数据库索引为什么采用B+树实现
1 构建索引需要考虑的因素
1.1 计算机存储结构
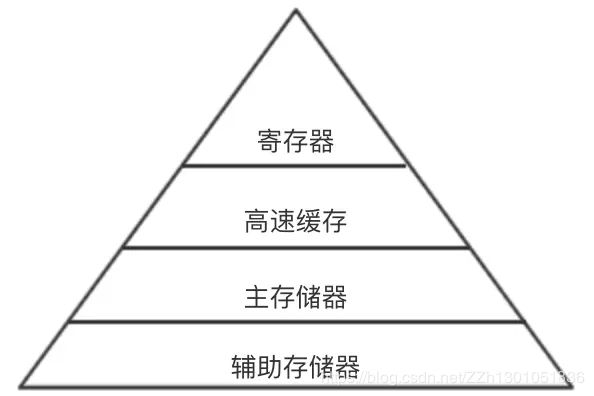
计算机存储结构如下图所示,从上到下依次为寄存器、高速缓存、主存储器、辅助存储器。其中主存储器,即我们常说的内存;辅助存储器也被称为外存,比较常见的就是磁盘、SSD等。在这个存储结构中,每一级存储的速度都比上一级慢很多,所以程序访问越上层存储中的数据,速度就会越快。
1.2 局部性原理与磁盘预读
- 起因:内存读写快,磁盘读写慢,而且慢很多;
- 磁盘预读:磁盘读写并不是按需读取,而是按页预读,一次读一页(一般为4KB, MySQL为16KB)的数据,即每次加载更多的数据。如果未来要读取的数据就在这一页中,可以避免未来的磁盘I/O,提高效率;
- 局部性原理:软件设计要尽量遵循“程序运行期间所需要的数据比较集中”和“当一个数据被用到时,其附近的数据也通常会马上被使用”,这样磁盘预读能充分提高磁盘I/O。
1.3 索引设计考虑因素
数据库索引因数据量较大,一般都是存储于外存中,而程序是在内存中执行的,这样就需要进行频繁的I/O操作,那么,为了减少I/O次数,该怎么做呢?我们知道,磁盘预读是按页操作的,如果每一页包含的信息量足够大,是不是就可以达成目的了。
索引设计需要考虑的第一个核心因素:保证每页包含尽可能多的“关键信息”,来减少磁盘I/O。
2 可提升查找性能的数据结构
添加索引的目的,主要是为了提升数据库的查找速度。一般来说,可提升查找速度的数据结构有以下两种:
(1)哈希。比如HashMap,其查询、插入、删除的平均时间复杂度均是O(1);
(2)树。比如二叉查找树,其查询、插入、删除的平均时间复杂度均是O(log(n))。
可以看到,论时间复杂度,不管是读请求,还是写请求,哈希的性能会更好,可为什么DB却选择使用B+树呢?接下来,我将按“哈希表 -> 平衡二叉树 -> B树 -> B+树”的思路逐个进行分析。
索引设计需要考虑的第二个核心因素:结合DB各种搜索场景,选取更合适的数据存储结构。
3 哈希表
假设采用HashMap存储,如果查询sql都是单行查询,比如
select * from user where name='zhangsan';
那么,采用哈希确实很快,但是,如果过滤条件是范围(<、>),排序(order by)等查询场景呢?其时间复杂度将退化为O(n)。假设我们采用的是“m叉查找树”,由于其本身是排好序的,其时间复杂度仍将是O(log(n)),即仍能保证其高效率。
所以,相比“m叉查找树”而言,后者更加合适。
哈希表:“指定数据”的定位较快,“范围查询”较慢。
4 平衡二叉树(AVL树)
平衡二叉树的结构如下图所示,可以认为它是升级版的二叉树,它有两个特征:
- 数据是有序排列的
- 任何节点的儿子子树高度差的绝对值不会超过1
- 采用中序遍历可获得所有节点

从图中可以看出,每个节点有且仅能存储一个记录,如果数据量大的话,树的高度将会很高,故而,当查询数据时,会产生很多次磁盘I/O。
相比哈希表而言,平衡二叉树支持范围查询,解决了哈希表的痛点。
5 B树(平衡多路查找树)
B树的结构如下图所示,它有以下特点:
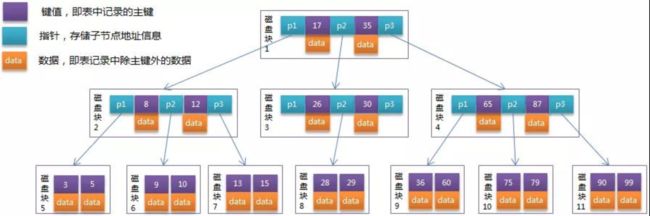
叶子节点和非叶子节点都存储数据(此特点会导致非叶子节点不能存储大量的索引)
