网络爬虫框架scrapy介绍及应用——抓取新浪新闻的标题内容评论
一、综述
开始这篇博文之前,调研了相关的爬虫方法,简单罗列冰山一角。
综述:
http://www.crifan.com/summary_about_flow_process_of_fetch_webpage_simulate_login_website_and_some_notice/
手动编写爬虫,httpclient 是常用工具。常见的请求方式有httpget 和httppost
http://blog.csdn.net/mr_tank_/article/details/17454315
http://blog.csdn.net/chszs/article/details/16854747
http://www.yeetrack.com/?p=779 这个教程很全面。供参考和备查
htmlunit
httpclient 对js 的支持比较差,有时候需要使用htmlunit 或者selenium。
http://www.360doc.com/content/13/1229/14/14875906_340995211.shtml
http://blog.csdn.net/strawbingo/article/details/5768421
http://www.cnblogs.com/microsoftmvp/p/3716750.html
抽取相关
当爬取了html 后,需要去除噪声广告,抽取有用的信息。jsoup 和tika 是非常强大的工具
http://jsoup.org/cookbook/
http://summerbell.iteye.com/blog/565922
github 开源爬虫库
https://github.com/CrawlScript/WebCollector
https://github.com/zhuoran/crawler4j
开源爬虫框架nutch
http://www.cnblogs.com/xuekyo/archive/2013/04/18/3028559.html
http://ahei.info/nutch-tutorial.htm
http://lc87624.iteye.com/blog/1625677
由于要学习python语言,就关注了python爬虫的方法,scrapy框架是个成熟的开源爬虫框架,因此选择其作为学习内容。
Scrapy是一个基于Twisted,纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容、图片、视频等,非常方便。
二、scrapy框架
1、整体架构如下:

绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。参考博客
2、工程文件介绍
假设你已经配置好环境了,进入某个文件夹pythonproject,在命令行中输入
scrapy startproject mypro
即可在pythonporoject文件夹下找到mypro的工程文件夹,结构如下:
├── mypro
│ ├── mypro
│ │ ├── __init__.py
│ │ ├── items.py
│ │ ├── pipelines.py
│ │ ├── settings.py
│ │ └── spiders
│ │ └── __init__.py
│ └── scrapy.cfg
scrapy.cfg: 项目配置文件
items.py: 需要提取的数据结构定义文件
pipelines.py:管道定义,用来对items里面提取的数据做进一步处理,如保存等
settings.py: 爬虫配置文件
Items是将要装载抓取的数据的容器,它工作方式像python里面的字典,但它提供更多的保护,比如对未定义的字段填充以防止拼写错误。它通过创建一个scrapy.item.Item类来声明,定义它的属性为scrpiy.item.Field对象,就像是一个对象关系映射(ORM),我们通过将需要的item模型化,来控制从dmoz.org获得的站点数据。虽然这次的实现并没有用到items.py和pipelines.py,但大规模的爬虫还是需要注意一下解耦。
举个例子:
from scrapy.item import Item, Field
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()在修改初始化代码时,首先需要在 pythonproject//mypro//mypro//spiders下新建一个python文件,原则上所有的实现可以在这个文件里完成,当然耦合度就高了。在这个文件中,你需要新建一个类,这个类需要添加以下属性:
1、该类继承于某个spider类,根据自己的需求,有很多可以选,如crawSpider,BaseSpider,Spider,XMLFeedSpider,CSVFeedSpider,SitemapSpider等等
2、name:爬虫的识别名,它必须是唯一的,在不同的爬虫中你必须定义不同的名字,例如下文的"yourname"
3、start_urls:爬虫开始爬的一个URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些URLS开始。其他子URL将会从这些起始URL中继承性生成。
4、parse():爬虫的方法,调用时候传入从每一个URL传回的Response对象作为参数,response将会是parse方法的唯一的一个参数,这个方法负责解析返回的数据、匹配抓取的数据(解析为item)并跟踪更多的URL。返回前可以巧妙地运用yield方法递归调用网址,此关键词的作用是返回某个对象后继续执行。如果不用该关键字,则直接会在函数中返回。
一般而言,运用scrapy的步骤是这样的:
1、在pythonproject//mypro//mypro//spiders下新建一个python文件
2、导入该导入的库文件,新建一个类满足以上要求。
3、根据继承的类的要求和功能,定义爬取规则。
4、在def parse(self, response)函数中对response对象解析,将需要的内容存入item对象并返回,在这里对数据不返回而是进行进一步处理也是可以的,耦合度高。
5、PipeLine用来对Spider返回的Item列表进行保存操作,可以写入到文件、或者数据库等。PipeLine只有一个需要实现的方法:process_item。
