娱乐头条-05solr
1.solr的基本概念
2.solr的部署
3.solr的管理界面
4.solr的配置文件
5.solr的客户端操作: solrj
6.高级
一、solr的基本概念
solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过http访问提出查找请求,并得到各种格式的返回结果。
solr本质是基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展。并对查询性能进行了优化,并且提供了一个完善的功能管理界面。
二、solr的部署
1.链接
链接:https://pan.baidu.com/s/1q8Ry0peIF3lwOemqxusWMw
提取码:jm3i
2.目录介绍


3.服务的启动
(1)启动方式一
启动步骤:
- 打开cmd窗口
- 切换目录到solr的example的目录下
- 执行 java -jar start.jar


注意: 由于jar包已经内置了一个web服务器(jetty) , 其默认的访问的为8983
(2)启动方式二(推荐)
注:最好重新解压一份Tomcat
启动步骤:
- 首先打开example目录下的webapps目录下
- 拷贝此目录下的solr.war , 将其复制到tomcat的webapps目录下
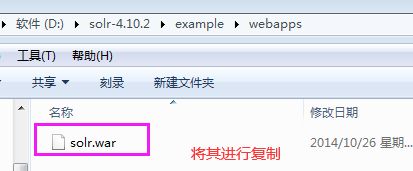

- 启动tomcat, 将war包进行解压, 然后关闭tomcat并将war包删除或者更改后缀名即可(一定要关闭Tomcat下删除或更改,否则解压后的目录会自动删除)
- 将其原有war包更改的主要目的是防止再次解压, 导致原有的设置失效
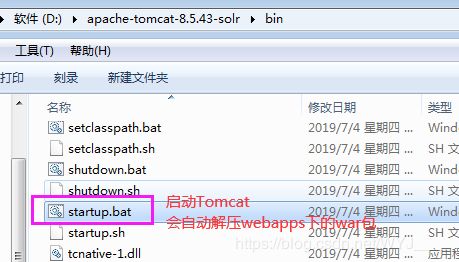

- 将资料中tomcat运行solr所需要的jar包复制到solr的web-INF下的lib目录中 ,classes目录复制到web-INF下
链接:https://pan.baidu.com/s/1mjwOHK1EBizcC5tZcSwCUw
提取码:kugn

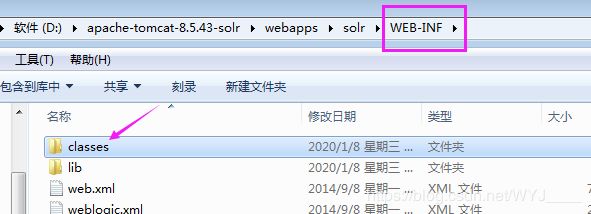
- 将example中solr的目录建议复制到和tomcat同级的目录下(方便管理)

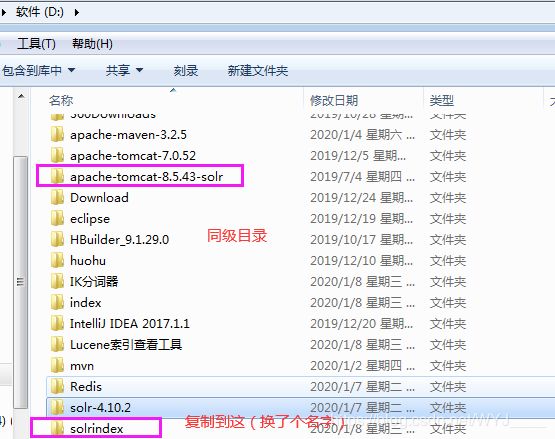
- 打开tomcat的bin目录找到Catalina.bat文件, 将其右键打开
- 将下列参数设置到此文件中即可
- set "JAVA_OPTS=-Dsolr.solr.home=目录位置"
- 注意: 目录位置就是刚刚复制过来的solr的目录

为了防止和其他Tomcat端口号冲突,最好在server.xml中更改端口号(都加一)
![]()



