笔记:Deep multi patch aggregation network for image style, aesthetics and quality estimation
在Image style, aesthetics and quality estimation三类任务中往往需要依靠更多的高像素(high resolution)图片中的细纹理(fine-grained)信息。通常CNN网络的输入是256*256*3的尺寸,通常的做法是,通常的做法是将一个高像素(比如1024*768)图片随机裁剪为一个patch,用这个patch表示整幅图像,这样会丢失掉其余部分的细纹理信息。本文用一个patch集合(multi patch)来表示整个图片。基于multiple patch,文章提出了一种特征学习以及聚集(aggregation)不同patch特征的框架。具体而言,首先在一个图片上提取多个patch,然后为每个patch做特征提取,将各个patch的特征进行聚集,从而得到用于分类的特征。在这个框架上,本文提出了两种用于特征聚集的方法,分别是statistics aggregation structure和fully-connected sorting aggregation。整个框架本文用下图表示:
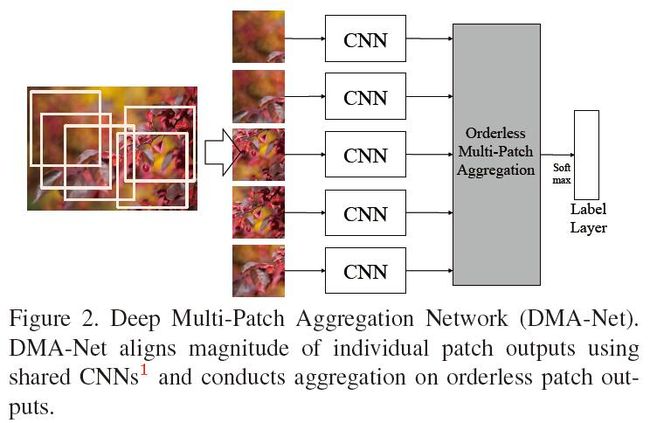
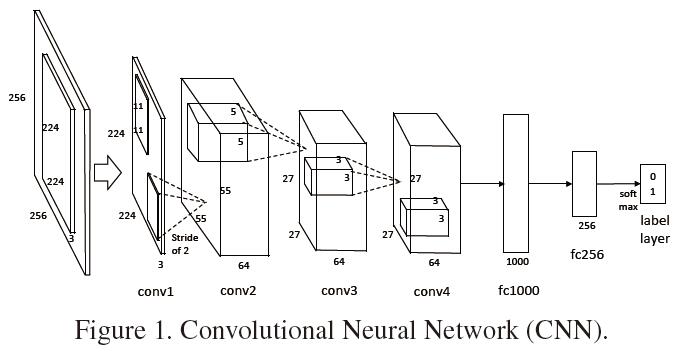
这里的CNN表示下面结构中从input layer到fc256.(没有softmax层)
详细的步骤如下:
1) 对图像选择patch,构成patch集;训练阶段随机每个图像随机选取5个patch,测试阶段没个图片随机选取250个patch,每5个构成一个patches集合,作为第(2)步的输入,每个图像共50个集合,最后取50个集合的平均值作为结果。
2) 对patch集中的每个patch单独进行特征提取:方法是将每个patch用CNN提取特征。在训练阶段,首先用任意一个patch训练一个CNN,然后将所有CNN初始化为该值,然后用对应的patch对各个CNN进行单独训练。在将CNN特征传去到aggregation层的时候,为了保持它们之间的可比性,将各个CNN columns上的权重设为相同。
3) 然后将patch的特征进行aggregation。本文讲了两种策略,每个patch的特征为K,每个图像用M个patch表示,分别是:
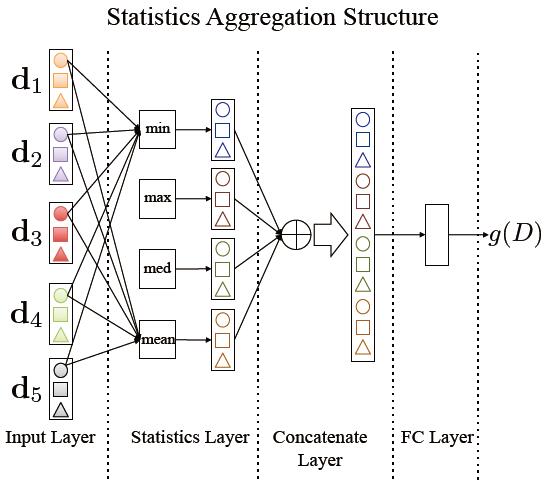
a) the statistics aggregation structure:这个结构保留每个patches特征上的统计特征,文章提到的包括max, min, median and mean. 聚集的过程为:分别计算multi patch上对应维度上的每个统计特征,将每维相同的统计特征串联起来得到M维向量,然后将U个统计特征分别得到的M维特征向量串联,得到U*K的向量(假设考虑U个统计特征),这个向量被传到一个全链接层,生成特征向量g(D)。整个流程在文中如下图表示:(K=3,U=4)
b) the fully-connected sorting aggregation:这个将上面的statistics layer替换为sorting layer,文章提到的sorting 方式为按值递增排序。首先提取每个patch的特征,然后将不同patch对应维度上的进行排序,每个维度上形成一个排序后的M维特征向量,将K个维度上的M维特征向量串联得到K*M维特征。这个结果在全连接层后得到特征向量g(D)。流程在文中如下表示

4)最后根据全连接层输出的特征分类用的CNN上的soft-max层。