A Review on Generative Adversarial Networks: Algorithms, Theory and Applications
论文地址:https://arxiv.org/pdf/2001.06937.pdf
近年来,生成对抗网络(GAN)是一个热门的研究课题。2014 年至今,人们对 GAN 进行了广泛的研究,并提出了大量算法。但是,很少有全面的研究来解释不同 GAN 变体之间的联系以及它们演变的方式。在本文中,我们尝试从算法、理论和应用的角度对多种 GAN 方法进行综述。首先,我们详细介绍了大多数 GAN 算法的研究动机、数学表征和架构。此外,GAN 已经在一些特定应用上与其它机器学习算法相结合,如半监督学习、迁移学习和强化学习。本文比较了这些 GAN 方法的异同。其次,我们研究了与 GAN 相关的理论问题。第三,我们阐述了 GAN 在图像处理与计算机视觉、自然语言处理、音乐、语音与音频、医学以及数据科学中的典型应用。最后,我们指出了 GAN 的一些未来的开放性研究问题。
算法
在本节中,我们首先介绍最原始的 GAN。然后,介绍其具有代表性的变体、训练及评估方式以及任务驱动的 GAN。
生成对抗网络
当模型都是神经网络时,GAN 架构实现起来非常直观。为了学习生成器在数据 x 上的分布 p_g,首先定义一个关于输入噪声变量的先验分布 p_z(z)[3],其中 z 是噪声变量。接着,GAN 表示了从噪声空间到数据空间的映射 G(z, θ_g),其中 G 是一个由参数为 θ_g 的神经网络表示的可微函数。除了 G 之外,另一个神经网络 D(x, θ_d) 也用参数 θ_d 定义,D(x) 的输出是一个标量。D(x) 表示了 x 来自真实数据而不是来自生成器 G 的概率。我们对判别器 D 进行训练,以最大化为训练数据和生成器 G 生成的假样本提供正确标签的概率。同时,我们训练 G,最小化 log(1-D(G(z)))。
- 目标函数
GAN 可以使用各种不同的目标函数。
- 最原始的极大极小博弈
GAN [3] 的目标函数是
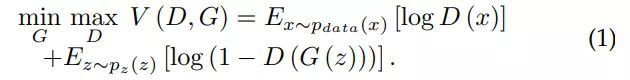
其中 D(x) 是 [1, 0]^T 和 [D(x), 1 - D(x)]^T 间的交叉熵。类似地,log(1-D(G(z))) 是 [0, 1]^T 和 [D(G(z)), 1 - D(G(z))]^T 间的交叉熵。对于一个固定的 G,[3] 中给出了最优的判别器 D:
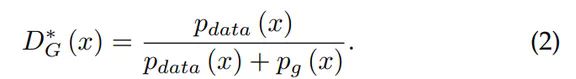
(1) 式中的极大极小博弈可以被重新形式化为:
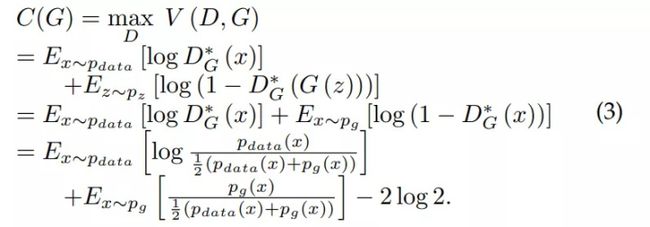
两个概率分布 p(x) 和 q(x) 之间的 KL 散度和 JS 散度定义如下:
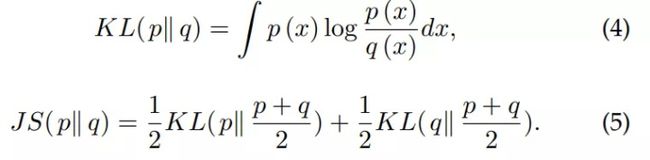
