vivado pcie DMA传输实战
-
写在前面
在我的另一篇博文中我已经详细介绍了如何对Xilinx pcie IP进行PIO数据传输vivado vc707 pcie传输实验。但是,PIO模式仅能用来传输少量的数据,因为它全程需要CPU监督运行,这样的运行方式非常不利于大量数据的传输。幸运的是,在这方面已经有了很多的参考,使我们这些新人学起来不是那么费劲。xapp1052出来的时间很早,它是Xilinx官方出的用来测试pcie IP核性能的程序。关于它的缺点,网上已经有很多人写过,比如这篇DMA技术之PCIE应用(XAPP1052注意点),这篇文章对xapp1052的问题说的很清楚,包括DMA读写过程,建议读一读;还有这篇别人转载的Xilinx FPGA 的PCIE 设计,这篇文章的前半部分介绍了pcie的理论,后半部分介绍并实现了如何仿真xapp1052 的DMA。虽然xapp1052有很多的缺点,但是优点也同样突出,对于初学者来说非常适合作为DMA的入门,这主要源于它的代码结构非常清晰,而且接触了DMA底层传输的实现;有时候你可能发现pcie理论看了一大堆觉得自己已经懂了很多,但是细想却发现自己什么也不懂,那就是因为缺乏实际的工程训练,而xapp1052就是这样一个非常好的工程。本篇博文暂时决定分为三小节的内容,分别为:xapp1052源码解析、xapp1052部分问题、解决办法。
-
xapp1052源码解析
xapp1052经历了多次的版本更迭,目前最新的版本是3.3,可以Xilinx官网下载;在最新的版本中添加了对Kintex7系列FPGA的支持,也可以移植到Artix7以及Zynq7000系列Soc上;官方的原话如下:

我这里使用的是Virtex7系列的,其实也是兼容的。 XILINX 公司 7 系列的 FPGA 全部采用了 AXI4 总线协议,所以 BMD 代码并不能直接使用。因此在最新的版本中官方提供了“TRN协议”(不准确的叫法)和AXI-Stream协议的转换代码,所以这部分不需要我们操心。完整的BMD工程如下所示:
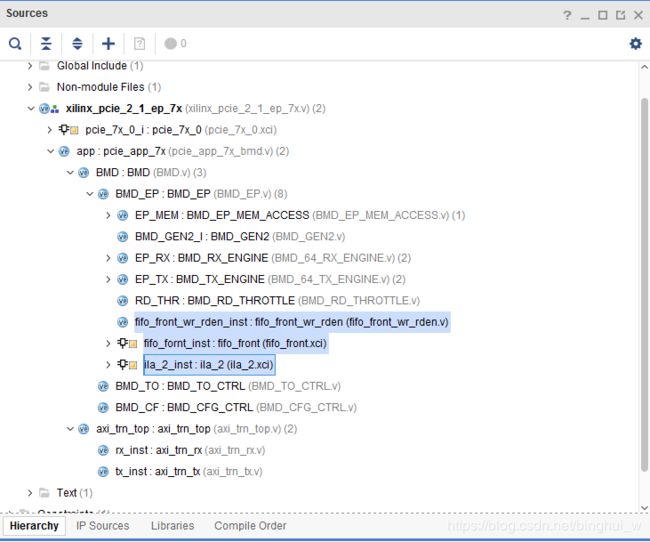
图中的阴影部分是我自己加的。图中axi_trn_top.v以及下面的两个子模块就是完成协议转换的。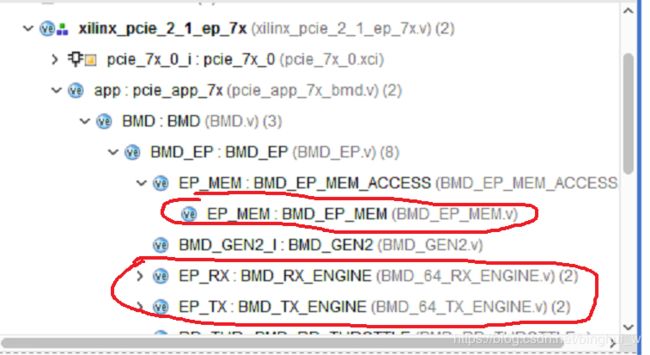
BMD_EP_MEM.v、BMD_64_RX_ENGINE、BMD_64_TX_ENGINE这三个文件是我们需要特别关心的。BMD_EP_MEM.v里面包含了各种寄存器,上位机对EP端进行DMA读写、上电配置初始化等过程都要先对这里面的寄存器进行操作。
我们可以看一下这个文件中的第一个寄存器都包含哪些内容

