【论文笔记】Improved Residual Networks (iResNet)
论文名称:《Improved Residual Networks for Image and Video Recognition》
论文链接:https://arxiv.org/abs/2004.04989
代码链接:https://github.com/iduta/iresnet
简介
残差网络(ResNets)代表了一种强大的卷积神经网络(CNN)体系结构,已广泛用于各种任务中。在这篇论文中,作者针对ResNets的三个主要组成部分(网络层之间的信息流、残差构建块和projection shortcut)加以改进,提出了ResNets的改进版本。
作者在三个任务涵盖6个数据集上检测了模型性能,包括图像分类(ImageNet、CIFAR-10和CIFAR-100)、目标检测(COCO)和视频行为识别(Kinetics-400和Something-Something-v2)。这项工作为CNN的深度建立一个新的里程碑。它成功地在ImageNet上训练了404层网络,并在CIFAR-10和CIFAR-100上成功训练了3002层,而baseline在这种深度下则表现出严重的优化问题。
研究动机
(1) 残差网络提供了一种解决网络退化问题的思路,这使得有效学习深得多的网络成为可能。然而,论文[1]通过实验证明,残差网络并不能完全解决网络的退化问题。例如,在ImageNet数据集上,当将网络深度从152层增加到200层,这导致明显更差的结果,表现出严重的优化问题。这表明,当网络层数增加时,残差网络仍然会危害网络中信息的传输。( 促进网络中信息传输就有意义了)
(2) 为了使不同残差模块之间的维度能够匹配,残差网络提出了projection shortcuts。projection shortcuts在网络结构中扮演着重要的角色,因为它们位于主要的信息传播路径上,因此容易干扰信号或造成信息丢失。( 改进projection shortcuts也有必要了)
(3) 残差网络构建了瓶颈模块来控制模型的参数量和计算量。然而,在这种瓶颈结构中,唯一的负责学习空间滤波器的卷积所接收的输入/输出通道却是最少的。( 很容易想到,可以考虑增加输出通道以提高空间信息提取能力)
主要贡献
(1) 提出了一种基于分段的残差学习网络结构,为信息在网络各层间的传输提供更好的路径,有利于特征信息的学习。
(2) 提出了一种改进的projection shortcut,它可以减少信息丢失,并提供更好的结果。
(3) 提出了一种新的模块,该模块大大增加了空间通道的数量,以学习更强大空间模式。
(4) 所提出的方法在残差网络的基础上加以改进,在不增加模型计算复杂度的情况下,提升了模型的性能。
(注:projection shortcut是指当前残差块和下一残差块维度不一致时使用的跳层连接。说白了,projection shortcut就是采用了1×1卷积层的跳层连接)
相关工作
主要涉及四部分的研究工作,一方面引出iResNet用到的技术,另一方面地阐述iResNet与现有方法的区别,突出贡献。
残差网络在训练用于视觉识别的深层结构方面是很有效的。已经有许多工作致力于改进这种强大的结构。本文也是以残差网络为baseline进行改进。
(1) pre-activation ResNets [1] 为模块中的组件提出新的组件顺序(即预激活策略),以改善信号在网络中的传播。本文的主要贡献也采用了预激活。但不同的是,本文将网络划分为三个不同阶段,并且每个阶段的每个部分提出了不同模块。
(2) AlexNet [2] 和ResNeXt [3] 采用了分组卷积,本文也采用了分组卷积。不同的是,本文提出新的模块结构,比ResNeXt的模块多了2倍的空间滤波器,表现出更好的性能。
(3) SENet [4] 和 Non-local neural networks [5] 分别提出squeeze-and-excitation blocks 和 non-local blocks来提升残差网络的性能。但将这些额外的模块插入到网络中会增加网络的计算复杂度。与之不同的是,本文对baseline做的改进不会增加模型计算复杂度。
(4) 工作 [6] 采用了各种技巧来提升残差网络的性能。本文和[6]有一个相同点,那就是都有projection shortcut。不过,本文提出的projection shortcut与[6]的并不相同,下面会详细讲projection shortcut的具体设计。
方法设计
(1) 改进information flow
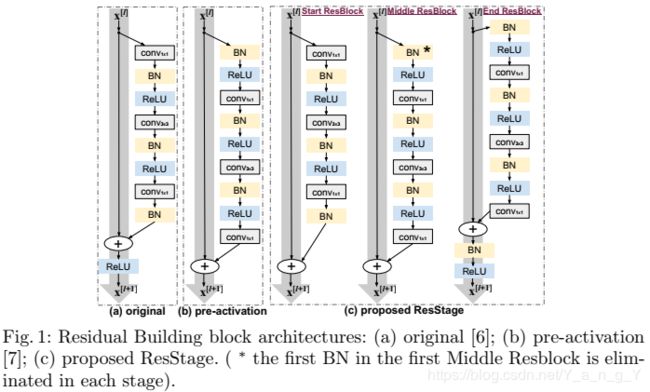
残差网络的主要模块是残差块。如下图1(a)为原始的瓶颈残差模块中,灰色大箭头(即跳层连接)是信息传播的主要路径,而在这个路径上有一个ReLU激活层。这个位置的ReLU因为会将负信号置0而对信息传播带来负面影响,尤其在刚开始训练的时候,影响更严重。pre-activation ResNets采用预激活策略来解决这个问题,通过将原始瓶颈残差模块中最后的BN和ReLU移到模块的开头,使得主路径上没有ReLU。这种改进仍然存在一些问题。
- 问题1:因为BN只用在了分支上,导致由主路径信号与分支上的信号汇总后的全信号,没有被归一化。随着多个模块的叠加,全信号变得越来越“unnormalized”,增加了网络的学习难度。
- 问题2:残差网络有四个主要阶段,就有四个projections shortcuts,相当于主路径上只有四个连续的1×1卷积层,但这四个卷积层之间没有任何的非线性,这也限制了网络的学习能力。
针对这两个问题,作者将网络结构分成多个阶段,当输出的空间尺寸或通道数量发生变化,意味着开始进入下一个阶段。以ResNet-50为例,把网络分为四个主要阶段(stage 1-4)、一个开始阶段和一个结束阶段。每个主要阶段都包含了若干残差模块,主要分为三部分,即一个Start ResBlock,若干Middle ResBlock和一个End ResBlock。简单来说,根据阶段中所处的位置不同,设计出不同的残差块。这样一来,在主路径上,有且只有四个主要阶段的末尾分别有一层ReLU激活层,既在主路径增加了非线性,也避免ReLU对信息造成损耗(解决了问题2)。此外,每个End ResBlock的末尾都采用BN,使得各阶段主路径上的全信号得到归一化处理。
值得注意的是,在设计不同ResBlock时,只是将ResBlock内部不同组件的顺序进行了调整,所以这种设计不会增加额外的参数。
(2) 改进projection shortcut
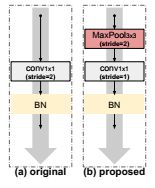
在残差网络中,由于某些残差模块的输入与其上一层输出在通道和空间维度上不匹配。因而采用stride为2的1×1卷积,对特征图的空间维度和通道维度加以转换,来实现不同模块间维度的匹配。但这将造成信息损失且会引入噪声,对网络中主要信息流造成负面干扰。
为解决这个问题,如下图的(b)图,作者将通道维度和空间维度的转换分开处理,用stride为2的3×3最大池化层进行空间维度的转换,用stride为1的1×1卷积完成通道维度的转换。最大池化考虑了特征图的所有信息并将最显著的信息提取出来。如此,便减少了信息损失。
关于projection shortcut的改进,作者还给出了几个设计动机,进行了详细的阐述,详情可见原文。(总之这种做法,在理论上是很有道理的)
(3) Grouped building block
残差网络通过瓶颈残差结构来控制模型的参数量和计算代价。但这种瓶颈结构原始瓶颈模块利用1×1卷积层对特征图先降维后升维,使得唯一用于提取空间信息的3×3卷积层接收的输入/输出通道数较少,限制了其学习空间模式的能力。
针对该问题,如下图的(b)图,作者采用分组卷积构建新模块,对特征图先升维再降维,使得3×3卷积层处理更多的通道,以提升其对空间模式的学习能力。虽然通道数增加了很多,但用了分组卷积,所以参数量增加的有限。

