基于 Knative 打造生产级 Serverless 平台 | KubeCon NA2019
本文推荐知道的背景知识:
Kubernetes 的基本原理和各大组件的职责;
Serverless 计算的基本概念和它的优势;
Plus: 对社区 Knative 项目的基本了解;
本文根据董一韬和王轲在 KubeCon NA 2019 大会分享整理。
董一韬 蚂蚁金服产品经理,致力于驱动云计算相关产品,包括云原生 PaaS 平台、容器与 Serverless 产品等,与最终顾客紧密合作,帮助客户在规模化的金融场景下采用与落地云原生相关解决方案。
王轲 蚂蚁金服软件工程师,建设基于 Kubernetes/Knative 的企业级 Serverless 产品,Knative 的早期使用者,Kubernetes 社区成员、控制面流控早期维护者,长期致力于用创新的方式优化、落地云原生技术。
一、分享概要
Knative 是 Google 主导的基于 Kubernetes 的 Serverless 平台,在社区上有较高的知名度。然而,身为社区项目的 Knative 主要关心的是标准、架构。虽有先进的理念,却离可在生产上使用有不少的差距。
本次 KubeCon 的演讲中,来自蚂蚁金服 SOFAStack-PaaS 平台产品技术团队的隐秀和仲乐与大家分享蚂蚁金服金融科技 Knative 的实践和改造:基于 Knative 构建一个优秀的 Serverless 计算平台,详细分析如何用独特的技术,解决性能、容量、成本三大问题。
从 Serverless 计算的应用场景开始,提炼客户真正的 Use Case,分公有云、私有云、行业云等,讲述 Serverless 计算的多种用途。之后我们将介绍在 Kubernetes 上运行 Knative 平台的方案,详细介绍要使其生产可用,不得不克服的问题。演讲最后,将刚刚的这些问题一一攻破,做出一个比社区版本优秀的 Knative 平台。
 图为董一韬、王轲 KubeCon NA 2019 大会分享现场
图为董一韬、王轲 KubeCon NA 2019 大会分享现场
二、解决性能问题:使用 Pod 预热池
熟悉 Kubernetes 的同学可能知道,Kubernetes 的首要目标并不是性能。
在一个大规模的 Kubernetes 集群下,要创建一个新的 Pod 并让它跑起来,是很慢的。这是因为这整个链路很长:先要向 APIServer 发一个 POST 请求,再要等 Scheduler 收到新 Pod 资源被创建的事件,再等 Scheduler 在所有的 Node 上运行一遍筛选、优选算法并把调度结果返回给 API Server,再到被选中 Node 的 Kubelet 收到事件,再到Docker 镜像拉取、容器运行,再到通过安全检查并把新的容器注册到 Service Mesh 上…
任何一个步骤都有可能出现延时、丢事件,或失败(如调度时资源不足是很常见的)。就算一切都正常工作,在一个大规模的 Kubernetes 集群里,整个链路延时达到20s,也是很常见的。
这便导致在 Kubernetes 上做 Serverless 的窘境:Serverless 的一大特点是自动扩缩容,尤其是自动从0到1,不使用时不占任何资源。但如果一个用户用 Serverless 跑自己的网站/后端,但用户的首个请求花费20s才成功,这是无法接受的。
为了解决冷启性能问题,我们团队提出了一个创造性的解决方案:使用 Pod 预热池(Pod Pool)。
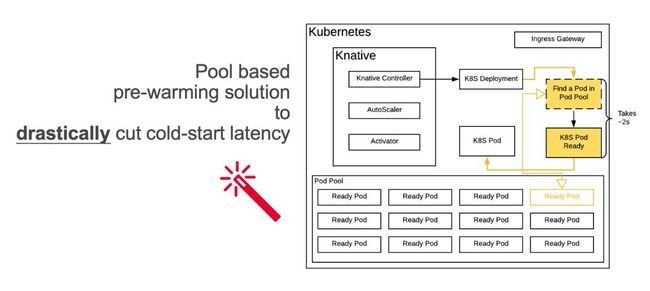
我们的产品会预先创建许多个 Pod 并让它们运行起来,当 Kubernetes 的控制器希望创建一个新的 Pod 的时候,我们不再是从零开始新建一个 Pod,而是找到一个处于待命状态的符合条件的 Pod,并把代码注入这个 Pod,直接使用。
在演讲中,我们分享了一定技术实现的细节,例如如何创建 CRD 并 fork Kubernetes 的 ControllerManager,来以较小的成本实现新 Workload;如何自动根据历史的使用数据来自动伸缩 Pod 池的水位;如何做代码注入等。我们提了3种方式,分别是给容器发指令让容器中的进程下载并执行代码包、使用 Ephemeral Container、魔改 Kubelet允许替换 Container。
实际的实现比这个还要复杂,要考虑的问题更多,例如如何响应 Pod 中不同的资源 request、limit。我们实际上也实现了一个调度器。当某个预热好的 Pod 不能满足,会看那个 Pod 所在 Node 上的资源余量,如果余量够则动态改 Kubernetes 控制面数据和 cgroups,实现“垂直扩容”。
实际操作证明,这个冷启优化的效果非常好,当 Pod 大小固定、代码包缓存存在时,启动一个最简单的 HTTP 服务器类型应用的耗时从近20秒优化到了2秒,而且由于不需要当场调度 Pod,从0到1的稳定性也提升了很多。
这个优化主要是跳过了若干次 API Server 的交互、Pod Schedule 的过程和 Service Mesh 注册的过程,用户程序从零到一的体验得到极大的提升,又不会招致过多的额外成本。一般来讲多预留10-20个 Pod 就可以应付绝大多数情况,对于少见的短时间大量应用流量激增,最坏情况也只是 fallback 到原先的新创建 Pod 的链路。
Pod 预热池不光可以用来做冷启优化,还有很多其他的应用场景。演讲中我呼吁将这种技术标准化,来解决 Kubernetes 数据面性能的问题。会后有观众提出 cncf/wg-serverless 可能有兴趣做这件事情。
三、降低成本:共享控制面组件
在成本方面,我们和大家分享了多租户改造和其他的降低成本的方式。
如果以单租户的方式运行社区版的 Knative,成本是昂贵的:需要部署 Kubernetes 控制面和 Service Mesh 控制面,因为这些都是 Knative 的依赖,Knative 本身的控制面也很占资源。十几C几十G 的机器就这样被使用了,不产生任何业务价值。因此,共享这些控制面的组件是非常必要的。
 通过共享,用户不必再单独为基础设施买单。控制面的成本也只和每个租户创建的应用的数量之和有关,而不会再和租户多少产生关联。
通过共享,用户不必再单独为基础设施买单。控制面的成本也只和每个租户创建的应用的数量之和有关,而不会再和租户多少产生关联。
我们推荐两种共享的方式,一种是 Namespace 隔离+ RBAC 权限控制,这种控制面共享的方法是最简单、Kubernetes 原生支持,也广为使用的一种方法。另一种方法是蚂蚁金服金融科技自研 Kubernetes 实现的多租户方案,通过在 etcd 中多加一级目录并把每个用户的数据存在他们自己的目录中,实现真正全方位多租户的 Kubernetes。
演讲中还提到了其他的一些降低成本的方法,如通过 Virtual Kubelet 对接阿里云的 ECI(按需的容器服务)、通过 Cluster AutoScaler 来自动释放使用率低的 Kubernetes 节点或从阿里云购置 ECS 来增加新的节点以水平扩容等。还简单提了一下多个租户的容器共享同一个宿主机可能面临的安全问题,如 Docker 逃逸。一种可能的解决方法是使用 Kata Container(虚拟机)以避免共享 Linux 内核。
四、解决容器问题:每个层级都做好对分片的支持
容量方面的挑战在于当 Workload 数量增多后,无论是 Knative 各控制器/数据面组件还是 Kubernetes 控制面本身还是 Service Mesh,都会面临更大的压力。要解决这个问题并不难,只要在从上到下每个层级都做好对分片的支持。
上游系统给每个 APP 创建一个分片 ID,下游就可以部署多组控制面组件,让每一组组件处理一个分片 ID。

