【MySQL笔记】正确的理解MySQL的索引机制以及内部实现(一)
正确的理解MySQL的索引机制以及内部实现(一)
如果觉得对你有帮助,能否点个赞或关个注,以示鼓励笔者呢?!博客目录 | 先点这里
- 第一部分 倾向于MySQL数据库索引的日常生活,主要体现MySQL索引的应用
正确的理解MySQL的索引机制以及内部实现(一) - 第二部分 更倾向于讲解MySQL B+树索引的实现原理
正确的理解MySQL的索引机制以及内部实现(二)
因为数据库索引的知识点比较多,而且感觉比较复杂和混乱!所以为了让文章更加的清晰,最终在按原目录结构写了三分之二的时候,还是决定分为两个部分分开去描述(虽然还是有很多地方没有去解释)
刚花了几小时撸了个py博客批量备份小工具,有需要可以拿走 https://github.com/SnailMann/CAB-Tool
- 前提概要
- 样例表
- 如何去学习MySQL的索引知识?
- MySQL索引
- 什么是索引?
- 索引的优缺点
- 索引设计的原则
- 索引相关SQL
- MySQL有哪些索引
- MySQL索引的分类
- 单列索引
- 组合索引
- 其他相关问题
- 索引是越建越多,越好吗?
- 不同类型字段隐式转换导致索引失效
前提概要
说明的表
以下是用于解释索引的样例表
建表语句
create table `student` (
`sid` int(11) not null,
`name` varchar(20) not null,
`age` int(11) not null,
`tel` varchar(11) not null,
`email` varchar(20) not null,
`class` varchar(20) not null,
primary key (`sid`),
unique name(`name`),
index age(`age`),
index tel_email(`tel`,`email`)
) engine=innodb default charset=utf8;
插入数据
insert into student values(1,"Jerry",22,"123451","[email protected]","计算机1班");
insert into student values(2,"Tom",22,"123452","[email protected]","计算机2班");
insert into student values(3,"Mark",20,"123453","[email protected]","计算机3班");
insert into student values(4,"Jack",19,"123454","[email protected]","计算机4班");
表与数据
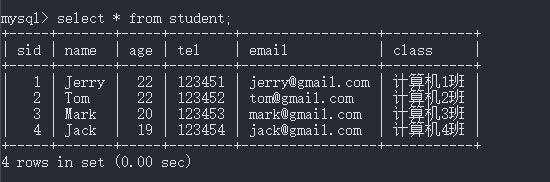
表中的索引
sid(学号)是主键索引name(姓名)是唯一非空索引age(年龄)是普通索引tel(电话),email(邮箱)是组合索引class(班级)列没有生成索引

