ELECTRA:超越BERT,2019年最佳NLP预训练模型

【导读】BERT推出这一年来,除了XLNet,其他的改进都没带来太多惊喜,无非是越堆越大的模型和数据,以及动辄1024块TPU,让工程师们不知道如何落地。今天要介绍的ELECTRA是我在ICLR盲审中淘到的宝贝(9月25日已截稿),也是BERT推出以来我见过最赞的改进,通过类似GAN的结构和新的预训练任务,在更少的参数量和数据下,不仅吊打BERT,而且仅用1/4的算力就达到了当时SOTA模型RoBERTa的效果。
1. 简介
ELECTRA的全称是Efficiently Learning an Encoder that Classifies Token Replacements Accurately,先来直观感受一下ELECTRA的效果:
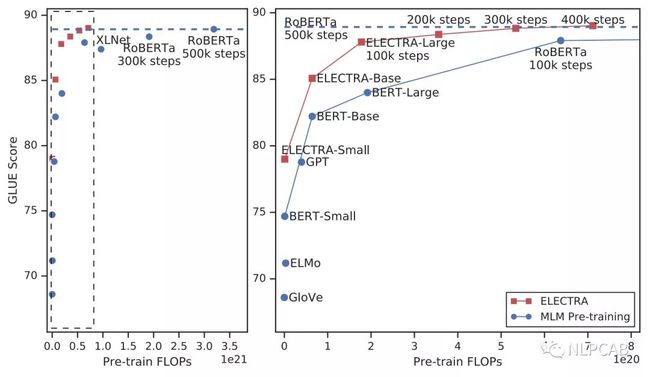
右边的图是左边的放大版,纵轴是GLUE分数,横轴是FLOPs (floating point operations),Tensorflow中提供的浮点数计算量统计。从上图可以看到,同等量级的ELECTRA是一直碾压BERT的,而且在训练更长的步数之后,达到了当时的SOTA模型——RoBERTa的效果。从左图曲线上也可以看到,ELECTRA效果还有继续上升的空间。
2.模型结构
NLP式的Generator-Discriminator
ELECTRA最主要的贡献是提出了新的预训练任务和框架,把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。那么问题来了,我随机替换一些输入中的字词,再让BERT去预测是否替换过可以吗?可以的,因为我就这么做过,但效果并不好,因为随机替换太简单了。
那怎样使任务复杂化呢?。。。咦,咱们不是有预训练一个MLM模型吗?
于是作者就干脆使用一个MLM的G-BERT来对输入句子进行更改,然后丢给D-BERT去判断哪个字被改过,如下:
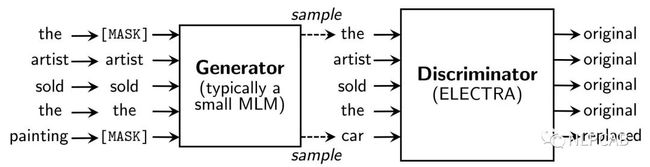
于是,我们NLPer终于成功地把CV的GAN拿过来了!
Replaced Token Detection
但上述结构有个问题,输入句子经过生成器,输出改写过的句子,因为句子的字词是离散的,所以梯度在这里就断了,判别器的梯度无法传给生成器,于是生成器的训练目标还是MLM(作者在后文也验证了这种方法更好),判别器的目标是序列标注(判断每个token是真是假),两者同时训练,但判别器的梯度不会传给生成器,目标函数如下:

因为判别器的任务相对来说容易些,RTD loss相对MLM loss会很小,因此加上一个系数,作者训练时使用了50。
另外要注意的一点是,在优化判别器时计算了所有token上的loss,而以往计算BERT的MLM loss时会忽略没被mask的token。作者在后来的实验中也验证了在所有token上进行loss计算会提升效率和效果。
事实上,ELECTRA使用的Generator-Discriminator架构与GAN还是有不少差别,作者列出了如下几点:

3.实验及结论
创新总是不易的,有了上述思想之后,可以看到作者进行了大量的实验,来验证模型结构、参数、训练方式的效果。
Weight Sharing
生成器和判别器的权重共享是否可以提升效果呢?作者设置了相同大小的生成器和判别器,在不共享权重下的效果是83.6,只共享token embedding层的效果是84.3,共享所有权重的效果是84.4。作者认为生成器对embedding有更好的学习能力,因为在计算MLM时,softmax是建立在所有vocab上的,之后反向传播时会更新所有embedding,而判别器只会更新输入的token embedding。最后作者只使用了embedding sharing。
Smaller Generators
从权重共享的实验中看到,生成器和判别器只需要共享embedding的权重就足矣了,那这样的话是否可以缩小生成器的尺寸进行训练效率提升呢?作者在保持原有hidden size的设置下减少了层数,得到了下图所示的关系图:

可以看到,生成器的大小在判别器的1/4到1/2之间效果是最好的。作者认为原因是过强的生成器会增大判别器的难度(判别器:小一点吧,我太难了)。
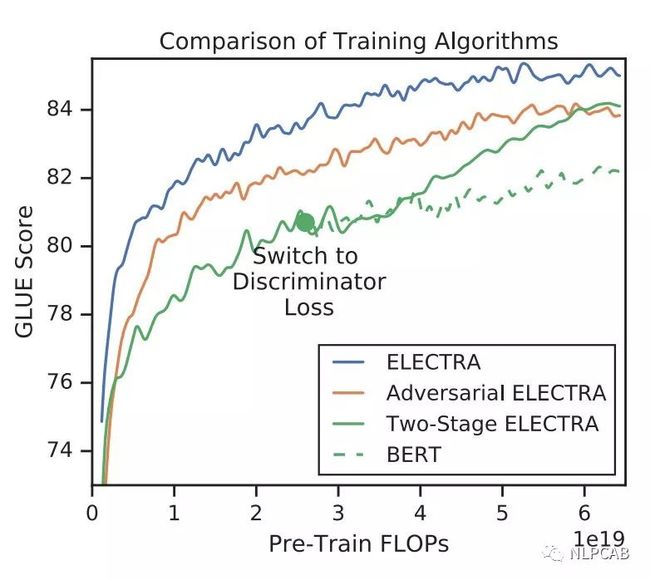
Training Algorithms
实际上除了MLM loss,作者也尝试了另外两种训练策略:
-
Adversarial Contrastive Estimation:ELECTRA因为上述一些问题无法使用GAN,但也可以以一种对抗学习的思想来训练。作者将生成器的目标函数由最小化MLM loss换成了最大化判别器在被替换token上的RTD loss。但还有一个问题,就是新的生成器loss无法用梯度下降更新生成器,于是作者用强化学习Policy Gradient的思想,将被替换token的交叉熵作为生成器的reward,然后进行梯度下降。强化方法优化下来生成器在MLM任务上可以达到54%的准确率,而之前MLE优化下可以达到65%。
-
Two-stage training:即先训练生成器,然后freeze掉,用生成器的权重初始化判别器,再接着训练相同步数的判别器。


-
ELECTRA 15%:让判别器只计算15% token上的损失
-
Replace MLM:训练BERT MLM,输入不用[MASK]进行替换,而是其他生成器。这样可以消除这种pretrain-finetune直接的diff。
-
All-Tokens MLM:接着用Replace MLM,只不过BERT的目标函数变为预测所有的token,比较接近ELECTRA。

-
对比ELECTRA和ELECTRA 15%:在所有token上计算loss确实能提升效果
-
对比Replace MLM和BERT:[MASK]标志确实会对BERT产生影响,而且BERT目前还有一个trick,就是被替换的10%情况下使用原token或其他token,如果没有这个trick估计效果会差一些。
-
对比All-Tokens MLM和BERT:如果BERT预测所有token 的话,效果会接近ELECTRA
4.总结

参考资料:
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
(*本文为AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。6.6 折票限时特惠(立减1400元),学生票仅 599 元!