要完整支持分片,我们需要改造控制面各控制器、数据面的 Knative Activator 和 Service Mesh。
控制器的改造非常容易,只需要在 Informer 中添加 LabelSelector,其值为分片 ID,控制器就只能看到那个分片 ID下的所有资源,自动无视其他资源了。每组控制器都设置不重叠的 LabelSelector,我们就可以同时运行多组互不干扰的控制器。因为控制器调和是无状态且幂等的,对于每一个分片 ID,我们仍然可以以主主的方式部署多个副本以实现高可用。
接下来是数据面 Activator 的改造,其主要挑战是如何找到每个应用对应的 AutoScaler(因为 AutoScaler 也被分片,部署了多份)。这里可以通过域名的方式来做寻址,把分片 ID 作为域名的一部分,然后搭配 DNS 记录或 Service Mesh,将 Activator 的报文路由到某个分片的 AutoScaler 里。
最后是 Service Mesh 的改造,默认情况下每个 Service Mesh 中的 Sidecar 都包含别的 Pod 的信息,所以一个含有 n 个 Pod 的 Mesh 的数据量是 O(n)。
通过 ServiceGroup,我们可以将一个 Service Mesh 分割成多个子 Service Mesh,并设为仅每个子 Service Mesh 中的 Sidecar 相互可见,来解决数据量在规模增长下激增的问题。自然的,每个子 Service Mesh 需要单独设置一个 Ingress,但这也有好处:每个 Ingress 的压力不会过高。如果要跨子 Service Mesh 访问,那可以走公网 IP 等,访问另一个子 Service Mesh 的 Ingress。改造完以上所有东西后,在单个 Kubernetes 集群里,就可以无限水平扩容了。
但当 Workload 多到一定程度,Kubernetes 控制面本身也可能成为瓶颈。这个时候,我们可以再部署一个Kubernetes,并把某些分片放到那个新的 Kubernetes 集群里,这算是更高级别的分片。巧的是,本届 KubeCon 一大火热话题也是多 Cluster:把你的全套应用打包带走,一键建立新 Kubernetes 集群并全量发布,统一运维和升级…
五、结束语

本次分享不到40分钟,现场观众约150人,关注653人,YouTube 观看目前近200人。KubeCon 的确是很不错的技术会议,有很多专业人士。更加棒的是那种包容、自由、分享的氛围,让人觉得自己是一个很大 Community 的一份子,一同进步与革新,一同做一些了不起的事情。
本次 KubeCon,我们将蚂蚁金服内部的一些技术成果带了出去和大家分享,也从这个 Community,见识了大家在搞的新技术、新产品,有很多非常棒,很值得借鉴。
在云原生 Serverless 平台模式下,我们需要处理的场景和待解决的问题还非常多,数据规模也在不断的增长,欢迎致力于云原生领域的小伙伴们加入我们,我们一起探索和创新!
分享演讲视频回顾:
https://www.youtube.com/watch?v=PA1UoLPf4nE
P.S. 团队长期招人、欢迎加入,base 支付宝上海S空间!具体岗位见次条~
本文归档在 sofastack.tech。

???? 圣诞快乐~奖励支持 SOFAStack 的你~
* 点下右下角“在看”
* 到公众号对话框发送“元旦快乐”,试试手气~
* 本期互动奖品“Istio 官网 T 恤”&“SOFAStack T 恤”