GPU高级调试与优化
[新一期GPU研习班,在上一期基础上增加更多动手试验,并对内容做了多项改进]
GPU的历史很短,只有十几年。但它发展迅猛,凭借强大的并行计算能力和高效率的固定硬件单元,在人工智能、区块链、虚拟和增强现实(VR/AR)、3D游戏和建模、视频编解码等领域大显身手。而且这种趋势还在延续,基于GPU的应用和创新势头正猛。
但是从系统架构来看,针对GPU的架构转型还在进行过程中,目前GPU依然还处于外设的地位,还没有摆脱从属身份。因为这个根本特征,对GPU编程并不像对CPU编程那样直接,而调试和优化GPU程序的难度就更大了,要比CPU程序复杂很多。
本研习班从GPU的发展简史入手,沿着GPU的发展历程,从内部结构、硬件接口和软件接口三个维度螺旋推进,深入解析GPU编程的知识要点和难点。硬件方面,以NVIDIA、AMD、INTEL和ARM四大阵营的GPU产品为例,揭秘GPU的内部架构和执行逻辑,解读其强大并行能力的硬件基础。软件方面,覆盖编程模型(CUDA、OpenCL、OpenVX、DirectX和OpenGL)、驱动模型(DRM和WDDM)和工具三个层面。具体由以下12个主题讲解和8个动手试验组成。
时间:2018年5月18日- 5月20日(周五-周日)
地点:上海
形式:实战演练、讲解和讨论点评
培训对象:使用GPU进行通用计算和图形加速的软件工程师(开发和测试)、技术经理和科研人员
主办单位:上海曜印网络科技有限公司、高端调试网站(advdbg.org)
序言:三轮演进 (0.5小时)
要点:VGA,TVGA,硬件加速,2D加速和3D加速,Voodo,从可配置到可编程,G80,GPGPU,John Nickolls,Brook和CUDA,GPU的四大功能模块

-----N篇-----
第一部分:在CUDA-GDB理解CUDA基础(1.5小时)
要点:CUDA简要历史,CUDA的C扩展,kernel函数,WARP,CUDA的线程组织,准备调试环境,单GPU调试和多GPU调试,远程调试,nvcc,-G和-g选项,附加到已经运行的进程,启用kernel初始断点(break on launch),观察源代码和汇编指令,设置断点,单步跟踪,条件断点,观察CUDA的内建变量,PTX指令集,理解WARP、grid、block和thread,Grid-Stride Loops,观察GPU线程,观察GPU的调用栈,观察GPU的寄存器,观察错误信息,从GPU上打印信息
试验1:编译和观察简单的CUDA程序
编译一个简单的CUDA程序,使用CUDA SDK中的二进制工具观察其内容,理解CUDA的编译过程和程序文件格式
试验2:改进和调试向量乘法程序
使用CUDA技术编写一个做向量乘法的小程序,理解如何向kernel函数传递参数和传回计算结果
试验3:学习CUDA-GDB的基本用法
编译并调试一个CUDA程序,练习常用的CUDA-GDB扩展命令,理解CUDA编程的关键概念
第二部分:使用NSight调试CUDA程序(1.5小时)
要点:NSight简介,安装和设置环境信息,CUDA 9.0.props,窗口布局,在VS中编译CUDA程序,产生调试信息(-G),本地调试模型,NSight Monitor,设置断点,观察变量,在Cuda Info窗口中观察计算状态,WarpWatch,调用栈,源代码跟踪,PTX/SASS汇编调试,数据断点,API Trace,OpenCL kernel追踪,产生GPU转储(core dump),调优功能
试验4:使用Visual Studio和NSight调试CUDA程序
在VS中编译和调试一个典型的并行计算程序,熟悉NSight提供的常用调试功能,包括产生调试信息,建立调试会话,设置各种断点,观察源代码和变量,单步跟踪等
第三部分:显存锥鉴(1.5小时)
要点:系统架构,内存映射,PCI Aperture,GART,GTT,访问主内存, UVA/UMA,Batch Buffer,CUDA中的内存类型,内存共享,内存复制,使用本地共享内存(shared memory),使用CUDA memory checker检查内存问题(越界访问),使用Nsight的内存调优功能
第四部分:使用NSight调试图形程序(1.5小时)
要点:设置调试环境,本地调试和远程调试,HUD,HUD图表,热键,HUD控制界面,帧调试器,DirecX软件栈,调试HLSL(High Level Shader Language)/GLSL shader,OpenGL负载追踪
试验5:使用NSight调试3D图形程序
在VS中编译和调试一个典型的3D程序,使用HUD功能观察GPU工作细节,使用VSGA深入分析某一帧画面的产生细节,认识DirectX软件栈中的关键组件和执行过程
第五部分:NVidia GPU微架构(1.5小时)
要点:G80,从SIMD到SIMT,warp,SM(Streaming Multiprocessors),Fermi微架构,PTX指令集,GigaThreads调度器,ECC支持,第三代SM,Kepler微架构,Hyper-Q,Grid Management Unit(GMU),SMX,动态并行,Maxwell微架构,SMM,指令缓存,WARP调度器,指令分发单元,Pascal微架构,伏特微架构,Tensor Core,软件仿真(GPUSim)