如何去学习MySQL的索引知识?
由于本文的主要性质是自己的笔记总结,是自己学习过程思路的整理。因为索引的知识点的确比较繁琐,所以简单的我说一下我在学习数据库索引机制的步骤和方式。
(一)首先要了解什么是索引?索引是干嘛呢,有什么好处
- 了解一下什么是索引,它能给我们带来什么好处?
- 索引的底层实现数据结构一般是什么,不同存储引擎的索引底层实现有区别吗?
- 我们使用索引需要注意什么事情,按照什么样的原则去建立索引?
(二)了解MySQL在功能上,给我们提供了什么索引?
- 了解单列索引的主键索引,唯一索引,普通索引以及全文索引
- 了解一下什么是组合索引,明白组合索引的
最左前缀原则,然后大概就知道MySQL的索引要怎么用了 - 有时间最好要了解如何分析索引命中(explain),至少得知道怎么才算走了索引
- 然后了解一下MySQL应用层面上的坑坑哇哇
(三)准备入门MySQL索引的底层实现(B+ Tree索引)
- 因为通常的MySQL索引底层实现主要是B+树,所以需要先把索引会涉及的
基础数据结构打个补丁,比如二叉搜索树,平衡二叉搜索树,B树,B+树。 - 区分一下索引底层实现的一些内部概念,如
主键索引(primary index),辅助键索引(secondary index) - 再区分一下
聚簇索引(clustered index)和非聚簇索引(non-clustered index)的概念分别是什么意思? - 在这个阶段,会很容易的出现概念性的混乱,因为大家都叫索引,但却有时候不是属于一个维度的东西
- 了解MySQL下InnoDB引擎和MyISAM引擎分别通过B+ Tree索引查询的过程
(四)如果你还想了解其他索引的实现的话,可以看看
- 了解什么是
BitMap索引 - 了解
哈希索引和自哈希索引 - 了解全文检索中的
倒排索引
索引
什么是索引?
什么是索引:
- 索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则在表中搜索所有的行相比,索引有助于更快地获取信息
- 通俗的讲,索引就是数据的目录,就像看书一样,假如我想看第三章第四节的内容,如果有目录,我直接翻目录,找到第三章第四节的页码即可。如果没有目录,我就需要将从书的开头开始,一页一页翻,直到翻到第三章第四节的内容。
索引的优缺点
索引的优点:
- 通过创建唯一索引,可以保证每一行数据的唯一性
- 可以大大提高查询速度
- 可以加速表与表的连接
- 可以显著的减少查询中分组和排序的时间
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的缺点:
- 创建索引需要时间,后期创建的索引,创建开销时间与表数据量呈正相关
- 创建索引时,需要对表加锁,在锁表的同时,可能会影响到其他的数据操作
- 索引需要磁盘的空间进行存储,如果针对单表创建了大量的索引,可能比数据文件更快达到大小上限
- 当对表中的数据进行CRUD的时,也会触发索引的维护,而维护索引需要时间,可能会降低数据操作的性能
索引设计的原则
不应该:
- 索引不是越多越好。索引太多,维护索引需要时间,同时索引也需要占用磁盘资源
- 频繁更新的数据,不宜建索引。 数据频繁更新,触发索引频频维护,降低写速度
- 数据量小的表没必要建立索引。数据量过小,建索引等于多此一举,还增加了操作复杂度
应该:
- 重复率小的列建议生成索引。因为重复数据少,索引树查询更有效率
- 数据具有唯一性,建议生成唯一性索引。在数据库的层面,保证数据正确性
- 频繁group by、order by的列建议生成索引。可以大幅提高分组和排序效率
- 经常用于查询条件的字段建议生成索引。通过索引查询,速度更快
索引相关SQL
查看表中的索引
show index from {table_name}
添加索引
# 创建表
CREATE TABLE {table_name}(
...
INDEX {index_name}({column_name})
);
# 修改表
alter table {table_name} add unique index {index_name}({column_name}); # 唯一索引
alter table {table_name} add index {index_name}({column_name}); # 普通索引
create index {index_name} on {table_name}({column_name}); # 普通索引
删除索引
drop index {index_name} on {table_name};
alter table {table_name} drop index {index_name}
查看索引命中情况
explain select * from {table_name} where {column_name} = xxx;
对于Explain不清楚的同学,可以看这篇文章 理解索引:MySQL执行计划详细介绍 - @作者:情情说
MySQL有哪些索引
MySQL索引的分类
我们根据对以列属性生成的索引大致分为两类:
单列索引
以该表的单个列,生成的索引树,就称为该表的单列索引组合索引
以该表的多个列组合,一起生成的索引树,就称为该表的组合索引
然后单列索引又有具体细的划分:
主键索引
以该表主键生成的索引树,就称为该表的主键索引唯一索引
以该表唯一列生成的索引树,就称为该表的唯一索引普通索引
以该表的普通列(非主键,非唯一列)生成的索引树,就称为该表的普通索引全文索引
单列索引
主键索引
主键索引,既主索引,以主键列生成的索引,每张表只有一个主键索引,不允许重复,不允许有空值(Null)
alter table student drop index `PRIMARY`; # 删除主索引
alter table student add primary key pk_index(`sid`); # 添加
基本查询的索引命中

