python基础 实战作业 ---Excel基本读写与数据处理
代码地址如下:
http://www.demodashi.com/demo/11650.html
看完本篇需要:
10min
作业练习需要:
0.5h~3h(依练习者对python熟悉程度而定)
看完本篇可以学到:
1、用xlrd模块读取Excel文件中的数据
2、用xlsxwriter模块向Excel文件写入数据并保存
3、用time和datetime模块将字符串转换成时间类,并进行时间的比较
本篇目录
1. 作业需求
2. 整体思路
3. 详细实现步骤
3.1. 读取表格数据
3.2. 将行数据list按时间先后升序排序
3.3. 维护一个map并新增数据到行数据
3.4. 将修改后的行数据list写入Excel表格并保存为xslx格式
4. 完整代码
5. 结果展示
6. 参考
7. 源码及作业练习文件
作业需求
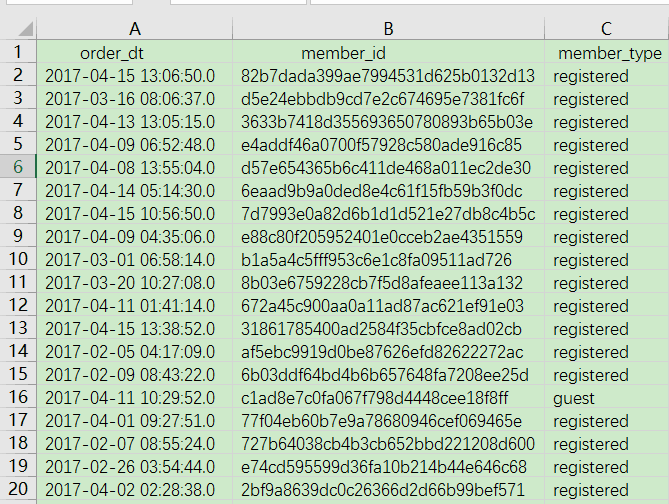
一个朋友在某运动品牌公司上班,老板给他布置了一个处理客户订单数据的任务。要求是根据订单时间和客户id判断生成四个新的数据:
1、记录该客户是第几次光顾
2、上一次的日期时间是什么时候
3、与上次订单的间隔时间
4、这是一个existing客户还是一个new客户(见定义)
文件说明:
1、第一列是订单日期和时间(乱序)
2、第二列是客户的id
3、第三列不需要使用
相关定义如下:
1、existing:此次下单日期时间与上次日期时间的距离在N天以内,精确到时间(时分秒)
2、new:即超过N天
整体思路
**1、读取表格的行数据存储成list,并按照时间列的升序排序。
2、维护一个map(在python里是字典dict),每个用户 id 作为key,一个二元组(第几次下单,上一次的日期时间)作为value。
3、遍历表格行数据的list。判断客户 id 是否已经存在于map中,若首次出现,则置该客户 id 在map中的value为[1,’首次下单’],对应行数据新增的4个数据为[1,’首次下单’,该次日期时间与上次日期时间差,’new’]。若已经存在,则更新map中对应的value为[原次数+1,该次日期时间],对应行数据新增的4个数据为[原次数+1,上次日期时间,间隔时间,new/existing取决于间隔时间与预设N]。
4、将修改过后的行数据list写入到Excel工作簿并保存。**
详细实现步骤
读取表格数据
我们可以用xlrd模块对Excel文件进行读取,以便进一步分析处理数据。示例代码如下:
wb=xlrd.open_workbook('../excel/buyer_day.xlsx')# 打开工作簿,参数为文件地址
sheet=wb.sheets()[0]# 获取工作簿中的第一张工作表
for i in range(100):
if i==0:# 跳过首行的标题
continue
time_str= sheet.row_values(i)[0]# 读取该工作表第i行的第一个单元格数据
print time_str以上代码成功输出前100行的日期则说明已经成功读取到数据。输出结果如下:
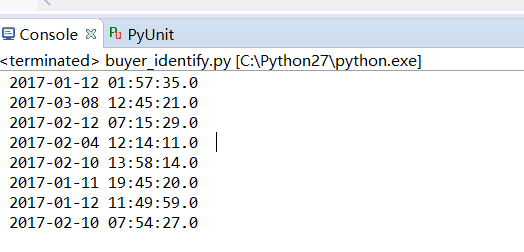
可以看到,这里输出的日期前后有空格,而且最后的时间有小数点,这不便于我们转换成时间类,所以要进行一些处理。用strip函数去掉前后空格,用切片切掉末尾的”.0”。将前面的第4行代码更改为:
time_str= sheet.row_values(i)[0].strip()[:-2]既然读取文件没有问题,进一步浏览整个文件发现存在多余的空行和重复的标题行(如图3),在读取和转存中可以用正则匹配过滤掉这些行。
另外,可以从图2看出时间是乱序的,这不利于后续的逻辑实现,所以将读取的行数据转存到list中,以便进行排序。
list_row=[]# 将行数据存储到list中,便于排序
wb=xlrd.open_workbook('../excel/buyer_day.xlsx')
sheet=wb.sheets()[0]
nrows=sheet.nrows# 工作表的行数
for i in range(nrows):
#用正则匹配过滤掉空行和标题行
str_date=sheet.row_values(i)[0].strip()[:-2]
if re.match('[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}', str_date)!=None:
list_row.append(sheet.row_values(i))# 插入到list将行数据list按时间先后升序排序
这里用到sorted函数,可以对list进行排序。示例代码如下,key指定的函数会作用于list中的每一个元素,其返回值必须为可比较的变量。
list_row=sorted(list_row,key=self.getDatetime)# 将list_row排序,排序是对key进行比较,key指定的函数会作用于list中的每一个元素行数据的第一格的日期时间字符串不便于直接比较,可以转换成datetime对象,以便直接比较。具体做法是将读取到的日期时间字符串用time模块的strptime转换成时间类,再用datetime模块转换成datetime类。
timeArray=time.strptime(time_str, "%Y-%m-%d %H:%M:%S")# 第二个参数是对应字符串的格式
Y,m,d,H,M,S=timeArray[0:6]
