promethus与监控系统
这就是prometheus

随着容器技术的迅速发展,Kubernetes已然成为大家追捧的容器集群管理系统。Prometheus 作为生态圈 Cloud Native Computing Foundation(简称:CNCF)中的重要一员,其活跃度仅次于 Kubernetes, 现已广泛用于 Kubernetes 集群的监控系统中。
本文带领大家体验如何使用Prometheus开始收集系统指标,以便开发人员和云平台运维人员可以快速的掌握 Prometheus。
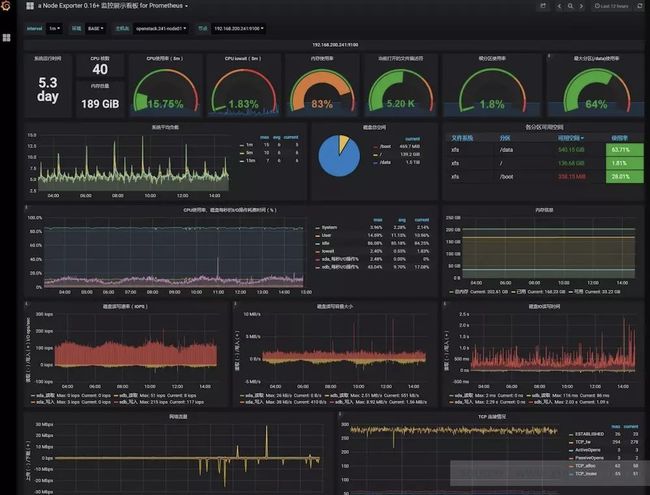
上图是Grafana看板的监控展示情况,让我们开始吧!
Prometheus 组成及架构
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的,这里仅阐述核心组件:
Prometheus Server: Prometheus服务端,由于存储及收集时间序列数据,提供相关api对外查询用。
Exporter: 类似传统意义上的被监控端的agent,用于暴露已有的第三方服务的指标(metrics) 。其中的区别是,它不会主动推送监控数据到server端,而是被动等待server端定时来收集数据,即所谓的主动监控。
Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
Push Gateway: 用于网络不可直达或者生命周期比较短的数据采集job,居于exporter与server端的中转站,将多个节点数据汇总到Push Gateway,再统一推送到server。
Alertmanager: 是单独抽离的告警组件。从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
Web UI: Prometheus的web接口,可用于简单可视化,及语句执行或者服务状态监控。
知道了以上的组件,理解起官网的Prometheus架构图,就非常的简单了,架构图见下方:
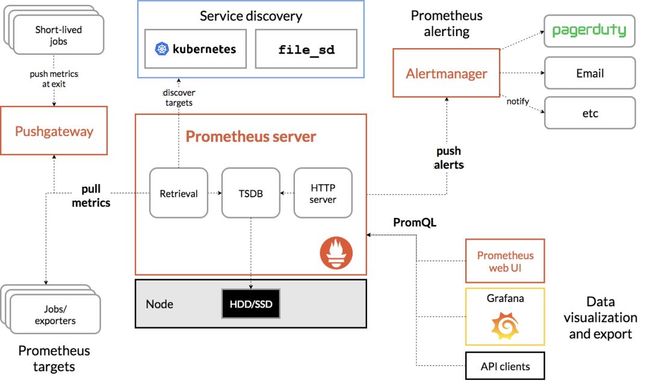
从上图可以看出,Prometheus 的主要模块包括:Prometheus server、Pushgateway、exporters、PromQL、 Alertmanager 、Service discovery以及图形界面。
其工作流程大体描述如下:
Prometheus server 定期从配置好的 jobs 或者 exporters 中拉指标(metrics),或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
Prometheus server 在本地存储收集到的 metrics;并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送告警信息。
Alertmanager 根据配置文件,对接收到的告警进行处理,使用多种方式发出告警提醒。
