吴恩达机器学习作业(五):支持向量机
目录
1)数据预处理
2)Scikit-learn支持向量机
3)决策边界比较
4)非线性SVM
5)最优超参数
6)垃圾邮件过滤器
在本练习中,我们将使用支持向量机(SVM)来构建垃圾邮件分类器。 我们将从一些简单的2D数据集开始使用SVM来查看它们的工作原理。 然后,我们将对一组原始电子邮件进行一些预处理工作,并使用SVM在处理的电子邮件上构建分类器,以确定它们是否为垃圾邮件。
我们要做的第一件事是看一个简单的二维数据集,看看线性SVM如何对数据集进行不同的C值(类似于线性/逻辑回归中的正则化项)。
1)数据预处理
同样的我们还是先看看我们的数据长什么样子:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from scipy.io import loadmat
raw_data = loadmat('ex6data1.mat')
raw_data我们将其用散点图表示,其中类标签由符号表示(+表示正类,o表示负类)。
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y']
positive = data[data['y'].isin([1])]
negative = data[data['y'].isin([0])]
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive['X1'], positive['X2'], s=50, marker='x', label='Positive')
ax.scatter(negative['X1'], negative['X2'], s=50, marker='o', label='Negative')
ax.legend()
plt.show()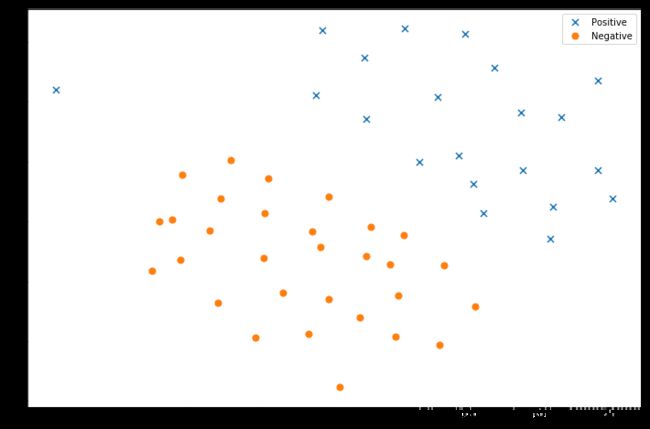
2)Scikit-learn支持向量机
from sklearn import svm
svc = svm.LinearSVC(C=1, loss='hinge', max_iter=1000)
svc首先,我们使用 C=1 看下结果如何。
svc.fit(data[['X1', 'X2']], data['y'])
svc.score(data[['X1', 'X2']], data['y'])
0.9803921568627451其次,让我们看看如果C的值越大,会发生什么。
svc2 = svm.LinearSVC(C=100, loss='hinge', max_iter=1000)
svc2.fit(data[['X1', 'X2']], data['y'])
svc2.score(data[['X1', 'X2']], data['y'])
1.03)决策边界比较
这次我们得到了训练数据的完美分类,但是通过增加C的值,我们创建了一个不再适合数据的决策边界。 我们可以通过查看每个类别预测的置信水平来看出这一点,这是该点与超平面距离的函数。
data['SVM 1 Confidence'] = svc.decision_function(data[['X1', 'X2']])
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(data['X1'], data['X2'], s=50, c=data['SVM 1 Confidence'], cmap='seismic')
ax.set_title('SVM (C=1) Decision Confidence')
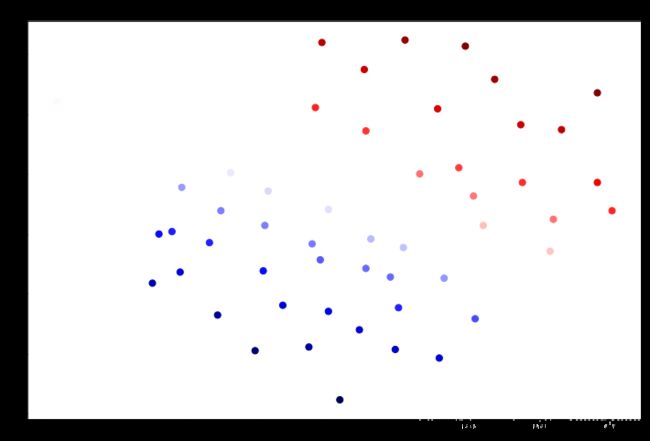
plt.show()data['SVM 2 Confidence'] = svc2.decision_function(data[['X1', 'X2']])
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(data['X1'], data['X2'], s=50, c=data['SVM 2 Confidence'], cmap='seismic')
ax.set_title('SVM (C=100) Decision Confidence')
plt.show()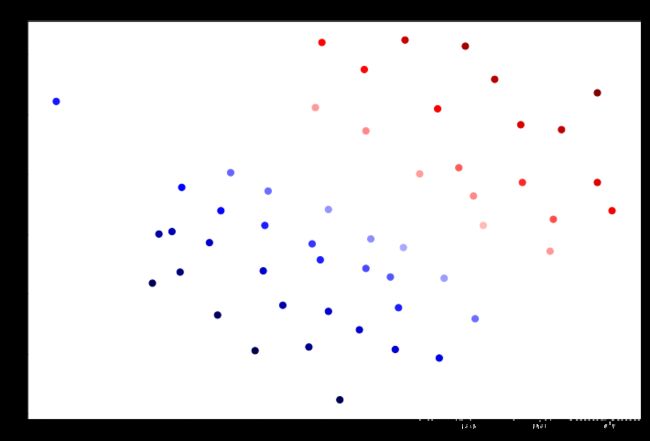
4)非线性SVM
现在我们将从线性SVM转移到能够使用内核进行非线性分类的SVM。 我们首先负责实现一个高斯核函数。 虽然scikit-learn具有内置的高斯内核,但为了实现更清楚,我们将从头开始实现。
def gaussian_kernel(x1, x2, sigma):
return np.exp(-(np.sum((x1 - x2) ** 2) / (2 * (sigma ** 2))))接下来,我们将检查另一个数据集,这次用非线性决策边界。
