kubernetes 部署附带解决(open /etc/docker/certs.d/registry.access.redhat.com/redhat-ca.crt: no such file)
kubernetes 官方提供的三种部署方式
-
minikube
Minikube是一个工具,可以在本地快速运行一个单点的Kubernetes,仅用于尝试Kubernetes或日常开发的用户使用。部署地址:https://kubernetes.io/docs/setup/minikube/
-
kubeadm
Kubeadm也是一个工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。部署地址:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
-
二进制包
推荐,从官方下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。下载地址:https://github.com/kubernetes/kubernetes/releases
环境准备工作
| 主机名 | 操作系统 | IP地址 |
| master | Centos 7.5-x86_64 | 10.10.1.151 |
| node1 | Centos 7.5-x86_64 | 10.10.1.152 |
| node2 | Centos 7.5-x86_64 | 10.10.1.153 |
配置Host(master、node1、node2)
hostnamectl set-hostname k8s-master (master节点)
hostnamectl set-hostname node1 (node1节点)
hostnamectl set-hostname node2 (node2节点)
# cat < /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.10.1.151 k8s-master
10.10.1.152 k8s-node1
10.10.1.153 k8s-node2
EOF [root@k8s-master yum.repos.d]#cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
EOF
[root@k8s-master yum.repos.d]#wget https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
[root@k8s-master yum.repos.d]#rpm -import rpm-package-key.gpg #安装key文件
如禁用防火墙:
systemctl stop firewalld && systemctl disable firewalld创建/etc/sysctl.d/k8s.conf文件,添加如下内容:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1执行命令使修改生效。
# modprobe br_netfilter
# sysctl -p /etc/sysctl.d/k8s.conf
关闭swap
关闭Swap,机器重启后不生效
# swapoff -a
# cp -p /etc/fstab /etc/fstab.bak$(date '+%Y%m%d%H%M%S')
# sed -i "s/\/dev\/mapper\/centos-swap/\#\/dev\/mapper\/centos-swap/g" /etc/fstab
# systemctl daemon-reload
# systemctl restart kubelet禁用SELINUX:
setenforce 0 && sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config| 主机名 | 操作系统 | IP地址 |
| master | etcd kube-apiserver kube-controller-manager kube-scheduler |
10.10.1.151 |
| node1 | kubelet etcd kube-proxy docker |
10.10.1.152 |
| node2 | kubelet etcd kube-proxy docker |
10.10.1.153 |
安装前准备
在安装部署集群前,先将三台服务器的时间通过NTP进行同步,否则,在后面的运行中可能会提示错误
master节点
# yum install ntp -y
# vim /etc/ntpd.conf# Permit all access over the loopback interface. This could
# be tightened as well, but to do so would effect some of
# the administrative functions.
restrict 127.0.0.1
restrict ::1
# Hosts on local network are less restricted.
restrict 10.9.1.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server 127.127.1.0