因此,(3) 式等价于
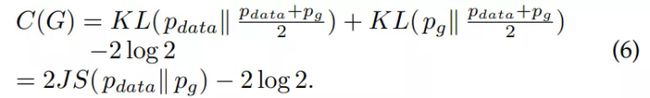
因此,GAN 的目标函数和 KL 散度与 JS 散度都相关。
- 非饱和博弈
实际上,公式 (1) 可能无法为 G 提供足够大的梯度使其很好地学习。一般来说,G 在学习过程的早期性能很差,产生的样本与训练数据有明显的差异。因此,D 可以以高置信度拒绝 G 生成的样本。在这种情况下,log(1-D(G(z))) 是饱和的。我们可以训练 G 以最大化 log(D(G(z))),而非最小化 log(1-D(G(z)))。生成器的损失则变为
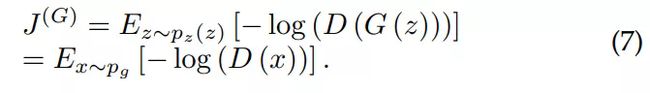
这个新的目标函数可以在训练过程中使 D 和 G 的达到相同的不动点,但是在学习初期就提供了大得多的梯度。非饱和博弈是启发式的,而非理论驱动的。然而,非饱和博弈还存在其它问题,如用于训练 G 的数值梯度不稳定。在最优的 D*_G 下,有

因此 E_(x~p_g)[-log(D*_G(x))] 等价于
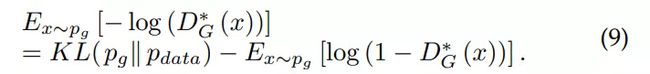
根据 (3) 式和 (6) 式,有
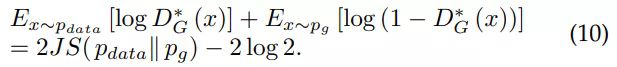
因此 E_(x~p_g)[log^(1 - D*_G(x))] 等价于

将 (11) 式代入 (9) 式,可以得到
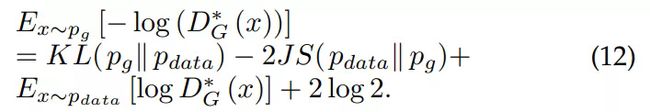
从 (12) 式可以看出,对非饱和博弈中的替代 G 损失函数的优化是矛盾的,因为第一项目标是使生成的分布与实际分布之间的差异尽可能小,而由于负号的存在,第二项目标是使得这两个分布之间的差异尽可能大。这将为训练 G 带来不稳定的数值梯度。此外,KL 散度是非对称度量,这可以从以下两个例子中反映出来
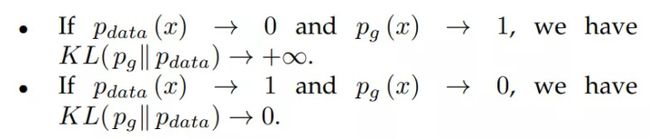
对 G 的两种误差的惩罚是完全不同的。第一种误差是 G 产生了不真实的样本,对应的惩罚很大。第二种误差是 G 未能产生真实的样本,而惩罚很小。第一种误差是生成的样本不准确,而第二种误差是生成的样本不够多样化。基于这个原理,G 倾向于生成重复但是安全的样本,而不愿意冒险生成不同但不安全的样本,这会导致模式坍塌(mode collapse)问题。
- 最大似然博弈
在 GAN 中,有许多方法可以近似 (1) 式。假设判别器是最优的,我们想最小化
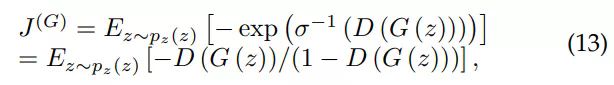
在 GAN 框架中有其它可能的方法逼近最大似然 [17]。图 1 展示了对于原始零和博弈、非饱和博弈以及最大似然博弈的比较。
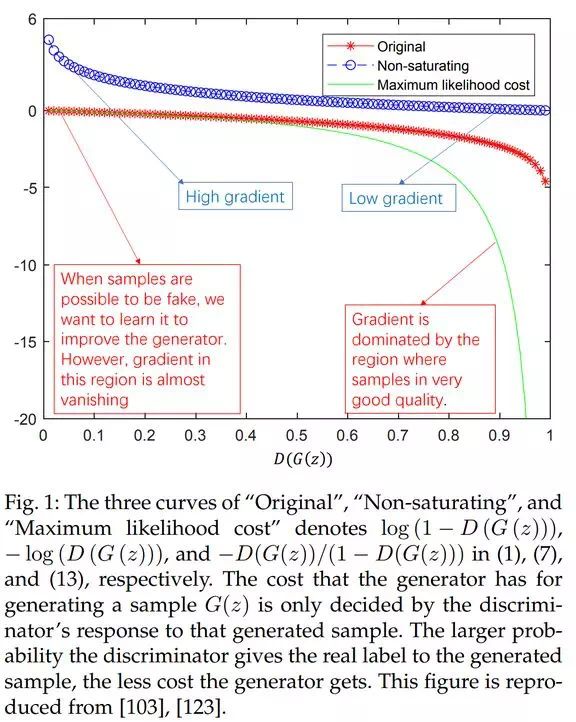
由图 1 可以得到三个观察结果。
