编译原理系列之五 自底向上优先分析(2)-算符优先分析法
算符优先分析法
1.基本概念
-
算符文法(OG):文法G中没有形如A=>···BC···的产生式,其中B、C为非终结符,则G为算符文法(operator grammar)。
也就是说产生式的右部不能出现两个非终结符相邻,就好像算式中两个操作数相连。
算符文法的两个性质:
①算符文法中任何句型都不包含两个相邻的非终结符。②如果Ab(bA)出现在算符文法的句型y中,则y中含b的短语必含A,含A的短语不一定含b。 -
算符优先文法(OPG):一个不含ε产生式的算符文法G,任意终结符对(a,b)之间最多只有一种优先关系存在,则G为算符优先文法(operator precedence grammar)。
以算式类比,也就是说我们只关心算符之间的优先关系,不关心操作数的优先关系,·利用算符的优先性和结合性来判断哪个部分先计算(归约)。
注意 :这里的优先关系与简单优先分析法中不一样。
a、b为终结符,A、B、C为非终结符
-
a和b优先级相等,表示为
a=·b,当且仅当G中存在产生式规则A=>···ab···或者A=>···aBb···。解读:表示a、b在同一句柄中同时归约。
-
a优先级小于b,表示为
a解读:表示b、a不在一个句柄中,b比a先归约。
-
a优先级大于b,表示为
a>·b,当且仅当G中存在产生式规则A=>··Bb···,且B=+=>···a或B=+=>···aC。解读:表示b、a不在一个句柄中,a比b先归约。
- FIRSTVT():FIRSTVT(B)={b|B=+=>b···或B=+=>Cb···}
- LASTVT():LASTVT(B)={b|B=+=>···b或B=+=>···bC}
- 素短语:(a)它首先是一个短语,(b)它至少含一个终结符号,(c)除自身外,不再包含其他素短语。
-
2.FIRSTVT()的构造算法
-
原理:
①如果有这样的表达式:A=>a···或者A=>Ba···,那么a∈FIRSTVT(A)。
②如果有这样的表达式:B=>A···且有a∈FIRSTVT(A),则a∈FIRSTVT(B)。
-
算法:
数据结构:
布尔数组F[m,n],m为非终结符数量,n为终结符数量,为真时表示对应a∈FIRSTVT(A)。
栈S:暂存用于进行原理②的元素。
流程图:
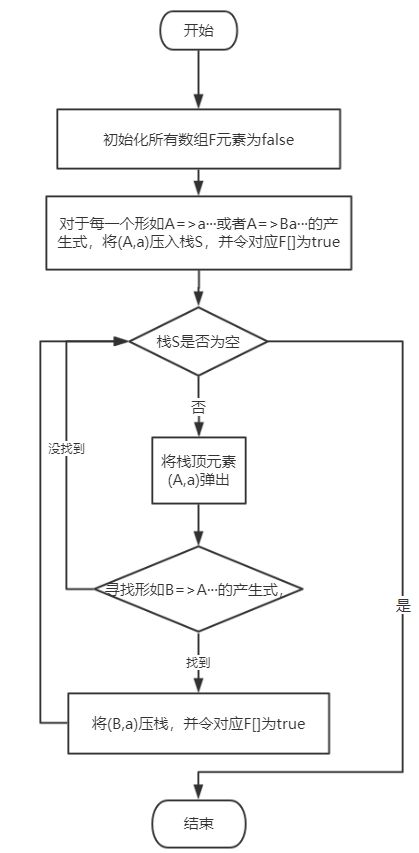
FIRSTVT构造算法流程图
类似原理可以构造LASTVT()的算法。
-
代码
#include
#include "fstream"
#include
using namespace std;
/**
* 文法输入文件格式要求:
* 所有符号均为单个字符,
* 每个产生式占一行,
* 非终结符用大写字母A-Z表示,
* 终结符用小写字母a-z和其他符号表示
* 产生式右部用|表示或
*
* 示例:
* S->#E#
* E->E+T
* E->T
* T->T*F
* T->F
* F->P!F|P
* P->(E)
* P->i
*/
#define MAX_NUM 30 //非终结符最大数量
//产生式的前两个字符
class EasyProductions
{
public:
char firstChar;
char secondChar;
EasyProductions *nextPtr = NULL;
};
//Tchar∈firstvt(Vchar)
class VTRelation
{
public:
char Tchar;
char Vchar;
};
//文法中终结符,非终结符数目
int tNum, vNum;
//储存终结符,非终结符
char tSymb[MAX_NUM], vSymb[MAX_NUM];
//存放VTRelation的栈
stack stk;
//26个非终结符的EasyProductions链表指针,序号为对应ascii码
EasyProductions *productions[MAX_NUM];
//firstvt矩阵
int **firstvt;
//判断是否为非终结符
bool isTerminal(char c)
{
if (c <= 90 && c >= 65)
return false;
else
return true;
}
//判断终结符是否已经保存至数组
bool isInTNum(char c)
{
for (int i = 0; i < tNum; i++)
