使用TDengine快速搭建运维监测系统
提到监测,有很多成熟的解决方案,似乎已经没有再讨论的必要,但随着计算机技术的发展,越来越多的场景开始需要监测,它会向着更深更广的方向发展。从业务领域来看,运维、电力、交通、工控、煤炭、油气、科研等,所有具有量化监测指标的产业,都需要数据的采集、存储、分析、可视化。但具体到不同业务,其监测的重点却可以差别很大。
官网博文同步发布地址:https://www.taosdata.com/blog/2019/07/10/使用tdengine快速搭建运维监测系统/
运维监测系统概述
本文将业务领域局限在IT运维监测方向,谈谈这里面需要关注的一些事情。IT运维监测数据通常都是对时间特性比较敏感的数据,例如
- 系统资源指标:CPU、内存、IO、带宽等
- 软件系统指标:存活状态、连接数目、请求数目、超时数目、错误数目、响应时间、服务类型及其他与业务有关的指标
这些数据的来源很丰富。可以来自操作系统自带命令,如free、vmstat、sar、iostat等。如果程序部署在Tomcat、WebLogic、IIS、JBoss等容器上,则由这些容器对外提供采集接口。但真正对软件系统起作用的,业务上真正关注的指标,主要来自于数据埋点。埋点的事情有很多,前后端都可能有,通常都是业务上的行为,但是如何存储与分析埋点后的数据,是监测系统的一个重要问题。通过以上实时采集的数据,主要目标是获得如下信息
- 宿主机的健康状态
- 软件是否处于正常运行状态,系统稳定性如何
- 软件负载情况,是否能够满足线上性能要求,是否需要增加实例,性能的瓶颈在哪里,如何提高性能
- 用户行为分析、用户画像
运维监测系统的组成
一个典型的监测系统,通常分为数据采集、数据传输、数据存储、数据统计分析、数据可视化五个模块,分析结果最终会反馈到产品经理或者软件研发人员,以确保线上软件稳定运行,并进一步提供改进软件的关键信息。
1.数据采集模块
数据采集是监测系统的第一步,采集信息是否丰富、是否足够准确、是否存够实时,直接影响到了监测系统的应用效果。
如果是对主机状态、软件基本运行情况进行数据采集,最简单易用的是Telegraf,它是一个插件驱动的服务器代理程序,可直接从其运行的容器和系统中提取各种指标,事件和日志,从第三方API提取指标。Telegraf还具有输出插件,可将指标发送到各种其他数据存储,服务和消息队列,包括InfluxDB、OpenTSDB、TDengine、NSQ等等。
如果是对软件系统产生的日志数据做数据采集,则需要该软件系统的开发人员来完成。日志数据可分为结构化日志和非结构化日志两类,对业务分析有益的数据,通常是结构化的,只是采用非结构化的文本进行了表示而已。很多软件开发人员因为偷懒,但更多的是没有这方面的意识,随意的编写记录日志的程序。这些日志因而格式变化较大,压缩比很差,等于将数据存储成本和数据分析的工作量完全推给了下游的数据分析人员,而分析人员受限于采用的开发工具,基本上无法准确、实时的给出分析结果。恰巧,软件系统中最容易更改且影响面最小的就是日志模块,所以,把日志模块抽象、改进、使得日志结构化,这是比较重要且简单的工作。
2.数据传输模块
网络环境不会是监控系统要考虑的主要问题,但是考虑到监控数据的大小和实时性要求,可以将日志区分慢日志和快日志。
对快日志,比较流行的传输方式采用RESTFul接口,不同点在于选择Pull还是Push。如果是与业务关联比较多的,建议采用Push方式,保证实时性的同时,也不需要缓存数据。Pull方式则比较简单,一般只需要被监控的软件系统提供Http接口即可,适用于拉取一些简单数值,例如系统状态、访问数量、访问时间等。快日志一般需要存储到实时分析系统,以生成实时报表为主要目标。TDengine提供的RESTFul接口,可以快速处理Push过来的Http请求,实时处理快日志。
慢日志通常记到日志文件,然后再单独做一个通用的日志收集程序,将日志写入到Kafka中,再分流出去。之后,由日志机消费这些数据,进入到数据存储模块中。
3.数据存储模块