首先,当样本可能来自于生成器的时候,即在图的左端,最大似然博弈和原始极大极小博弈都受到梯度弥散的影响,而启发式的非饱和博弈不存在此问题。
第二,最大似然博弈还存在一个问题,即几乎所有梯度都来自曲线的右端,这意味着每个 minibatch 中只有极少一部分样本主导了梯度的计算。这表明减小样本方差的方法可能是提高基于最大似然博弈的 GAN 性能的重要研究方向。
第三,基于启发式的非饱和博弈的样本方差较低,这可能是它在实际应用中更成功的可能原因。
M.Kahng 等人 [124] 提出了 GAN Lab,为非专业人士学习 GAN 和做实验提供了交互式可视化工具。Bau 等人 [125] 提出了一个分析框架来可视化和理解 GAN。
代表性的 GAN 变体
与 GAN [126]-[131] 相关的论文有很多,例如 CSGAN [132] 和 LOGAN [133]。在本小节中,我们将介绍一些具有代表性 GAN 变体。
- InfoGAN
- ConditionalGANs(cGANs)
- CycleGAN
- f-GAN
- IntegralProbabilityMetrics(IPMs)
- LossSensitiveGAN(LS-GAN)
有一个叫做「The GAN Zoo」的网站(https://github.com/hindupuravinash/the-gan-zoo),列举了许多 GAN 的变体。更多详细信息请访问该网站。
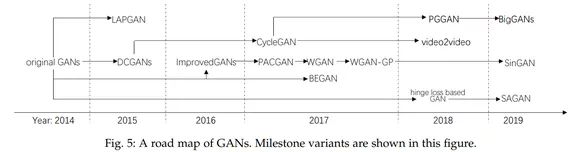
GAN 的训练
尽管理论上存在特有的解决方案,但由于多种原因 [29],[32],[179],GAN 的训练是困难且常常不稳定的。其中一个困难是来自这样一个事实:即 GAN 的最佳权重对应于损失函数的鞍点,而非极小值点。
关于 GAN 训练的论文很多。Yadav 等人 [180] 用预测方法使 GAN 训练更加稳定。[181] 通过使用独立的学习率,为判别器和生成器提出了两个时间尺度更新规则(TTUR),以确保模型可以收敛到稳定的局部纳什均衡。Arjovsky [179] 为全面了解 GAN 的训练动力学(training dynamics)进行了理论探究,分析了为什么 GAN 难以训练,研究并严格证明了训练 GAN 时出现的损失函数饱和和不稳定等问题,提出了解决这类问题的一个实用且具有理论依据的方向,并引入了新的工具来研究它们。Liang 等人 [182] 认为 GAN 的训练是一个连续的学习问题 [183]。
改善 GAN 训练的一种方法是评估训练中可能发生的经验性「症状」。这些症状包括:生成器坍塌至对于不同的输入只能生成极其相似的样本 [29];判别器损失迅速收敛至零 [179],不能为生成器提供梯度更新;使生成器、判别器这一对模型难以收敛 [32]。
我们将从三个角度介绍 GAN 的训练:
- 目标函数
- 训练技巧
- 架构


GAN 的评价指标
