1.cookielib模块
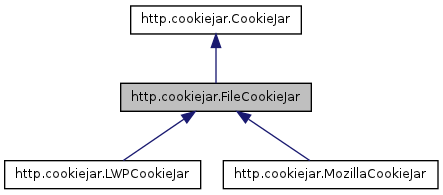
cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源。例如可以利用本模块的CookieJar类的对象来捕获cookie并在后续连接请求时重新发送。coiokielib模块用到的对象主要有下面几个:CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。其中他们的关系如下:
2.urllib2模块
说到urllib2模块最强大的部分绝对是它的opener,
urllib2模块的 OpenerDirector 操作类。这是一个管理很多处理类(Handler)的类。而所有这些 Handler 类都对应处理相应的协议,或者特殊功能。分别有下面的处理类:
- BaseHandler
- HTTPErrorProcessor
- HTTPDefaultErrorHandler
- HTTPRedirectHandler
- ProxyHandler
- AbstractBasicAuthHandler
- HTTPBasicAuthHandler
- ProxyBasicAuthHandler
- AbstractDigestAuthHandler
- ProxyDigestAuthHandler
- AbstractHTTPHandler
- HTTPHandler
- HTTPCookieProcessor
- UnknownHandler
- FileHandler
- FTPHandler
- CacheFTPHandler
cookielib模块一般与urllib2模块配合使用,主要用在urllib2.build_oper()函数中作为urllib2.HTTPCookieProcessor()的参数。
由此可以使用python模拟网站登录。
先写个获取CookieJar实例的demo:
1 #!/usr/bin/env python 2 #-*-coding:utf-8-*- 3 4 import urllib 5 import urllib2 6 import cookielib 7 8 #获取Cookiejar对象(存在本机的cookie消息) 9 cookie = cookielib.CookieJar() 10 #自定义opener,并将opener跟CookieJar对象绑定 11 opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) 12 #安装opener,此后调用urlopen()时都会使用安装过的opener对象 13 urllib2.install_opener(opener) 14 15 url = "http://www.baidu.com" 16 urllib2.urlopen(url)
然后写个用POST方法来访问网站的方式(用urllib2模拟一起post过程):
1 #! /usr/bin/env python 2 #coding=utf-8 3 4 import urllib2 5 import urllib 6 import cookielib 7 8 def login(): 9 email = raw_input("请输入用户名:") 10 pwd = raw_input("请输入密码:") 11 data={"email":email,"password":pwd} #登陆用户名和密码 12 post_data=urllib.urlencode(data) #将post消息化成可以让服务器编码的方式 13 cj=cookielib.CookieJar() #获取cookiejar实例 14 opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) 15 #自己设置User-Agent(可用于伪造获取,防止某些网站防ip注入) 16 headers ={"User-agent":"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1"} 17 website = raw_input('请输入网址:') 18 req=urllib2.Request(website,post_data,headers) 19 content=opener.open(req) 20 print content.read() #linux下没有gbk编码,只有utf-8编码 21 22 if __name__ == '__main__': 23 login()
注意这个例子经过测试,发现只有人人网和开心网之类的网站可以,而像支付宝,百度网盘,甚至是我们学校的教务系统都不能成功登录,就会显示如下的报错消息:
Traceback (most recent call last): File "login.py", line 23, inlogin() File "login.py", line 19, in login content=opener.open(req) File "/usr/lib/python2.7/urllib2.py", line 406, in open response = meth(req, response) File "/usr/lib/python2.7/urllib2.py", line 519, in http_response 'http', request, response, code, msg, hdrs) File "/usr/lib/python2.7/urllib2.py", line 444, in error return self._call_chain(*args) File "/usr/lib/python2.7/urllib2.py", line 378, in _call_chain result = func(*args) File "/usr/lib/python2.7/urllib2.py", line 527, in http_error_default raise HTTPError(req.get_full_url(), code, msg, hdrs, fp) urllib2.HTTPError: HTTP Error 405: Method Not Allowed
可能是这些网站在编写时不接受客户端请求该方法,具体原因我也不知道为什么。而且这个程序不能自动通过有验证码验证的网站,所以纯粹学习它的原理吧。
然后放一下用python模拟登录的几个示例(转自:http://www.nowamagic.net/academy/detail/1302882)
# -*- coding: utf-8 -*- # !/usr/bin/python import urllib2 import urllib import cookielib import re auth_url = 'http://www.nowamagic.net/' home_url = 'http://www.nowamagic.net/'; # 登陆用户名和密码 data={ "username":"nowamagic", "password":"pass" } # urllib进行编码 post_data=urllib.urlencode(data) # 发送头信息 headers ={ "Host":"www.nowamagic.net", "Referer": "http://www.nowamagic.net" } # 初始化一个CookieJar来处理Cookie cookieJar=cookielib.CookieJar() # 实例化一个全局opener opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar)) # 获取cookie req=urllib2.Request(auth_url,post_data,headers) result = opener.open(req) # 访问主页 自动带着cookie信息 result = opener.open(home_url) # 显示结果 print result.read()
1. 使用已有的cookie访问网站
