Phoenix
一、phoenix
当我们按照之前的博文,安装完Hadoop分布式集群之后,再安装了Hbase,当准备通过hbase shell命令开始使用Hbase的时候,发现hbase非常的难用,都是一些scan,status,describe命令等,无法像mysql,oracle,hive等通过一些简单的SQL语句来操作数据,但是通过Phoenix,它可以让Hbase可以通过SQL语句来进行操作。并且Phoenix只针对Hbase,所以它的效率比起Impala,HQL有过之而无不及!
操作步骤
1. Phoenix介绍
可以把Phoenix理解为Hbase的查询引擎,phoenix,由saleforce.com开源的一个项目,后又捐给了Apache。它相当于一个Java中间件,帮助开发者,像使用jdbc访问关系型数据库一些,访问NoSql数据库HBase。
phoenix,操作的表及数据,存储在hbase上。phoenix只是需要和Hbase进行表关联起来。然后再用工具进行一些读或写操作。
其实,可以把Phoenix只看成一种代替HBase的语法的一个工具。虽然可以用java可以用jdbc来连接phoenix,然后操作HBase,但是在生产环境中,不可以用在OLTP中。在线事务处理的环境中,需要低延迟,而Phoenix在查询HBase时,虽然做了一些优化,但延迟还是不小。所以依然是用在OLAT中,再将结果返回存储下来。
2. Phoenix安装包下载
phoenix安装包下载地址,下载后上传到主节点的opt目录下!
注:phoenix安装包的下载非常讲究,如果和hbase的版本不匹配,那么可能导致hbase也会失败,导致HRegionServer开启后,1分钟之内自动关闭,很麻烦!上面的安装包针对hbase1.2.X,亲测好用!
phoenix的其他版本下载地址
3. phoenix安装包解压缩更换目录
# cd /opt
# tar -xzvf apache-phoenix-4.10.0-HBase-1.2-bin.tar.gz
# mv apache-phoenix-4.10.0-HBase-1.2-bin phoenix4.10.0
# chmod 777 -R /opt/phoenix4.10.0 #给phoenix目录授权
4. 修改配置文件
# vim /etc/profile
export PHOENIX_HOME=/opt/phoenix4.10.0 #在最后两行加上如下phoenix配置
export PATH=$PATH:$PHOENIX_HOME/bin
# source /etc/profile #使环境变量配置生效
5. 将主节点的phoenix包传到从节点
# scp -r phoenix4.10.0 root@hadoop1:/opt/
# scp -r phoenix4.10.0 root@hadoop2:/opt/
并且在从节点上将phoenix目录进行授权,添加环境变量!
6. 将hbase-site.xml配置文件拷贝到phoenix的bin目录下【主从节点都需要】
# cp /opt/hbase1.2.6/conf/hbase-site.xml /opt/phoenix4.10.0/bin/
7. 将phoenix安装包下的包放到hbase的lib目录下【主从节点都需要】
将如下两个jar包,目录在/opt/phoenix4.10.0/下,拷贝到hbase的lib目录,目录在/opt/hbase1.2.6/lib/
phoenix-4.10.0-HBase-1.2-server.jar
phoenix-core-4.10.0-HBase-1.2.jar
注:全部配置完后需要重启Hbase!
8. 启动phoenix
# sqlline.py hadoop0,hadoop1,hadoop2:2181
> !tables #测试命令
二、jdbc
既然hbase支持sql语句对数据进行操作,那么我们能不能通过代码连接Hbase,通过phoenix,在代码中书写sql语句,对phoenix进行操作呢?
#操作方案
1. 新建maven项目
为什么要建maven项目,因为引用的包实在太多了!