PromQL是Prometheus 自己开发的数据查询 DSL 语言,在图形界面中,可视化用此方法展示采集到的数据。
Service discovery(服务发现),Prometheus支持多种服务发现机制:文件、DNS、Consul、Kubernetes、OpenStack、EC2等等。基于服务发现的过程并不复杂,通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮训这些Target获取监控数据。
光说不练假把式,我们来简单的体验一下prometheus
第1步 - 配置Prometheus
Prometheus服务器需要一个配置文件,该文件定义要扫描的端点以及访问度量的频率。
$ ls
prometheus.yml
$ pwd
/Users/pzqu/Documents/code/docker/prometheus
配置的前半部分定义了间隔。
下半部分定义了Prometheus应该从中获取数据的服务器和端口。在此示例中,我们定义了在不同端口上运行的两个目标。
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['127.0.0.1:9090', '172.17.0.1:9100']
labels:
group: 'prometheus'
9090端口是普罗米修斯本身。Prometheus公开内部指标以及性能相关的信息,而且还可以自我监控。
9100端口是Node Exporter Prometheus(agent)进程。这会公开有关节点的信息,例如磁盘空间,内存和CPU使用情况。
有关默认端口的更多信息,请访问https://github.com/prometheus/prometheus/wiki/Default-port-allocations
第2步 - 启动Prometheus服务端
Prometheus可以作为Docker容器运行,并在端口9090提供访问页面。
Prometheus使用配置来抓取目标,收集和存储指标,然后通过允许仪表板,图形和警报的API提供这些指标。
以下命令使用prometheus配置启动容器。由prometheus创建的任何数据都将存储在主机上的目录/ prometheus / data中。当我们更新容器时,数据将被保留。
$ docker run -d --net=host \
-v /Users/pzqu/Documents/code/docker/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
--name prometheus-server \
prom/prometheus
0e8a6f9ec7ae41b79db3ab3638968f82f721752b83f4e90a2a12eea975e0377c
--net=host代表直接打通容器网络与本地网络,容器可以直接配置host网络,可以看到host的所有网卡,但是mac机器上有限制,没办法直接映射端口绑定到本地。
