用自己的数据集进行遥感图像分类---------u-net改进版dlinknet
刚开始接触深度学习就是看的这个算法,想想当时连python语言都不会,虽然今天依旧咸鱼一条,但是也能用上网络做一点事情了,源码是北京邮电大学的道路识别比赛,采用的torch框架,也算是比较流行框架,网络结构还是端到端的下采样用resnet34,代码讲解想了解的可以看源码,本文主要介绍如何用自己的数据训练,以及训练自己数据中遇到的一些问题。
torch中自带训练好的模型,调用也很简单,获取每一层的数据直接调用即可。
from torchvision import models
resnet = models.resnet34(pretrained=True)
#调用
self.firstconv = resnet.conv1
self.firstbn = resnet.bn1
self.firstrelu = resnet.relu
self.firstmaxpool = resnet.maxpooltrain.py文件中主要参数介绍以及设置
SHAPE = (256,256)#数据维度
ROOT = r'G:\Opendata\deepglobe-road-dataset\train/'
imagelist = filter(lambda x: x.find('sat')!=-1, os.listdir(ROOT))#确定数据
trainlist = list(map(lambda x: x[:-8], imagelist))#取前面的名字
NAME = 'roadnew_dink34'#数据模型
modefiles = 'weights/'+NAME+'.th'
solver = MyFrame(DinkNet34, dice_bce_loss, 1e-5)#网络,损失函数,以及学习率SHAPE网络中并没有用到,只是用作输出打印。
ROOT训练文件所在位置,原文读取数据的方式标签和样本放在同一文件夹,用不同的名字区分样本和数据,如果要修改可以在data.py中根据自己数据的储存结构进行修改,其他参数已经有注释。这里需要注意的是网络接受的数据格式是通道数在前,因此需要transpose(2,0,1),作者采用了大量的数据增强处理,我的代码省略,数据设置完毕,运行train.py便可开始执行训练,
def default_loader(id, root):
img = skimage.io.imread(os.path.join(root,'{}.tif').format(id))
mask = skimage.io.imread(os.path.join(root.replace('images', 'labels'), '{}.png').format(id),-1)
mask = np.expand_dims(mask, axis=2)
img = np.array(img, np.float32).transpose(2,0,1)#/255.0 * 3.2 - 1.6
mask = np.array(mask, np.float32).transpose(2,0,1)#/255.0
mask[mask>=0.5] = 1
mask[mask<=0.5] = 0
return img, mask训练结束后可用predict_best.py进行识别,添加了坐标系和上色功能,参数注释中有明确的介绍。主要参数设置:
识别文件路径source,模型文件位置,输出路径,以及识别图片类型后缀。
if __name__ == '__main__':
source = r'G:\Opendata\deepglobe-road-dataset\valid/' # 识别路径
solver = TTAFrame(DinkNet34) # 根据批次识别类
solver.load('weights/road1_dink34.th') # 加载模型
target = 'submits/log01_dink341/' # 输出文件位置
if not os.path.exists(target):
os.mkdir(target)
listpic = glob.glob(os.path.join(source, "*.jpg"))
a = P(2)
a.main_p(listpic, target, solver,changes=False)添加坐标系函数,需要原始带坐标的函数,以及预测结果,输出文件位置。
def CreatTf(self,file_path_img,data,outpath):#原始文件,识别后的文件数组形式,新保存文件
d,n = os.path.split(file_path_img)