采用中序遍历亦可获得所有节点。
从图中可以看出,每一个节点可以有多个子节点,且每一个节点(包括非叶子节点)均存储数据,采用中序遍历便可查找到所有数据。但是,数据库磁盘交互是按页为单位(MySQL默认为16K)的,如果数据量过多时,每个节点存储的键值会较少,进而树的高度比较高,导致磁盘I/O比较多。同时,在实际项目中,范围查询的SQL比较频繁,倘若采用B树作为索引结构,需要中序遍历很多节点,来收集符合筛选条件的数据集。因此,此结构某种程度来看,不是太合适。
6 B+树
B+树的结构如下图所示,它有以下特点:

- B树的升级版
- 非叶子节点仅保存索引和指针(不再存储数据),仅叶子节点存储数据信息(保证节点可以存储更多索引,进而减少树的高度)。
- 叶子节点间采用了链表,这样,范围查询时,只要确定范围的左右边界坐标,遍历叶子节点链表,便可获取所有符合条件节点集合。
从其特点可得知,它兼具了**“降低树高度,减少磁盘I/O”、“提升范围查询性能”**两个因素。
接下来,举一个例子来说明B+树怎么控制树的高度的。
我们假设一页大小是16KB,每个索引(主键)是bigint类型,即8B,指针为6B。那么每页能存储大约1000个索引(16KB/(8B+6B) \approx1000)。
那么,一颗3层的B+树能够存储多少索引呢?如下图:
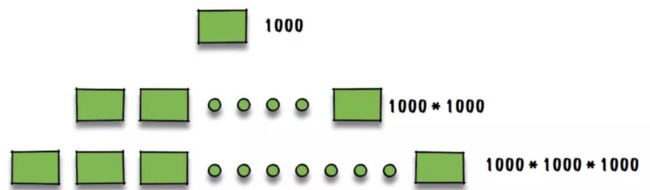
大约能够存储10亿个索引。通常 B+ 树的高度在2-4层,由于 MySql 在运行时,根节点是常驻内存的,因此每次查找只需要大约2-3次IO。
7 番外篇 —— 索引构建注意事项
结合索引的底层原理,我们在实际项目中构建索引时,需要注意以下几点:
- 主键不能太大,否则,每个节点可容纳的节点会较少
- 主键最好是自增的,否则,每次插入都会调整B+树,从而导致页分裂,影响性能
8 "索引&B+树"的常见面试题
8.1 为什么 MySQL 的索引使用 B+ 树而不是其它树形结构?
拿到索引需要去磁盘中取数,所以谁的磁盘IO次数少,就用谁。
简单版本回答:
因为 B 树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致 IO 操作变多,查询性能变低。
详细版本回答:即本文内容。
- 其他结构的缺点
Hash表:指定数据的查询挺快,范围查询较慢。
B树(二叉搜索树):在B树的基础上,加上平衡策略就是平衡二叉树。B树、B-树、B+树、B*树 红黑树。
AVL(平衡二叉树):每个结点只能存储一个数据,树的高度太高(磁盘IO次数太多)。支持范围查询,但是范围查询时需要中序遍历很多结点。
B-树(平衡多路二叉树):叶子节点和非叶子节点都存储数据,每个非叶子节点存储的关键信息太少,会导致树的高度太高,磁盘IO过多。 - B+ 树的优点
(1)树的高度低。非叶结点只存储索引,数据只存储在叶结点上。
(2)范围查询性能高。所有的叶结点使用一个链表连接起来。范围查询时,只需要找到两个边界,就可以遍历链表找出所有符合条件的数据。 - 红黑树:红黑树是二叉树。树太高,磁盘IO次数太多。
(1)红黑树的查找性能比B+树低。
(2)红黑树的优点在于,插入或删除结点时,操作比B+树少。适用于插入删除频繁的地方。例如常见的TreeMap、TreeSet(底层是TreeMap)、STL中的Map、Set。
8.2 联合索引在B+树中如何存储?