dt=datetime.datetime(Y,m,d,H,M,S)# 转换成datetime对象,可以直接进行比较datetime之间的比较可以直接用>,<,=符号,而且可以直接相减求间隔时间,间隔时间的类型是timedelta,也可以直接比较。示例代码如下:
dt1=datetime.datetime(2017,5,2,13,23,01)
dt2=datetime.datetime(2017,3,2,12,00,00)
dt3=datetime.datetime(2017,6,19)
dt4=datetime.datetime(2017,5,21)
dis1=dt1-dt2# 相减返回的类型是timedelta
dis2=dt3-dt4
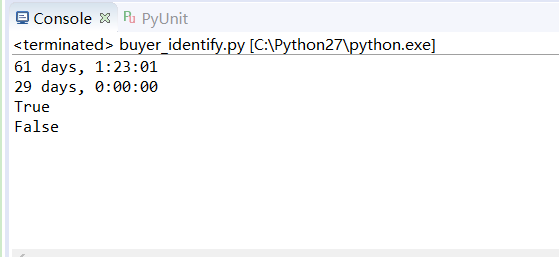
print dis1
print dis2
print dis1>dis2
print dis1<datetime.timedelta(days=30)示例输出:
维护一个map并新增数据到行数据
map={客户 id :[第几次下单,上次日期时间]}搞清楚了日期时间的比较和时间间隔的比较,我们就可以按之前整体思路的2、3步的逻辑进行map的维护更新和list中行数据的修改了。逻辑之前已经提过了,细节见代码注释。
for row_value in list_rowValues:
dt_current=self.getDatetime(row_value)# 订单日期时间的datetime类型
mber_id=row_value[1].strip()# 客户id
# 维护一个dict,用一个dict保存,客户id作为key,[当前第几次,上次订单日期时间]作为value
# 并且依此写入新数据到list的行数据中
if mber_id in self.dict_mid_data: # 如果存在这个key,说明该顾客之前有订单记录,更新dict,同时插入新数据到row_value
self.dict_mid_data[mber_id][0]+=1# 更新下单次数+1
row_value[3]=self.dict_mid_data[mber_id][0]# 插入下单次数
dt_last=self.dict_mid_data[mber_id][1]
row_value[4]=dt_last.strftime("%Y-%m-%d %H:%M:%S")# 插入上次订单日期时间
dis=abs(dt_current-dt_last)# 时间差的绝对值
row_value[5]=str(dis)# 插入与上次订单时间的间隔时间差
# 插入usertype
if dis <= datetime.timedelta(days=N):# 如果间隔在N天内
row_value[6]='existing'
else:
row_value[6]='new'
if dt_current>dt_last:# 如果当前时间更近,更新dict里的上次日期时间
self.dict_mid_data[mber_id][1]=dt_current
else:# 不存在这个key,直接保存初始值
self.dict_mid_data[mber_id]=[1,dt_current]
row_value[3]=1 # 当前是第几次订单
row_value[4]=u'首次下单' # 当前日期时间
row_value[5]='-' # 与上次订单间隔时间
row_value[6]='new' # usertype 将修改后的行数据list写入Excel表格并保存为xslx格式
xlrd模块读取的工作簿是不能修改的,也就是只能读,不能写。想要新增数据进原来的工作簿,要用到xlsxwriter模块生成新的Excel工作簿,然后把修改后的list写入到一张新的工作表中,再保存到原路径(或者新的路径),以达到修改的目的。
wb=xlsxwriter.Workbook('../excel/buyer_day_new.xlsx')
sheet=wb.add_worksheet('sheet1')# 新增一张工作表sheet1
# 写入标题
sheet.write(0,0,'order_dt')# 三个参数分别是:单元格横坐标,纵坐标,写入内容
sheet.write(0,1,'member_id')
sheet.write(0,2,'member_type')
sheet.write(0,3,'times')
sheet.write(0,4,'last_order_dt')
sheet.write(0,5,'interval')
sheet.write(0,6,'user_type')
# 写入处理后的数据
len_list=len(list_rowValues)
for i in range(len_list):
row_value=list_rowValues[i]
len_row=len(row_value)
for j in range(len_row):
sheet.write(i+1,j,row_value[j])
wb.close()完整代码
# -*- coding:utf-8 -*-
'''
Created on 2017年5月31日
@author: wycheng
'''
import xlrd
import xlsxwriter
import time,datetime
import re
class BuyerManager:
dict_mid_data={}# 维护的一个 map{客户id:[第几次下单,上次日期时间]}
# 获取对应行数据的订单时间
def getDatetime(self,row_value):
time_str=row_value[0].strip()[:-2]