raw_data = loadmat('ex6data2.mat')
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y']
positive = data[data['y'].isin([1])]
negative = data[data['y'].isin([0])]
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive['X1'], positive['X2'], s=30, marker='x', label='Positive')
ax.scatter(negative['X1'], negative['X2'], s=30, marker='o', label='Negative')
ax.legend()
plt.show()
为了可视化决策边界,这一次我们将根据实例具有负类标签的预测概率来对点做阴影。 从结果可以看出,它们大部分是正确的。
svc = svm.SVC(C=100, gamma=10, probability=True)
svc
data['Probability'] = svc.predict_proba(data[['X1', 'X2']])[:,0]
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(data['X1'], data['X2'], s=30, c=data['Probability'], cmap='Reds')
plt.show()
5)最优超参数
对于第三个数据集,我们给出了训练和验证集,并且任务是基于验证集表现为SVM模型找到最优超参数。 虽然我们可以使用scikit-learn的内置网格搜索来做到这一点,但是本着遵循练习的目的,我们将从头开始实现一个简单的网格搜索。
raw_data = loadmat('ex6data3.mat')
X = raw_data['X']
Xval = raw_data['Xval']
y = raw_data['y'].ravel()
yval = raw_data['yval'].ravel()
C_values = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
gamma_values = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
best_score = 0
best_params = {'C': None, 'gamma': None}
for C in C_values:
for gamma in gamma_values:
svc = svm.SVC(C=C, gamma=gamma)
svc.fit(X, y)
score = svc.score(Xval, yval)
if score > best_score:
best_score = score
best_params['C'] = C
best_params['gamma'] = gamma
best_score, best_params
(0.965, {'C': 0.3, 'gamma': 100})6)垃圾邮件过滤器
在这一部分中,我们的目标是使用SVM来构建垃圾邮件过滤器。 在练习文本中,有一个任务涉及一些文本预处理,以获得适合SVM处理的格式的数据。 然而,这个任务很简单(将字词映射到为练习提供的字典中的ID),而其余的预处理步骤(如HTML删除,词干,标准化等)已经完成。
spam_train = loadmat('spamTrain.mat')
spam_test = loadmat('spamTest.mat')
spam_train
X = spam_train['X']
Xtest = spam_test['Xtest']
y = spam_train['y'].ravel()
ytest = spam_test['ytest'].ravel()
X.shape, y.shape, Xtest.shape, ytest.shape每个文档已经转换为一个向量,其中1,899个维对应于词汇表中的1,899个单词。 它们的值为二进制,表示文档中是否存在单词。 在这一点上,训练评估是用一个分类器拟合测试数据的问题。
svc = svm.SVC()
svc.fit(X, y)
print('Training accuracy = {0}%'.format(np.round(svc.score(X, y) * 100, 2)))
Training accuracy = 94.4%print('Test accuracy = {0}%'.format(np.round(svc.score(Xtest, ytest) * 100, 2)))
Test accuracy = 95.3%