这个寄存器是reg0,里面有上位机对EP的复位、置位操作,也有EP发给上位机的rd_d_o[31:0]数据。在上位机程序中有*VIRTEX5_WriteReg32();*函数,通过该函数可以向EP端寄存器中写入各种数据,从而达到配置DMA传输的目的。详细的寄存器功能描述可以参考Xilinx xapp1052.pdf这本英文的官方文档。
BMD_64_RX_ENGINE.v该文件是用来接收从上位机发过来的各种TLP包,并对包进行解析。解析包的类型如下图:

BMD_64_TX_ENGINE.v用来向上位机发送各种TLP包,并且产生Legacy 中断信号以及MSI中断消息,发送包类型如下:
 我们只考虑存储器读写操作,我们来看一下BMD工程是如何完成这些操作的。
我们只考虑存储器读写操作,我们来看一下BMD工程是如何完成这些操作的。
官方对此的描述为:

1、存储器读:首先对EP端进行复位,通过PCIE的PIO模式向EP端寄存器0写0x00000001,用来复位EP,然后再通过写0x00000000取消复位(在xapp1052中有两个复位,一个是FPGA本身的硬件复位rst_n,还有一个是上位机发来的复位信息init_rst),随后发送读取数据的地址、要读取TLP的长度、个数等;第六步启动DMA传输,第七步等待EP端发送的中断信号。另外需要说明的是,存储器读是上位机发送数据给EP;存储器写是EP发送数据给上位机内存。
数据是这样传输的:首先EP通过发送TLP给上位机,告诉上位机我需要多少的数据,然后上位机将数据以完成报文的形式发送给EP,随后的RX_ENGINE将完成报文的数据接收,做进一步的处理(xapp1052直接将数据丢弃了)。
2、存储器写:存储器写比存储器读的方式简单点,EP端直接通过TX_ENGINE发送存储器写TLP即可,当发送完以后产生中断信号告诉上位机发送完,上位机检测到中断信号以后结束当次DMA传输。
这一部分只是简单地介绍一下BMD工程的结构和数据传输过程,详细的过程可以参考其他博文,这里不作赘述。
3. xapp部分问题
1、数据存储:前面讲过xapp1052是为了测试Xilinx pcie IP核的性能的演示程序,所以只做了数据pattern验证功能,没有做数据存储。其实只要外挂一个DDR或者用BRAM都可以将数据存储。
2、数据乱序:将数据存储起来很简单,但是有一个问题就是,上位机发送过来的数据并不是按照你所期望的顺序过来的,也就是说你需要在EP端对接收到的数据进行重新排序。在TLP Header中有Attr字段,下面通过截图展示:
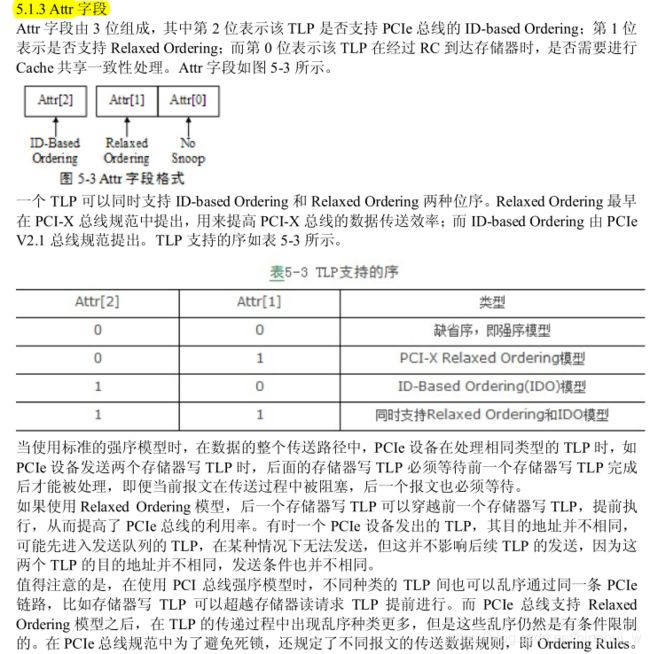