timeArray=time.strptime(time_str, "%Y-%m-%d %H:%M:%S")
Y,m,d,H,M,S=timeArray[0:6]
dt_current=datetime.datetime(Y,m,d,H,M,S)# 转换成datetime对象,可以直接进行比较
return dt_current
# 将所有工作表的行按照订单日期升序排序
def getList_sorted(self,list_xl):# list_xl: Excel文件的地址list
list_row=[]# 将行数据存储到list中,便于排序
for exl in list_xl:
print u'正在打开文件 '+exl
wb=xlrd.open_workbook(exl)
sheet=wb.sheets()[0]
nrows=sheet.nrows# 工作表的行数
print u'正在插入文件 '+exl+u'的row_value'
for i in range(nrows):
#用正则匹配过滤掉空行和标题行
str_date=sheet.row_values(i)[0].strip()[:-2]
if re.match('[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}', str_date)!=None:
list_row.append(sheet.row_values(i))
print u'正在排序……'
list_row=sorted(list_row,key=self.getDatetime)# 将list_row排序,排序是对key进行比较,key指定的函数会作用于list中的每一个元素
return list_row
def process(self,list_rowValues,N):# list_rowValues: 存放所有row_value的list N: 间隔N天内是existing
# 遍历每一行
line=1
for row_value in list_rowValues:
print u'正在处理第'+str(line)+u'行'
line+=1
dt_current=self.getDatetime(row_value)# 订单日期时间的datetime类型
mber_id=row_value[1].strip()# 客户id
# 维护一个dict,用一个dict保存,客户id作为key,[当前第几次,上次订单日期时间]作为value
# 并且依此写入新数据到EXcel
if mber_id in self.dict_mid_data: # 如果存在这个key,说明该顾客之前有订单记录,更新dict,同时插入新数据到row_value
self.dict_mid_data[mber_id][0]+=1# 更新下单次数+1
row_value[3]=self.dict_mid_data[mber_id][0]# 插入下单次数
dt_last=self.dict_mid_data[mber_id][1]
row_value[4]=dt_last.strftime("%Y-%m-%d %H:%M:%S")# 插入上次订单日期时间
dis=abs(dt_current-dt_last)# 时间差的绝对值
row_value[5]=str(dis)# 插入与上次订单时间的间隔时间差
# 插入usertype
if dis <= datetime.timedelta(days=N):# 如果间隔在N天内
row_value[6]='existing'
else:
row_value[6]='new'
if dt_current>dt_last:# 如果当前时间更近,更新dict里的上次日期时间
self.dict_mid_data[mber_id][1]=dt_current
else:# 不存在这个key,直接保存初始值
self.dict_mid_data[mber_id]=[1,dt_current]
row_value[3]=1 # 当前是第几次订单
row_value[4]=u'首次下单' # 当前日期时间
row_value[5]='-' # 与上次订单间隔时间
row_value[6]='new' # usertype
return list_rowValues
# 写入Excel并保存
def write_t_xl(self,list_rowValues,xl_addr):
wb=xlsxwriter.Workbook(xl_addr)
sheet=wb.add_worksheet('sheet1')
# 写入标题
sheet.write(0,0,'order_dt')
sheet.write(0,1,'member_id')
sheet.write(0,2,'member_type')
sheet.write(0,3,'times')
sheet.write(0,4,'last_order_dt')
sheet.write(0,5,'interval')
sheet.write(0,6,'user_type')
# 写入处理后的数据
len_list=len(list_rowValues)
for i in range(len_list):
print u'正在写入第'+str(i+1)+u'行……'
row_value=list_rowValues[i]
len_row=len(row_value)
for j in range(len_row):
sheet.write(i+1,j,row_value[j])
wb.close()
print u'写入完毕,excel文件已生成!'
