1.什么是hadoop
hadoop中有3个核心模块:
HDFS(分布式文件系统):将文件分布式存储在多台服务器上
MAPREDUCE(分布式运算编程框架):多台服务器并行运算
YARN(分布式资源调度平台):帮用户调度大量的MAPREDUCE程序,合理分配资源
2.HDFS整体运作机制
HDFS(分布式文件系统):
一个HDFS系统,是由一个运行namenode的服务器和若干运行datanode的服务器组成

3.搭建HDFS分布式集群
3.1.需要准备多台Linux服务器
1.准备1+N台服务器:1个namenode节点和N个datanode节点
2.修改服务器ip修改为固定的 方法自行百度
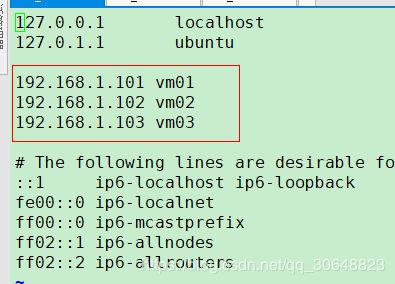
3.修改etc下的hosts 将ip与服务器的名称对应上(相当于域名解析)(域名映射配置)
4.关闭防火墙
关闭防火墙:service iptables stop
关闭防火墙自启: chkconfig iptables off
6.安装jdk(自行百度)
(2-6)每台服务器都需要
3.2安装,配置,启动HDFS
3.2.1上传hadoop安装包到各服务器
3.2.2修改配置文件
- 解压至任意位置 演示为root目录下
hadoop的配置文件在:/root/hdoop./etc/hadoop/ - 修改hadoop-env.sh(配置java环境:因为hadoop是java程序需要java环境)
export JAVA_HOME = 你的java jdk目录 (javahome) - 修改core-site.xml (说明你的 namenode在什么地方)
fs.defaultFS
hdfs://vm01:9000
说明:格式为固定写法,name为固定,value中vm01为你想要运行namenode服务的服务器的地址
- 修改hdfs-site.xml (说明你的文件分割记录放在哪个目录,分割的文件放在哪个目录)
dfs.namenode.name.dir
/root/dfs/name
dfs.datanode.data.dir
/root/dfs/data
dfs.namenode.secondary.http-address
vm02:50090
说明:
dfs.namenode.name.dir中的value是指定文件分割记录放在哪个目录
dfs.datanode.data.dir中的value是指定文件的分块放在哪个目录
dfs.namenode.secondary.http-address中的valuevm02是指服务器,50090是端口号(最好不要改)
- 将这些修改过的配置文件复制到其他服务器上(每台服务器都一样)
3.33启动HDFS
要想直接运行Hadoop命令 先要配置环境变量
vi/etc/profile
文件尾部追加
export
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export
HADOOP_HOME=/root/hadoop/hadoop-2.8.5
export
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
- 初始化namenode的源数据目录
在vm01上执行初始化namenode命令
hadoop namenode -format
这个时候hdfs已经初步搭建完成
在vm01上可以启动namenode和datanode
在其他服务器上可以穹顶datanode
启动namenode命令
hadoop-daemon.sh start namenode
启动datanode命令
hadoop-daemon.sh start datanode
此时可以在window浏览器中访问hdfs提供的web端口:50070
http://192.168.1.101:50070 (运行namenode的服务器的ip)
但是要是有N台datanode那么是不是要在N台上面输入命令启动datanode呢?
当然不是,可以使用HDFS提供的批量启动脚本来执行启动
- 配置ssh免密登录
在主服务器(vm01)执行
ssh-keygen(一顿回车)
ssh-copy-id vm01(第一次需要输入密码)
ssh-copy-id vm0* (依次在主服务器执行以下命令vm02 03 04......)
······
······
如果遇到错误可能是无root登录权限 那么就修改
/etc/ssh/sshd_config文件中 添加一条 PermitRootLogin yes
然后重启ssh服务 sudo service ssh restart
如果还是有错误可能是没有设置root用户密码
那么在root用户下 sudo su
输入命令 sudo passwd 设置密码
这时候就可以免密登录了
修改hadoop安装目录中/etc/hadoop/slaves(把需要启动datanode进程的节点列入
vm-01
vm-02
vm-03
这时候就可以在主服务器上执行:
start-dfs.sh 来自动启动整个集群
如果要停止,则用脚本:stop-dfs.sh(如果提示没有找到命令 那就是环境变量没有配置好,可以在hadoop目录下面的sbin下用 ./ start-dfs.sh或./stop-dfs.sh来执行)
可以自行更改HDFS的分块以及副本数量配置
文件的切块大小和存储的副本数量,都是由客户端决定
所谓的由客户端决定,是通过配置参数来定的
hdfs的客户端会读以下两个参数,来决定切块大小、副本数量:
切块大小的参数: dfs.blocksize
副本数量的参数: dfs.replication
上面两个参数应该配置在客户端机器的hadoop目录中的hdfs-site.xml中配置(每台都需要改)
dfs.blocksize
64m
dfs.replication
2
hdfs命令行客户端的所有命令列表
Usage: hadoop fs [generic options]
[-appendToFile ... ]
[-cat [-ignoreCrc] ...]
[-checksum ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] ... ]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] ... ]
[-count [-q] [-h] [-v] [-t []] [-u] [-x] ...]
[-cp [-f] [-p | -p[topax]] [-d] ... ]
[-createSnapshot []]
[-deleteSnapshot ]
[-df [-h] [ ...]]
[-du [-s] [-h] [-x] ...]
[-expunge]
[-find ... ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] ... ]
[-getfacl [-R] ]
[-getfattr [-R] {-n name | -d} [-e en] ]
[-getmerge [-nl] [-skip-empty-file] ]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [ ...]]
[-mkdir [-p] ...]
[-moveFromLocal ... ]
[-moveToLocal ]
[-mv ... ]
[-put [-f] [-p] [-l] [-d] ... ]
[-renameSnapshot ]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] ...]
[-rmdir [--ignore-fail-on-non-empty] ...]
[-setfacl [-R] [{-b|-k} {-m|-x } ]|[--set ]]
[-setfattr {-n name [-v value] | -x name} ]
[-setrep [-R] [-w] ...]
[-stat [format] ...]
[-tail [-f] ]
[-test -[defsz] ]
[-text [-ignoreCrc] ...]
[-touchz ...]
[-truncate [-w] ...]
[-usage [cmd ...]]