万事具备之后,通过命令行进入 pythonproject// mypro文件夹中,敲下命令行开始爬虫scrapy crawl "yourname"
scrapy命令罗列几个,要更多请参看doc
* `scrapy startproject xxx` 新建一个xxx的project
* `scrapy crawl xxx` 开始爬取,必须在project中
* `scrapy shell url` 在scrapy的shell中打开url,非常实用
* `scrapy runspider
三、新浪新闻爬虫
众所周知,评论一般是隐藏起来的,或者显示部分,需要手动点击加载去获取更多评论。有两种方法可以解决这种方法,一种是利用js动态解析,工作量大,也比较难实现,二是直接定位到其查询数据库的url,直接抽取。下文就是讲第二种方法。
新浪页面导航为我们简单分好类了 http://news.sina.com.cn/guide/,而且每个类别中都可以找到相应的滚动新闻(url冠以roll),因而没必要用到crawSpider这个类,这个类功能很强大,不仅可以自动去重,还可以定义更多的爬取规则。
例如这个链接 http://roll.finance.sina.com.cn/finance/zq1/index_1.shtml,通过修改数字可以实现不断爬取对于新闻的url,当然没有这么“好”的url也是可以找到新闻的url。
==========================================================================================================================================================
例如:http://sports.sina.com.cn/nba/
可以调用的浏览器的开发工具查找对应的js代码,查看数据库的url,之后在查看评论的时候也是这样的方法(点击刷新即可)

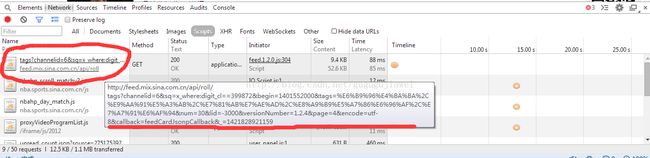
访问这个链接http://feed.mix.sina.com.cn/api/roll/tags?channelid=6&sq=x_where:digit_cl==399872&begin=1401552000&tags=%E6%B9%96%E4%BA%BA%2C%E9%AA%91%E5%A3%AB%2C%E7%81%AB%E7%AE%AD%2C%E8%A9%B9%E5%A7%86%E6%96%AF%2C%E7%A7%91%E6%AF%94&num=30&lid=-3000&versionNumber=1.2.4&page=4&encode=utf-8&callback=feedCardJsonpCallback&_=1421828921159
可以查看url

==========================================================================================================================================================
这里以有很好得url列表为例进行代码说明。
因此,访问这个链接 http://roll.finance.sina.com.cn/finance/zq1/index_1.shtml 的内容,爬取新闻url,访问新闻并爬取标题、内容、评论。
#! /usr/bin/env python
#coding=utf-8
from scrapy.selector import Selector
from scrapy.http import Request
import re,os
from bs4 import BeautifulSoup
from scrapy.spider import Spider
import urllib2,thread
#处理编码问题
import sys
reload(sys)
sys.setdefaultencoding('gb18030')
#flag的作用是保证第一次爬取的时候不进行单个新闻页面内容的爬取
flag=1
projectpath='F:\\Python27\\pythonproject\\fuck\\'
def loop(*response):
sel = Selector(response[0])
#get title
title = sel.xpath('//h1/text()').extract()
#get pages
pages=sel.xpath('//div[@id="artibody"]//p/text()').extract()
#get chanel_id & comment_id
s=sel.xpath('//meta[@name="comment"]').extract()
#comment_id = channel[index+3:index+15]
index2=len(response[0].url)
news_id=response[0].url[index2-14:index2-6]
comment_id='31-1-'+news_id
#评论内容都在这个list中
cmntlist=[]
page=1
#含有新闻url,标题,内容,评论的文件
file2=None
#该变量的作用是当某新闻下存在非手机用户评论时置为False
is_all_tel=True
while((page==1) or (cmntlist != [])):
tel_count=0 #each page tel_user_count
#提取到的评论url
url="http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=cj&newsid="+str(comment_id)+"&group=0&compress=1&ie=gbk&oe=gbk&page="+str(page)+"&page_size=100"
url_contain=urllib2.urlopen(url).read()
b='={'
after = url_contain[url_contain.index(b)+len(b)-1:]
#字符串中的None对应python中的null,不然执行eval时会出错