数据存储选型在监测系统中至关重要,可供选择的大数据引擎很多。针对时序数据做了优化的,例如Prometheus、InfluxDB、TDengine、ClickHouse、OpenTSDB、Graphite等时序数据库;通用分析型的,例如Hadoop体系及其上的流式计算引擎。具体怎么选?还是要从记录的数据类型来看,关注的指标可以从写入速度、采集频率、数据压缩比、查询分析速度方面着手。
如果和时间关联不大,采用Hadoop处理这类问题较好。如果确实是时序数据的,则采用时序数据库比较好。在时序数据库上,如果为非结构化数据的,可以采用InfluxDB、OpenTSDB、Cassendra、MongoDB,如果为结构化数据的,可以采用Prometheus、ClickHouse、TDengine。后面这三种,Prometheus受限于设计,需要在水平扩展的问题上妥善考虑;ClickHouse偏重于分析,实时数据的处理能力稍差;TDengine推出时间较短,但在写入速度、查询速度、压缩比等方面都有突出的性能表现。
4.数据统计分析模块
统计分析的目标,不应该被选择的存储引擎限制了想象力。但是通常来说,监控数据的统计分析也都是与时间序列有关的一系列分析,可以分为两类
- 实时分析:最新值、实时曲线、流式计算、滑动窗口、历史截面等
- 非实时分析:年报、月报、日报、分组、聚合等
这些指标的查询性能,是选择数据存储引擎的关键因素。TDengine查询性能非常好,能够将绝大多数传统思维下的非实时分析,转变为实时分析,充分利用这个特点,可以为用户提供新功能,进一步拓展新业务。
5.数据可视化模块
数据可视化方面,除了Grafana之外,并没有太多可供选择的开源可视化软件。如果部门内部使用,是足够的;如果是对外的项目,或者需要跨部门提供数据,就需要自己编写更加易用、查询条件更丰富的界面,展示实时或者定时任务的计算结果,以期得到更好的反馈。
基于TDengine的运维监测系统的快速搭建
参照TDengine的白皮书,它创新性的定义了时序数据的存储结构,而且具备安装使用方便、压缩比高、查询性能好等特点,特别适用于处理实时监测类数据。与具体业务上有关的监测逻辑,不容易举例说明。但由于TDengine能够与开源数据采集系统Telegraf和开源数据可视化系统Grafana快速集成,所以本节参照以上各系统的用户手册,快速搭建运维数据监测系统,整个过程无需任何代码开发。
1.架构图
![]()
2.TDengine的安装与配置
- 下载tdengine-1.6.1.0.tar.gz,地址http://www.taosdata.com/downloads
- 安装TDengine,解压后运行install.sh进行安装
- 启动TDengine,运行sudo systemctl start taosd
- 测试是否安装成功,运行TDengine的shell命令行程序taos,可以看到如下类似信息
Welcome to the TDengine shell, server version:1.6.0 client version:1.6.0
Copyright (c) 2017 by TAOS Data, Inc. All rights reserved.
taos>
3.Telegraf的安装与配置
- 下载telegraf_1.7.4-1_amd64.deb,地址https://portal.influxdata.com/downloads/
- 安装telegraf,sudo dpkg -i telegraf_1.7.4-1_amd64.deb
- 配置telegraf,修改Telegraf配置文件/etc/telegraf/telegraf.conf中与TDengine有关的配置项
在output plugins部分,修改[[outputs.http]]配置项
url:http://ip:6020/telegraf/udb,其中ip为TDengine集群的中任意一台服务器的IP地址,6020为TDengine RESTful接口的端口号,telegraf为固定关键字,udb为用于存储采集数据的数据库名称,可预先创建
method: "POST"
username: 登录TDengine的用户名
password: 登录TDengine的密码
data_format: "json"
json_timestamp_units: "1ms"