{
if (tSymb[i] == c)
return true;
}
return false;
}
//判断终结符是否已经保存至数组
bool isInVNum(char c)
{
for (int i = 0; i < vNum; i++)
{
if (vSymb[i] == c)
return true;
}
return false;
}
//通过终结符字符找在数组中的编号
int findIndexByTchar(char c)
{
for (int i = 0; i < tNum; i++)
{
if (tSymb[i] == c)
{
return i;
}
}
return -1;
}
//通过非终结符字符找在数组中的编号
int findIndexByVchar(char c)
{
for (int i = 0; i < vNum; i++)
{
if (vSymb[i] == c)
{
return i;
}
}
return -1;
}
//将出现过的终结符或非终结符保存至数组
void saveSymb(char c)
{
if (isTerminal(c))
{ //是终结符
if (!isInTNum(c))
{
tSymb[tNum] = c;
tNum++;
}
}
else
{ //是非终结符
if (!isInVNum(c))
{
vSymb[vNum] = c;
vNum++;
}
}
}
//解析每条产生式的前两个字符
void analysisGrammar(char buffer[], EasyProductions *productions[])
{
int start = 3; //从3开始为产生式右部开头
int offset = 0; //距离产生式右部开头的偏移量
saveSymb(buffer[0]);
while (buffer[start + offset] != 0) //产生式读完 //没有换行符
{
if (buffer[start + offset] != '|')
saveSymb(buffer[start + offset]);
if (offset == 0 && buffer[start + offset] != '|') //开头
{
if (buffer[start + offset + 1] != 0 || buffer[start + offset + 1] != '|') //开头有两字符
{
EasyProductions *production = new EasyProductions;
production->firstChar = buffer[start + offset];
production->secondChar = buffer[start + offset + 1];
if (productions[buffer[0] - 65] == NULL)
{
productions[buffer[0] - 65] = production;
}
else //头插法
{
EasyProductions *temp = productions[buffer[0] - 65]->nextPtr;
productions[buffer[0] - 65]->nextPtr = production;
production->nextPtr = temp;
}
}
else //开头只有一个字符
{
EasyProductions *production = new EasyProductions;
production->firstChar = buffer[start + offset];
production->secondChar = 0;
if (productions[buffer[0] - 65] == NULL)
{
productions[buffer[0] - 65] = production;
}
else //头插法
{
EasyProductions *temp = productions[buffer[0] - 65]->nextPtr;
productions[buffer[0] - 65]->nextPtr = production;
production->nextPtr = temp;
}
}
offset++;
}
else //不是开头,跳过
{
if (buffer[start + offset] == '|')//重新开头