- 启动tomcat,访问localhost:8081/solr即可

三、solr的管理界面
- 仪表盘

- 日志窗口: 记录solr在启动过程中和启动后执行过程中的执行信息

解决警告信息:
第一步: 将solr的安装包中依赖包的两个目录, 复制到solr的索引库中


第二步: 打开索引库中的collection1中conf目录, 将solrconfif.xml右键打开, 去掉两个../即可

重新运行Tomcat,就不会出现上面的警告信息

- core 窗口: 用于配置solr的索引库
solr中支持配置和管理多个索引库, 就像数据库中有多个database是一样的

如何配置多个索引库呢?
简单方案: 将collection1复制一个,然后删除其data文件夹并修改core.properties配置文件即可

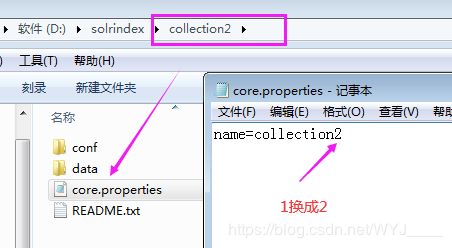
重新启动Tomcat,就会出现新添加的索引库2
针对core selector的详细讲解:

1.使用solr的管理界面进行添加索引

2.用solr的管理界面进行查询索引

四、solr的配置文件
1.solrConfig.xml : solr的核心配置文件
solrconfig.xml 配置文件主要定义了 solr 的一些处理规则,包括索引数据的存放 位置,更新,删除,查询的一些规则配置。 一般此文件不需要进行修改, 采取默认即可
2.schema.xml: solr约束文件
Solr中会提前对文档中的字段进行定义,并且在schema.xml中对这些字段的属性进行约束,例如:字段数据类型、字段是否索引、是否存储、是否分词等等
(1)field标签
主要是用来指定字段名称的, Lucene中是有用户在程序中指定, solr中需要提前在配置文件中指定
name:字段的名称
type:字段的类型,里面的内容为fieldType标签的名字
indexed:是否对字段进行索引
stored:是否保存该字段的值
multiValued:该字段是否可以存储多个值
required="true":表示添加文档时,在文档中必须要添加的字段
注:_version_ _root_ id 保留不要删掉
(2)dynamicField标签
被称为是动态字段
此种标签是为程序的扩展所使用的,因为我们不可能把所有的字段全部定义好,所以就需要动态与来进行动态扩展,弥补field标签无法详细列举的字段
(3)uniqueKey标签
必要标签, 表名文档的唯一属性, 一般默认为id
Lucene中是自己进行维护, solr中, 需要自己指定
(4)copyField标签
被称为是复制域
source: 表名要复制那个字段的值
dest: 复制到那个字段上
原字段和目标字段必须是已经使用field字段定义,而且,dest字段最好是多值字段,主要目的是用于查询
(5)fieldType标签
此种标签是用来定义字段的类型的,可以指定此字段使用何种分词器进行分词
name:字段类型的名字,用户执行field字段的字段类型
class:solr的字段类型
textFile在配置字段类型时,需要指定分词器
3.引入ik分词器
- 第一步: 导入ik相关的依赖包
- 将三个文件放置在tomcat>webapps>solr>WEB-INF>lib下(此步骤在部署solr到tomcat中的时候, 就已经导入了)
- 第二步: 导入ik相关的配置文件(ik配置文件, 扩展词典和停止词典)
- 将三个文件放置在tomcat>webapps>solr>WEB-INF>classes下(此步骤, 在部署solr到tomcat中的时候, 已经导入)
- 第三步, 在schema.xml配置文件中自定义一个字段类型, 引入ik分词器

- 第四步: 为对应的字段设置为text_ik类型即可
![]()