----I篇---
第六部分:在Code-Builder中理解OpenCL(1小时)
要点: OpenCL版本,标准导读,执行模型,运行时,OpenCL的执行硬件,CPU模拟,SIMD,kernel函数, Code-Builder简介,离线编译和在线编译,NDRange,启动算核函数,使用Code-Builder的调试功能,观察device信息,context,对象树,命令队列,内建函数
第七部分:计算机视觉加速接口(OpenVX)和英特尔实现(1.5小时)
要点:OpenVX简介,框架对象,数据对象,图,节点,节点参数,执行模型,回掉,用户kernel,常用功能的接口函数,Intel CV SDK,Vision Algorithm Designer(VAD),人脸检测实力分析和演示
试验6:使用Code-Builder调试人脸检测程序
编译和调试Intel CV SDK中的人脸检测示例程序,练习常用的调试功能
第八部分:英特尔GPU综述(50分钟)
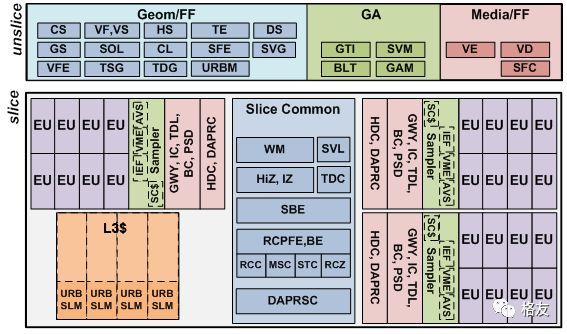
要点:Intel显卡简史,GEN架构,固定功能单元和通用计算单元(EU),EU结构,Slice和SubSlice,公开的编程手册,寄存器,GRF和ARF,VLIW,GEN指令集,LINUX驱动,i915,SRB驱动,开源项目(Beignet,NEO,CM,IGC)
-----优化篇-----
第九部分:使用CUDA profiler优化CUDA程序(1.5小时)
要点:测量GPU的时间,nvprof,命令行选项,指定收集范围,定义输出目标,Visual Profiler基础,配置远程目标,导入数据,观察时序图,识别重要事件:CPU缺页,GPU缺页,数据迁移,内存复制;采样视图,分析热点,源代码和汇编结合分析,Profile API,定义别名,定制标记,创建调优会话
试验7:使用nvprof和Visual Profiler优化CUDA程序
使用nvprof观察CUDA程序的执行细节,收集性能数据,在Visual Profiler中进行深入分析
第十部分:使用GPUView分析CPU与GPU交互(1小时)
要点:ETW基础,log.cmd,收集事件,识别典型问题:GPU/CPU Starvation,CPU/GPU Idle,线程切换,分析线程切换原因,实例演示
试验8:使用GPUView观察GPU的工作状态
安装GPUView,使用GPUView分析一个典型3D图形程序,理解GPUView的常用功能
-----A篇-----