{
offset++;
start = start + offset;
offset = 0;
}
else
{
offset++;
}
}
}
}
//读取当前目录下grammar.txt并解析文法
int readGrammar(EasyProductions *productions[])
{
char buffer[256];
ifstream inf("grammar.txt");
if (!inf.is_open())
{
cout << "Error opening file" << endl;
return -1;
}
while (!inf.eof()) //每读一句产生式就解析
{
inf.getline(buffer, 100);
analysisGrammar(buffer, productions);
}
return 0;
}
//算法原理第一步:如果有这样的表达式:A=>a···或者A=>Ba···,那么a∈FIRSTVT(A)。
void stepOne()
{
for (int i = 0; i < MAX_NUM; i++) //遍历每个非终结符的EasyProductions
{
EasyProductions *production;
production = productions[i]; //链表头指针
while (production != NULL)
{
if (isTerminal(production->firstChar))
{ //产生式第一个字符是终结符
//保存至矩阵中
firstvt[findIndexByVchar((char)(i + 65))][findIndexByTchar(production->firstChar)] = 1;
//保存到关系中并压栈
VTRelation *relation = new VTRelation;
relation->Vchar = (char)(i + 65);
relation->Tchar = production->firstChar;
stk.push(relation);
}
else if (isTerminal(production->secondChar) && production->secondChar != 0)
{ //产生式第一个字符不是终结符但第二个字符是终结符
//保存至矩阵中
firstvt[findIndexByVchar((char)(i + 65))][findIndexByTchar(production->secondChar)] = 1;
//保存到关系中并压栈
VTRelation *relation = new VTRelation;
relation->Vchar = (char)(i + 65);
relation->Tchar = production->secondChar;
stk.push(relation);
}
production = production->nextPtr; //指向下个节点
}
}
}
//算法原理第二步:B=>A···且有a∈FIRSTVT(A),则a∈FIRSTVT(B)
void stepTwo()
{
while (!stk.empty())
{ //栈不为空
VTRelation *relation = stk.top();
int nnn = stk.size();
stk.pop();
nnn = stk.size(); //弹出,得到(A,a)
for (int i = 0; i < MAX_NUM; i++) //遍历每个非终结符的EasyProductions
{
if ((char)i == relation->Vchar) //A->···时跳过
continue;
EasyProductions *production;
production = productions[i]; //链表头指针
while (production != NULL)
{
if (production->firstChar == relation->Vchar) //找到B->A···,得到(B,a)
{
if (firstvt[findIndexByVchar((char)(i + 65))][findIndexByTchar(relation->Tchar)] == 1) //已知则跳过
{
