refineDet
refineDet
motivation
one stage目标检测准确率低的原因是因为 class imbalance problem。
已有的一些解决方案{
- object prior constraint[24]
- reshaping the standard cross entropy loss to focus on hard examples[28]
- max-out labeling mechanism[53]
}
two stage 工作的advantages{
- two stage 结构做 sampling heuristics 采样探索 来处理 class imbalance problem
- 两步级联地去回归 object box parameters
- two stage features 来描述objects–> RPN 特征 预测二分类(object / background), stage2 预测 多分类(BG and objects classes) 本文借鉴了这种两次分类的好处
}
structure 两个模块
- anchor refinement module ARM *****
- objection detection module ODM
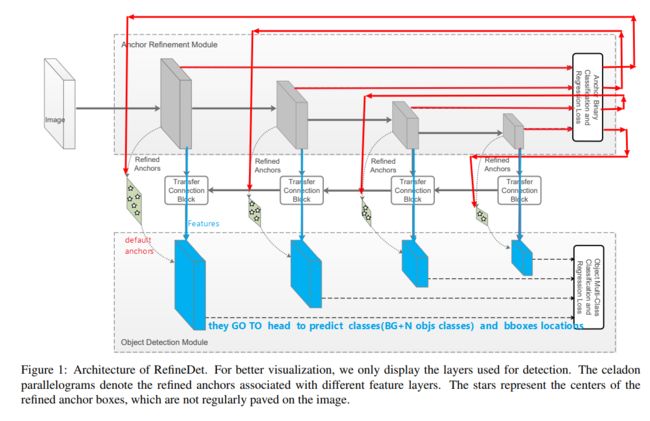
整个模型的结构可以分解为三部分
- backbone ---------> Features[F1,F2,F3,F4]
- necks 包括 FPN(blue path ) + ARM(red path) --------->refine anchors[A1,…A4] +FPNfeatures[F1’…F4’]
- head (SSD head 或者retina head) ----------->predict multi classes + bbox loc
为了方便理解,我们可以把ARM模块化成红色的path, 把FPN 特征金字塔化成蓝色的path。这样理解, refineDet的anchor refine 就比较好理解成一个module了.
ARM 实际上很像two stage 模型里RPN 承担的作用,paper中也说是在imitate two stage模型
细节
-
采用
jaccard overlap[7] 对应anchors和GTbox, 1 match给每个gtbox 一个与它overlap最大的anchor, 2 match所有anchor boxs 到 与其overlap 大于0.5 的gtbox。 -
anchor 选择的正负样本比例 nagtives:positives==3:1 ,选择 loss值大的 负样本anchors,而不是选择全部负样本anchor或者随机选择负样本anchor
代码
https://github.com/luuuyi/RefineDet.PyTorch
模型代码
#main model
class RefineDet(nn.Module):
"""Single Shot Multibox Architecture
The network is composed of a base VGG network followed by the
added multibox conv layers. Each multibox layer branches into
1) conv2d for class conf scores
2) conv2d for localization predictions
3) associated priorbox layer to produce default bounding
boxes specific to the layer's feature map size.
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
Args:
phase: (string) Can be "test" or "train"
size: input image size
base: VGG16 layers for input, size of either 300 or 500
extras: extra layers that feed to multibox loc and conf layers
head: "multibox head" consists of loc and conf conv layers
"""
def __init__(self, phase, size, base, extras, ARM, ODM, TCB, num_classes):
super(RefineDet, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.cfg = (coco_refinedet, voc_refinedet)[num_classes == 21]
self.priorbox = PriorBox(self.cfg[str(size)])
with torch.no_grad():
self.priors = self.priorbox.forward()
self.size = size
# SSD network
self.vgg = nn.ModuleList(base)
# Layer learns to scale the l2 normalized features from conv4_3
self.conv4_3_L2Norm = L2Norm(512, 10)
self.conv5_3_L2Norm = L2Norm(512, 8)
self.extras = nn.ModuleList(extras)
self.arm_loc = nn.ModuleList(ARM[0])
self.arm_conf = nn.ModuleList(ARM[1])
self.odm_loc = nn.ModuleList(ODM[0])
self.odm_conf = nn.ModuleList(ODM[1])
#self.tcb = nn.ModuleList(TCB)
self.tcb0 = nn.ModuleList(TCB[0])
self.tcb1 = nn.ModuleList(TCB[1])
self.tcb2 = nn.ModuleList(TCB[2])
if phase == 'test':
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect_RefineDet(num_classes, self.size, 0, 1000, 0.01, 0.45, 0.01, 500)
def forward(self, x):
"""Applies network layers and ops on input image(s) x.