问题来源:从一道索引数据结构面试题看B树、B+树
问题解答:联合索引在B+树上的结构介绍
联合索引(col1, col2,col3)也是一棵B+树,其非叶子节点存储的是第一个关键字的索引,而叶节点存储的则是三个关键字的数据,且按照col1、col2、col3的顺序进行排序。
col1表示的是年龄,col2表示的是姓氏,col3表示的是名字。如下图:
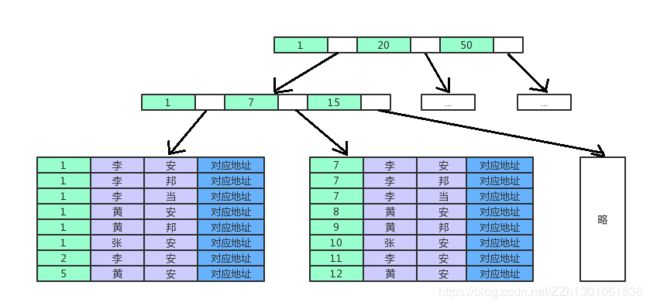
PS:对应地址指的是数据记录的地址。
如图,联合索引(年龄, 姓氏,名字),叶节点上data域存储的是三个关键字的数据。且是按照年龄、姓氏、名字的顺序排列的。
因此,如果执行的是:
select * from STUDENT where 姓氏='李' and 名字='安';
或者
select * from STUDENT where 名字='安';
那么当执行查询的时候,是无法使用这个联合索引的。因为联合索引中是先根据年龄进行排序的。如果年龄没有先确定,直接对姓氏和名字进行查询的话,就相当于乱序查询一样,因此索引无法生效。因此查询是全表查询。
如果执行的是:
select * from STUDENT where 年龄=1 and 姓氏='李';
那么当执行查询的时候,索引是能生效的,从图中很直观的看出,age=1的是第一个叶子节点的前6条记录,在age=1的前提下,姓氏=’李’的是前3条。因此最终查询出来的是这三条,从而能获取到对应记录的地址。
如果执行的是:
select * from STUDENT where 年龄=1 and 姓氏='黄' and 名字='安';
那么索引也是生效的。
而如果执行的是:
select * from STUDENT where 年龄=1 and 名字='安';
那么,索引年龄部分能生效,名字部分不能生效。也就是说索引部分生效。
因此我对联合索引结构的理解就是B+Tree是按照第一个关键字进行索引,然后在叶子节点上按照第一个关键字、第二个关键字、第三个关键字…进行排序。
最左原则
而之所以会有最左原则,是因为联合索引的B+Tree是按照第一个关键字进行索引排列的。
9 B-树、B+树、红黑树的应用场景
- B-树:文件系统(磁盘文件组织)。
它的设计思想是,将相关数据尽量集中在一起,以便一次读取多个数据,硬盘IO次数少。 - B+树:数据库索引。
(1)树的高度低。非叶结点只存储索引,数据只存储在叶结点上。
(2)范围查询性能高。所有的叶结点使用一个链表连接起来。范围查询时,只需要找到两个边界,就可以遍历链表找出所有符合条件的数据。 - 红黑树:
红黑树往往由于树的深度过大,磁盘IO读写过于频繁,效率低下。
在数据较小,可以完全放到内存中时,红黑树的时间复杂度比B-树低。
如linux中进程的调度用的是红黑树。
反之,数据量较大,外存中占主要部分时,B-树因其读磁盘次数少,而具有更快的速度。所以B-树适用于文件系统。
总结:
B-/B+树就是是为了磁盘或其它存储设备而设计的。
需要读写的数据多在磁盘中,需要多次读写磁盘文件(外存)时,适用B-树。
需要读写的数据多在内存中,需要在内存中多次读写数据时,适用红黑树。
B+树适用于数据库索引。
假定一个节点可以容纳100个值,那么3层的B树可以容纳100万个数据,如果换成二叉查找树(红黑树就是一种二叉查找树),则需要20层!假定操作系统一次读取一个节点,并且根节点保留在内存中,那么B树在100万个数据中查找目标值,只需要读取两次硬盘。