2. 代码
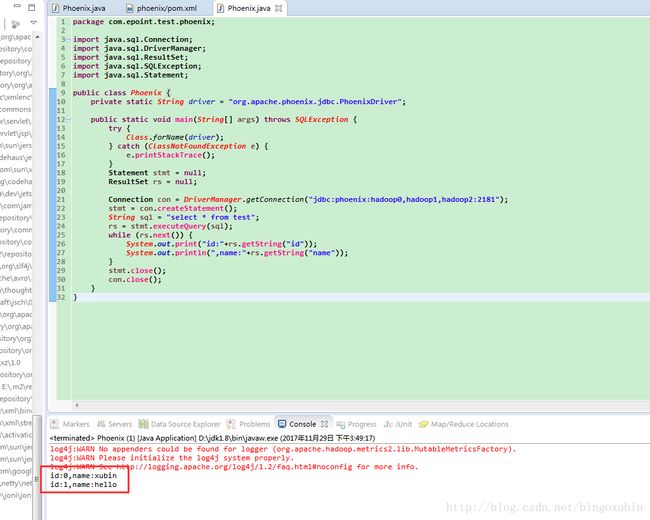
package com.epoint.test.phoenix;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class Phoenix {
private static String driver = "org.apache.phoenix.jdbc.PhoenixDriver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
Statement stmt = null;
ResultSet rs = null;
Connection con = DriverManager.getConnection("jdbc:phoenix:hadoop0,hadoop1,hadoop2:2181");
stmt = con.createStatement();
String sql = "select * from test";
rs = stmt.executeQuery(sql);
while (rs.next()) {
System.out.print("id:"+rs.getString("id"));
System.out.println(",name:"+rs.getString("name"));
}
stmt.close();
con.close();
}
}
3. pom中加入如下dependency
org.apache.phoenix
phoenix-core
4.10.0-HBase-1.2
maven下载的依赖包如下所示:

4. 运行代码,右击run as java application
三、sqlline.py
按照 完全分布式Hadoop集群安装Phoenix博文,安装了phoenix后,可以通过普通的SQL方式,操作HBASE,使hbase分布式非关系型数据库,更加易于用户的使用。
操作步骤
1. 启动phoenix
# sqlline.py hadoop0,hadoop1,hadoop2:2181
> !tables #启动完毕后,输入该命令进行测试
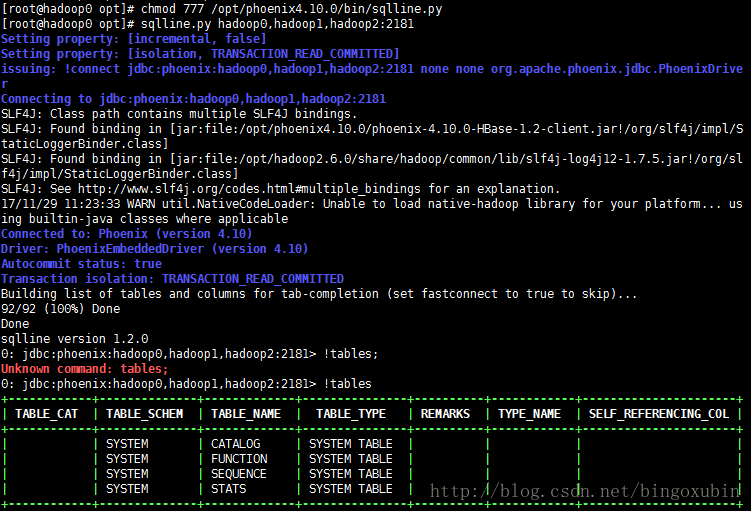
[root@hadoop0 opt]# sqlline.py hadoop0,hadoop1,hadoop2:2181
Setting property: [incremental, false]
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect jdbc:phoenix:hadoop0,hadoop1,hadoop2:2181 none none org.apache.phoenix.jdbc.PhoenixDriver
Connecting to jdbc:phoenix:hadoop0,hadoop1,hadoop2:2181
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/phoenix4.10.0/phoenix-4.10.0-HBase-1.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
17/11/29 13:37:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Connected to: Phoenix (version 4.10)
Driver: PhoenixEmbeddedDriver (version 4.10)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
92/92 (100%) Done
Done
sqlline version 1.2.0
0: jdbc:phoenix:hadoop0,hadoop1,hadoop2:2181> !tables
+------------+--------------+-------------+---------------+----------+------------+----------------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL |
+------------+--------------+-------------+---------------+----------+------------+----------------------+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | |
+------------+--------------+-------------+---------------+----------+------------+----------------------+
2. 创建表
> create table test(id integer not null primary key,name varchar);
0: jdbc:phoenix:hadoop0,hadoop1,hadoop2:2181> create table test(id integer not null primary key,name varchar);
No rows affected (1.338 seconds)
3. 插入数据
> upsert into test values(0,'xubin');
0: jdbc:phoenix:hadoop0,hadoop1,hadoop2:2181> upsert into test values(0,'xubin');
1 row affected (0.012 seconds)
4. 查询数据
> select * from test;
0: jdbc:phoenix:hadoop0,hadoop1,hadoop2:2181> select * from test;
+-----+--------+
| ID | NAME |
+-----+--------+
| 0 | xubin |
| 1 | hello |
+-----+--------+
2 rows selected (0.03 seconds)
5. 退出phoenix
> !q
0: jdbc:phoenix:hadoop0,hadoop1,hadoop2:2181> !q
Closing: org.apache.phoenix.jdbc.PhoenixConnection