Args:
x: input image or batch of images. Shape: [batch,3,300,300].
Return:
Depending on phase:
test:
Variable(tensor) of output class label predictions,
confidence score, and corresponding location predictions for
each object detected. Shape: [batch,topk,7]
train:
list of concat outputs from:
1: confidence layers, Shape: [batch*num_priors,num_classes]
2: localization layers, Shape: [batch,num_priors*4]
3: priorbox layers, Shape: [2,num_priors*4]
"""
sources = list()
tcb_source = list()
arm_loc = list()
arm_conf = list()
odm_loc = list()
odm_conf = list()
--------------------1------------------------------------------------
# apply vgg up to conv4_3 relu and conv5_3 relu
for k in range(30):
x = self.vgg[k](x)
if 22 == k:
s = self.conv4_3_L2Norm(x)
sources.append(s)
elif 29 == k:
s = self.conv5_3_L2Norm(x)
sources.append(s)
# apply vgg up to fc7
for k in range(30, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)
# apply extra layers and cache source layer outputs
for k, v in enumerate(self.extras):
x = F.relu(v(x), inplace=True)
if k % 2 == 1:
sources.append(x)
-----------------------------------------------------------------
------------------------2-----------------------------------------------
# apply ARM and ODM to source layers
for (x, l, c) in zip(sources, self.arm_loc, self.arm_conf):
arm_loc.append(l(x).permute(0, 2, 3, 1).contiguous())
arm_conf.append(c(x).permute(0, 2, 3, 1).contiguous())
arm_loc = torch.cat([o.view(o.size(0), -1) for o in arm_loc], 1)
arm_conf = torch.cat([o.view(o.size(0), -1) for o in arm_conf], 1)
#print([x.size() for x in sources])
# calculate TCB features
#print([x.size() for x in sources])
----------------------------------------------------------------------
-----------------------3----------------------------------------------
p = None
for k, v in enumerate(sources[::-1]):
s = v
for i in range(3):
s = self.tcb0[(3-k)*3 + i](s)
#print(s.size())
if k != 0:
u = p
u = self.tcb1[3-k](u)
s += u
for i in range(3):
s = self.tcb2[(3-k)*3 + i](s)
p = s
tcb_source.append(s)
#print([x.size() for x in tcb_source])
tcb_source.reverse()
-------------------------------------------------------------------------
------------------------4---------------------------------------------
# apply ODM to source layers
for (x, l, c) in zip(tcb_source, self.odm_loc, self.odm_conf):
odm_loc.append(l(x).permute(0, 2, 3, 1).contiguous())
odm_conf.append(c(x).permute(0, 2, 3, 1).contiguous())
odm_loc = torch.cat([o.view(o.size(0), -1) for o in odm_loc], 1)
odm_conf = torch.cat([o.view(o.size(0), -1) for o in odm_conf], 1)
#print(arm_loc.size(), arm_conf.size(), odm_loc.size(), odm_conf.size())
-------------------------------------------------------------------------
------------------------------5-------------------------------------
if self.phase == "test":
#print(loc, conf)
output = self.detect(
arm_loc.view(arm_loc.size(0), -1, 4), # arm loc preds
self.softmax(arm_conf.view(arm_conf.size(0), -1,
2)), # arm conf preds
odm_loc.view(odm_loc.size(0), -1, 4), # odm loc preds
self.softmax(odm_conf.view(odm_conf.size(0), -1,
self.num_classes)), # odm conf preds
self.priors.type(type(x.data)) # default boxes
)
else:
output = (
arm_loc.view(arm_loc.size(0), -1, 4),
arm_conf.view(arm_conf.size(0), -1, 2),
odm_loc.view(odm_loc.size(0), -1, 4),
odm_conf.view(odm_conf.size(0), -1, self.num_classes),
self.priors
)
return output
主要是forward 方法,简单分成五个part分析。
1- backbone卷积网络提取特征,得到输出应该是四个尺度的features [F1,…F4]
2- ARM模块预测得到bbox的回归和anchor正负样本的二分类结果。,这个结果暂存,arm_loc + arm_conf
3- paper中的TCB 模块从高层特征向底层特征融合,实际上类似FPN特征金字塔,得到新的四个尺度features [F1’…F4’]
4- 第三步的四个尺度特征送入 anchor head ,预测bbox的回归和所有object多类别的分类结果。odm_loc + odm_conf.