在本小节中,我们说明用于 GAN 的一些评价指标 [215],[216]:
- InceptionScore(IS)
- Modescore(MS)
- FrechetInceptionDistance(FID)
- Multi-scalestructuralsimilarity(MS-SSIM)
如何为 GAN 选择一个好的评价指标仍然是一个难题 [225]。Xu 等人 [219] 提出了对 GAN 评价指标的实证研究。Karol Kurach [224] 对 GAN 中的正则化和归一化进行了大规模的研究。还有一些其它对于 GAN 比较性的研究,例如 [226]。参考文献 [227] 提出了几种作为元度量的度量依据,以指导研究人员选择定量评价指标。恰当的评价指标应该将真实样本与生成的假样本区分开,验证模式下降(mode drop)或模式坍塌,以及检测过拟合。希望将来会有更好的方法来评价 GAN 模型的质量。
任务驱动的 GAN
本文的重点关注 GAN 模型。目前,对于涉及特定任务的紧密相关的领域,已经有大量的文献。
- 半监督学习
- 迁移学习
- 强化学习
- 多模态学习
GAN 已被用于特征学习领域,例如特征选择 [277],哈希 [278]-[285] 和度量学习 [286]。MisGAN [287] 可以通过 GAN 利用不完整数据进行学习。[288] 中提出了进化型 GAN(Evolutionary GAN)。Ponce 等人 [289] 结合 GAN 和遗传算法为视觉神经元演化图像。GAN 还被用于其它机器学习任务 [290],例如主动学习 [291],[292],在线学习 [293],集成学习 [294],零样本学习 [295],[296] 和多任务学习 [297]。
理论
最大似然估计(MLE)
并不是所有生成模型都使用 MLE。一些生成模型不使用 MLE,但可以被修改为使用 MLE(GAN 就属于此类)。可以简单地证明,最小化 p_data(x) 和 p_g(x) 之间的 KL 散度(KLD)等价于最大化样本数 m 增加时的对数似然:
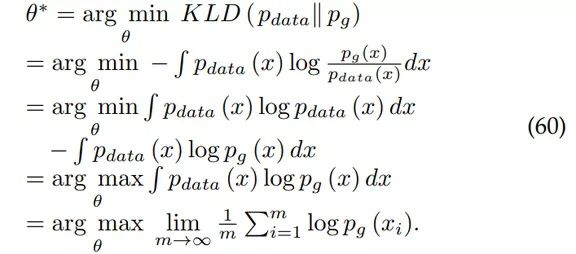
为了保证符号一致性,将模型概率分布 p_θ(x)替换为 p_g(x)。有关 MLE 和其他统计估计量的更多信息,请参阅 [298] 的第 5 章。
模式坍塌
GAN 很难训练,并且在 [26],[29] 已经观察到它们经常受到模式坍塌 [299],[300] 的影响,其中生成器学习到仅仅根据少数几种数据分布模式生成样本,而忽视了许多其它的模式(即使整个训练数据中都存在来自缺失模式的样本)。在最坏的情况下,生成器仅生成单个样本(完全坍塌)[179],[301]。
在本小节中,我们首先引入 GAN 模式坍塌的两种观点:散度观点和算法观点。然后,我们将介绍通过提出新的目标函数或新的架构以解决模式坍塌的方法,包括基于目标函数的方法和基于架构的方法。
其它理论问题
其它理论问题包括:
1. GAN 是否真正学到了分布?
2. 散度/距离
3. 逆映射
4. 数学观点(例如优化)
5. 记忆
应用
如前所述,GAN 是可以由随机向量 z 生成逼真的样本的强大的生成模型。我们既不需要知道显式的真实数据分布,或进行其他任何数学假设。这些优点使 GAN 可以被广泛应用于许多领域,例如图像处理和计算机视觉、序列数据等。
图像处理和计算机视觉
GAN 最成功的的应用是在图像处理和计算机视觉方面,例如图像超分辨率、图像生成与操作和视频处理。
- 超分辨率
- 图像合成和操作
- 纹理合成
- 目标检测
- 视频应用
序列数据
GAN 也在序列数据上取得了一定成就如自然语言、音乐、语音、音频 [376], [377]、时间序列 [378]–[381] 等。
开放性研究问题
GAN 领域仍然存在许多开放性研究问题。
将 GAN 用于离散数据:GAN 依赖于生成参数关于生成样本是完全可微的。因此,GAN 无法直接生成离散数据,例如哈希编码和独热(one-hot)向量。解决此类问题非常重要,因为它可以释放 GAN 在自然语言处理和哈希计算中的潜力。Goodfellow 提出了三种解决这个问题的方法 [103]:使用 Gumbel-softmax [448],[449] 或离散分布 [450];利用强化算法 [451];训练生成器以采样可转换为离散值的连续值(例如,直接对单词的嵌入向量进行采样)。
还有其他方法朝着该研究方向发展。Song 等人 [278] 使用了一个连续函数来近似哈希值的符号函数。Gulrajani 等人 [19] 用连续生成器建模离散数据。Hjelm 等人 [452] 引入了一种用离散数据训练 GAN 的算法,该算法利用来自判别器的估计差异度量来计算生成样本的重要性权重,从而为训练生成器提供了策略梯度。可以在 [453],[454] 中找到其它的相关工作。在这个有趣的领域需要有更多的工作出现。
新的散度:研究者提出了一系列用于训练 GAN 的新的积分概率度量(IPM),如 Fisher GAN [455],[456],均值和协方差特征匹配 GAN(McGan)[457] 和 Sobolev GAN [458]。是否还有其它有趣的散度类别?这值得进一步的研究。
估计不确定性:通常来说,我们拥有的数据越多,估计的不确定性会越小。GAN 不会给出生成训练样本的分布,但 GAN 想要生成和训练样本分布相同的新样本。因此,GAN 既没有似然也没有明确定义的后验分布。目前已经有关于这个方向研究的初步尝试,例如 Bayesian GAN [459]。尽管我们可以利用 GAN 生成数据,但是如何度量训练好的生成器的不确定性呢?这是另一个值得未来研究的有趣问题。
理论:关于泛化问题,Zhang 等人 [460] 提出了在不同评价指标下的真实分布和学习到的分布之间的泛化界。当用神经距离进行评价时,[460] 中的泛化界表明,只要判别器的集合足够小,无论假设集或生成器集合的大小如何,泛化性都是可以保证的。Arora 等人 [306] 提出了一种新颖的测试方法,使用离散概率的「生日悖论」来估计支撑集大小,并且表明即使图像具有较高的视觉质量,GAN 也会受到模式坍塌的影响。更深入的理论分析非常值得研究。我们如何经验性地测试泛化性?有用的理论应当能够选择模型的类别、容量和架构。这是一个值得未来工作深入研究的有趣问题。
其它:GAN 领域还有许多其它重要的研究问题,如评估方式(详见 3.4 小节)和模式坍缩(详见 4.2 小节)。