第十一部分:AMD GPU和HSA(1.5小时)
要点:从ATI到AMD,HSA联盟,公开的技术手册,APU和GCN,GCN3解析,硬件架构,支持HSA的LINUX驱动,先进的调试支持,软件工具链:GpuOpen.com,Radeon GPU Analyzer (RGA),使用GPU PerfStudio调试图形程序,CodeXL简介,使用CodeXL调试和优化OpenCL程序,CodeXL功能演示
第十二部分:ARM GPU(1.5小时)
要点:Mali,典型应用,在深度学习中的应用(inference),Midgard微架构解析,内部结构,通用计算执行单元,DS-5简介, DS-5编译工具,DS-5调试器,Streamline性能分析工具,DS-5 IDE介绍, 系统时域范围的自下而上和自上而下分析方法,自定义标注,Log的图形化显示,OpenCLKernel跟踪, 找到代码热点,调用链分析,矩阵乘法的优化,ARM GPU软件工具链,OpenVX实现,开源代码解读,实例演示:在Midgard GPU上调试OpenCL程序(使用OpenCL加速的人脸检测应用)
讲师介绍

张银奎(Raymond Zhang),绰号“格蠹老雷”,1996年毕业于上海交通大学信息与控制工程系,在软件产业工作20余年,一多半时间在INTEL公司的上海研发中心工作,其中五年多工作在INTEL的GPU部门,以调试显卡驱动代码和各类GPU有关的问题为乐。业余时间喜欢写作和参与各类技术会议,发文数百万字,探讨各类软件问题。2015年起获微软全球最有价值技术专家(MVP)奖励。著有《软件调试》和《格蠹汇编》二书,曾经主笔《程序员》杂志调试之剑专栏。在多家跨国公司历任开发工程师、软件架构师、开发经理、项目经理等职务,对IA-32 架构、操作系统内核、驱动程序、虚拟化技术、云计算、软件调优、尤其是软件调试有较深入研究。从2005年开始公开讲授“Windows内核及高级调试”课程,曾在微软的Webcast和各种技术会议上做过《Windows Vista内核演进》、《调试之剑》(全球软件战役研究峰会)、《感受和思考调试器的威力》(CSDN SD2.0大会)、《Windows启动过程》、《如何诊断和调试蓝屏错误》、《Windows体系结构——从操作系统的角度》(以上三个讲座都是微软“深入研究Windows内部原理系列”的一部分)等。翻译(合译)作品有《现代x86汇编语言编程》、《21世纪机器人》、《观止——微软创建NT和未来的夺命狂奔》、《数据挖掘原理》、《机器学习》、《人工智能:复杂问题求解的结构和策略》等。
特邀讲师:Joey Ye

从显卡的TVGA时代开始便在当时处于领导地位的Trident公司工作,曾参与制定多项GPU设计规范,带领团队实现cmodel,为GPU集成电路设计提供软件验证。后来加入英特尔公司亚太研发中心,主要负责GPU芯片的Power On、调试、功能的研发以及GPU技术在游戏、AR/VR和机器视觉上的应用。目前工作于ARM开放智能实验室,主要负责和领导深度学习在ARM平台上GPU和CPU的实现和加速。
在显卡和GPU领域耕耘二十年,对GPU领域的主流技术都有涉猎,精通OpenCL编译技术、3D图形加速技术等。长期从事GPU底层软件的开发和调试,对嵌入式系统的CPU和GPU协同工作有深刻理解。擅长调试复杂的交互问题和对优化各类GPU应用。
附录1:试验方法
研习班现场配备多台安装有独立显卡的工作站(Nvidia和AMD GPU),学员通过现场的局域网使用SSH连接到工作站完成试验。

附录2:往届研习班部分照片




录3:报名与收费
标准收费:7000元每人
包括:
§ 包含实验材料的U盘
§ 研习班讲义和精选的学习资料纸质版
优惠条款:
- 距离上课日15天前报名可以享受8折优惠
- 6人及以上可以享受团购价4550元每人
报名或垂询
1)联系课程顾问:
a) Lisa Zhang ,电话:13801874134,电子邮件:[email protected]
b) Cindy Long,电话:13621638537,电子邮件:[email protected]
2)识别下图二维码,关注格友公众号提交报名信息
***********************************************************
正心诚意,格物致知,以人文情怀审视软件,以软件技术改变人生。
欢迎关注格友公众号