fudge 127.127.1.0 stratum 10
nodes节点
# yum install ntp -y
# vim /etc/ntpd.conf# Permit all access over the loopback interface. This could
# be tightened as well, but to do so would effect some of
# the administrative functions.
restrict 127.0.0.1
restrict ::1
# Hosts on local network are less restricted.
#1新增权限配置
restrict 10.9.1.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#2注释掉原来的服务器地址
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#3新增自己服务器的地址
server 10.9.1.151
[root@k8s-node2 ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
10.9.1.151 LOCAL(0) 11 u 27 64 1 0.198 -1.249 0.000
[root@k8s-node2 ~]# ntpdate 10.9.1.151
14 Nov 01:15:51 ntpdate[10192]: the NTP socket is in use, exiting
在所有node节点上安装redhat-ca.crt
[root@k8s-node1 ~]# yum install *rhsm* -ymaster节点配置
1.安装kubernetes etcd
[root@k8s-master ~]# yum -y install kubernetes-master etcd
[root@k8s-master ~]# vim /etc/etcd/etcd.conf
#[Member]
#ETCD_CORS=""
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
#ETCD_WAL_DIR=""
ETCD_LISTEN_PEER_URLS="http://10.9.1.151:2380"
ETCD_LISTEN_CLIENT_URLS="http://10.9.1.151:2379,http://127.0.0.1:2379"
#本机ip 如果不写http://127.0.0.1:2379 这个etcdctl cluster-health命令报错
ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
ETCD_NAME="etcd1"
#ETCD_SNAPSHOT_COUNT="100000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
#ETCD_QUOTA_BACKEND_BYTES="0"
#ETCD_MAX_REQUEST_BYTES="1572864"
#ETCD_GRPC_KEEPALIVE_MIN_TIME="5s"
#ETCD_GRPC_KEEPALIVE_INTERVAL="2h0m0s"
#ETCD_GRPC_KEEPALIVE_TIMEOUT="20s"
#
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.9.1.151:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.9.1.151:2379"
#ETCD_DISCOVERY=""
#ETCD_DISCOVERY_FALLBACK="proxy"
#ETCD_DISCOVERY_PROXY=""
#ETCD_DISCOVERY_SRV=""
#ETCD_INITIAL_CLUSTER="default=http://localhost:2380"
ETCD_INITIAL_CLUSTER="etcd1=http://10.9.1.151:2380,etcd2=http://10.9.1.152:2380,etcd3=http://10.9.1.153:2380"
#ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
#ETCD_INITIAL_CLUSTER_STATE="new"
#ETCD_STRICT_RECONFIG_CHECK="true"
#ETCD_ENABLE_V2="true"
nodes节点配置
1.安装部署kubernetes-node/etcd/flannel/docker
[root@k8s-node1 ~]# yum -y install kubernetes-node etcd flannel docker2.分别配置etcd,node1与node2的配置方法相同,以node1配置文件为例说明
[root@k8s-node1 ~]# vim /etc/etcd/etcd.con
#[Member]
#ETCD_CORS=""
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
#ETCD_WAL_DIR=""
##本机ip 如果不写http://127.0.0.1:2379 这个etcdctl cluster-health命令
ETCD_LISTEN_PEER_URLS="http://10.9.1.153:2380"
ETCD_LISTEN_CLIENT_URLS="http://10.9.1.153:2379,http://127.0.0.1:2379"
#ETCD_MAX_SNAPSHOTS="5"
#ETCD_MAX_WALS="5"
ETCD_NAME="etcd3"
#ETCD_SNAPSHOT_COUNT="100000"
#ETCD_HEARTBEAT_INTERVAL="100"
#ETCD_ELECTION_TIMEOUT="1000"
#ETCD_QUOTA_BACKEND_BYTES="0"
#ETCD_MAX_REQUEST_BYTES="1572864"
#ETCD_GRPC_KEEPALIVE_MIN_TIME="5s"
#ETCD_GRPC_KEEPALIVE_INTERVAL="2h0m0s"
#ETCD_GRPC_KEEPALIVE_TIMEOUT="20s"
#
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.9.1.153:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.9.1.153:2379"
#ETCD_DISCOVERY=""
#ETCD_DISCOVERY_FALLBACK="proxy"
#ETCD_DISCOVERY_PROXY=""
#ETCD_DISCOVERY_SRV=""
ETCD_INITIAL_CLUSTER="etcd1=http://10.9.1.151:2380,etcd2=http://10.9.1.152:2380,etcd3=http://10.9.1.153:2380"
#ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
#ETCD_INITIAL_CLUSTER_STATE="new"
#ETCD_STRICT_RECONFIG_CHECK="true"
#ETCD_ENABLE_V2="true"启动etcd cluster
分别在3台服务器启动etcd
[root@k8s-master ~]# systemctl start etcd.service
[root@k8s-master ~]# systemctl status etcd.service
● etcd.service - Etcd Server
Loaded: loaded (/usr/lib/systemd/system/etcd.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2019-11-13 03:37:38 EST; 22h ago
Main PID: 8832 (etcd)
CGroup: /system.slice/etcd.service
└─8832 /usr/bin/etcd --name=default --data-dir=/var/lib/etcd/default.etcd --listen-client-urls=h...