after=after.replace('null','None')
#转换为字典变量text
text=eval(after)
if 'cmntlist' in text['result']:
cmntlist=text['result']['cmntlist']
else:
cmntlist=[]
if cmntlist != [] and (page==1):
filename=str(comment_id)+'.txt'
path=projectpath+'stock\\' +filename
file2=open(path,'a+')
news_content=str('')
for p in pages:
news_content=news_content+p+'\n'
item=""+response[0].url+" "+'\n\n'+""+str(title[0])+" \n\n"+"\n"+str(news_content)+" \n\n\n"
file2.write(item)
if cmntlist != []:
content=''
for status_dic in cmntlist:
if status_dic['uid']!='0':
is_all_tel=False
#这一句视编码情况而定,在这里去掉decode和encode也行
s=status_dic['content'].decode('UTF-8').encode('GBK')
#见另一篇博客“三张图”
s=s.replace("'",'"')
s=s.replace("\n",'')
s1="u'"+s+"'"
try:
ss=eval(s1)
except:
try:
s1='u"'+s+'"'
ss=eval(s1)
except:
return
content=content+status_dic['time']+'\t'+status_dic['uid']+'\t'+ss+'\n'
#当属于手机用户时
else:
tel_count=tel_count+1
#当一个page下不都是手机用户时,这里也可以用is_all_tel进行判断,一种是用开关的方式,一种是统计的方式
#算了不改了
if tel_count!=len(cmntlist):
file2.write(content)
page=page+1
#while loop end here
if file2!=None:
#当都是手机用户时,移除文件,否则写入" "到文件尾
if is_all_tel:
file2.close()
try:
os.remove(file2.name)
except WindowsError:
pass
else:
file2.write("")
file2.close()
class DmozSpider(Spider):
name = "stock"
allowed_domains = ["sina.com.cn"]
#在本程序中,start_urls并不重要,因为并没有解析
start_urls = [
"http://news.sina.com.cn/"
]
global projectpath
if os.path.exists(projectpath+'stock'):
pass
else:
os.mkdir(projectpath+'stock')
def parse(self, response):
#这个scrapy.selector.Selector是个不错的处理字符串的类,python对编码很严格,它却处理得很好
#在做这个爬虫的时候,碰到很多奇奇怪怪的编码问题,主要是中文,试过很多既有的类,BeautifulSoup处理得也不是很好
sel = Selector(response)
global flag
if(flag==1):
flag=2
page=1
while page<260:
url="http://roll.finance.sina.com.cn/finance/zq1/index_"
url=url+str(page)+".shtml"
#伪装为浏览器
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req)
url_contain = response.read()
#利用BeautifulSoup进行文档解析
soup = BeautifulSoup(url_contain)
params = soup.findAll('div',{'class':'listBlk'})
if os.path.exists(projectpath+'stock\\'+'link'):
pass
else:
os.mkdir(projectpath+'stock\\'+'link')
filename='link.txt'
path=projectpath+'stock\\link\\' + filename
filelink=open(path,'a+')
for params_item in params:
persons = params_item.findAll('li')
for item in persons:
href=item.find('a')
mil_link= href.get('href')
filelink.write(str(mil_link)+'\n')
#递归调用parse,传入新的爬取url
yield Request(mil_link, callback=self.parse)
page=page+1
#对单个新闻页面新建线程进行爬取
if flag!=1:
if (response.status != 404) and (response.status != 502):
thread.start_new_thread(loop,(response,))

在爬取的过程中要注意三点:
1、爬取不要过于频繁,不然可能会被封ip,可以减小爬取的速度,sleep一下,或者更改设置文件,我的在F:\Python27\python\Lib\site-packages\Scrapy-0.24.4-py2.7.egg\scrapy\settings\default_settings.py
2、文件夹的文件上限为21845,超过后注意再新建一个文件夹爬取
3、线程不能开得太多,不然也可能达到上限,可以考虑用代码现在所开线程的多少或者利用分布式系统