启动后,仪表板可在端口9090上查看。接下来的步骤将解释详细信息以及如何查看数据。
第3步 - 启动agent
node_exporter是可以在*Nix和Linux系统上运行的计算机度量标准的导出器,也就是agent。
启动Node Exporter容器。通过挂载本地主机的 /proc和/sys等目录,容器可以访问到必要的信息以监控部署的主机。
$ docker run -d --net=host \
-v "/proc:/host/proc:ro" \
-v "/sys:/host/sys:ro" \
-v "/:/rootfs:ro,rslave" \
--name=prometheus \
quay.io/prometheus/node-exporter:v0.13.0 \
-collector.procfs /host/proc \
-collector.sysfs /host/sys \
-collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
2b2b276c588f6e593b387dd52b4d64a8e19b72bd466ee10dda8985ddb09c3cf7
运行结束以后会绑定本地9100端口,服务端又正好从主机的9100拉数据,这样网络就打通了。
这里需要注意的是,ro只读选项和rslave的传播挂载,不然在卸载设备的时候会被docker容器锁住,导致主机无法卸载和挂载设备。
这里可能会不生效,需要修改/usr/lib/systemd/system/docker.service的MountFlags=shared
第4步 - 查看指标
如果是二进制或者docker部署,部署成功后可以访问:http://127.0.0.1:9100/metrics
会输出下面格式的内容,包含了node-exporter暴露的所有指标:
curl localhost:9100/metrics
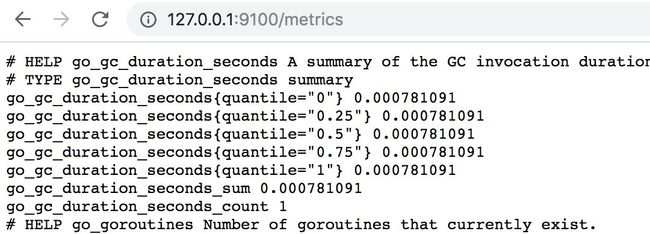
随着容器的推出,Prometheus将根据配置中的内部结构来抓取和存储数据。
Dashboard 大屏展示
默认的Prometheus Dashboard自带展示内部指标的页面,并提供调试收集的指标的方法。
仪表板将通过/targets页面报告抓取状态和不同目标。
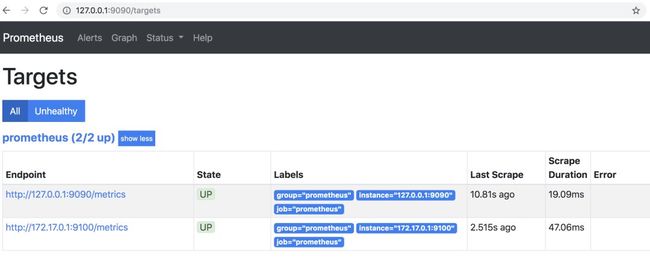
因为我的是mac环境,没办法用--net=host模式绑定网卡,所以直接配置了访问内网ip 172.17.0.1:9090,一样的效果。
查询普罗米修斯
要查询基础指标并创建图表,请访问控制面板上的图表页面:http://127.0.0.1:9090/graph
从这里可以根据名称查询不同的指标。
例如,查询node_network_receive_bytes将显示磁盘IO的活动程度。查询使用node_cpu将输出Docker主机CPU信息。

