使用Tesseract对图片文字OCR识别
前言
想用Python对身份证图片进行OCR识别,提取出身份证上面的文字,但是不想依赖网络上提供的第三方的接口(比如Face++提供的身份证OCR识别),因为将身份证的照片上传到这样的接口进行识别,很可能会泄露用户的隐私信息等。所以就想用Python在本地进行图片文字OCR识别。
Tesseract是一款被广泛使用的开源 OCR 工具,本文将对其进行简单的介绍,先配置安装好Tesseract,为后续用Python在本地调用tesseract提供基础。
目录
文章目录
- 前言
- 目录
- 关于Tesseract
- 笔者的电脑环境
- 获取,安装与配置
- tesseract命令的格式
- 测试
- 测试对英文数字混合的四位验证码的识别
- 测试对英文文本图片的识别
- 测试对中文文本图片的识别
- 测试对身份证图片的识别
- 测试对模糊的中文文本的图片的识别
- 后续想法
- Python调用tesseract的两种方法
- 参考资料
关于Tesseract
所谓 OCR 是图像识别领域中的一个子领域,该领域专注于对图片中的文字信息进行识别并转换成能被常规文本编辑器编辑的文本。
Tesseract是一个流行的OCR(Optical Character Recognition,光学字符识别)库,通俗来说就是文本识别。Tesseract最初由HP(就是惠普啦)在1985年开始研发,后面貌似就没啥太重大的进展了;直到2005年HP将Tesseract开源,2006年开始交给Google维护。
Tesseract 已经有 30 年历史,开始它是惠普实验室的一款专利软件,然后在 2005 年开源,自 2006 年后由 Google 赞助进行后续的开发和维护。
在 1995 年 Tesseract 曾是世界前三的 OCR 引擎,而且在现在的免费 OCR 引擎中,其识别精度也仍然是出类拔萃的。因为其免费与较好的效果,许多的个人开发者以及一些较小的团队在使用着 Tesseract ,诸如验证码识别、车牌号识别等应用中,不难见到 Tesseract 的身影。
Tesseract在进入3.0版本后各方面功能都有了长足的发展,尤其是3.02.02版本开始提供C-API,使得通过动态链接库与其他编程语言混合开发成为了可能。
笔者的电脑环境
Windows10教育版 64位 1709 (OS内部版本:16299.371)
获取,安装与配置
1、下载tesseract-ocr软件。点这里进入软件下载页面。
选择4.0.0-alpha for Windows下面的 Windows Installer made with MinGW-w64 from UB Mannheim,点击UB Mannheim进入另一网页。
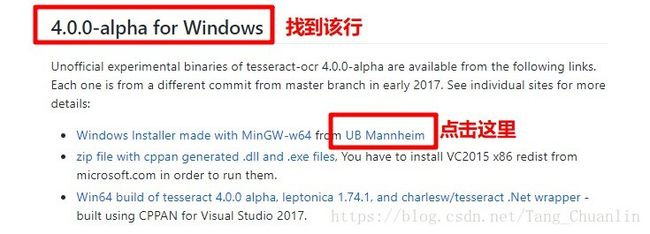
进入的另一网页的网址为https://github.com/UB-Mannheim/tesseract/wiki。
点击tesseract-ocr-setup-4.0.0-alpha.20180109.exe,下载4.0版本的软件.

注:下载链接会根据软件版本更新,下载地址会不断更新。大家可以到网页自行查找下载链接。
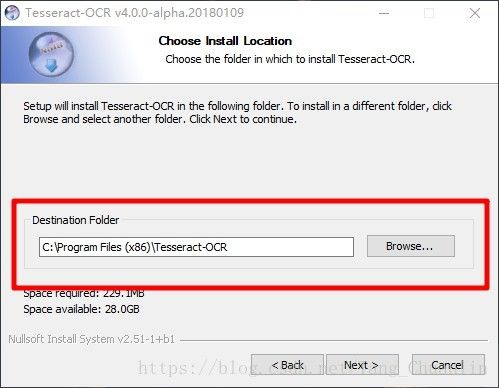
2、下载好的软件安装包如图,双击安装软件。安装过程按照下面的图片指示进行。

注意选择安装语言包,包含英文(默认安装)、中文、数学公式等,可以根据需要自己下载。






3、点击这里进入下载最新的tessdata(训练好的数据),下载后解压到tesseract-OCR的安装目录下的tessdata文件夹。

4、配置环境变量。在path环境变量中加入tesseract-OCR的安装目录。


5、按下windows + R 输入 cmd 打开命令行窗口。键入tesseract --list-langs可查看到tessdata文件夹下所有训练好的数据。

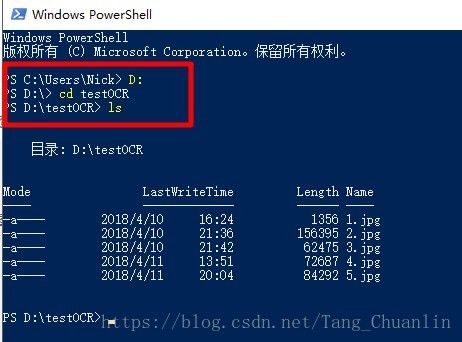
7、按下windows + R 输入 cmd 打开命令行窗口。键入D:按回车进入D盘,键入cd testOCR按回车进入“testOCR”文件夹,键入ls按回车可看到刚刚准备好的用于测试的5张图片。
tesseract命令的格式
tesseract命令的格式为:
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
其中imagename为输入图片路径,outputbase为输出文本文件路径,此文本文件内容为图片文本识别结果。
测试
笔者分别找了几张带文字的图片放到了D盘testOCR文件夹下准备用于测试。

测试对英文数字混合的四位验证码的识别
在命令行窗口键入tesseract 1.jpg 1.txt按回车,到D盘testOCR文件夹下打开1.txt可看到识别的结果。如下图。


测试对英文文本图片的识别
在命令行窗口键入tesseract 2.jpg 2.txt按回车,到D盘testOCR文件夹下打开1.txt可看到识别的结果。如下图。
![]()

测试对中文文本图片的识别
在命令行窗口键入tesseract 3.jpg 3.txt -l chi_sim按回车,到D盘testOCR文件夹下打开1.txt可看到识别的结果。如下图。
![]()

测试对身份证图片的识别
在命令行窗口键入tesseract 4.jpg 4.txt -l chi_sim按回车,到D盘testOCR文件夹下打开1.txt可看到识别的结果。如下图。


测试对模糊的中文文本的图片的识别
在命令行窗口键入tesseract 5.jpg 5.txt -l chi_sim按回车,到D盘testOCR文件夹下打开1.txt可看到识别的结果。如下图。
![]()

后续想法
由上的测试可看出对识别英文准确率要高一些,对中文的识别还有一些错别字,对身份证的文字识别准确率上还不够,所以想让Python先对图片进行一定处理后,再用python调用Tesseract对图片文字OCR识别。
Python调用tesseract的两种方法
1、通过shell与tesseract通信完成识别过程;
2、通过动态链接库(Windows下即DLL)实现。
参考资料
1、Python:文本识别抛弃pytesser,直接使用Tesseract
2、Tesseract:安装与命令行使用
3、图片文字OCR识别-tesseract-ocr4.00.00安装使用
4、tesseract安装使用