import cookielib, urllib2 ckjar = cookielib.MozillaCookieJar(os.path.join('C:\Documents and Settings\tom\Application Data\Mozilla\Firefox\Profiles\h5m61j1i.default', 'cookies.txt')) req = urllib2.Request(url, postdata, header) req.add_header('User-Agent', \ 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)') opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(ckjar) ) f = opener.open(req) htm = f.read() f.close()
2. 访问网站获得cookie,并把获得的cookie保存在cookie文件中
import cookielib, urllib2 req = urllib2.Request(url, postdata, header) req.add_header('User-Agent', \ 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)') ckjar = cookielib.MozillaCookieJar(filename) ckproc = urllib2.HTTPCookieProcessor(ckjar) opener = urllib2.build_opener(ckproc) f = opener.open(req) htm = f.read() f.close() ckjar.save(ignore_discard=True, ignore_expires=True)
3. 使用指定的参数生成cookie,并用这个cookie访问网站
import cookielib, urllib2 cookiejar = cookielib.CookieJar() urlOpener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookiejar)) values = {'redirect':", 'email':'[email protected]', 'password':'password', 'rememberme':", 'submit':'OK, Let Me In!'} data = urllib.urlencode(values) request = urllib2.Request(url, data) url = urlOpener.open(request) print url.info() page = url.read() request = urllib2.Request(url) url = urlOpener.open(request) page = url.read() print page
另外,补充一下urllib2的方法:
1.geturl():
这个返回获取的真实的URL,这个很有用,因为urlopen(或者opener对象使用的)或许会有重定向。获取的URL或许跟请求URL不同。
URL重定向(URL redirection,或称网址重定向或网域名称转址),是指当使用者浏览某个网址时,将他导向到另一个网址的技术。常用在把一串很长的网站网址,转成较短的网址。因为当要传播某网站的网址时,常常因为网址太长,不好记忆;又有可能因为换了网路的免费网页空间,网址又必须要变更,不知情的使用者还以为网站关闭了。这时就可以用网路上的转址服务了。这个技术使一个网页是可借由不同的统一资源定位符(URL)连结。
>>> import urllib2 >>> url = "http://www.baidu.com" >>> req = urllib2.Request(url) >>> response = urllib2.urlopen(req) >>> response.geturl() 'http://www.baidu.com' >>> print response.info() Date: Fri, 28 Mar 2014 03:30:01 GMT Content-Type: text/html Transfer-Encoding: chunked Connection: Close Vary: Accept-Encoding Set-Cookie: BAIDUID=AF7C001FCA87716A52B353C500FC45DB:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com Set-Cookie: BDSVRTM=0; path=/ Set-Cookie: H_PS_PSSID=1466_5225_5288_5723_4261_4759_5659; path=/; domain=.baidu.com P3P: CP=" OTI DSP COR IVA OUR IND COM " Expires: Fri, 28 Mar 2014 03:29:06 GMT Cache-Control: private Server: BWS/1.1 BDPAGETYPE: 1 BDQID: 0xea1372bf0001780d BDUSERID: 0
我们可以通过urllib2 默认情况下会针对 HTTP 3XX 返回码自动进行 redirect 动作(URL重定向),无需人工配置。要检测是否发生了 redirect 动作,只要检查一下 Response 的 URL 和 Request 的 URL 是否一致就可以了。
import urllib2 my_url = 'http://www.google.cn' response = urllib2.urlopen(my_url) redirected = response.geturl() == my_url print redirected my_url = 'http://rrurl.cn/b1UZuP' response = urllib2.urlopen(my_url) redirected = response.geturl() == my_url print redirected
Debug Log
使用 urllib2 时,可以通过下面的方法把 debug Log 打开,这样收发包的内容就会在屏幕上打印出来,方便调试,有时可以省去抓包的工作
import urllib2 httpHandler = urllib2.HTTPHandler(debuglevel=1) httpsHandler = urllib2.HTTPSHandler(debuglevel=1) opener = urllib2.build_opener(httpHandler, httpsHandler) urllib2.install_opener(opener) response = urllib2.urlopen('http://www.google.com')
基本cookielib和urllib2结合就这些内容,请多多指教!