五、solr的客户端操作: solrj
solrj是Apache官方提供的一套java开发的, 用于操作solr服务的API, 通过这套API可以让程序与solr服务进行交互, 让java程序可以直接操作solr服务进行增删改查
1.solr的基本入门程序(原生的方式写入)
准备数据:如果想添加昨天爬取的新闻数据,修改约束文件
将自带的field删掉(除了上面强调的三个不能删);将copyField字段也删除;将下面的添加在文件中
导入相关的jar包
org.apache.solr
solr-solrj
4.10.2
commons-logging
commons-logging-api
1.1
junit
junit
4.12
@Test
public void testWriteIndex() throws Exception{
//创建solr服务对象
SolrServer server = new HttpSolrServer("http://localhost:8081/solr/collection1");
//文档对象
SolrInputDocument document = new SolrInputDocument();
document.addField("id",1);
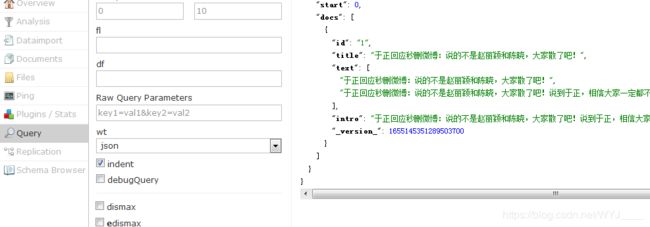
document.addField("title","于正回应秒删微博:说的不是赵丽颖和陈晓,大家散了吧!");
document.addField("intro","于正回应秒删微博:说的不是赵丽颖和陈晓,大家散了吧!说到于正,相信大家一定都不陌生吧?近两年来,于正这个名字在圈内是非常火的!有非常多的好作品都是由他“制作的”,例如:《美人心计》《宫锁心玉》!就在……");
//添加文档对象
server.add(document);
//写入索引
server.commit();
}
2.solrj写入索引2(写入多条索引)(原生的方式写入)
@Test
public void testWriteIndex2() throws Exception{
//创建solr服务对象
SolrServer server = new HttpSolrServer("http://localhost:8081/solr/collection1");
//文档对象
SolrInputDocument document1 = new SolrInputDocument();
document1.addField("id",2);
document1.addField("title","杨颖曝人生第一份工作,15岁当模特挣600港币,吴亦凡则是洗碗");
document1.addField("intro","最近,吴亦凡、Angelababy(杨颖)、赵今麦、福克斯相聚于综艺《潮流合伙人》,在日本东京合开一家潮流集合店。在最新一期的节目中,Angelababy一行四人在结束了一天的辛苦工作后,带着\"丰收……");
SolrInputDocument document2 = new SolrInputDocument();
document2.addField("id",3);
document2.addField("title","《庆余年》之后,阅文男频IP的爆款指南");
document2.addField("intro","《庆余年》爆了!屠榜各大社交平台,连平时很少追剧的小哥哥们,都开始讨论起《庆余年》了。作为引领行业的正版数字阅读平台和文学 IP 培育平台,阅文集团一直在探索男频IP开发的多种可能性,《庆余年》之后……");
List dosc = new ArrayList();
dosc.add(document1);
dosc.add(document2);
//添加文档对象
server.add(dosc);
//写入索引
server.commit();
} 3.使用solrj写入索引3(使用javabean进行写入)
- 注意事项:
- 如果使用javaBean进行数据添加时, 需要给对应要加入索引库的字段添加@Field,用来指定其实一个document字段
- javaBean中的字段必须提前在solr的schema.xml中提前定义好(前面已经定义好了)
public class News {
@Field
private Integer id;
@Field
private String title;
@Field
private String intro;
@Field
private String source;
@Field
private String vurl;
@Field
private Date publishTime;
@Override
public String toString() {
return "News{" +
"id=" + id +
", title='" + title + '\'' +
", intro='" + intro + '\'' +
", source='" + source + '\'' +
", vurl='" + vurl + '\'' +
", publishTime=" + publishTime +
'}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getIntro() {
return intro;
}
public void setIntro(String intro) {
this.intro = intro;
}
public String getSource() {
return source;
}
public void setSource(String source) {
this.source = source;
}
public String getVurl() {
return vurl;
}
public void setVurl(String vurl) {
this.vurl = vurl;
}
public Date getPublishTime() {
return publishTime;
}
public void setPublishTime(Date publishTime) {
this.publishTime = publishTime;
}
} @Test
public void testWriteIndex3() throws Exception{
//创建solr服务对象
SolrServer server = new HttpSolrServer("http://localhost:8081/solr/collection1");
News news = new News();
news.setId(4);
news.setTitle("这是标题");
