load data local inpath '/opt/5.txt' into table rate;
4.3创建hive管理表与HBase进行映射
创建hive hbase映射表:
create table video.hbase_rate(
videoId string,
uploader string,
age string,
category string,
length string,
views string,
rate string,
ratings string,
comments string,
relatedId string)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping" = "cf:uploader,cf:age,cf:category,cf:length,cf:views,cf:rate,cf:ratings,cf:comments,cf:relatedId")
tblproperties("hbase.table.name" = "hbase_rate");
插入数据:
insert into table hbase_rate select * from rate;
5.数据的查询显示阶段
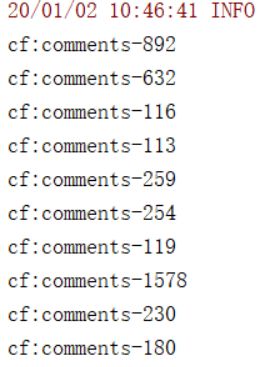
5.1请使用hbaseapi对hbase_comments表,只查询comments列的值
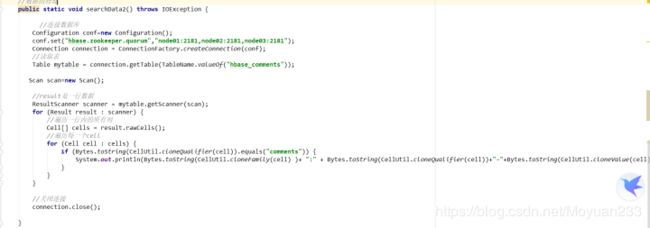
结果: