使用Pandas处理杂乱数据
现在我有一份非常乱的数据,随便从里面读出一列就可以看出来有多乱了:
import pandas as pd
import numpy as np
data = pd.read_csv("data.csv")
data['Incident Zip'].unique()
D:\ProgramData\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py:2698: DtypeWarning: Columns (8) have mixed types. Specify dtype option on import or set low_memory=False.
interactivity=interactivity, compiler=compiler, result=result)
array([11432.0, 11378.0, 10032.0, 10023.0, 10027.0, 11372.0, 11419.0,
11417.0, 10011.0, 11225.0, 11218.0, 10003.0, 10029.0, 10466.0,
11219.0, 10025.0, 10310.0, 11236.0, nan, 10033.0, 11216.0, 10016.0,
10305.0, 10312.0, 10026.0, 10309.0, 10036.0, 11433.0, 11235.0,
11213.0, 11379.0, 11101.0, 10014.0, 11231.0, 11234.0, 10457.0,
10459.0, 10465.0, 11207.0, 10002.0, 10034.0, 11233.0, 10453.0,
10456.0, 10469.0, 11374.0, 11221.0, 11421.0, 11215.0, 10007.0,
10019.0, 11205.0, 11418.0, 11369.0, 11249.0, 10005.0, 10009.0,
11211.0, 11412.0, 10458.0, 11229.0, 10065.0, 10030.0, 11222.0,
10024.0, 10013.0, 11420.0, 11365.0, 10012.0, 11214.0, 11212.0,
10022.0, 11232.0, 11040.0, 11226.0, 10281.0, 11102.0, 11208.0,
10001.0, 10472.0, 11414.0, 11223.0, 10040.0, 11220.0, 11373.0,
11203.0, 11691.0, 11356.0, 10017.0, 10452.0, 10280.0, 11217.0,
10031.0, 11201.0, 11358.0, 10128.0, 11423.0, 10039.0, 10010.0,
11209.0, 10021.0, 10037.0, 11413.0, 11375.0, 11238.0, 10473.0,
11103.0, 11354.0, 11361.0, 11106.0, 11385.0, 10463.0, 10467.0,
11204.0, 11237.0, 11377.0, 11364.0, 11434.0, 11435.0, 11210.0,
11228.0, 11368.0, 11694.0, 10464.0, 11415.0, 10314.0, 10301.0,
10018.0, 10038.0, 11105.0, 11230.0, 10468.0, 11104.0, 10471.0,
11416.0, 10075.0, 11422.0, 11355.0, 10028.0, 10462.0, 10306.0,
10461.0, 11224.0, 11429.0, 10035.0, 11366.0, 11362.0, 11206.0,
10460.0, 10304.0, 11360.0, 11411.0, 10455.0, 10475.0, 10069.0,
10303.0, 10308.0, 10302.0, 11357.0, 10470.0, 11367.0, 11370.0,
10454.0, 10451.0, 11436.0, 11426.0, 10153.0, 11004.0, 11428.0,
11427.0, 11001.0, 11363.0, 10004.0, 10474.0, 11430.0, 10000.0,
10307.0, 11239.0, 10119.0, 10006.0, 10048.0, 11697.0, 11692.0,
11693.0, 10573.0, 83.0, 11559.0, 10020.0, 77056.0, 11776.0,
70711.0, 10282.0, 11109.0, 10044.0, '10452', '11233', '10468',
'10310', '11105', '10462', '10029', '10301', '10457', '10467',
'10469', '11225', '10035', '10031', '11226', '10454', '11221',
'10025', '11229', '11235', '11422', '10472', '11208', '11102',
'10032', '11216', '10473', '10463', '11213', '10040', '10302',
'11231', '10470', '11204', '11104', '11212', '10466', '11416',
'11214', '10009', '11692', '11385', '11423', '11201', '10024',
'11435', '10312', '10030', '11106', '10033', '10303', '11215',
'11222', '11354', '10016', '10034', '11420', '10304', '10019',
'11237', '11249', '11230', '11372', '11207', '11378', '11419',
'11361', '10011', '11357', '10012', '11358', '10003', '10002',
'11374', '10007', '11234', '10065', '11369', '11434', '11205',
'11206', '11415', '11236', '11218', '11413', '10458', '11101',
'10306', '11355', '10023', '11368', '10314', '11421', '10010',
'10018', '11223', '10455', '11377', '11433', '11375', '10037',
'11209', '10459', '10128', '10014', '10282', '11373', '10451',
'11238', '11211', '10038', '11694', '11203', '11691', '11232',
'10305', '10021', '11228', '10036', '10001', '10017', '11217',
'11219', '10308', '10465', '11379', '11414', '10460', '11417',
'11220', '11366', '10027', '11370', '10309', '11412', '11356',
'10456', '11432', '10022', '10013', '11367', '11040', '10026',
'10475', '11210', '11364', '11426', '10471', '10119', '11224',
'11418', '11429', '11365', '10461', '11239', '10039', '00083',
'11411', '10075', '11004', '11360', '10453', '10028', '11430',
'10307', '11103', '10004', '10069', '10005', '10474', '11428',
'11436', '10020', '11001', '11362', '11693', '10464', '11427',
'10044', '11363', '10006', '10000', '02061', '77092-2016', '10280',
'11109', '14225', '55164-0737', '19711', '07306', '000000',
'NO CLUE', '90010', '10281', '11747', '23541', '11776', '11697',
'11788', '07604', 10112.0, 11788.0, 11563.0, 11580.0, 7087.0,
11042.0, 7093.0, 11501.0, 92123.0, 0.0, 11575.0, 7109.0, 11797.0,
'10803', '11716', '11722', '11549-3650', '10162', '92123', '23502',
'11518', '07020', '08807', '11577', '07114', '11003', '07201',
'11563', '61702', '10103', '29616-0759', '35209-3114', '11520',
'11735', '10129', '11005', '41042', '11590', 6901.0, 7208.0,
11530.0, 13221.0, 10954.0, 11735.0, 10103.0, 7114.0, 11111.0,
10107.0], dtype=object)
这一列中,既有字符串str、又有浮点数float、还有缺失值(nan、no clue),还有一些极不规范的数据。
接下来我们将对这些数据一一进行处理:
1. 转换字符类型
可以在读取数据时就将这一列数据的类型统一转换为字符串,方便进行批量处理,并同时对nan数据进行统一表达。
na_values = ['NO CLUE', 'N/A', '0']
data = pd.read_csv('data.csv', na_values=na_values, dtype={'Incident Zip': str})
data["Incident Zip"].unique()
array(['11432', '11378', '10032', '10023', '10027', '11372', '11419',
'11417', '10011', '11225', '11218', '10003', '10029', '10466',
'11219', '10025', '10310', '11236', nan, '10033', '11216', '10016',
'10305', '10312', '10026', '10309', '10036', '11433', '11235',
'11213', '11379', '11101', '10014', '11231', '11234', '10457',
'10459', '10465', '11207', '10002', '10034', '11233', '10453',
'10456', '10469', '11374', '11221', '11421', '11215', '10007',
'10019', '11205', '11418', '11369', '11249', '10005', '10009',
'11211', '11412', '10458', '11229', '10065', '10030', '11222',
'10024', '10013', '11420', '11365', '10012', '11214', '11212',
'10022', '11232', '11040', '11226', '10281', '11102', '11208',
'10001', '10472', '11414', '11223', '10040', '11220', '11373',
'11203', '11691', '11356', '10017', '10452', '10280', '11217',
'10031', '11201', '11358', '10128', '11423', '10039', '10010',
'11209', '10021', '10037', '11413', '11375', '11238', '10473',
'11103', '11354', '11361', '11106', '11385', '10463', '10467',
'11204', '11237', '11377', '11364', '11434', '11435', '11210',
'11228', '11368', '11694', '10464', '11415', '10314', '10301',
'10018', '10038', '11105', '11230', '10468', '11104', '10471',
'11416', '10075', '11422', '11355', '10028', '10462', '10306',
'10461', '11224', '11429', '10035', '11366', '11362', '11206',
'10460', '10304', '11360', '11411', '10455', '10475', '10069',
'10303', '10308', '10302', '11357', '10470', '11367', '11370',
'10454', '10451', '11436', '11426', '10153', '11004', '11428',
'11427', '11001', '11363', '10004', '10474', '11430', '10000',
'10307', '11239', '10119', '10006', '10048', '11697', '11692',
'11693', '10573', '00083', '11559', '10020', '77056', '11776',
'70711', '10282', '11109', '10044', '02061', '77092-2016', '14225',
'55164-0737', '19711', '07306', '000000', '90010', '11747',
'23541', '11788', '07604', '10112', '11563', '11580', '07087',
'11042', '07093', '11501', '92123', '00000', '11575', '07109',
'11797', '10803', '11716', '11722', '11549-3650', '10162', '23502',
'11518', '07020', '08807', '11577', '07114', '11003', '07201',
'61702', '10103', '29616-0759', '35209-3114', '11520', '11735',
'10129', '11005', '41042', '11590', '06901', '07208', '11530',
'13221', '10954', '11111', '10107'], dtype=object)
处理带横杠的数据
先查看带有横杠的数据有多少条:
dash_row = data["Incident Zip"].str.contains('-').fillna(False)#将不包含横杠的列标记为False
data[dash_row]
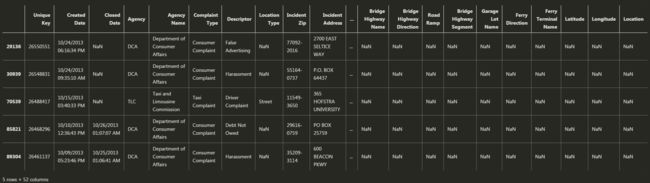
带横杠的数据
因为其他编码都是五位数,只需将编码全部进行截断,只保留前五位,就可以把多余的代码去除了。
顺便看看还有没有超过五位的编码:
longcode = data['Incident Zip'].str.len() > 5
data['Incident Zip'][longcode].unique()
array(['77092-2016', '55164-0737', '000000', '11549-3650', '29616-0759',
'35209-3114'], dtype=object)
对这些编码进行截断
data['Incident Zip'] = data['Incident Zip'].str.slice(0,5)
data['Incident Zip'].unique()
array(['11432', '11378', '10032', '10023', '10027', '11372', '11419',
'11417', '10011', '11225', '11218', '10003', '10029', '10466',
'11219', '10025', '10310', '11236', nan, '10033', '11216', '10016',
'10305', '10312', '10026', '10309', '10036', '11433', '11235',
'11213', '11379', '11101', '10014', '11231', '11234', '10457',
'10459', '10465', '11207', '10002', '10034', '11233', '10453',
'10456', '10469', '11374', '11221', '11421', '11215', '10007',
'10019', '11205', '11418', '11369', '11249', '10005', '10009',
'11211', '11412', '10458', '11229', '10065', '10030', '11222',
'10024', '10013', '11420', '11365', '10012', '11214', '11212',
'10022', '11232', '11040', '11226', '10281', '11102', '11208',
'10001', '10472', '11414', '11223', '10040', '11220', '11373',
'11203', '11691', '11356', '10017', '10452', '10280', '11217',
'10031', '11201', '11358', '10128', '11423', '10039', '10010',
'11209', '10021', '10037', '11413', '11375', '11238', '10473',
'11103', '11354', '11361', '11106', '11385', '10463', '10467',
'11204', '11237', '11377', '11364', '11434', '11435', '11210',
'11228', '11368', '11694', '10464', '11415', '10314', '10301',
'10018', '10038', '11105', '11230', '10468', '11104', '10471',
'11416', '10075', '11422', '11355', '10028', '10462', '10306',
'10461', '11224', '11429', '10035', '11366', '11362', '11206',
'10460', '10304', '11360', '11411', '10455', '10475', '10069',
'10303', '10308', '10302', '11357', '10470', '11367', '11370',
'10454', '10451', '11436', '11426', '10153', '11004', '11428',
'11427', '11001', '11363', '10004', '10474', '11430', '10000',
'10307', '11239', '10119', '10006', '10048', '11697', '11692',
'11693', '10573', '00083', '11559', '10020', '77056', '11776',
'70711', '10282', '11109', '10044', '02061', '77092', '14225',
'55164', '19711', '07306', '00000', '90010', '11747', '23541',
'11788', '07604', '10112', '11563', '11580', '07087', '11042',
'07093', '11501', '92123', '11575', '07109', '11797', '10803',
'11716', '11722', '11549', '10162', '23502', '11518', '07020',
'08807', '11577', '07114', '11003', '07201', '61702', '10103',
'29616', '35209', '11520', '11735', '10129', '11005', '41042',
'11590', '06901', '07208', '11530', '13221', '10954', '11111',
'10107'], dtype=object)
经过这样修改之后的编码已经比较规范了,接下来可以利用编码对数据进行筛选查看了,数据中编码以0和1开头的最多,可以先查看一下以其他数字开头的数据有哪些。
zips = data['Incident Zip']
zero_one = zips.str.startswith('0') | zips.str.startswith('1')
n_zeroone = ~(zero_one) & zips.notnull()
zips[n_zeroone]
12102 77056
13450 70711
29136 77092
30939 55164
44008 90010
47048 23541
57636 92123
71001 92123
71834 23502
80573 61702
85821 29616
89304 35209
94201 41042
Name: Incident Zip, dtype: object
data[n_zeroone][['Incident Zip','Descriptor','City']].sort_values('Incident Zip')
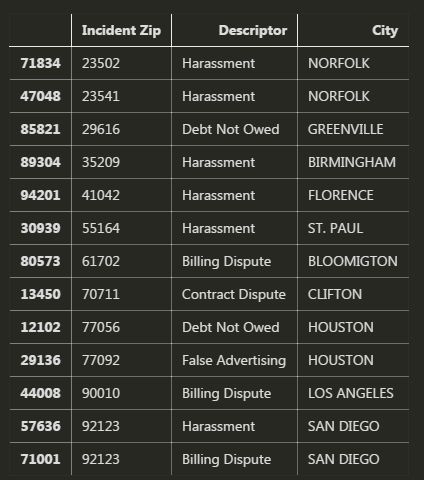
非0/1开头的数据
还可以通过计数的方式查看数据分布
data['City'].str.upper().value_counts()
BROOKLYN 31662
NEW YORK 22664
BRONX 18438
STATEN ISLAND 4766
JAMAICA 2246
FLUSHING 1803
ASTORIA 1568
RIDGEWOOD 1073
CORONA 707
OZONE PARK 693
LONG ISLAND CITY 678
FAR ROCKAWAY 652
ELMHURST 647
WOODSIDE 609
EAST ELMHURST 562
QUEENS VILLAGE 549
JACKSON HEIGHTS 541
FOREST HILLS 541
SOUTH RICHMOND HILL 521
MASPETH 473
WOODHAVEN 464
FRESH MEADOWS 435
SPRINGFIELD GARDENS 434
BAYSIDE 411
SOUTH OZONE PARK 410
RICHMOND HILL 404
REGO PARK 402
MIDDLE VILLAGE 396
SAINT ALBANS 387
WHITESTONE 348
...
WOODBURY 1
STAMFORD 1
LAWRENCE 1
LOS ANGELES 1
SYRACUSE 1
ROSELYN 1
LYNBROOK 1
MINEOLA 1
FLORENCE 1
EAST ROCKAWAY 1
FREEPORT 1
CHEEKTOWAGA 1
ROSLYN 1
WEST NEW YORK 1
NEW YOR 1
UNION CITY 1
HASBROCK HEIGHTS 1
ELIZABETH 1
NORWELL 1
BELLEVILLE 1
EDGEWATER 1
RYEBROOK 1
NANUET 1
JERSEY CITY 1
GREENVILLE 1
BRIARWOOD 1
BLOOMIGTON 1
BIRMINGHAM 1
COL.ANVURES 1
BRIDGE WATER 1
Name: City, Length: 100, dtype: int64
data['Incident Zip'].unique()
array(['11432', '11378', '10032', '10023', '10027', '11372', '11419',
'11417', '10011', '11225', '11218', '10003', '10029', '10466',
'11219', '10025', '10310', '11236', nan, '10033', '11216', '10016',
'10305', '10312', '10026', '10309', '10036', '11433', '11235',
'11213', '11379', '11101', '10014', '11231', '11234', '10457',
'10459', '10465', '11207', '10002', '10034', '11233', '10453',
'10456', '10469', '11374', '11221', '11421', '11215', '10007',
'10019', '11205', '11418', '11369', '11249', '10005', '10009',
'11211', '11412', '10458', '11229', '10065', '10030', '11222',
'10024', '10013', '11420', '11365', '10012', '11214', '11212',
'10022', '11232', '11040', '11226', '10281', '11102', '11208',
'10001', '10472', '11414', '11223', '10040', '11220', '11373',
'11203', '11691', '11356', '10017', '10452', '10280', '11217',
'10031', '11201', '11358', '10128', '11423', '10039', '10010',
'11209', '10021', '10037', '11413', '11375', '11238', '10473',
'11103', '11354', '11361', '11106', '11385', '10463', '10467',
'11204', '11237', '11377', '11364', '11434', '11435', '11210',
'11228', '11368', '11694', '10464', '11415', '10314', '10301',
'10018', '10038', '11105', '11230', '10468', '11104', '10471',
'11416', '10075', '11422', '11355', '10028', '10462', '10306',
'10461', '11224', '11429', '10035', '11366', '11362', '11206',
'10460', '10304', '11360', '11411', '10455', '10475', '10069',
'10303', '10308', '10302', '11357', '10470', '11367', '11370',
'10454', '10451', '11436', '11426', '10153', '11004', '11428',
'11427', '11001', '11363', '10004', '10474', '11430', '10000',
'10307', '11239', '10119', '10006', '10048', '11697', '11692',
'11693', '10573', '00083', '11559', '10020', '77056', '11776',
'70711', '10282', '11109', '10044', '02061', '77092', '14225',
'55164', '19711', '07306', '00000', '90010', '11747', '23541',
'11788', '07604', '10112', '11563', '11580', '07087', '11042',
'07093', '11501', '92123', '11575', '07109', '11797', '10803',
'11716', '11722', '11549', '10162', '23502', '11518', '07020',
'08807', '11577', '07114', '11003', '07201', '61702', '10103',
'29616', '35209', '11520', '11735', '10129', '11005', '41042',
'11590', '06901', '07208', '11530', '13221', '10954', '11111',
'10107'], dtype=object)

机器学习菜鸡互啄