5- 如果是test时,把arm_loc + arm_conf odm_loc + odm_conf. 送入一个detect的类,预测得到最终的bbox。
解释一下这个过程,在目标检测中我们预测的bbox实际上是一个编码了的长度为4的vector,而不是实际的坐标或者长宽(这一点如果不知道看faster RCNN等paper)。
那么, 在第五步,我们送入detect类完成的就是根据预测的bbox location解码(decode)得到实际的坐标。
首先, anchor refine module(ARM)预测得到arm_loc,
arm_anchors = decode(arm_Loc,predefined_anchor)
#predefined_anchor是参数定义的anchors,它没有编码,就是实际坐标值,也就是faster RCNN中说的default anchors
#arm_loc 是ARM模块预测的、编码的、预测loc
#arm_anchors = 根据 上面两个参数解码出来预测bbox的实际空间坐标值。
其次, ODM模块预测得到的odm_loc,就不是根据事先定义的default anchors去解码了,而是根据刚刚得到的arm_anchors 去解码。
这也就是本文的核心-----------> anchor refine
odm_bbox = decode(odm_loc, arm_anchors)
# odm_loc是预测的、编码了的 bbox loc
# arm_anchors and odm_bbox都是实际的空间坐标。
上面是test阶段,如果是train时,就不需要refine这个anchor啦, 直接把
output = (
arm_loc.view(arm_loc.size(0), -1, 4),
arm_conf.view(arm_conf.size(0), -1, 2),
odm_loc.view(odm_loc.size(0), -1, 4),
odm_conf.view(odm_conf.size(0), -1, self.num_classes),
self.priors
)
送出去计算loss咯, 跟two stage 的模型一样,总的loss 有四项,arm_Loc arm_conf odm_loc odm_conf
其他代码细节,可以参考 https://github.com/luuuyi/RefineDet.PyTorch
References
[1] S. Bell, C. L. Zitnick, K. Bala, and R. B. Girshick. Insideoutside net: Detecting objects in context with skip pooling
and recurrent neural networks. In CVPR, pages 2874–2883,
2016. 3, 6, 7, 8
[2] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis. Improving object detection with one line of code. In ICCV, 2017. 7,
8
[3] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos. A unified
multi-scale deep convolutional neural network for fast object
detection. In ECCV, pages 354–370, 2016. 1, 3
[4] L. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L.
Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In ICLR, 2015. 4
[5] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: object detection via
region-based fully convolutional networks. In NIPS, pages
379–387, 2016. 1, 3, 6, 7, 8
[6] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei.