Nov 13 03:37:38 k8s-master etcd[8832]: 8e9e05c52164694d received MsgVoteResp from 8e9e05c52164694d at term 2
Nov 13 03:37:38 k8s-master etcd[8832]: 8e9e05c52164694d became leader at term 2
Nov 13 03:37:38 k8s-master etcd[8832]: raft.node: 8e9e05c52164694d elected leader 8e9e05c52164694d at term 2
Nov 13 03:37:38 k8s-master etcd[8832]: setting up the initial cluster version to 3.3
Nov 13 03:37:38 k8s-master etcd[8832]: published {Name:default ClientURLs:[http://0.0.0.0:2379]} to cl...a8c32
Nov 13 03:37:38 k8s-master etcd[8832]: ready to serve client requests
Nov 13 03:37:38 k8s-master etcd[8832]: serving insecure client requests on [::]:2379, this is strongly...aged!
Nov 13 03:37:38 k8s-master systemd[1]: Started Etcd Server.
Nov 13 03:37:38 k8s-master etcd[8832]: set the initial cluster version to 3.3
Nov 13 03:37:38 k8s-master etcd[8832]: enabled capabilities for version 3.3
Hint: Some lines were ellipsized, use -l to show in full.
如果出现报错
[root@k8s-master ~]# systemctl status etcd.service
● etcd.service - Etcd Server
Loaded: loaded (/usr/lib/systemd/system/etcd.service; disabled; vendor preset: disabled)
Active: active (running) since Thu 2019-11-14 01:39:43 EST; 3s ago
Main PID: 10145 (etcd)
CGroup: /system.slice/etcd.service
└─10145 /usr/bin/etcd --name=etcd1 --data-dir=/var/lib/etcd/default.etcd --listen-client-urls=ht...
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Nov 14 01:39:46 k8s-master etcd[10145]: request cluster ID mismatch (got d2135848fea6b97d want cdf81819...c32)
Hint: Some lines were ellipsized, use -l to show in full.
执行rm -rf /var/lib/etcd/ 然后在重启
查看etcd集群状态
[root@k8s-master ~]# etcdctl cluster-health
member 1cee87bc2e2538ff is healthy: got healthy result from http://10.9.1.153:2379
member d0f1fe2820a9ce30 is healthy: got healthy result from http://10.9.1.151:2379
member dfde526bce6b55a9 is healthy: got healthy result from http://10.9.1.152:2379
cluster is healthy
ETCD_LISTEN_CLIENT_URLS="http://10.9.1.153:2379,http://127.0.0.1:2379"
#如上:如果/etc/etcd/etcd.conf 中不加后面的,http://127.0.0.1:2379"会出现如下报错
每个节点都加上,http://127.0.0.1:2379" 可在每个节点执行etcdctl cluster-health这个命令
[root@k8s-master ~]# etcdctl cluster-health
cluster may be unhealthy: failed to list members
Error: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 127.0.0.1:2379: connect: connection refused
; error #1: dial tcp 127.0.0.1:4001: connect: connection refused
error #0: dial tcp 127.0.0.1:2379: connect: connection refused
error #1: dial tcp 127.0.0.1:4001: connect: connection refusedKubernetes集群配置
master节点配置
1.apiserver配置文件修改,注意KUBE_ADMISSION_CONTROL选项的参数配置
###
# kubernetes system config
#
# The following values are used to configure the kube-apiserver
#
# The address on the local server to listen to.
KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0"
# The port on the local server to listen on.
KUBE_API_PORT="--port=8080"
# Port minions listen on
KUBELET_PORT="--kubelet-port=10250"
# Comma separated list of nodes in the etcd cluster
KUBE_ETCD_SERVERS="--etcd-servers=http://10.9.1.151:2379,http://10.9.1.152:2379,http://10.9.1.153:2379"
# Address range to use for services
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16"
# default admission control policies
#KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota"
KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,ResourceQuota"
