Cifar10数据集
- 提供 5万张 32*32 像素点的十分类彩色图片和标签,用于训练。
- 提供 1万张 32*32 像素点的十分类彩色图片和标签,用于测试。
- 导入cifar10数据集:
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train),(x_test, y_test) = cifar10.load_data()
- 可视化训练集输入特征的第一个元素
plt.imshow(x_train[0]) #绘制图片
plt.show()

- 打印出训练集输入特征的第一个元素
print("x_train[0]:\n", x_train[0])

- 打印出训练集标签的第一个元素
print("y_train[0]:\n", y_train[0])

- 打印出整个训练集输入特征形状
print("x_train.shape:\n", x_train.shape)

- 打印出整个训练集标签的形状
print("y_train.shape:\n", y_train.shape)

- 打印出整个测试集输入特征的形状
print("x_test.shape:\n", x_test.shape)

- 打印出整个测试集标签的形状
print("y_test.shape:\n", y_test.shape)

搭建网络
利用cifar10数据集搭建一个网络,训练模型
- 网络设计:
卷积层:6个5x5,步长为1,使用全零填充的卷积核;2个2x2,步长为2,使用全零填充的最大值池化核;20%的神经元休眠(暂时舍弃)。
全连接层:先将卷积训练的数据拉直;送入128个神经元,激活函数为“relu”,20%休眠的全连接;再将数据送入10个神经元,符合概率分布的全连接。

- 源码
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class Baseline(Model):
def __init__(self):
super(Baseline, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5), padding='same') # 卷积层
self.b1 = BatchNormalization() # BN层
self.a1 = Activation('relu') # 激活层
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same') # 池化层
self.d1 = Dropout(0.2) # dropout层
self.flatten = Flatten()
self.f1 = Dense(128, activation='relu')
self.d2 = Dropout(0.2)
self.f2 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.d1(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d2(x)
y = self.f2(x)
return y
model = Baseline()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/Baseline.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
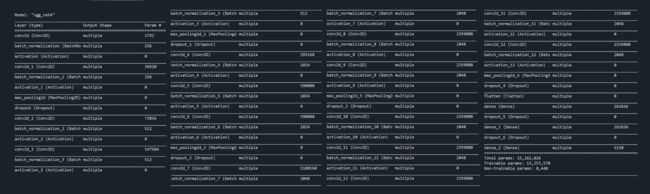
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
- 运行结果


LeNet

是由Yann LeCun于1998年提出,是卷积网络的开篇之作

网络结构
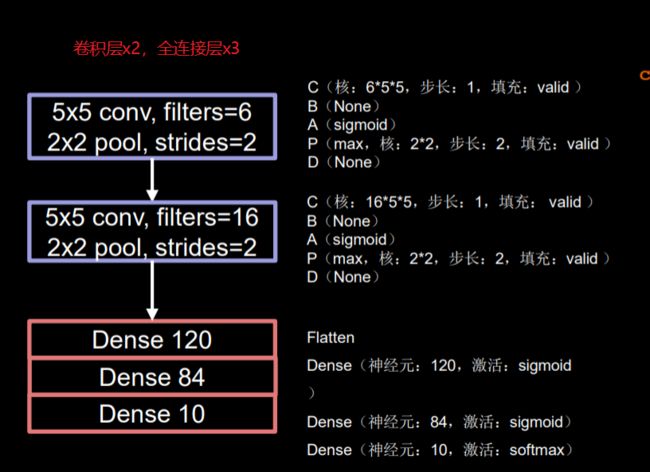
- 网络搭建
class LeNet5(Model):
def __init__(self):
super(LeNet5, self).__init__()
self.c1=Conv2D(fliters=6, kernel_size=(5, 5), activation='sigmoid')
self.p1=MaxPool2D(pool_size=(2, 2), strides=2)
self.c2=Conv2D(filters=16, kernel_size=(5, 5), activation='sigmoid')
self.p2=MaxPool2D(pool_size=(2, 2), strides=2)
self.flatten=Flatten()
self.d1=Dense(128, activation='sigmoid')
self.d2=Dense(84, activation='sigmoid')
self.d3=Dense(10, activation='softmax')
def call(self, x):
x=self.c1(x)
x=self.p1(x)
x=self.c2(x)
x=self.p2(x)
x=self.flatten(x)
x=self.d1(x)
x=self.d2(x)
y=self.d3(x)
return y
示例:
import tensorflow as tf
from matplotlib import pyplot as plt
import os
import numpy as np
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train/255.0, x_test/255.0
class LeNet5(Model):
def __init__(self):
super(LeNet5, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5), activation='sigmoid')
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2)
self.c2 = Conv2D(filters=16, kernel_size=(5, 5), activation='sigmoid')
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2)
self.flatten = Flatten()
self.d1 = Dense(128, activation='sigmoid')
self.d2 = Dense(84, activation='sigmoid')
self.d3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.p1(x)
x = self.c2(x)
x = self.p2(x)
x = self.flatten(x)
x = self.d1(x)
x = self.d2(x)
y = self.d3(x)
return y
model = LeNet5()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/LeNet5.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath = checkpoint_save_path,
save_weights_only = True,
save_best_only = True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
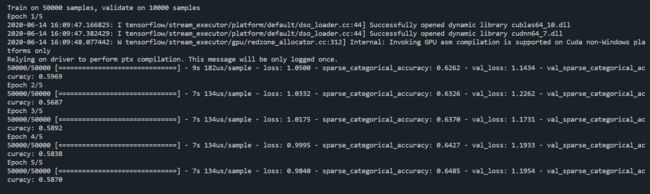
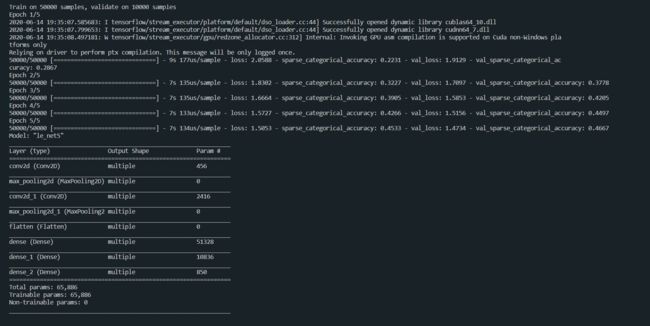
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和测试集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Valiation Loss')
plt.title('Train and Validation Loss')
plt.legend()
plt.show()
运行结果