在网上也看到很多人都遇到这个问题关于PCIe完成报文乱序的问题还有eetop乱序帖子。一般情况下我们发送的TLP包头的Attr字段用的都是缺省,也就是强序模型,如上图所述;在这个模式下,PCIE设备在处理相同类型的TLP时,是不应该乱序的,比如我发送很多TLP读请求并且是按顺序发送的,按道理它也应该按顺序返回数据才对。但要注意这是PCIe设备,也就是EP在处理相同类型的TLP,并不是主机,也就是说你发的读请求是按顺序发的,但是我主机不一定按顺序将数据给你传过来,我pcie设备虽然是按顺序处理TLP包,但是你主机发过来的都不是顺序的,我pcie设备也无能为力了。这也就是为什么EP端发存储器写请求向上位机内存中写数据时并不会出现乱序。
中断问题
中断问题在网上也有人遇到过,大体是这样的:在完成一次DMA操作后没有清理中断信号,导致上位机一直收到中断信息。在 PCI 总线中,所有需要提交中断请求的设备,必须能够通过 INTx 引脚提交中断请求,而MSI 机制是一个可选机制。而在 PCIe 总线中,PCIe 设备必须支持 MSI 或者 MSI-X 中断请求机制,而可以不支持 INTx 中断消息。
这一点在生成pcie IP core的时候可以设置:
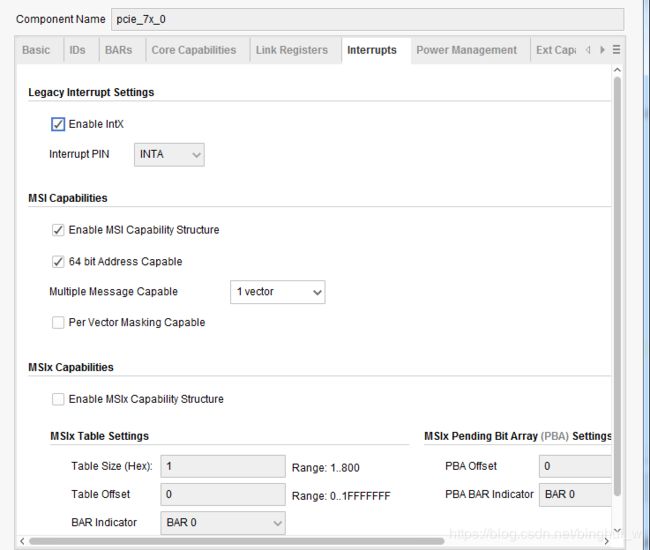
在这里我是将Legacy Interrupt和MSI Capability都勾上了,也就是支持两种中断,在后面我会结合实际抓取的信号来解释中断问题。
4.解决方法
数据存储的问题不用多说,不管是存RAM还是DDR都是可以的,只要控制好存取数据的时机就行了,主要是乱序的问题,网上的帖子大多说自己遇到了这个问题,然后就没有然后了,没有人给出详细的解决办法,这令我们这些初学者实在是摸不着头脑。我也是最开始在网上寻找解决办法,期望能有现成的代码可供使用,但找了一圈发现并无所获,于是自己潜心钻研了半个月,总算是解决了这个问题。
首先,我们来了解一下TLP包头中tag字段的用意:
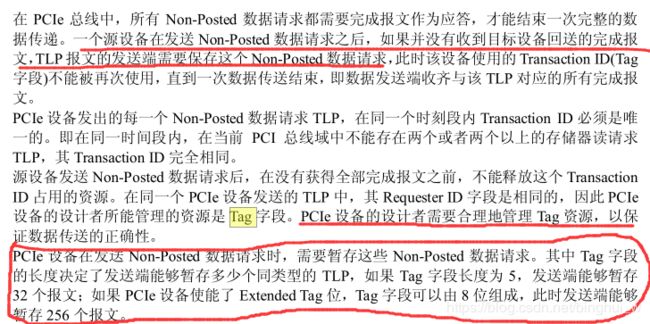
一个tag对应的有512B的数据量,我这边可以缓存256个tag,所以一共有128KB的数据量
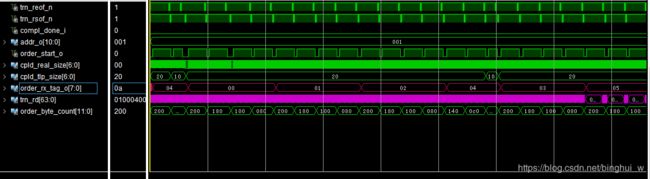
这是在vivado中用debug抓取到的信号,注意观察红色的两条总线,上面一条就是从完成报文中提取的tag标签。按理说,我发给上位机的时候tag是从0开始步长为1自加,所以返回的同样应该是这样才是正确的数据顺序。上图中,tag4数据先来一部分然后是tag0,tag1,tag2,tag4,tag3,tag5…,正确的顺序应该是tag0,tag1,tag2,tag3,tag4,tag5…
要完成乱序重排,我们还需要一个参数 Byte Count字段:

具体到debug图片上的就是order_byte_count[11:0],为十六进制显示,200十进制为512,单位是Byte,刚好是一个tag对应的数据长度。