dataset = gdal.Open(file_path_img, GA_ReadOnly)#打开图片只读
projinfo = dataset.GetProjection()#获取坐标系
geotransform = dataset.GetGeoTransform()
format = "GTiff"
driver = gdal.GetDriverByName(format)#数据格式
name = n[:-4]+'_result'+'.tif'#输出文件名字
dst_ds = driver.Create(os.path.join(outpath,name), dataset.RasterXSize, dataset.RasterYSize,
1, gdal.GDT_Byte )#创建一个新的文件
dst_ds.SetGeoTransform(geotransform)#投影
dst_ds.SetProjection(projinfo)#坐标
dst_ds.GetRasterBand(1).WriteArray(data)
dst_ds.FlushCache()识别采用滑动窗口的形式,每次按照设置好的批次输入网络,同时每次只更新输出结果中的1/4这样能减少遥感大图的拼接痕迹。
for row_begin in range(0, x.shape[0], half_target_size): # 行中每次移动半个[0,x+160,64]
for col_begin in range(0, x.shape[1], half_target_size): # 列中每次移动半个[0,x+160,64]
row_end = row_begin + target_size # 0+128
col_end = col_begin + target_size # 0+128
if row_end <= x.shape[0] and col_end <= x.shape[1]: # 范围不能超出图像的shape
batch.append((row_begin, row_end, col_begin, col_end)) # 取出来一部分列表[0,128,0,128]
if len(batch) == batch_size: # 够一个批次的数据
batchs.append(batch)
batch = []
if len(batch) > 0:更新中间1/4代码函数
for k in range(len(wins)): # 获取窗口编号
row_begin, row_end, col_begin, col_end = one_batch[k] # 取出来一个索引
pred = y_window[k, ...] # 裁剪出来一个数组,取出来一个批次数据
pad_y[
row_begin:row_end,col_begin :col_end
] = pred
y_window_center = pred[
quarter_target_size:target_size - quarter_target_size,
quarter_target_size:target_size - quarter_target_size
] # 只取预测结果中间区域减去边界32[32:96,32:96]
pad_y[
row_begin + quarter_target_size:row_end - quarter_target_size,
col_begin + quarter_target_size:col_end - quarter_target_size
] = y_window_center # 只取4/1输出的时候可以根据阈值进行显示,同时对输出结果上色,需要可以在此处修改。
y_probs[y_probs>0.3]=1
y_probs[y_probs<=0.3]=0
self.CreatTf(one_path, y_probs,outpath) # 添加坐标系
img_out = np.zeros(y_probs.shape + (3,))
for i in range(self.number):
img_out[y_probs == i, :] = COLOR_DICT[i]#对应上色
y_probs = img_out / 255
save_file=os.path.join(outpath,n[:-4]+'_init'+'.png')结果展示:原始网络与自己训练网络结果对比,可以看出来数据增强,和识别的时候采用TTA确实很厉害的。

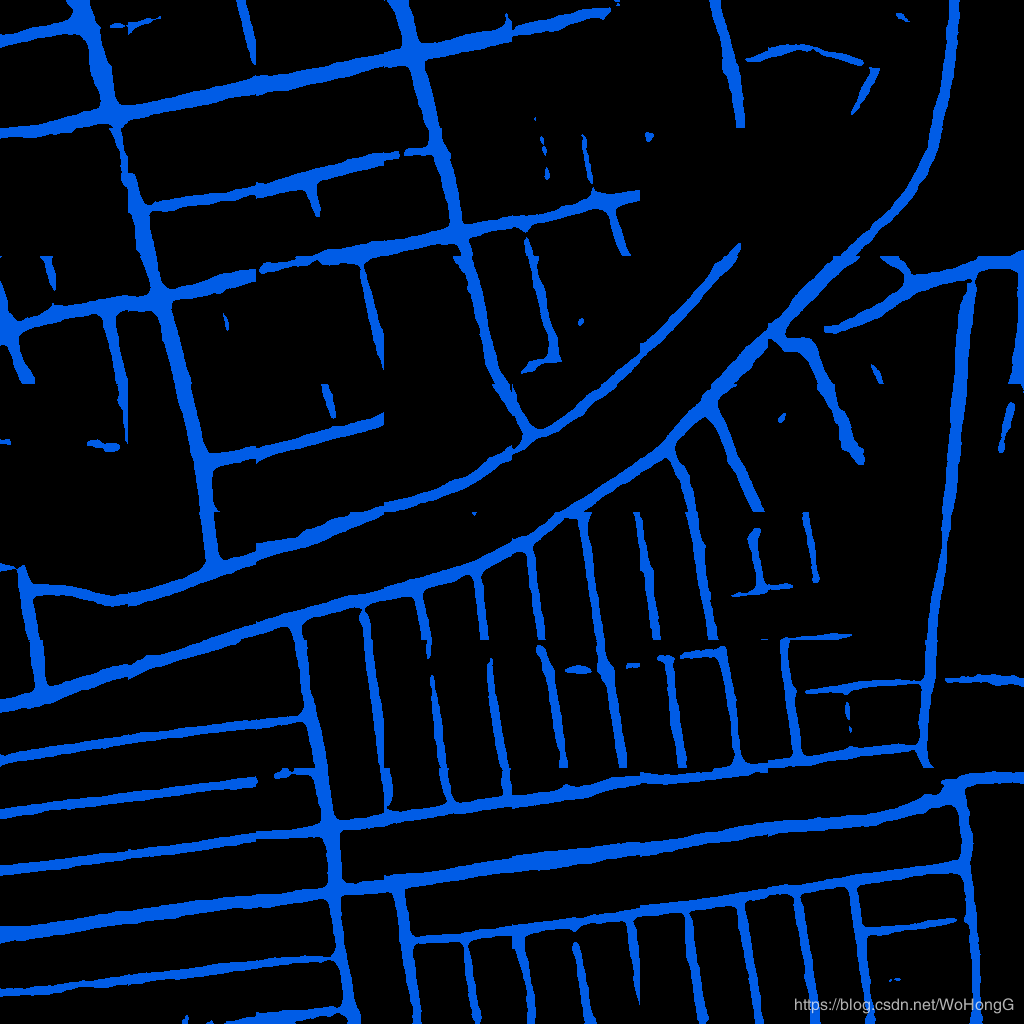
自己尝试用arcgis矢量化,做训练集,提取谷歌影像中的大棚结果。