唯一索引
唯一索引,以唯一列生成的索引,该列不允许有重复值,但允许有空值(Null)
- 在数据库的角度中,
NULL!=NULL, 所以唯一索引列,可以由多个空值,但这样的一个做饭,不符合我们的常规理解,所以要特别注意 - 主键索引也是一种唯一索引,但主键索引不能有空值(Null)
alter table student drop index `name`; # 删除主索引
alter table student add unique index name(`name`); # 添加
基本查询的索引命中

普通索引
普通索引,以普通列生成的索引,没有任何限制
alter table student drop index `age`; # 删除主索引
alter table student add index age(`age`); # 添加
此时的age是普通索引,class无索引,分别根据age和class进行查询,使用explain分析语句,会发现第一个的type是ref,代表使用了索引。第二张图的type是ALL, 代表全部查询


全文索引
全文索引通常使用大文本对象的列去构建索引,索引底层实现是FULLINDEX
alter table student add fulltext index ft_index(`class`); # 添加全文索引
alter table student drop index `ft_index`; # 删除全文索引

组合索引
组合索引
组合索引,相对单列索引,组合索引是用多个列组合构建的索引
alter table student add index tel_email(`tel`,`email`); # 添加tel列和email列的组合索引
alter table student drop index `tel_email`; # 删的tel_email组合索引
通常,组合索引又多个列组成,所以有时有可能因为多个列名过长,导致正棵组合索引树的键大小过大,降低了存储和查询的效率。所以为了避免出现这样的情况,可以适当的保证每一列的名字不要太长,或只取组合索引每一列前几个字符组成索引
最左前缀匹配原则
最左前缀匹配原则
- 在MySQL建立组合索引时会遵循最左前缀匹配的原则,即最左优先,在检索数据时从组合索引的最左边开始匹配
alter table student add index tel_email(`tel`,`email`);
比如我们的说明表中,我们以tel列和email列生成一个组合索引,按照最左优先,我们要把最常作为检索或排序的列放在最左边,依次递减。因为这个组合索引相当于建立了(tel),(tel,email)两个索引。因为我们的样例只有连个列,效果不够明显。我们以三个列的组合索引举例,如下
alter table table_name add index col1_col2_col3(`col1`,`col2`,col3);
那么根据最左前缀匹配原则,最终相当于生成(col1),(col1,col2),(col1,col2,col3)三个索引。哈哈,有看出什么问题吗?那就是这样三个列的组合索引并不是全排列,是有严格顺序的最左优先匹配,既跟(col2),(col3),(col2,col3)等索引没有必要联系,不会产生与他们等价的效果
所以使用组合索引时一定要记住这一点,最查用的匹配列,在建索引时,优先放在最左边。另外组合索引实际还是一个索引,并非真的创建了多个索引,只是产生的效果等价于产生多个索引。
使用组合索引的好处
减少开销
建一个组合索引(col1,col2,col3),实际产生的作用等价于建了(col1),(col1,col2),(col1,col2,col3)三个索引。而我们知道,索引也是站磁盘空间的,每多一个索引,不仅增加磁盘空间的开销,还多了一棵索引的查询。对于大量数据的表,使用联合索引会大大的减少开销!覆盖索引(下一篇会说)
对于组合索引(col1,col2,col3),如果有如下的select col1,col2,col3 from table where col1=1 and col2=2。那么MySQL可以通过直接一遍历次该组合索引,便可以取到col1,col2,col3三列的数据,而无需回表,这就减少了很多的IO操作效率高
索引列越多,通过索引筛选出的数据越少。有1000w条数据的表,如果有如下的select from table where col1=1 and col2=2 and col3=3的SQL。假设每个条件可以筛选出10%的数据,如果三个条件均是单列索引,那么通过col1索引能筛选出1000w * 10%=100w条数据,然后再回表从100w条数据中找到符合col2=2的数据(100w * 10% = 10w), 依次回表,最后从结果数据中找出满足col3= 3的数据。而如果是组合索引,通过一棵索引树就能直接筛选出1000w * 10% * 10% * 10% = 1w的最终数据,效率提升可想而知!
Mysql联合索引最左匹配原则 - @princekin
其他问题
索引是越建越多,越好吗?
数据库索引是越多越好吗?非也非也 。虽然很多情况下, 建立索引能够很好的加快数据库的查询, 但也不是什么都需要建索引的,索引建的过多,反而会引起一定的不良作用,导致性能降低。比如说:
- 假设我们一个表的字段很多,但是实际行记录很少。如果我们为每个列都生成一个索引,这很容易就导致该表的索引文件远大于行记录数据本身,这就造成了一定的资源浪费,在占据大量磁盘资源的基础上,还因为行数据量太小,索引根本起不来作用。
- 建立的索引越多,说明需要维护的索引树越多。每当新增,删除一个行记录,或是更新单行或多行的列数据,都需要对涉及的索引树进行维护。而维护的过程也是需要有性能消耗的,在涉及索引过多的情况下,每次的数据库写操作都需要耗费大量的时间, 这就大大降低了数据库写的性能
所以我们要注意索引原则中的三大不应该:
- 索引不是越多越好。索引太多,维护索引需要时间,同时索引也需要占用磁盘资源
- 频繁更新的数据,不宜建索引。 数据频繁更新,触发索引频频维护,降低写速度
- 数据量小的表没必要建立索引。数据量过小,建索引等于多此一举,还增加了操作复杂度
索引失效的场景
模糊搜索,左模糊或全模糊都会导致索引失效,比如'%key'和'%key%'。但是右模糊是可以利用索引的,比如'key%'隐式类型转换,比如select * from name = xxx, name是字符串类型,但是没有加引号,所以是由MySQL隐式转换的,所以会让索引失效当语句中带有or的时候,比如select * from table where name=‘snailmann’ or age=20不符合联合索引的最左前缀匹配, (A,B,C)的联合索引,你只where了C或B或只有B,C
不同类型字段隐式转换导致索引失效
问题描述
假设,我们要指向一个查询语句select * from xxx where xxx = xxx,查询条件是建立了索引的字段,字段类型为varchar, 但我们的SQL条件实际传入的是int类型,那么猜测一下,这条查询语句会走索引吗?
测试数据
student表定义
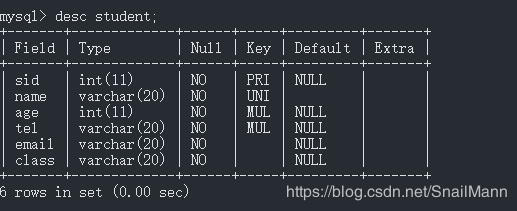
student表的索引定义