对于FPGA内部资源较为丰富的板卡来说可以在FPGA内部用BRAM来完成乱序重排,如果内部资源不够丰富的话就需要外挂DDR来实现,我用的是Virtex 7系列,内部资源很丰富,因此使用BRAM可以大大降低开发难度。值得注意的是,这种乱序的情况是随机发生的
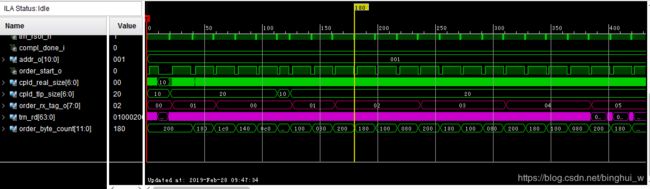
这是最新抓取的数据乱序的情况,可以看到和上面有所不同。
解决乱序的方法之一(我只知道一个…)就是使用一个大的RAM将256个tag对应的数据全部存起来,不同tag对应的起始地址不同,然后按顺序读出。以上图乱序情况为例。
tag0首先到来,由于tag0是第一个tag,因此tag0从RAM的地址0开始存储,本设计使用的是64位数据宽度,深度为16384的BRAM(前面算出256个tag的数据量为128KB=131072B,再除以8就得到了64位数据宽度的RAM的深度);每一个tag的数据量为512B,因此ram中tag0的地址空间应该是00H–3FH,tag1为40H–7FH,tag2为80H–BFH,tag3为C0H–FFH,以此类推。上图中假设tag0最开始只到了10个数据,那么地址范围为00H–09H,由于tag0并没有收齐tag1就来了,所以0AH–3FH这一段地址空间将暂时不存放数据,而新来的tag1继续从40H开始存储,随后等tag0的数据全部收到之后现将tag0发送出去,如果在tag0没有收完的情况下,后续tag1、tag2等全部收集完,也不能将tag1、tag2数据发送出去。
首先要解决的就是tag标签和RAM地址之间的映射关系,因为你不可能通过Verilog case语句一个一个自己映射,一定是要有公式一样的东西的。幸运的是通过我不懈的努力终于找到了这样一个公式:
addra_r <= {tag,6’b000000} + {7’h40 - byte_count[9:3]}; //每一个tag对应的存储地址
不同的应用也许公式要稍做修改,但就我的应用而言是完全适用的。我们可以验证一下:以上图为例,tag为0时,byte_count[11:0]=200H,代入公式刚好得到addra_r = 0;当tag为1时,addra_r = 40H;当tag再为0时,byte_count[11:0]=1C0H,addra_r = 08H…感兴趣的可以自己接着往下算。
当映射关系做好了以后,还要通过状态机来控制数据从BRAM中读出,当然你可以等256个tag全部收齐以后再从地址0一个一个读出,但这样显然会浪费很多的时间,所以恰当的做法是顺序收齐一个tag释放一个tag。
在这里,我的做法是这样的:
case(bmd_64_rx_state_q)
`BMD_64_RX_CPLD_QW1 : begin
order_start_o <= 1'b1;
order_rx_tag_o <= trn_rd_q[47:40];