Deformable convolutional networks. In ICCV, 2017. 7, 8
[7] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable
object detection using deep neural networks. In CVPR, pages
2155–2162, 2014. 4
[8] M. Everingham, L. J. V. Gool, C. K. I. Williams, J. M. Winn,
and A. Zisserman. The pascal visual object classes (VOC)
challenge. IJCV, 88(2):303–338, 2010. 1, 3
[9] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn,
and A. Zisserman. The Leaderboard of the PASCAL
Visual Object Classes Challenge 2012 (VOC2012). http:
//host.robots.ox.ac.uk:8080/leaderboard/
displaylb.php?challengeid=11&compid=4.
Online; accessed 1 October 2017. 8
[10] M. Everingham, L. Van Gool, C. K. I. Williams,
J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. http:
//www.pascal-network.org/challenges/VOC/
voc2007/workshop/index.html. Online; accessed
1 October 2017. 2
[11] M. Everingham, L. Van Gool, C. K. I. Williams,
J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. http:
//www.pascal-network.org/challenges/VOC/
voc2012/workshop/index.html. Online; accessed
1 October 2017. 2, 3
[12] P. F. Felzenszwalb, R. B. Girshick, D. A. McAllester, and
D. Ramanan. Object detection with discriminatively trained
part-based models. TPAMI, 32(9):1627–1645, 2010. 3
[13] C. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg.
DSSD : Deconvolutional single shot detector. CoRR,
abs/1701.06659, 2017. 3, 5, 6, 7
[14] S. Gidaris and N. Komodakis. Object detection via a multiregion and semantic segmentation-aware CNN model. In
ICCV, pages 1134–1142, 2015. 3, 6
[15] R. B. Girshick. Fast R-CNN. In ICCV, pages 1440–1448,
2015. 1, 3, 5, 6, 7
[16] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich
feature hierarchies for accurate object detection and semantic
segmentation. In CVPR, pages 580–587, 2014. 3
[17] X. Glorot and Y. Bengio. Understanding the difficulty of
training deep feedforward neural networks. In AISTATS,
pages 249–256, 2010. 5
[18] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling
in deep convolutional networks for visual recognition. In
ECCV, pages 346–361, 2014. 3
[19] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning
for image recognition. In CVPR, pages 770–778, 2016. 3, 4,
7, 8
[20] A. G. Howard. Some improvements on deep convolutional neural network based image classification. CoRR,
abs/1312.5402, 2013. 4
[21] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara,
A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, and
K. Murphy. Speed/accuracy trade-offs for modern convolutional object detectors. In CVPR, 2017. 5, 7, 8
[22] S. Ioffe and C. Szegedy. Batch normalization: Accelerating
deep network training by reducing internal covariate shift. In
ICML, pages 448–456, 2015. 4
[23] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. B.
Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. In ACMMM,
pages 675–678, 2014. 5
[24] T. Kong, F. Sun, A. Yao, H. Liu, M. Lu, and Y. Chen. RON:
reverse connection with objectness prior networks for object
detection. In CVPR, 2017. 1, 3, 5, 6, 7, 8
[25] T. Kong, A. Yao, Y. Chen, and F. Sun. Hypernet: Towards accurate region proposal generation and joint object detection.
In CVPR, pages 845–853, 2016. 3, 6
[26] H. Lee, S. Eum, and H. Kwon. ME R-CNN: multi-expert
region-based CNN for object detection. In ICCV, 2017. 3
[27] T. Lin, P. Dollar, R. B. Girshick, K. He, B. Hariharan, and ´
S. J. Belongie. Feature pyramid networks for object detection. In CVPR, 2017. 1, 3, 7
[28] T. Lin, P. Goyal, R. B. Girshick, K. He, and P. Dollar. Focal ´
loss for dense object detection. In ICCV, 2017. 1, 3, 7, 8
[29] T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick. Microsoft COCO: com- ´
mon objects in context. In ECCV, pages 740–755, 2014. 1,
2, 3, 8
[30] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed,
C. Fu, and A. C. Berg. SSD: single shot multibox detector.
In ECCV, pages 21–37, 2016. 1, 3, 4, 6, 7, 8
[31] W. Liu, A. Rabinovich, and A. C. Berg. Parsenet: Looking
wider to see better. In ICLR workshop, 2016. 4
[32] P. H. O. Pinheiro, R. Collobert, and P. Dollar. Learning to ´
segment object candidates. In NIPS, pages 1990–1998, 2015.