l=['../excel/buyer_day.xlsx']#需要输入处理的文件路径list,即可以输入多个文件进行处理
buyerManager=BuyerManager()
list_rowValues=buyerManager.getList_sorted(l)
list_rowValues_new=buyerManager.process(list_rowValues, 100)
buyerManager.write_t_xl(list_rowValues, '../excel/buyer_day_new.xlsx')结果展示
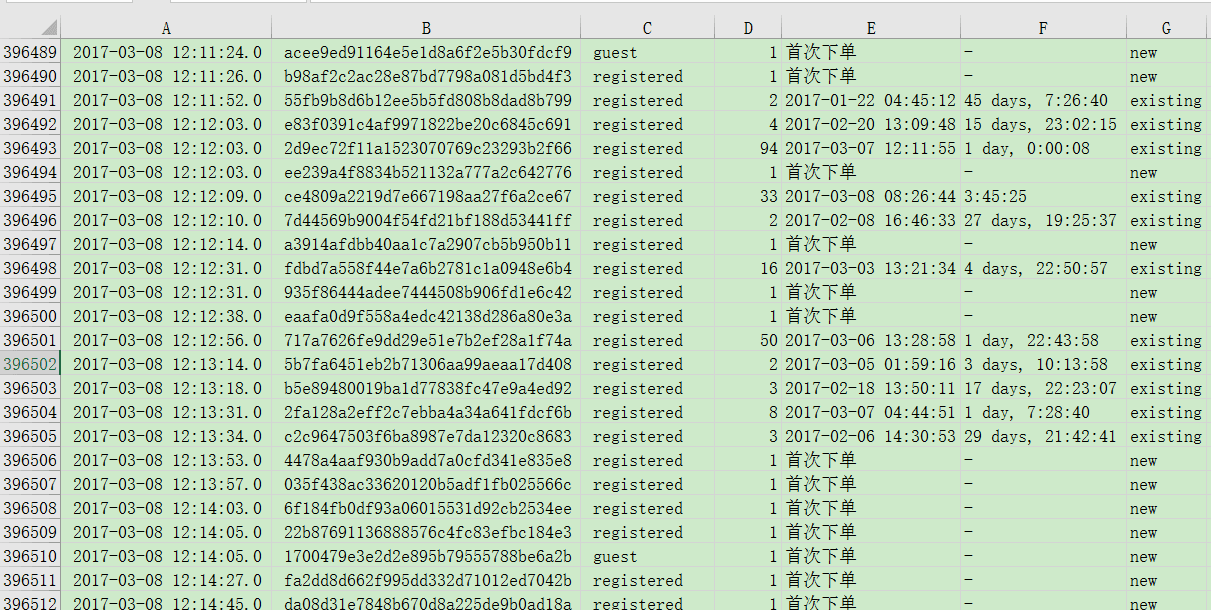
源码截图
其中附带的Excel数据文件
参考
python高手之路python处理excel文件(方法汇总)
python模块之XlsxWriter
python基础 实战作业 —Excel基本读写与数据处理
代码地址如下:
http://www.demodashi.com/demo/11650.html注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权