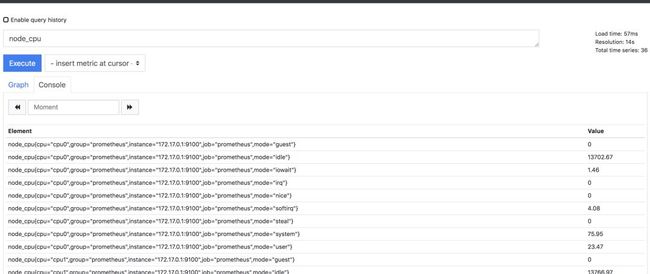
常用指标类型有:
node_cpu:系统CPU使用量
node_disk*:磁盘IO
node_filesystem*:文件系统用量
node_load1:系统负载
node_memeory*:内存使用量
node_network*:网络带宽
node_time:当前系统时间
go_*:node exporter中go相关指标
process_*:node exporter自身进程相关运行指标
Prometheus虽然自带了web页面,但一般会和更专业的Grafana配套做指标的可视化。
Grafana有很多模板,用于更友好地展示出指标的趋势情况,如Node Exporter for Prometheus,文章的开头那张图片就是这个模板的展示情况样例。
启动grafana
docker run -d --name=grafana -p 3000:3000 grafana/grafana
3bf6f5d7794f9694dc59fc598c91e6e4dbb315088eb012a03629d6d181e2e818
输入默认用户名和密码 admin/admin ,进入到首页

首页长这个样子,都是比较简单的英文,按步骤来就可以了。
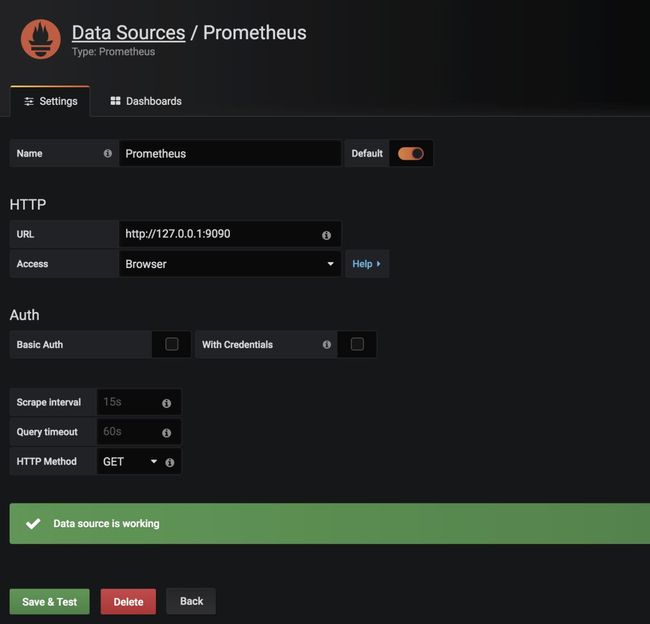
Add Data Sources ->
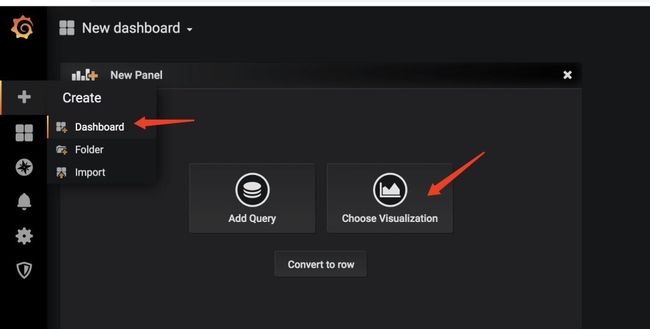
选择图表展示
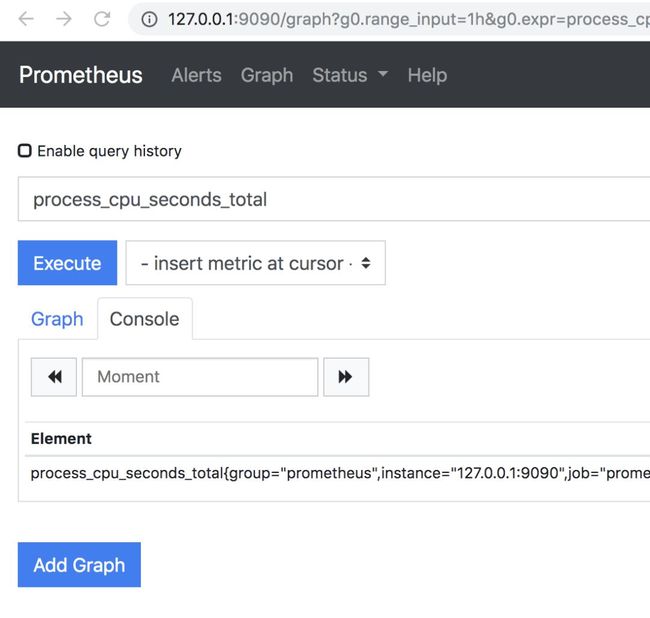
在promethus server上添加指标
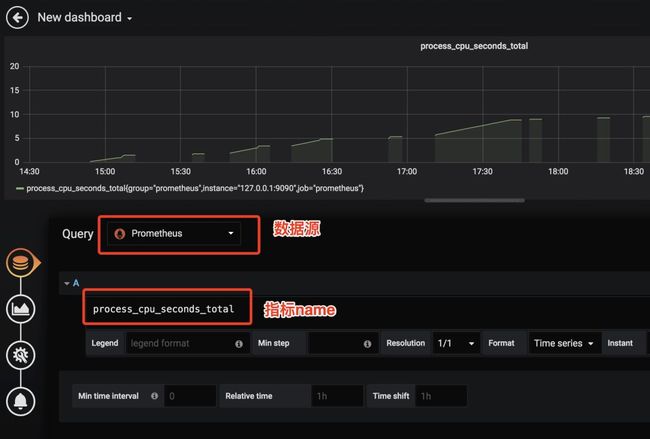
选择数据源和指标,右上角保存,重复操作就可以有下图效果了,注意使用docker run -d --net=host方式会比较方便
参考
官方文档 https://prometheus.io/docs/introduction/overview/
容器监控实践—node-exporter
https://www.jianshu.com/p/e3c9fc929d8a
如何在CentOS 7上安装Prometheus和node_exporter
https://www.howtoing.com/how-to-install-prometheus-and-node-exporter-on-centos-7使用Prometheus收集Docker指标
https://docs.docker.com/config/thirdparty/prometheus/
Prometheus 入门与实践
https://www.ibm.com/developerworks/cn/cloud/library/cl-lo-prometheus-getting-started-and-practice/
推荐阅读
(点击标题可跳转阅读)
回复 m 获取全部文章目录
如果有帮助别忘了分享给朋友哦~