news.setIntro("这是内容部分");
news.setSource("这是作者");
news.setVurl("https://www.baidu.com");
Long dateLong = new Date().getTime()* 1000 * 3600 * 8;
news.setPublishTime(new Date(dateLong));
server.addBean(news);
server.commit();
}
4.修改索引
@Test
public void testUpdateIndex() throws Exception{
//创建solr服务对象
SolrServer server = new HttpSolrServer("http://localhost:8081/solr/collection1");
//文档对象
SolrInputDocument document = new SolrInputDocument();
document.addField("id",1);
document.addField("title","一口气看完三集,BBC的重口味英剧终于开播了");
document.addField("intro","吸血鬼题材类的影视剧,一直都是影视界的宠儿。前前后后,火了很多该类的作品:HBO的《真爱如血》;舔屏级颜值的《暮光之城》;狗血多角恋的《吸血鬼日记》...诸如此类的剧集,好像都在告诉我们吸血鬼并不是……");
server.add(document);
server.commit();
}
5.删除索引
@Test
public void testDelIndex() throws Exception{
//创建solr服务对象
SolrServer server = new HttpSolrServer("http://localhost:8081/solr/collection1");
//server.deleteById("1");根据id删除
//server.deleteByQuery("*:*");删除所有
server.deleteByQuery("title:标题");//通过查询字符串进行删除
server.commit();
}6.查询操作
@Test
public void testQuery() throws Exception{
//创建solr服务对象
SolrServer server = new HttpSolrServer("http://localhost:8081/solr/collection1");
//创建solr的查询对象
SolrQuery query = new SolrQuery("*:*");//查询所有
QueryResponse response = server.query(query);
//文档的集合
SolrDocumentList documentList = response.getResults();
for(SolrDocument document:documentList){
String id = document.get("id").toString();
String title = document.get("title").toString();
System.out.println("id:"+id+"title:"+title);
}
}返回javaBean
@Test
public void testQuery2() throws Exception{
//创建solr服务对象
SolrServer server = new HttpSolrServer("http://localhost:8081/solr/collection1");
//创建Solr的查询对象
SolrQuery query = new SolrQuery("*:*");
QueryResponse response = server.query(query);
List beans = response.getBeans(News.class);
for (News news : beans) {
System.out.println(news);
}
} 注:这里会报错。因为实体类的id属性是Integer类型的,而约束文件中的id是string类型的,解决方法,将实体类的id属性换成String类型。转换成JavaBean这种查询方式不推荐
7.复杂查询
准备数据:添加多条索引(随意)
// 抽取出一个方法
public void query(SolrQuery query) throws Exception{
SolrServer server = new HttpSolrServer("http://localhost:8081/solr/collection1");
QueryResponse response = server.query(query);
SolrDocumentList documentList = response.getResults();
for(SolrDocument document:documentList){
String id = document.get("id").toString();
//String title = document.get("title").toString();
//System.out.println("id:"+id+"title:"+title);
System.out.println("id:"+id);
}
} //词条查询
@Test
public void testTerm() throws Exception{
/*
* 字段名:关键字
* 在查询时,会对关键字进行分词
* */
// SolrQuery query = new SolrQuery("*:*");
SolrQuery query = new SolrQuery("title:今天");
query(query);
}
//通配符查询
@Test
public void testWildCard() throws Exception{
/*
* *:匹配0到多个字符
* ?:匹配1个字符
* */
//SolrQuery query = new SolrQuery("title:awkwafina");
//SolrQuery query = new SolrQuery("title:awkwafin?");
SolrQuery query = new SolrQuery("title:awkwafi*");
query(query);
}
//模糊查询
@Test
public void testFuzzy() throws Exception{
/*
* 在关键字之后添加~ 表示模糊查询