AlexNet
AlexNet网络诞生于2012年,当年ImageNet竞赛的冠军,Top5错误率为16.4%
使用“relu”激活函数,提升了训练速度,使用Dropout缓解过拟合

网络结构

网络搭建示例
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class AlexNet8(Model):
def __init__(self):
super(AlexNet8, self).__init__()
self.c1 = Conv2D(filters=96, kernel_size=(3, 3))
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
self.flatten = Flatten()
self.f1 = Dense(2048, activation='relu')
self.d1 = Dropout(0.5)
self.f2 = Dense(2048, activation='relu')
self.d2 = Dropout(0.5)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p2(x)
x = self.c3(x)
x = self.c4(x)
x = self.c5(x)
x = self.p3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d1(x)
x = self.f2(x)
x = self.d2(x)
y = self.f3(x)
return y
model = AlexNet8()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/AlexNet8.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
运行结果



VGGNet
VGGNet诞生于2014年,当年ImageNet竞赛的亚军,Top5错误率减小到7.3%
使用小尺寸卷积核,在减少参数的同时提高了识别的准确率,网络规整适合硬件加速

网络结构

网络搭建示例
import tensorflow as tf
import numpy as np
import os
from tensorflow.keras.layers import Flatten, Conv2D, Dense, Activation, MaxPool2D, Dropout, BatchNormalization
from tensorflow.keras import Model
from matplotlib import pyplot as plt
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class VGGNet4(Model):
def __init__(self):
super(VGGNet4, self).__init__()
self.c1 = Conv2D(filters=64, kernel_size=(3, 3), padding='same')
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.c2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same')
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2)
self.d1 = Dropout(0.2)
self.c3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b3 = BatchNormalization()
self.a3 = Activation('relu')
self.c4 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b4 = BatchNormalization()
self.a4 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2)
self.d2 = Dropout(0.2)
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b5 = BatchNormalization()
self.a5 = Activation('relu')
self.c6 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b6 = BatchNormalization()
self.a6 = Activation('relu')
self.c7 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b7 = BatchNormalization()
self.a7 = Activation('relu')
self.p3 = MaxPool2D(pool_size=(2, 2), strides=2)
self.d3 = Dropout(0.2)
self.c8 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b8 = BatchNormalization()
self.a8 = Activation('relu')
self.c9 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b9 = BatchNormalization()
self.a9 = Activation('relu')
self.c10 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b10 = BatchNormalization()
self.a10 = Activation('relu')
self.p4 = MaxPool2D(pool_size=(2, 2), strides=2)
self.d4 = Dropout(0.2)
self.c11 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b11 = BatchNormalization()
self.a11 = Activation('relu')
self.c12 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b12 = BatchNormalization()
self.a12 = Activation('relu')
self.c13 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b13 = BatchNormalization()
self.a13 = Activation('relu')
self.p5 = MaxPool2D(pool_size=(2, 2), strides=2)
self.d5 = Dropout(0.2)
self.flatten = Flatten()
self.f1 = Dense(512, activation='relu')
self.d6 = Dropout(0.2)
self.f2 = Dense(512, activation='relu')
self.d7 = Dropout(0.2)
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.p1(x)
x = self.d1(x)
x = self.c3(x)
x = self.b3(x)
x = self.a3(x)
x = self.c4(x)
x = self.b4(x)
x = self.a4(x)
x = self.p2(x)
x = self.d2(x)
x = self.c5(x)
x = self.b5(x)
x = self.a5(x)
x = self.c6(x)
x = self.b6(x)
x = self.a6(x)
x = self.c7(x)
x = self.b7(x)
x = self.a7(x)
x = self.p3(x)
x = self.d3(x)
x = self.c8(x)
x = self.b8(x)
x = self.a8(x)
x = self.c9(x)
x = self.b9(x)
x = self.a9(x)
x = self.c10(x)
x = self.b10(x)
x = self.a10(x)
x = self.p4(x)
x = self.d4(x)
x = self.c11(x)
x = self.b11(x)
x = self.a11(x)
x = self.c12(x)
x = self.b12(x)
x = self.a12(x)
x = self.c13(x)
x = self.b13(x)
x = self.a13(x)
x = self.p5(x)
x = self.d5(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d6(x)
x = self.f2(x)
x = self.d7(x)
y = self.f3(x)
return y
model = VGGNet4()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = './checkpoint/AGGNet4.ckpt'
if os.path.exists(checkpoint_save_path + '.index'):
print('--------------- load the model -----------------')
model.load_weights(checkpoint_save_path)
cp_callabck = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=128, epochs=5, validation_data=(x_test, y_test),
validation_freq=1, callbacks=[cp_callabck])
model.summary()
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
- 运行结果