实验结果
最后,放一波实验结果,不做详细分析。总之表明所提出的方法确实有很好的性能。
与两个baseline的对比
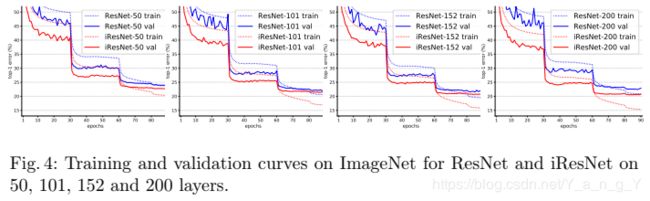
不同网络深度下学习曲线的对比
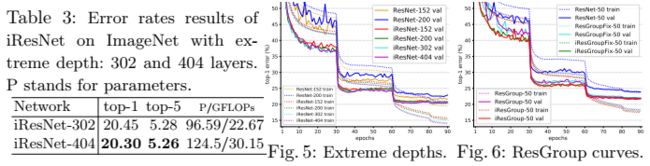
网络深度达到302层和404层的表现
不难发现,在很深的情况下,iResNet仍然能够收敛,不存在优化难题。
iResNet在视频识别任务上的表现

iResNet在CIFAR-10和CIFAR-100上的表现

以iResNet为backbone的SSD检测器在COCO数据集上的表现

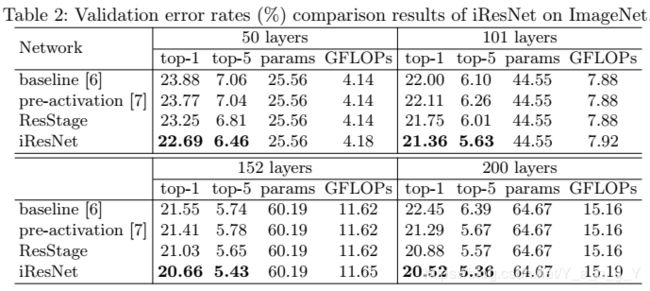
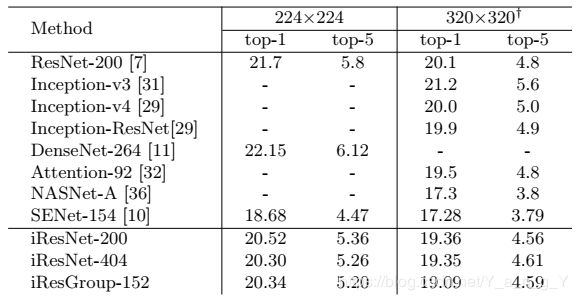
在ImageNet上iResNet与其它网络的对比
参考文献
[1] He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: ECCV (2016)
[2] Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: NIPS (2012)
[3] Xie, S., Girshick, R., Doll´ar, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: CVPR (2017)
[4] Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: CVPR (2018)
[5] Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: CVPR (2018)