测试
我们的student表的tel字段是一个组合索引,类型是varchar。所以我们就拿tel电话字段来测试一下
- (1) 执行SQL
explain select * from student where tel = 123451;
我们发现,因为123451没有引号,传入数值类型。所以explain语句的分析中,type类型是ALL,说明走的是全表查询,并没有走索引。

- (2) 执行SQL
explain select * from student where tel = '123451';
当我们给参数加上了引号,代表字符类型后,type类型变成了ref,走的是普通索引,并没有全部查询

结论
- 再写SQL语句的时候,要尽量的避免出现类型不一致的情况,因为MySQL的隐式类型转换,很可能会导致查询没有走索引,从而导致查询性能低下。
参考资料
- 《MySQL技术内幕》
- 深入理解MySQL索引原理和实现——为什么索引可以加速查询?
- 数据库索引的作用和优点缺点以及索引的11中用法 - @作者:菜鸟程序猿
- mysql--------四种索引类型 - @作者:切切歆语
- Mysql联合索引最左匹配原则 - @princekin
- 通俗易懂 索引、单列索引、复合索引、主键、唯一索引、聚簇索引、非聚簇索引、唯一聚簇索引 的区别与联系 - @知乎
- 如果觉得对你有帮助,能否点个赞或关个注,以示鼓励笔者呢?!