# Add your own!
KUBE_API_ARGS=""
2.启动服务
[root@k8s-master ~]# systemctl start kube-apiserver
[root@k8s-master ~]# systemctl start kube-controller-manager
[root@k8s-master ~]# systemctl start kube-scheduler
[root@k8s-master ~]# systemctl enable kube-apiserver
[root@k8s-master ~]# systemctl enable kube-controller-manager
[root@k8s-master ~]# systemctl enable kube-schedulernodes节点配置
1.配置config配置,node1&node2配置相同
[root@k8s-node2 ~]# vim /etc/kubernetes/config
###
# kubernetes system config
#
# The following values are used to configure various aspects of all
# kubernetes services, including
#
# kube-apiserver.service
# kube-controller-manager.service
# kube-scheduler.service
# kubelet.service
# kube-proxy.service
# logging to stderr means we get it in the systemd journal
KUBE_LOGTOSTDERR="--logtostderr=true"
# journal message level, 0 is debug
KUBE_LOG_LEVEL="--v=0"
# Should this cluster be allowed to run privileged docker containers
KUBE_ALLOW_PRIV="--allow-privileged=false"
# How the controller-manager, scheduler, and proxy find the apiserver
KUBE_MASTER="--master=http://10.9.1.151:8080"
~ 2.配置kubelet
[root@k8s-node2 ~]# vim /etc/kubernetes/kubelet
###
# kubernetes kubelet (minion) config
# The address for the info server to serve on (set to 0.0.0.0 or "" for all interfaces)
KUBELET_ADDRESS="--address=127.0.0.1"
# The port for the info server to serve on
# KUBELET_PORT="--port=10250"
# You may leave this blank to use the actual hostname
KUBELET_HOSTNAME="--hostname-override=10.9.1.153"
# location of the api-server
KUBELET_API_SERVER="--api-servers=http://10.9.1.151:8080"
# pod infrastructure container
KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest"
# Add your own!
KUBELET_ARGS=""
网络配置
这里使用flannel进行网络配置,已经在2个节点上安装,下面进行配置。
在节点上进行配置flannel
[root@k8s-node2 ~]# vim /etc/sysconfig/flanneld
# Flanneld configuration options
# etcd url location. Point this to the server where etcd runs
FLANNEL_ETCD_ENDPOINTS="http://10.9.1.151:2379"
# etcd config key. This is the configuration key that flannel queries
# For address range assignment
FLANNEL_ETCD_PREFIX="/atomic.io/network"
# Any additional options that you want to pass
#FLANNEL_OPTIONS=""
设定网段
确定etcd可以使用之后,我们需要设置分配给docker网络的网段
etcdctl mk /atomic.io/network/config '{"Network":"172.17.0.0/16", "SubnetMin": "172.17.1.0", "SubnetMax": "172.17.254.0"}'
systemctl enable flanneld.service
systemctl start flanneld.service
systemctl daemon-reload//重新加载配置
systemctl start docker
systemctl enable docker //开启自启动
systemctl restart kubelet.service
systemctl restart kube-proxy.service
其中最主要的问题是:details: (open /etc/docker/certs.d/registry.access.redhat.com/redhat-ca.crt: no such file or directory)
解决方案:
查看/etc/docker/certs.d/registry.access.redhat.com/redhat-ca.crt (该链接就是上图中的说明) 是一个软链接,但是链接过去后并没有真实的/etc/rhsm,所以需要使用yum安装:
yum install *rhsm*
安装完成后,执行一下docker pull registry.access.redhat.com/rhel7/pod-infrastructure:latest
如果依然报错,可参考下面的方案:
wget http://mirror.centos.org/centos/7/os/x86_64/Packages/python-rhsm-certificates-1.19.10-1.el7_4.x86_64.rpmrpm2cpio python-rhsm-certificates-1.19.10-1.el7_4.x86_64.rpm | cpio -iv --to-stdout ./etc/rhsm/ca/redhat-uep.pem | tee /etc/rhsm/ca/redhat-uep.pem
这两个命令会生成/etc/rhsm/ca/redhat-uep.pem文件.
顺得的话会得到下面的结果。
[root@localhost]# docker pull registry.access.redhat.com/rhel7/pod-infrastructure:latest
Trying to pull repository registry.access.redhat.com/rhel7/pod-infrastructure ...
latest: Pulling from registry.access.redhat.com/rhel7/pod-infrastructure
26e5ed6899db: Pull complete
66dbe984a319: Pull complete
9138e7863e08: Pull complete
Digest: sha256:92d43c37297da3ab187fc2b9e9ebfb243c1110d446c783ae1b989088495db931
Status: Downloaded newer image for registry.access.redhat.com/rhel7/pod-infrastructure:latest查看集群状态
[root@k8s-master ~]# kubectl get nodes
NAME STATUS AGE
10.9.1.152 Ready 2h
10.9.1.153 Ready 2h
[root@k8s-master ~]# etcdctl member list
1cee87bc2e2538ff: name=etcd3 peerURLs=http://10.9.1.153:2380 clientURLs=http://10.9.1.153:2379 isLeader=true
d0f1fe2820a9ce30: name=etcd1 peerURLs=http://10.9.1.151:2380 clientURLs=http://10.9.1.151:2379 isLeader=false
dfde526bce6b55a9: name=etcd2 peerURLs=http://10.9.1.152:2380 clientURLs=http://10.9.1.152:2379 isLeader=false
[root@k8s-master ~]# etcdctl cluster-health
member 1cee87bc2e2538ff is healthy: got healthy result from http://10.9.1.153:2379
member d0f1fe2820a9ce30 is healthy: got healthy result from http://10.9.1.151:2379
member dfde526bce6b55a9 is healthy: got healthy result from http://10.9.1.152:2379
cluster is healthy使用
nodes节点
[root@k8s-node1 ~]# docker pull registry.access.redhat.com/rhel7/pod-infrastructure:latest
Trying to pull repository registry.access.redhat.com/rhel7/pod-infrastructure ...
latest: Pulling from registry.access.redhat.com/rhel7/pod-infrastructure
26e5ed6899db: Downloading [===========> ] 15.49 MB/66.51 MB
66dbe984a319: Download complete
9138e7863e08: Download complete
[root@k8s-node1 ~]# docker pull nginx
master节点
kubectl run my-nginx --image=nginx --replicas=2 --port=80也可在master节点上直接运行以上命令,可以不在node 节点上执行docker pull nginx,但是相对于比较慢
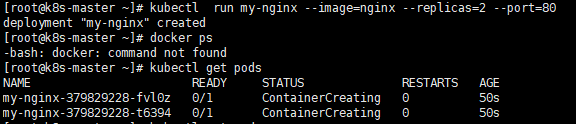
最后结果

![]()
![]()
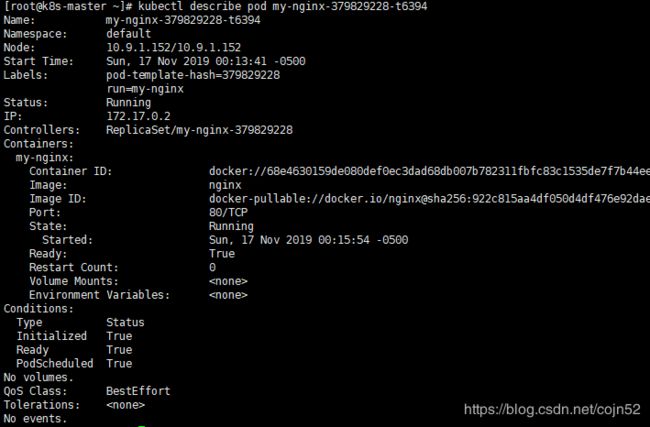
如果出现一直creating 可以使用kubectl describe pod my-nginx-379829228-t6394来查看

最后如果下载不下来可以用下面的repo 我在部署的时候没有用到
[root@k8s-master ~]# cd /etc/yum.repos.d
[root@k8s-master yum.repos.d]# yum install wget -y
[root@k8s-master yum.repos.d]# rm -f CentOS-*
[root@k8s-master yum.repos.d]#wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@k8s-master yum.repos.d]#wget -P /etc/yum.repos.d/ http://mirrors.aliyun.com/repo/epel-7.repo
[root@k8s-master yum.repos.d]#cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
EOF
[root@k8s-master yum.repos.d]#wget https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
[root@k8s-master yum.repos.d]#rpm -import rpm-package-key.gpg #安装key文件
[root@k8s-master yum.repos.d]#wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@k8s-master yum.repos.d]#yum clean all && yum makecache fast