production = production->nextPtr; //指向下个节点
continue;
}
//保存至矩阵中
firstvt[findIndexByVchar((char)(i + 65))][findIndexByTchar(relation->Tchar)] = 1;
//保存到关系中并压栈
VTRelation *relationStack = new VTRelation;
relationStack->Vchar = (char)(i + 65);
relationStack->Tchar = relation->Tchar;
stk.push(relationStack);
}
production = production->nextPtr; //指向下个节点
}
}
}
}
//打印FirstVT矩阵
void printFirstVT()
{
for (int i = 0; i < vNum; i++)
{
cout << "FirstVT(" << vSymb[i] << ")={ ";
for (int j = 0; j < tNum; j++)
{
if (firstvt[i][j] == 1)
{
cout << tSymb[j] << " ";
}
}
cout << "}" << endl;
}
}
/**
* FirstVT构造算法
*/
int main()
{
//初始化terminal数组
for (int i = 0; i < MAX_NUM; i++)
productions[i] = NULL;
tNum = 0, vNum = 0;
readGrammar(productions);
//初始化firstvt矩阵
firstvt = new int *[vNum]; //非终结符为行
for (int i = 0; i < vNum; i++)
firstvt[i] = new int[tNum]; //终结符为列
for (int i = 0; i < vNum; i++)
for (int j = 0; j < tNum; j++)
firstvt[i][j] = 0;
stepOne();
stepTwo();
printFirstVT();
return 0;
}
3.算符优先关系矩阵的构造算法
-
原理
=·关系
查看所有产生式的右部,寻找A=>···ab···或者A=>···aBb···的产生式,可得a=·b。
<·关系
查看所有产生式的右部,寻找A=>···aB···的产生式,对于每一b∈FIRSTVT(B),可得a<·b。
>·关系
查看所有产生式的右部,寻找A=>··Bb···的产生式,对于每一a∈LASTVT(B),可得a>·b。
-
算法:
流程图:

算符优先关系矩阵的构造算法流程图
- 代码
4.算符优先分析法
读入字符串为X1X2···Xn#
数组S[n+2]用于存放压入栈的字符
流程图:
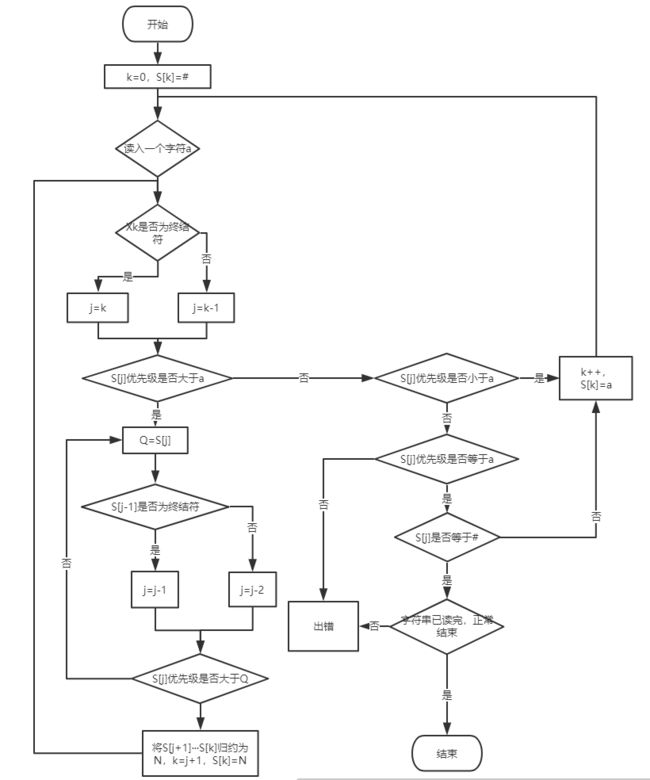
算符优先分析法流程图
代码:
5.实例
算术表达式文法G[E]:
E→E +T | T
T→T * F | F
F→i |(E)
对输入串i+i#的算符优先分析
-
求非终结符的FIRSTVT()和LASTVT()集:
FIRSTVT()={ + * i ( }
FIRSTVT()={ * i ( }
FIRSTVT()={ i ( }
LASTVT()={ + * i )}
LASTVT()={ * i )}
LASTVT()={ i )}
-
求算符优先关系矩阵
+
*
(
)
i
+
>
<
<
>
<
*
>
>
<
>
<
(
<
<
<
=
<
)
>
>
>
i
>
>
>
- 用算符优先分析法进行归约
S栈
优先关系
当前符号
输入串
动作
#
<
i
+i#
移进
#i
>
+
i#
归约
#N
<
+
i#
移进
#N+
<
i
#
移进
#N+i
>
#
归约
#N+N
>
#
归约
#N
=
#
完成
语法树:

语法树
6. 总结
通过算符优先分析法我们避免了单非终结符的归约,可以检查字符串是否为文法的句子,但是可以发现我们无法知道句子是怎么进行归约的,语法树也不是真正的语法树。
同时算符优先分析法也无法完全确定字符串能够被正确归约,有一些字符串可能可以通过算符优先分析法进行归约,但实际上它不是该文法的句子。
算符优先分析法在对文法的要求较高,适用于表达式的语法分析。