* 最大编辑次数:通过新增、修改、删除可以匹配正确词条的次数,默认也为2
* ~后的数字:表示最大编辑次数
* */
//SolrQuery query = new SolrQuery("title:wkwafin~");
SolrQuery query = new SolrQuery("title:wkwafin~1");//最大编辑次数设置为1
query(query);
}
//范围查询
@Test
public void testRange() throws Exception{
/*
* id是string类型的,是按字典顺序进行排序
* 所以id:3也被查找出来
*
* []包含最大值和最小值,{}不包含最大值和最小值
* */
//SolrQuery query = new SolrQuery("id:[20 TO 40]");
//SolrQuery query = new SolrQuery("publishTime:[2010-01-01T12:00:00Z TO 2030-01-01T12:00:00Z]");
SolrQuery query = new SolrQuery("publishTime:{2010-01-01T12:00:00Z TO 2030-01-01T12:00:00Z}");
query(query);
}
//组合查询
@Test
public void testBoolean() throws Exception{
// SolrQuery query = new SolrQuery("publishTime:{2010-01-01T12:00:00Z TO 2030-01-01T12:00:00Z} OR title:awkwafi*");
SolrQuery query = new SolrQuery("NOT publishTime:{2010-01-01T12:00:00Z TO 2030-01-01T12:00:00Z}");
query(query);
}总结:
1、匹配所有文档:*:* (通配符?和 * :“*”表示匹配任意字符;“?”表示匹配出现的位置)
2、布尔操作:AND、OR和NOT布尔操作(推荐使用大写,区分普通字段)
3、子表达式查询(子查询):可以使用“()”构造子查询。 比如:(query1 AND query2) OR (query3 AND query4)
4、相似度查询:
(1)默认相似度查询:title:appla~,此时默认编辑距离是2
(2)指定编辑距离的相似度查询:对模糊查询可以设置编辑距离,可选02的整数:title:appla1。
5、范围查询(Range Query):Lucene支持对数字、日期甚至文本的范围查询,并且两端范围。结束的范围可以使用“*”通配符。
(1)日期范围(ISO-8601 时间GMT):birthday:[1990-01-01T00:00:00.000Z TO 1999-12-31T24:59:99.999Z]
(2)数字:age:[2000 TO *]
(3)文本:content:[a TO a]
六、solr高级
1.排序
//排序
@Test
public void testSort() throws Exception{
//字典顺序
// 1 10 2 23 3
//注:这里的id是string类型,按字典顺序排
SolrQuery query = new SolrQuery("*:*");
query.setSort("id",SolrQuery.ORDER.desc);
query(query);
}2、分页
//分页
@Test
public void testPage() throws Exception{
int currentPage = 2;
int pageSize = 3;
SolrQuery query = new SolrQuery("*:*");
//分页
int start = (currentPage - 1 ) * pageSize;
query.setStart(start);
query.setRows(pageSize);
query(query);
}3、高亮
将抽取的方法返回值改为QueryResponse
// 抽取出一个方法2
public QueryResponse query2(SolrQuery query) throws Exception{
SolrServer server = new HttpSolrServer("http://localhost:8081/solr/collection1");
QueryResponse response = server.query(query);
SolrDocumentList documentList = response.getResults();
for(SolrDocument document:documentList){
String id = document.get("id").toString();
String title = document.get("title").toString();
System.out.println("id:"+id+"title:"+title);
}
return response;
} //高亮
@Test
public void testHighlighting() throws Exception{
SolrQuery query = new SolrQuery("title:哒哒哒");
//开启高亮
query.setHighlight(true);
//设置高亮的字段
query.addHighlightField("title");
//query.addHighlightField("content");可以添加多个
query.setHighlightSimplePre("");
query.setHighlightSimplePost("");
QueryResponse response = query2(query);
/*
* 最外层的map的key为查询到的文档的id
* 外层map的value为高亮的内容
*
* 内层map的key为高亮的字段的名字
* 内层map的value为高亮的内容
*
* 内层map的value为list,通常只有一条数据
*/
Map>> outMap = response.getHighlighting();
for(String docId : outMap.keySet()){
Map> innerMap = outMap.get(docId);
for(String fileName : innerMap.keySet()){
List contents = innerMap.get(fileName);
System.out.println(contents.get(0));
}
}