if(trn_rrem_n_q)
order_data_o <= {trn_rd_q[31:0],trn_rd[63:32]};
else
order_data_o <= {trn_rd_q[31:0],trn_rd[63:32]};
end
`BMD_64_RX_CPLD_QWN : begin
order_start_o <= 1'b1;
if (!trn_reof_n_q) begin
order_start_o <= 1'b0;
end
else begin
order_data_o <= {trn_rd_q[31:0],trn_rd[63:32]};
end
end
default: begin
order_start_o <= 1'b0;
order_data_o <= 64'd0;
end
上面这段程序我们可以得到order_start信号,在我们截图中也有这个信号。在这个信号的上升沿使用公式得到tag的存储地址;然后在下一个上升沿来之前,addra_r自加,这样就可以将每一个tag的数据全部顺序存储。
if(order_start)begin
if(pos_echo)begin
addra_r <= {order_tag,6'b000000} + {7'h40 - order_byte_count[9:3]};
end
else
addra_r <= addra_r + 14'b1;
end
else if(order_start_r1)begin
addra_r <= addra_r + 14'b1;
end
else begin
state <= tag_rx;
addra_r <= addra_r;
end
order_start_r1是order_start延时一个时钟周期的信号。
数据读取的方法:
空闲状态:
if addra = 3f
使能ram读,状态转移到读tag0
else
空闲状态
读tag0:
if 读地址 <= 3f
读地址自加1,使能ram读,状态维持
else if addra = 7f
读使能,状态转移到读tag1
else
读地址不变,读使能为0
读tag1:
if 读地址 <= 7f
读地址自加1,使能ram读,状态维持
else if addra = bf
读使能,状态转移到读tag2
else
读地址不变,读使能为0
else
停止状态
读tag2:
if 读地址 <= bf
读地址自加1,使能ram读,状态维持
else if addra = ff
读使能,状态转移到读tag3
else
读地址不变,读使能为0
读tag3:
if 读地址 <= ff
读地址自加1,使能ram读,状态维持
else if addra = 13f
读使能,状态转移到读tag4
else
读地址不变,读使能为0
后面的以此类推...