3
[33] P. O. Pinheiro, T. Lin, R. Collobert, and P. Dollar. Learning ´
to refine object segments. In ECCV, pages 75–91, 2016. 3
[34] J. Redmon, S. K. Divvala, R. B. Girshick, and A. Farhadi.
You only look once: Unified, real-time object detection. In
CVPR, pages 779–788, 2016. 3, 6
[35] J. Redmon and A. Farhadi. YOLO9000: better, faster,
stronger. CoRR, abs/1612.08242, 2016. 1, 3, 6, 7
[36] S. Ren, K. He, R. B. Girshick, and J. Sun. Faster R-CNN:
towards real-time object detection with region proposal networks. TPAMI, 39(6):1137–1149, 2017. 1, 3, 6, 7, 8
[37] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh,
S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein,
A. C. Berg, and F. Li. Imagenet large scale visual recognition
challenge. IJCV, 115(3):211–252, 2015. 3, 4, 5
[38] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus,
and Y. LeCun. Overfeat: Integrated recognition, localization
and detection using convolutional networks. In ICLR, 2014.
3
[39] Z. Shen, Z. Liu, J. Li, Y. Jiang, Y. Chen, and X. Xue. DSOD:
learning deeply supervised object detectors from scratch. In
ICCV, 2017. 3, 6, 8
[40] A. Shrivastava and A. Gupta. Contextual priming and feedback for faster R-CNN. In ECCV, pages 330–348, 2016. 3
[41] A. Shrivastava, A. Gupta, and R. B. Girshick. Training
region-based object detectors with online hard example mining. In CVPR, pages 761–769, 2016. 1, 3, 6, 7, 8
[42] A. Shrivastava, R. Sukthankar, J. Malik, and A. Gupta. Beyond skip connections: Top-down modulation for object detection. CoRR, abs/1612.06851, 2016. 3, 7, 8
[43] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR,
abs/1409.1556, 2014. 3, 4
[44] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi.
Inception-v4, inception-resnet and the impact of residual
connections on learning. In AAAI, pages 4278–4284, 2017.
4, 7
[45] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. E. Reed,
D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich.
Going deeper with convolutions. In CVPR, pages 1–9, 2015.
6
[46] J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, and
A. W. M. Smeulders. Selective search for object recognition.
IJCV, 104(2):154–171, 2013. 3
[47] P. A. Viola and M. J. Jones. Rapid object detection using a
boosted cascade of simple features. In CVPR, pages 511–
518, 2001. 3
[48] X. Wang, A. Shrivastava, and A. Gupta. A-fast-rcnn: Hard
positive generation via adversary for object detection. In
CVPR, 2017. 3
[49] S. Xie, R. B. Girshick, P. Dollar, Z. Tu, and K. He. Aggre- ´
gated residual transformations for deep neural networks. In
CVPR, 2017. 4, 8
[50] X. Zeng, W. Ouyang, B. Yang, J. Yan, and X. Wang. Gated
bi-directional CNN for object detection. In ECCV, pages
354–369, 2016. 3
[51] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li. Detecting face with densely connected face proposal network.
In CCBR, pages 3–12, 2017. 4
[52] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li.
Faceboxes: A CPU real-time face detector with high accuracy. In IJCB, 2017. 4
[53] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li.
S
3
FD: Single shot scale-invariant face detector. In ICCV,
2017. 1, 3, 4
[54] Y. Zhu, C. Zhao, J. Wang, X. Zhao, Y. Wu, and H. Lu. Couplenet: Coupling global structure with local parts for object
detection. In ICCV, 2017. 3, 5, 6, 7