例如
[[outputs.http]]
url = "http://127.0.0.1:6020/telegraf/udb"
method = "POST"
username = "root"
password = "taosdata"
data_format = "json"
json_timestamp_units = "1ms"
在agent部分,修改如下配置项
hostname: 区分不同采集设备的机器名称,需确保其唯一性
metric_batch_size: 30,允许Telegraf每批次写入记录最大数量,增大其数量可以降低Telegraf的请求发送频率,但对于TDegine,该数值不能超过50
例如
[agent]
hostname = "gsl"
metric_batch_size = 30
interval = "10s"
debug = true
omit_hostname = false
- 启动telegraf,sudo systemctl start telegraf
- 测试是否接收到Telegraf的数据
- 在shell中输入show databases语句,应该看到名为udb的数据库
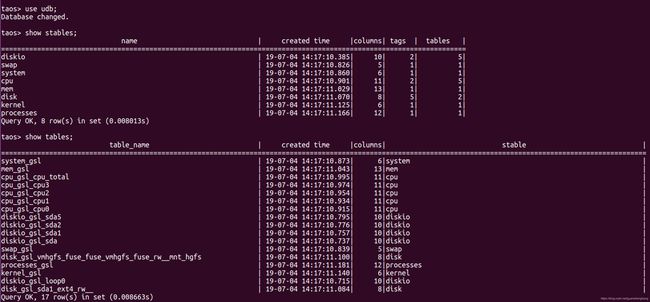
- 运行use udb语句
- 运行show stables语句,可以看到cpu等超级表
- 运行show stables语句,可以看到cpu_gsl_cpu0等普通数据表
3.Grafana的安装与配置
- 下载grafana_6.2.5_amd64.deb,地址https://grafana.com/grafana/download
- 安装Grafana,sudo dpkg -i grafana_6.2.5_amd64.deb
- 配置Grafana,TDengine 的 Grafana 插件 /usr/local/taos/connector/grafana 目录下,将之拷贝到/var/lib/grafana/plugins 目录
- 启动Grafana,sudo systemctl start taosd
- 用户可以直接通过localhost:3000的网址,登录Grafana服务器(用户名/密码:admin/admin),配置TDengine数据源,此时可以在数据源列表中看到TDengine数据源类型
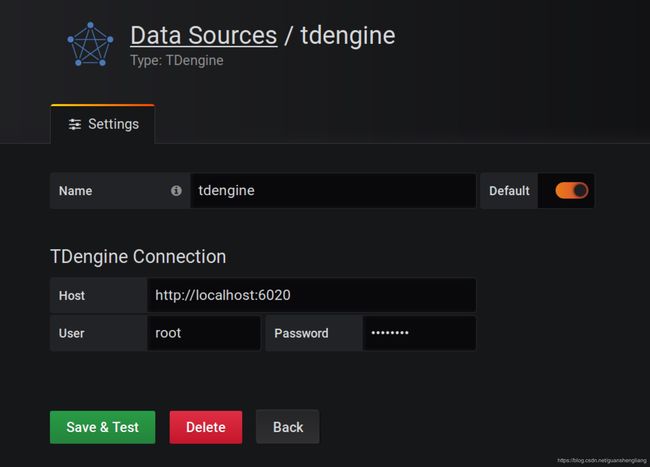
- 在Host文本框中输入http://localhost:6020并保存
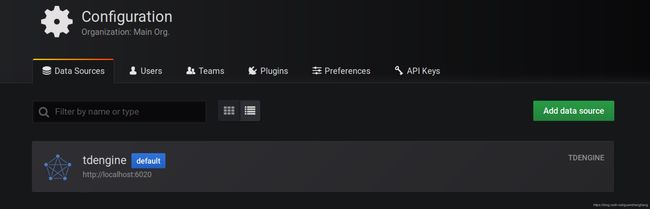
- 然后,就可以在Grafana的数据源列表中看到刚创建好的TDengine的数据源
- 创建Dashboard的时候使用TDengine数据源
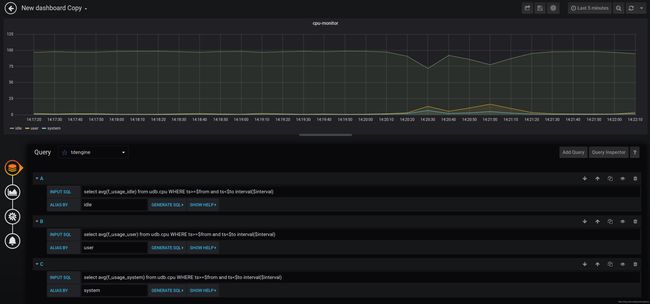
- 点击Add Query按钮增加三个新查询,在INPUT SQL输入框中输入查询SQL语句,该SQL语句的结果集应为两行多列的曲线数据,例如
select avg(f_usage_idle) from udb.cpu WHERE ts>=$from and ts<$to interval($interval)
其中,$from、$to和$interval为TDengine插件的内置变量,表示从Grafana插件面板获取的查询范围和时间间隔
点击GENERATE SQL按钮可以看到Grafana发给TDengine的SQL语句。
select avg(f_usage_idle) from udb.cpu WHERE ts>='2019-07-04T01:23:44.509Z' and ts<'2019-07-04T07:23:44.511Z' interval(20000a)
总结
监测系统可以采用的技术方案有很多,如果仅仅是做一个玩具,选择面是很大的。但若监测的数据量很大,对于写入尤其是分析性能要求很高的场景,不妨试试TDengine。
本文只是简单对TDengine使用做了初步探讨,要想真正了解它超强的读写能力,还需要进一步构造大规模的测试数据集。