为了验证这段代码的正确性,我手工画了几种数据乱序的情况:

首先我们来看情况二,在这种情况下我们的接受顺序是tag03->tag00->tag01(部分)->tag04->tag01(收完)…
按照第一段程序所写,c0H–ffH收满tag03,由于空闲状态的转移条件不满足,因此伪代码将停留在空闲状态;随后00H–3fH收满tag00,空闲状态的转移条件满足,伪代码转移到读tag0状态,此时ram读地址依然为初始化值0,必然小于3fH,于是将tag0对应的数据全部读出,此时ram读地址为40H。在读tag00的同时,tag01的数据也从40H开始存入RAM中,不过并未存满,因此伪代码中的状态
转移条件: if addra = 7f不满足,不会读tag01的数据;随后tag04的数据全部收到,此时addra=13fH;等tag01全部收完,满足伪代码转移条件,随后将tag01的数据读出;此时ram中tag00和tag01的数据已经读出,tag02还未收到,tag03和tag04待读出,addra(写ram地址)=80H,addrb(读ram地址)= 80H,后续如果tag02全部收齐并且读出,那么addra(写ram地址)=c0H,addrb(读ram地址)= c0H,此时应该要将ram中的tag03和tag04依次读出,我们看看读tag03的条件是: if addra = ff 读使能,状态转移到读tag3 很显然此时的addra不满足条件,并且由于tag03在早些时候已经全部收到,就是说addra已经等于过一次ff了,所以这个条件不会满足,因此读取失败。在这种情况下,由于我的状态机是按照读取tag的顺序来设计的,而如果后面的tag对应的数据先来的话,那么这种方法就会造成状态机卡住而不能读取数据。
对于情况一同样如此,但情况三却是可行的(可以自己验证)。但是如果加一个控制信号进去,那么对于所有的情况都将适用,下面直接贴代码:
if(!order_done)begin
if(addra_r == 14'h3f)
tag0_rd_en <= 1'b1;
else if(tag_state == tag1_tx)
tag0_rd_en <= 1'b0;
else
tag0_rd_en <= tag0_rd_en;
if(addra_r == 14'h7f)
tag1_rd_en <= 1'b1;
else if(tag_state == tag2_tx)
tag1_rd_en <= 1'b0;
else
tag1_rd_en <= tag1_rd_en;
if(addra_r == 14'hbf)
tag2_rd_en <= 1'b1;
else if(tag_state == tag3_tx)
tag2_rd_en <= 1'b0;
else
tag2_rd_en <= tag2_rd_en;
if(addra_r == 14'hff)
tag3_rd_en <= 1'b1;
else if(tag_state == tag4_tx)
tag3_rd_en <= 1'b0;
else
tag3_rd_en <= tag3_rd_en;
就是说,只要addra第一次出现某一tag的最后一个地址(说明该tag对应的数据全部接收),就将该tag的读使能置位,由于状态机中的状态转移完全是按照tag读取的顺序转移的,因此只有当某一tag对应的数据全部读取出,读使能为0,否则会一直为1.
将该信号加到伪代码中,如下:
空闲状态:
if addra = 3f 或 tag0_rd_en
使能ram读,状态转移到读tag0
else
空闲状态
读tag0:
if 读地址 <= 3f
读地址自加1,使能ram读,状态维持
else if addra = 7f 或者tag1_rd_en
读使能,状态转移到读tag1
else
读地址不变,读使能为0
读tag1:
if 读地址 <= 7f
读地址自加1,使能ram读,状态维持
else if addra = bf 或者 tag2_rd_en
读使能,状态转移到读tag2
else
读地址不变,读使能为0
读tag2:
if 读地址 <= bf
读地址自加1,使能ram读,状态维持
else if addra = ff 或者 tag3_rd_en
读使能,状态转移到读tag3
else
读地址不变,读使能为0
读tag3:
if 读地址 <= ff
读地址自加1,使能ram读,状态维持
else if addra = 13f 或者 tag4_rd_en
读使能,状态转移到读tag4
else
读地址不变,读使能为0
后面的以此类推...
如此便可以完成乱序重排。
另外,经过我很多次的实验发现,对于这种乱序情况理论上需要将256个tag全部用这样的代码写,实际上出现乱序的tag往往只有前面几个tag(每个人可能情况不同),所以我只对前面10个tag进行了重排。
中断问题解决办法:
中断的控制部分放在了TX_ENGINE里面,这个模块的作用是产生中断信号。

我们看一下它的例化信号:写完成输入信号、读完成输入信号、msi使能信号以及4个中断有关的信号。它的意思就是在存储器读写完成之后需要产生中断信号告诉上位机。在Xilinx官方文档中对中断有着详细的描述:
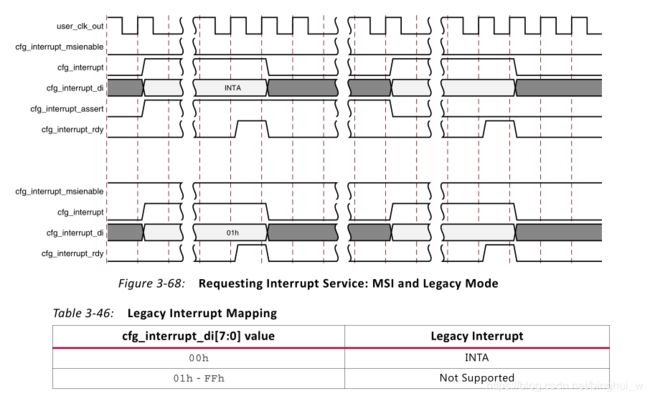
上图中第一部分是Legacy Interrupt,第二部分是MSI中断。Legacy中断中cfg_interrupt_msienable是一直为0的,cfg_interrupt_di值也是为0。在xapp1052中,cfg_interrupt_di信号并没有出现在中断文件中,它在顶层文件中就被赋值为0,可以说并没有用到这个信号。取而代之的是cfg_interrupt_legacyclr信号,奇怪的是,在Xilinx的官方文档中竟然没找到这个信号;但是从字面意思上理解它应该是清除Legacy中断用的信号,事实也确实如此。我们从这个信号出发,逆向寻找最终在BMD_EP_MEM.v文件中找到了该信号。
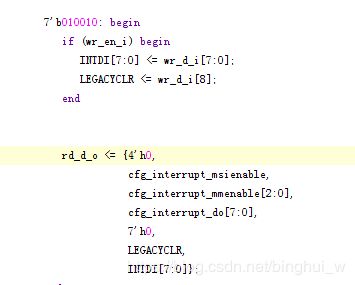
该信号位于偏移寄存器48-4BH中,所以应该是上位机通过给这个寄存器发送值来清除Legacy中断信号,通过查看WinDriver生成的驱动程序发现确实上位机在DMA完成之后没有向这个寄存器发送值。于是在上位机程序中加了这几句:
if (VIRTEX5_DMAInterruptCompletion(pDma->hDma, fIsRead))
{
VIRTEX5_WriteReg32(hDev, VIRTEX5_LEGACYCLR_OFFSET, 0x00000100);
printf("interrupt clear completion\n");
}
我们看一下在没加这几句程序之前,没勾选MSI选项的时候抓取的波形:

可以看到legacyclr一直为0,与此同时上位机程序则一直进入中断。
下面的是上位机加了程序之后的波形:

可以看到和官方的中断时序相对应。
其实如果在生成IP核的时候勾选 MSI选项,此时msi_enable选项则为1,抓取到的波形如下:
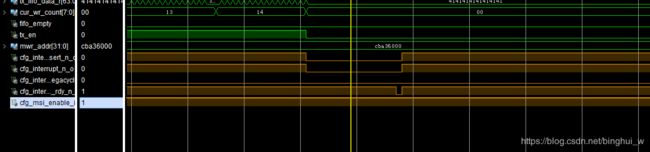
此时使用的是MSI中断,因此上位机并不会一直进入中断,程序不会出错。我一开始就勾选了MSI选项因此一直没有出错,只是看到网上的一些问题才仔细思考了一下这个问题,并做了一个浅显的说明。